Dense Text Retrieval based on Pretrained Language Models: A Survey 上
摘要
文本检索是信息搜索领域一个由来已久的研究课题,其中一个系统需要将相关的信息资源以自然语言的形式返回给用户的查询。从经典的检索方法到基于学习的排序函数,其背后的检索模型随着技术的不断革新而不断演进。要设计有效的检索模型,一个关键的问题在于如何学习文本表示并对相关性匹配进行建模。预训练语言模型(Pretrained Language Models,PLMs)最近的成功为利用PLMs的优秀建模能力开发更有效的文本检索方法提供了启示。借助强大的PLMs,我们可以有效地学习查询和文本在潜在表示空间中的表示,并进一步构建稠密向量之间的语义匹配函数进行相关性建模。这种检索方法被称为稠密检索,**因为它使用稠密向量(即,embedding)来表示文本。**考虑到稠密检索的快速发展,在本综述中,我们系统地回顾了基于PLM的稠密检索的最新进展。与以往对稠密检索的综述不同,我们从一个新的视角,从架构、训练、索引和集成4个主要方面来组织相关工作,并总结了每个方面的主流技术。我们对文献进行了充分的调研,包括300余篇关于稠密检索的相关参考文献。为了支持我们的综述,我们创建了一个网站来提供有用的资源,并发布了一个代码库和工具包来实现稠密检索模型。本综述旨在为稠密文本检索的主要进展提供全面、实用的参考。
1 介绍
文本检索旨在查找相关信息资源(例如,文件或段落)以响应用户查询。它是指查询和资源以自然语言文本的形式存在的特定信息检索场景。作为克服信息过载的关键技术之一,文本检索系统已经被广泛地应用于许多下游应用,包括问答[1]、[2]、对话系统[3]、[4]、实体链接[5]、[6]和Web搜索[7]等。
第一时间段 BOW
开发文本检索系统的想法在研究文献中由来已久。早在20世纪50年代,开拓性的研究者们就已经开始研究如何通过选择具有代表性的术语对文本进行索引来进行信息检索[8]。在早期的工作中,**一个重要的成果是基于"词袋"假设的向量空间模型[9]、[10],**将文档和查询都表示为稀疏的基于术语的向量。为了构造稀疏向量表示,人们设计并实现了各种术语加权方法,包括经典的tf-idf方法[11]-[13]。基于该方案,可以根据稀疏查询与文本向量之间的词汇相似度来估计相关度。这种表示方案进一步得到了著名的倒排索引数据结构[14][15]的支持,它将文本内容组织为面向术语的发布列表,以实现高效的文本检索。
**为了更好地理解潜在的检索机制,概率相关性框架被提出用于相关性建模,例如经典的BM25模型[16][17]。**此外,统计语言建模方法[18]也被广泛用于文本排序。这些早期的贡献奠定了现代信息检索系统的基础,而提出的检索方法通常基于启发式策略或简化的概率原则。
Bagofwords模型,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法、句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
第二时间段 learning to rank
随着机器学习学科的发展,学习排名[19],[20]引入了监督学习进行文本排名。其基本思想是设计基于特征的排名函数,将手工制作的特征(不仅限于词汇特征)作为输入,然后用相关性判断(文档上的二进制或分级相关性注释)来训练排名函数。尽管有灵活性,但学习对方法进行排序仍然依赖于特征工程的人工努力。
第三阶段 Neural IR
此外,神经网络的重新兴起为开发更强大的文本检索系统提供了线索,该系统不再需要手工制作的文本特征。
作为信息检索的一项重要进展,深度学习方法[21]可以自动从标记数据中学习查询和文档表示,其中查询和文档都被映射到潜在表示空间中的低维向量(称为密集向量或嵌入)。通过这种方式,可以根据密集向量之间的语义相似性来测量相关性。
与经典向量空间模型中的稀疏向量相比,嵌入并不对应于显式术语维度,而是旨在捕捉潜在的语义特征以进行匹配。这种检索范式被称为神经信息检索(Neural Information retrieval,Neural IR)[22]-[24],这可以被认为是对密集检索技术的初步探索。根据[25]、[26]中的约定,我们将这些神经IR方法(在使用预训练的语言模型之前)称为pre-BERT模型。
近年来,基于强大的Transformer架构[27],预训练语言模型(Pretrained Language Models,PLM)[28]极大地推动了语言智能的发展。PLMs在大规模通用文本数据上进行预训练,可以对大量语义知识进行编码,从而具有更好的理解和表示文本内容语义的能力。遵循“预训练然后微调”的范式,PLMs可以根据特定的下游任务进行进一步的微调。受PLMs在自然语言处理领域的成功启发,自2019年起,研究人员开始开发基于PLMs的文本检索模型,产生了新一代的文本检索方法,即基于PLM的稠密检索模型。
近四年来,大量基于PLM的稠密检索的研究被提出[25],[26],[29],在现有的基准数据集上很大程度上提高了性能。据报道,在2021深度学习赛道上,基于PLM方法在文档和段落检索任务中都占据了主导地位[30]。基于PLM的稠密检索模型取得成功的原因主要有两个方面。首先,PLMs出色的文本表示能力使文本检索系统能够回答无法通过简单的词汇匹配解决的困难查询。其次,大规模标注检索数据集(例如,MS MARCO[32]和Natural Questions[33]数据集)的可用性使得训练(或微调)有能力的PLM用于文本检索变得可行。例如,TREC 2019和2020 Deep Learning Track[31],[34]发布了用于文档检索任务的36.7万个查询(源自MS MARCO )的训练集,这明显大于TREC中之前的检索任务。
考虑到稠密检索的重要进展,本综述旨在对现有的文本检索方法进行系统的综述。特别是,我们关注基于PLM的稠密检索方法(本综述中简称为稠密检索模型),而不是先前的神经IR模型(即pre-BERT方法[21],[22])。本文以第一阶段检索为核心,广泛探讨了构建稠密检索系统的四个方面,包括架构(如何为稠密检索器设计网络架构)、训练(如何利用特殊的训练策略优化稠密检索器)、索引(如何为索引和检索稠密向量设计高效的数据结构)和集成(如何集成和优化一个完整的检索流程)。我们的调查广泛讨论了构建稠密检索系统的各种有用的主题或技术,旨在为研究人员和工程师提供对这个研究方向全面、实用的参考。
我们知道几个与稠密检索密切相关的综述或书籍[24]-[26],[29],[35]。例如,Guo等[24]综述了神经IR的早期贡献,Cai等[29]从三种范式总结了第一阶段检索的的主要进展,Lin等[25]综述了主要基于预训练Transformers的文本排序方法,Fan等[26]综述了基于预训练方法的信息检索的主要进展,Nicola Tonellotto [35]介绍了神经信息检索的最新进展。
Lecture Notes on Neural Information Retrieval
2022 9
与这些文献调研不同的是,我们强调本综述的三个新特点:
第一,我们专注于基于PLM的稠密检索的研究,并从架构、训练、索引和集成四个主要方面对相关研究进行了新的分类。
第二,我们特别关注稠密检索的实用技术,广泛讨论了训练检索模型、构建密集索引和优化检索流程的方法。
第三,我们涵盖了稠密检索的最新进展,并详细讨论了几个新兴的研究课题(例如,基于模型的检索和表示增强的预训练)。
为了支持这项调查,我们创建了一个参考网站,用于纳入稠密检索研究的相关资源(例如,论文、数据集和库),网址为:https://github.com/RUCAIBox/DenseRetrieval。此外,我们实现并发不了许多基于PaddlePaddle3(包括RocketQA 、PAIR和RocketQAV2 )的稠密检索模型的代码库,并提供了灵活的接口来使用或重新训练稠密检索器。
本文剩余内容安排如下:
第2节全面介绍了稠密检索的术语、符号和任务设置,
第3节介绍了现有的稠密检索数据集和评价指标。
作为核心内容,第4、5、6、7节回顾了稠密检索的主流架构、训练方法、索引机制和检索流程,并对这4个方面的最新进展进行深入讨论。然后,我们继续讨论高级主题(第8节)和应用(第9节)。
最后,我们通过总结第10部分的主要发现和遗留问题来结束本词调查。
2概述
本部分首先介绍了稠密文本检索的背景,然后讨论了设计稠密检索模型的关键问题。
2.1 任务设置与术语
在本调查中,我们关注的任务是从一个庞大的文本集合中查找相关文本,以响应用户发出的自然语言查询。特别地,查询和文本(例如,文档)都是以词汇表中的单词标记序列的形式呈现的。**特别地,文本可以具有不同的语义粒度(例如,文档、段落或句子),从而导致文档检索、篇章检索等不同类型的检索任务。**由于我们旨在为各种检索任务引入通用的方法,因此我们统一地将这些任务称为文本检索。
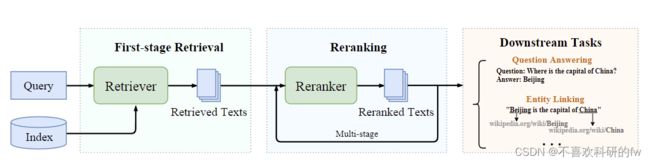
图1 信息检索系统总体流程示意图
通常情况下,一个完整的信息检索系统由多个程序或阶段排列在一个处理流程中[25],[26]。在这个流程中,第一阶段的检索旨在通过检索相关的候选对象来减少候选空间,我们将实现第一阶段检索的组件称为检索器[25],[29]。相应地,后续阶段主要是对候选文本进行重排序(或排序),称为重排序阶段,并得到重排序器的支持[25]。基于第一阶段检索器的检索结果,检索系统通常设置一个或多个重排序阶段细化初始结果并导出最终的检索结果。对于其他细粒度的检索任务,例如问答,可以进一步集成另一个名为Reader [39]的组件来分析检索器(或重排序器)返回的文本并定位查询的答案。
2.2 稠密检索公式化
形式上,令q表示一个自然语言查询,d表示由m个文档组成的大型文本集合中的一个文本。给定一个查询,文本检索的目的是根据检索模型的相关度得分返回n个最相关文本的排序列表。作为一种技术方法,稀疏检索模型(依靠词汇匹配)或稠密检索模型(依靠语义匹配)都可以用来实现 retriever。
稠密检索的关键是将查询和文本表示为稠密向量,根据这些稠密向量之间的某种相似度函数[25],[26],[29],[40]计算相关性得分,记为
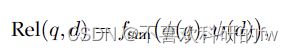
其中,和分别是将查询和文本映射为l维向量的函数。对于稠密检索,和是基于神经网络编码器开发的,相似性度量函数(例如,内积)可以用来实现。在pre-BERT时代,编码器通常由多层感知器网络(或者由别的神经网络)实现,而在本综述中,我们重点关注基于预训练语言模型( pretrained language models,PLMs )的文本编码器,称为稠密检索器。
为了学习稠密检索模型,我们还假设提供了一组相关性判断用于训练或微调PLM。特别地,我们只考虑具有二元(仅正例)相关性判断的集合:对于一个查询q,给出一个正文本列表作为训练数据。通常,负例文本(称为负例)并不直接可用,我们需要通过抽样或其他策略(详见5.2节)来获得负例。值得注意的是,在某些情况下,我们也可以得到分级相关性判断[42],[43],其中标签表示文本的相关程度(例如,相关、部分相关和不相关)。然而,这种细粒度的相关性标签在现实检索系统中很难获得。因此,我们在本总数中主要考虑二元相关性判断。
2.3 主要方面
本综述以第一阶段的稠密检索为核心,广泛讨论了构建一个强大的检索系统的四个关键方面,具体如下:
架构(第4节)。设计合适的网络架构对于关联模型的构建具有重要意义。目前,一些通用的PLM已经被开发出来,我们需要根据任务需求对现有的PLM进行调整,以适应文本检索。
训练(第5节)。与传统的检索模型不同,基于PLM的检索器的训练难度更大,包含的参数量巨大。我们需要开发有效的训练方法来达到理想的检索性能。
索引(第6节)。传统上,倒排索引可以有效地支持稀疏检索模型。然而,稠密向量并不明确对应于词汇术语。我们需要为稠密检索设计合适的索引机制。
集成(第7节)。如前所述,检索系统通常通过由检索器和重排序器组成的流程来实现。如何在一个完整的检索流程中集成和优化稠密检索器是需要研究的问题。
数据、评价和资源
在本节中,我们将介绍用于稠密检索的数据集、评价指标和支持库。
3.1 数据集
与传统检索模型相比,稠密检索模型对数据更加饥渴,需要大规模有标签数据集来学习PLMs的参数。近年来,公开发布了多个具有相关性判断的检索数据集,极大地推动了稠密检索的研究。我们将现有的检索数据集按照其原始任务分为三大类,即信息检索、问答和其他任务。可用数据集的统计如表1所示。

从表1可以看出,维基百科和Web是创建这些数据集的两个主要资源。其中,MS MARCO数据集[32]包含大量带有Web文档相关段落注释的查询,Natural Questions (NQ)数据集[33]包含排名靠前的维基百科页面带有注释(段落和答案跨度)的Google搜索查询。在这些数据集中,MS MARCO和NQ数据集已被广泛用于评估稠密检索模型。最近的一项研究[70]总结了MS MARCO对稠密检索进展的促进作用:“MS MARCO数据集实现了神经模型的大数据探索”。此外,在MS MARCO的基础上,还创建了多个变体,以丰富某些特定方面的评价特征,如多语种版本mMARCO[44]和MS MARCO Chameleons数据集[71] (由难以被神经检索器回答的顽固查询组成,尽管其查询长度和相关性判断分布与较容易回答的查询相似)。此外,Sciavolino等人[52]创建了EntityQuestions数据集,作为在NQ上训练的模型的一个挑战性的测试集,该数据集包含维基百科中关于实体的简单仿真问题。另一个有趣的观察是,越来越多的领域特定的检索数据集出现,包括新冠肺炎疫情数据集[45],金融数据集[60],生物医学数据集[61],气候特定数据集[67]和科学数据集[68]。
除了表1中给出的数据集之外,还发布了几个更全面的基准数据集,通过聚合代表性数据集和执行不同的评估任务来评估检索模型的整体检索能力,如BEIR[72]和KILT[73]。
尽管现有的数据集在很大程度上改进了稠密检索器的训练,但在这些数据集中,查询通常响应很少的相关性判断。例如,诺盖拉等人观察到MS MARCO数据集中的大多数查询只包含一个标记为正的查询[74],这很可能小于集合中相关查询的实际数量。这主要是因为对于一个大的数据集构建完整的相关性判断是很耗时的。不完整的相关性标注会导致潜在的训练问题,如假负例,这将损害检索性能。
此外,迄今为止,大多数发布的数据集都是以英文创建的,获取足够的标注数据来训练一个非英文的稠密检索器更加困难。最近,DuReader-retrieval [54]发布了一个大规模的中文数据集,该数据集由来自百度搜索的9万个查询和超过800万个用于段落检索的段落组成。为了增强评估质量,DuReader-Retrieval试图减少开发和测试集中的假阴性,同时也删除了与开发和测试查询语义相似的训练查询。此外,它还提供了跨语言检索的人译查询(英文)。
3.2 评价指标
为了评价一个信息检索系统的检索能力,需要考虑多个因素[75],[75],[76]:有效性、效率、多样性、新颖性等。本综述主要关注检索系统的有效性。接下来介绍排序常用的评价指标,包括召回率、精确度、MAP、MRR和NDCG。对于稠密检索任务,排序靠前的文本对于评价更为重要,因此通常采用截断度量(cut-off)来考察排名靠前的文本的质量。接下来,我们详细介绍几种常用的稠密检索指标。
在传统的检索基准中,在传统的检索基准中,召回率是一个检索模型实际检索到的相关文本在所有相关文本中所占的比例,Recall@k[77]在检索到的列表的第k个位置计算截断的召回率值:

对于第一阶段的检索,Recall@k和Precision@k是最常用的度量指标,因为它的主要关注点是在截断长度下召回尽可能多的相关文本或答案;而对于排序,实践中更常用的是MRR、NDCG和MAP。对于关于IR评估的全面讨论,建议读者阅读更多有重点的参考文献[75],[76],[79],[80]。
3.3 代码库资源
最近,出于研究目的,一些开源的稠密检索库已经发布。作为一个代表性的库,Tevatron[81]开发了一个模块化的框架,用于通过命令行接口构建基于PLMs的稠密检索模型。它支持包括文本处理、模型训练、文本编码和文本检索在内的完整检索流程中涉及的多个重要步骤。
此外,Pyserini [82]是一个工具包,旨在为信息检索提供可重复研究。具体来说,它支持Anserini IR工具包[83]和FAISS [84]的稀疏检索和稠密检索。同时也为标准的IR测试集提供了评估脚本。可在链接http://pyserini.io/处访问。
为了增强稠密检索器检查点的验证,Asyncval [85]被发布,用于简化和加速稠密检索模型的检查点验证。一个重要的优点是可以通过Asyncval将训练与检查点验证解耦。可以通过以下链接访问:https://github.com/ielab/asyncval。
OpenMatch [86]最初是针对pre-BERT神经IR模型(v1)提出的,并扩展(v2)以支持在MS MARCO和NQ等常用基准上的稠密检索模型。可以通过https://github.com/thunlp/OpenMatch链接访问。
MatchZoo [87]是一个文本匹配库,支持多个神经文本匹配模型,并允许用户通过提供丰富的接口来开发新的模型。可以通过https://github.com/NTMC-Community/MatchZoo链接访问。
PyTerrier [88]是一个检索框架,它支持声明式使用Python运算符构建检索管道和评估检索模型,涵盖代表性的排序学习、神经重排序和稠密检索模型。它可以通过此链接访问:https://github.com/terrier-org/pyterrier。
SentenceTransformers [89]是另一个库,它提供了一种基于Transformer网络为句子和段落提供计算稠密嵌入的简单方法。具体来说,它集成了SentenceBERT [89]和Transformer-based Sequential Denoise Auto-Encoder (TSDAE) [90]的实现。可在链接https://www.sbert.net/处访问。
作为支持资源,我们还在前期工作RocketQA [36]的基础上发布了稠密检索器的开源实现,包括RocketQA[36]、RocketQAPAIR[37]和RocketQAV2[38],链接为https://github.com/PaddlePaddle/RocketQA。该软件还提供了一个易于使用的工具包,其中包含预先构建的模型(包括英文和中文模型),可在安装后直接使用。我们还在我们的调查网站上聚合了相关密集检索论文的其他开源代码,可以在链接https://github.com/RUCAIBox/DenseRetrieval中找到。
架构
本节介绍了稠密文本检索的主要网络架构。我们从Transformer和PLMs的背景出发,介绍两种典型的用于构建稠密检索模型的神经架构,最后对稀疏和稠密检索模型进行了对比。
4.1 背景
4.1.1 Transformer和预训练语言模型
Transformer [27]已经成为语言模型预训练的主流支柱,最初是为了高效地建模序列数据而提出的。与传统的序列神经网络(即RNN及其变体[156],[157])不同,Transformer不再按顺序处理数据,而是引入了一种新的自注意力机制:一个token关注来自输入的所有位置。这样的架构特别适合在GPU或TPU的支持下进行并行化。作为一个显著的贡献,Transformer使训练非常大的神经网络变得更加灵活和容易。有大量的变体改进了基础Transformer的架构,读者可以参考相关综述[158],[159]进行综合讨论。
A Survey of Transformers. 2021
Efficient Transformers: A Survey 2020.9
基于Transformer及其变体,在自然语言处理领域提出了预训练语言模型(PLM)[28]、[160]、[161]。PLM在大规模通用文本语料库上进行预训练,具有特别设计的自监督损失函数,并且可以根据各种下游任务进一步微调。这种学习方法被称为预训练然后微调范式[28],[162],这是近年来语言智能方面最引人注目的成就之一。作为最具代表性的PLMs之一,BERT[28]预训练了用于学习通用文本表示(用单词掩蔽的技巧)的深度双向架构,这在很大程度上提高了各种自然语言处理任务的性能。BERT的成功激发了一系列后续研究,包括改进的预训练方法[160]、改进的双向表示[163]、模型压缩[164]等。此外,一些研究尝试训练超大规模的PLM,以探索作为通用学习器的性能极限[161],[165],在下游任务上取得了令人印象深刻的结果。
除语言建模外,PLMs目前已成为建模、表示和处理大规模无标签数据的通用技术方法,也被称为基础模型[166]。对基础模型近期进展的详细介绍超出了本综述的范围,在本次调查中省略。
4.1.2 稀疏检索的PLMs
在介绍PLMs用于稠密检索之前,本部分简要回顾如何利用PLMs改进依赖词汇匹配的稀疏检索模型。基本上来说,这一行的研究工作大致可以分为两大类,即术语加权和术语扩展。
第一类工作旨在**改进基于每个token的上下文表示的术语权重。**作为一个代表性的研究,DeepCT[167]利用学习到的BERT token 表示来估计每个段落中出现的术语的上下文特定重要性。其基本思想是将token表示回归为实值术语权重。HDCT [168]通过将文档拆分成段落的方式将其扩展到长文档中,并在每段落中聚合估计的术语权重。具体来说,它利用三种数据资源(即标题、Web inlinks和伪相关反馈)生成弱监督信号用于学习术语权重。它通过对一个术语的文本上下文进行建模,可以更好地学习该术语的重要性。此外,COIL [169]利用精确匹配术语的上下文token表示来估计相关性。它计算来自查询编码器和文本编码器(只考虑重叠术语)的token表示之间的点积,然后将特定于术语的相似度得分加和作为相关度得分。为了更好地理解上述模型,Lin等人[170]提出了一个概念框架来统一这些方法:DeepCT旨在为查询项分配标量权重,而COIL旨在为查询词分配向量权重。此外,uniCOIL [170]也是通过将COIL中的权重向量降低到一维而提出的,文献[170]的实验表明,uniCOIL在提高效率的同时还能保持有效性。
第二类工作**通过使用PLM来缓解词汇不匹配问题,以此扩展查询或文档。**例如,docTTTTTquery [171]预测文档将要相关的一组查询,这样以来预测的查询可以用来丰富文档内容。此外,SPLADE [172]和SPLADEv2 [173]将查询和文本中的每个术语投影到一个词汇表大小的权重向量中,其中每个维度表示术语在PLMs词汇表中的权重。权重用掩盖语言模型的logits 进行估计。然后,通过组合(例如,求和或最大池化)由文本的所有token估计的权重向量来获得整个文本(或查询)的最终表示。这种表示可以被视为查询(或文本)的扩展,因为它包含查询(或文本)中没有出现的术语。进一步应用稀疏正则化来获得稀疏表示,以便有效地使用倒排索引。
尽管使用了PLMs,但这些方法仍然是基于词汇匹配的。它们可以通过引入额外的负载(例如,上下文嵌入)来重用传统的索引结构。对于PLM增强的稀疏检索模型的更深入讨论,读者可以参考[25],[26],[29]。
4.2 稠密检索的神经架构
稠密检索的本质是基于潜在语义空间中学习到的表征来建模查询和文本之间的语义交互。基于不同的交互建模方式,稠密检索有两种主流架构,即交叉编码器和双编码器。
4.2.1 交叉编码器架构
作为PLMs的直接应用,交叉编码器将查询-文本对视为一个完整的"句子"。具体来说,交叉编码器的输入是一个查询和一个文本的拼接,由一个特殊符号“[SEP]”分隔。为了获得整体表示,在拼接句句首插入另一个符号“[CLS]”。然后,将查询文本序列输入到PLM中,用于对输入序列的任意两个token之间的语义交互进行建模。在学习到序列中每个token的表示后,我们可以得到这个查询-文本对的匹配表示。常用的方式是将“[CLS]”表示作为语义匹配表示[174]。也可以使用其他变体,例如,平均token嵌入[89]。这种架构类似于BERT之前的研究中基于交互的架构[22],[175],因为它允许token跨查询和文本进行交互。


4.2.2 双编码器结构
双编码器(bi-encoder或dual-encoder)采用双塔结构,类似于BERT之前研究中基于表示的方法(如DSSM [21])。主要区别在于,它用基于PLM的编码器取代了以前使用的多层感知器(或其他神经网络)。接下来,我们将讨论用于稠密检索的双编码器架构的主要进展。
**单表示双编码器。作为双编码器架构的基本形式,它首先使用两个独立的编码器分别学习查询和文本的潜在语义表示,分别称为查询嵌入和文本嵌入。然后,通过查询嵌入和文本嵌入之间的某种相似度函数(例如,余弦相似度和内积)来计算相关性得分。
如前所述,我们可以通过在文本序列的开头放置一个特殊符号(例如BERT中的“[CLS]”)来直接对查询和文本进行编码,这样学习到的特殊符号的表示就可以用来表示文本(或查询)的语义。大多数单表示的稠密检索器[1]、[36]、[98]都是使用仅有编码器的PLMs (例如BERT[28]、RoBERTa[28]和ERNIE[176]) 学习查询和文本表示。**最近,文本到文本的Transformer(T5) [165],一种基于编码器-解码器的PLM,已经被探索用于学习稠密检索的文本表示[118],[129]。已有研究表明,基于T5的句子嵌入模型在SentEval [178]和SentGLUE [165]任务上优于SentenceBERT [177]。


上述为单塔模型
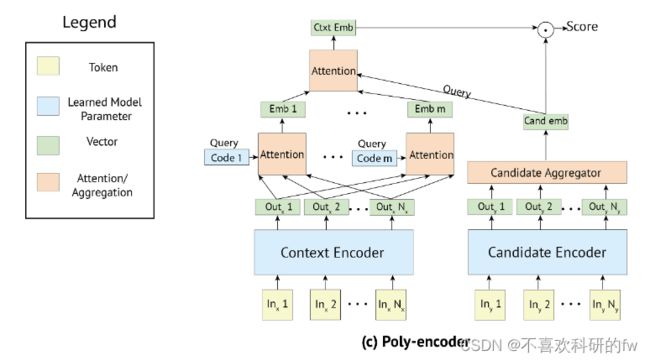
多塔模型
Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring 【91】
多表示双编码器。单表示双编码器的一个主要局限性是不能很好地建模查询和文本之间的细粒度语义交互。为了解决这个问题,一些研究人员提出探索多表示双编码器来增强文本表示和语义交互。多编码器模型[91]学习m个不同的表示来建模一个文本在多个视图中的语义,在原论文中称为上下文代码。在查询期间,通过关注查询向量,这些m个表示组合成一个单一的向量。最后,计算查询向量与聚合向量之间的内积作为相关度得分。
作为另一项相关研究,ME-BERT[96]也通过直接获取前m个token的上下文化表示,来为候选文本生成m个表示。通过计算查询向量和m个上下文表示之间的最大内积来得到文本相关性。
此外,ColBERT[95]设计了一种极端的多表示语义匹配模型,在该模型中保留了每个token的上下文化表示,用于查询-文本交互。与交叉编码器的表示方案( 4.2 . 1节)不同,这些上下文化的表示在编码过程中并不直接跨查询和文本进行交互。取而代之的是,他们为交互中的每个token表示引入了一种查询时间机制,称为延迟交互[95]。
作为ColBERT的扩展,ColBERTer[136]设计了一种结合单表示(“[CLS]”嵌入)和多表示(每个token嵌入)机制进行匹配的方法,实现了对ColBERT的性能改进。
最近,MVR [135]提出在文本开头插入多个“[VIEW] ”标记(类似于“[CLS]”),旨在学习多个不同视图中的文本表示。更进一步,他们设计了一个特殊的局部损失来区分查询文本的最佳匹配视图和其余视图。
MADRM [179]提出学习查询和文本的多个方面嵌入,并使用显式的方面标注来监督方面学习。本文没有使用标准的稠密检索基准,而是基于电子商务数据集进行了评估实验。
这些多表示双编码器共享使用多个上下文嵌入来表示查询或文本的思想,使得相似性可以从不同的语义视图来度量。这些上下文化的表示在训练和索引过程中被学习和存储;而在查询时,我们可以对查询嵌入和预先计算的文本嵌入之间的细粒度语义交互进行建模。这种方法对于提高检索性能是有效的,但是维护多表示实现(例如,增加了索引大小)的成本很高,在实际应用中并不实用。考虑到这个问题,ColBERTer[136]中提出的一些特定策略用来降低多表示成本,例如嵌入降维、唯一全词表示袋和上下文停用词移除。[136]中的实验表明,ColBERTer可以在保持有效性的同时显著降低空间开销。
短语级表示。一般而言,稠密检索模型专注于解决文档或段落级别的文本检索任务。针对特定任务,如开放域问答和槽填充[106],考虑更细粒度的检索单元(例如,短语或连续文本片段),来扩展现有的检索模型是很自然的。最近,一些研究提出学习短语表示来直接检索短语作为查询的答案[106],[180]-[182]。其基本思想是以查询无关的方式对所有文档进行预处理,并对文档中连续的文本片段生成短语表示(称为短语嵌入)。然后,将答案查找任务转化为检索与查询嵌入最近的短语嵌入的问题。PIQA (短语索引问答) [182]第一个提出了利用稠密短语索引进行问答的方法。Den SPI [180]进一步结合短语的稠密向量和稀疏向量来捕获语义和词汇信息,从而提高短语索引问答的性能。然而,这种方法在很大程度上依赖于稀疏向量来获得良好的性能。考虑到这个问题,Seo等人[106]提出了DensePhrases,这是一种在不使用稀疏表示的情况下改进稠密短语编码器学习的方法。DensePhrases通过数据增强和知识蒸馏学习稠密短语表示,并进一步使用增强的负例训练(同时考虑批内和批前的负例)和查询端调优。文献[181]的一个有趣的发现是,在NQ和Trivia QA上,稠密短语检索系统可以获得比DPR更好的段落检索准确率,而不需要重新训练。这说明通过捕捉细粒度的语义特征,短语级信息对于相关性匹配是有用的。他们进一步提出,稠密短语检索器可以被认为是多表示检索器的动态版本,因为它为每个文本动态生成一组短语嵌入。
**其他改进变体。**除了上述主要的表示方式外,还有几个不同方面的改进变体。
**复合架构。**根据具体任务,上述双编码器和变体可以应用于文档检索或段落检索。我们还可以通过集成不同语义粒度的文本编码器来设计复合架构。在最近的一项工作[183]中,通过结合文档检索器和段落检索器,同时考虑文档级别和段落特定语义,提出了一种分层检索方法。此外,[128]中提出了一种增强方法,将多个“弱”稠密检索器集成在一起,以实现良好的检索性能。此外,Li等人[184]提出以不确定性加权的方式将经过不同任务训练的多个稠密检索器结合起来。
Dense Hierarchical Retrieval for Open-Domain Question Answering 【183】
**轻量级架构。**除了检索性能外,还有一些旨在学习轻量级表示的方法,包括根据估计的术语重要性进行查询嵌入剪枝的方法[185],使用带硬负例的交叉编码器蒸馏和残差表示压缩的轻量级延迟交互变体[125] (即ColBERTv2),以及使用离散量化表示(详见6.2 . 3节)的乘积量化方法[117]。
**结合相关性反馈。**作为一种经典的策略,伪相关性反馈在稠密检索的设置中被重新访问以增强查询表示[119],[186]-[188]。其基本思想是利用初始检索到的文档导出增强的查询嵌入。此外,Zhuang等[189]利用基于点击模型的模拟,将点击数据作为反馈信号进行探索,进而提出了一种反事实方法来处理点击数据中的偏差问题。Wang等人[190]使用相关反馈来增强多表示稠密检索模型,表现出比基础模型ColBERT更大的性能提升。
**参数有效微调。**由于对大规模的PLM进行微调的成本很高,为了使PLM适应检索任务[150],[191],参数有效微调被提出[162]。一般而言,当直接应用于稠密检索时,参数有效微调往往不如微调方法。针对这一问题,DPTDR引入了面向检索的预训练和反向挖掘[150]来增强参数有效微调,取得了与微调检索器相当的性能。此外,文献[191]的实验表明,参数有效微调 (例如, P-tuning v2 [192] )可以提高DPR和ColBERT的零样本检索性能。
4.2.3 交叉编码器和双编码器的比较
基于表示 query 和 context 之间没有交互 分开表示后 计算分数
基于交互 query 和 context 之间在训练时就有交互
自BERT时代以来,根据细粒度tokens是否可以在查询和文本之间进行交互,基于交互或基于表示的方法被提出作为神经IR的两种主要架构[22]。遵循这一惯例,交叉编码器和双编码器可以分别理解为基于PLM的两种架构的实例化。为了对其有更深入的了解,接下来我们从密集文本检索的角度对交叉编码器和双编码器进行了比较。
首先,交叉编码器更有能力学习查询-文本对的细粒度语义交互信息。人们普遍认为交叉编码器在相关性匹配方面更有效[36],[100],[193]。
与之相反,双编码器(在一个原始的实现中)无法捕获查询和文本表示之间的细粒度交互。如上所述,许多研究旨在通过使用多个上下文嵌入来提高双编码器的表示能力**[91],[95]**。根据MS MARCO [38],[125]的报道结果,多表示双编码器的性能优于单表示双编码器,但仍差于交叉编码器,因为它试图模仿交叉编码器来建模细粒度的语义交互。
第二,双编码器在架构上更加灵活高效。在灵活性方面,它可以使用不同的编码网络对查询和文本进行编码,从而为稠密检索提供更灵活的架构设计,例如短语索引[180]。为了提高效率,可以通过近似最近邻搜索来加速大规模向量召回[84],这对于稠密检索方法的实际使用尤为重要。
考虑到两种架构的优劣,在实际应用中,为了在有效性和效率之间进行权衡,它们往往被联合应用于检索系统中。通常,**双编码器用于大规模候选召回(即,第一阶段检索),交叉编码器用于实现重排序器或阅读器(第7.1.2节)。**此外,交叉编码器经常被用来改进双编码器,例如知识蒸馏[38],[102] (第5.3.2节)和伪标注数据生成[36],[37] (第5.4.2节)。
4.3 稀疏检索V.S.稠密检索
在这一部分,我们首先讨论稀疏检索和稠密检索的区别/联系,然后介绍如何结合两种方法进行检索。
4.3.1 讨论
为了理解稠密检索模型的行为以及它们与稀疏检索模型之间的联系,我们将围绕以下几个问题展开讨论。
A 稠密检索模型总是优于稀疏检索模型?它们各自的优势和劣势是什么?
一方面,在稠密检索的早期文献[1]、[36]、[98]中,有多项实验研究报道了稠密检索模型往往优于经典的稀疏模型(例如, BM25),尤其是在最初为问答而设计的基准测试集(如MS MARCO、自然问句和TriviaQA等)上。
由于这些基准测试侧重于复杂的查询求解,因此需要深度语义匹配能力来解决与答案有少量重叠术语的查询。
因此,由于无法处理术语不匹配问题,稀疏检索器无法很好地解决这些查询。
相比之下,稠密检索器通过度量潜在语义相似度来回答复杂查询更有效。以DPR论文中一个稀疏检索器无法解决的问题为例[1]:给定问题"谁是《指环王》中的坏人? “,一个稠密检索器可以通过捕捉"坏人"和"反派"之间的语义关联,检索出相关的文本跨度"Sala Baker在《指环王三部曲》中扮演反派索伦而闻名” [1]。
另一方面,稠密检索器的一个主要限制是它们依赖有标签的数据来学习模型参数。有文献报道,在BEIR基准测试数据集上,在零样本设置(没有来自目标领域的相关性判断数据)下,稠密检索模型的性能可能比稀疏检索模型更差[72]。
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models 2021
在BEIR上进行的实验表明,与BM25等经典检索模型相比,稠密检索模型的零样本检索能力非常有限[72]。**因此,大量研究致力于提高稠密检索器(具体讨论见8.1节)的零样本检索能力。
此外,稀疏模型更有能力解决需要精确匹配(例如,关键词或实体检索)的查询,而稠密检索器在这些情况下表现较差,特别是当实体或组合在训练集中很少出现或没有出现时[52],[194]。**例如,DPR论文[1]表明,对于“谁在《权力游戏》中扮演Myr的Thoros ?”的查询,它无法捕获实体短语“Thoros of Myr”,而BM25在这种情况下成功了。这一发现确实与两种技术方法的潜在机制一致:稀疏检索器基于词汇匹配,而稠密检索器使用潜在嵌入进行语义匹配,这可能会由于压缩的语义表示而导致显著信息的丢失。第4.3.2节将讨论如何通过组合稀疏和稠密检索器来增强稠密检索模型的精确匹配能力。
B 对于稠密表示在相关性匹配上的能力,特别是它们如何模仿并关联稀疏检索,有没有什么理论分析?是否可以将传统的IR公理应用于稠密检索?
稠密检索使用潜在语义表示进行相关性匹配,表现出与稀疏检索模型不同的检索性能:它们在复杂查询上表现较好,但在精确匹配查询上表现较差。理解稠密检索模型的检索行为及其与稀疏检索模型(例如,它们如何进行精确匹配)的联系具有重要意义。为此,Luan等人[96]研究了嵌入大小对(例如,词袋模型(bag-of-word model))模拟稀疏检索能力的影响。他们证明,当文档长度增加时,应该增加稠密检索器的嵌入大小,以实现与词袋模型相当的检索性能。此外,另一项相关研究表明,语料规模对稠密检索的影响更大[195]:“稠密表示的性能随着索引规模的增加而下降的速度要快于稀疏表示”。他们解释这一发现的依据是,当索引大小增加时,假正例的概率会变大,尤其是在维度降低的情况下。
理解稠密检索器行为的另一种可能方法是来自经典IR文献[196]-[198]的公理化分析。具体来说,IR公理被形式化为一组相关性约束,合理的IR模型需要满足或至少部分满足[197],[199],例如,包含查询术语出现次数更多的文档应该获得更高的评分,这可以为传统的IR模型提供可解释的证据和学习指导。然而,人们发现现有的IR公理可能只能部分解释[200],甚至不适合分析[201]基于PLM的IR模型的行为。一些进一步的分析[202]也表明,与稀疏排序模型相比,神经排序模型具有不同的特点。例如,稠密模型更容易受到添加非相关内容的影响,基于同一语言模型的不同排序架构可能导致不同的检索行为。
尽管基于BERT的排序模型不能很好地与传统的IR公理保持一致,但最近的研究[203]也表明一些稠密检索模型(例如,ColBERT)意识到文本表示中的术语重要性,并且也可以隐式地模拟重要术语的精确匹配。
总体而言,稠密检索模型的理论探索仍然是一个开放的研究方向。在这方面需要付出更多的努力来理解稠密检索模型的相关性匹配行为。
4.3.2 结合稀疏和稠密检索模型
在实际应用中,两种检索模型可以通过利用互补的相关性信息而互相收益。例如,稀疏检索模型可以用来为训练稠密检索模型提供初始检索结果[1],[204],而PLMs也可以用来学习术语权重来改进稀疏检索[167],[168] (如4.1.2节所述)。特别地,这也说明了稀疏检索模型可以用来增强稠密检索模型(更多讨论请参见8.1节)的零样本检索能力。
考虑到两种方法所捕获的不同相关性特征,越来越多的研究开发了稀疏和稠密的混合检索模型。一种直接的方法是将两种方法的检索得分进行汇总[1],[96]。进一步,使用分类器为每个单独的查询在稀疏、密集或混合检索策略中进行选择[205],旨在是平衡检索器的成本和效用。
Dense Passage Retrieval for Open-Domain Question Answering 【1】
Sparse, Dense, and Attentional Representations for Text Retrieval 【96】
Predicting Efficiency/Effectiveness Trade-offs for Dense vs. Sparse Retrieval Strategy Selection 【2021】 【205】
Aggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval 2022 【147】
Densifying Sparse Representations for Passage Retrieval by Representational Slicing【206】
然而,这些混合方法需要维护两个不同的索引系统(倒排索引和稠密向量索引),由于过于复杂,难以在实际中部署。为了解决这个问题,Lin等人[147],[206]提出通过对高维稀疏词汇表示进行稠密化来学习低维稠密词汇表示( DLRs ),使得端到端学习词汇语义联合检索系统变得可行。稠密化的基本思想是首先将高维的词汇表示划分成片,并通过专门设计的池化方法减少每个切片表示。然后,将这些表示拼接起来,作为稠密的词汇表示。
对于文本排序,将稠密的词汇表示和稠密的语义表示(即,“[CLS]”的表示)结合起来计算相似度得分。文献[147],[206]中的实验结果表明,该方法通过结合两种表示的优点,可以在很大程度上提高检索效果,在零样本评价上表现出优越的性能。此外,Chen等人[123]提出从BM25构建的弱监督数据中学习稠密词汇检索器,使得学习到的稠密词汇检索器能够模仿稀疏检索器的检索行为。在该方法中,来自稠密词汇检索器和稠密语义检索器(例如,DPR和RocketQA)的表示结合起来进行相关性计算。已有研究表明,从BM25中学习到的知识可以帮助稠密检索器处理包含稀有实体的查询,从而提高鲁棒性[123]。
**此外,LED [151]提出使用基于PLM的词汇感知模型(即SPLADE [172])来增强稠密检索器的词汇匹配能力。**它引入了词汇增强的对比学习和秩一致正则化来开发词汇增强的稠密检索模型。实验结果表明,本文提出的方法优于多个具有竞争力的基线。
5训练
在介绍了网络架构之后,我们接下来讨论如何有效地训练基于PLM的稠密检索器,这是实现良好检索性能的关键。针对用于第一阶段检索的双编码器的训练,我们将首先制定损失函数并介绍训练的三个主要问题(即大规模的候选空间,有限的相关性判断和预训练差异),然后分别讨论如何解决这三个问题。
5.1 公式化和训练问题
本部分提出了基于PLM的稠密检索器的公式化和训练问题。
5.1.1损失函数
在这一部分,我们首先通过负对数似然损失将检索任务公式化为一个学习任务,然后讨论实现损失函数的几种变体。



5.1.3 主要训练问题
在这一部分,我们总结了稠密检索的主要训练问题。
问题1:大规模候选空间。在检索任务中,一个文本集合中通常有大量的候选文本,而集合中只有少数文本与查询相关。因此,训练能够在大规模文本集合上表现良好的稠密检索器是具有挑战性的。具体来说,由于计算空间和时间的限制,我们只能采样少量的负例样本来计算损失函数(公式(11)),导致训练(一小部分文本)和测试(整个集合)之间的候选空间发生偏移。研究发现,负例样本对检索性能有显著影响[1],[36],[98]。
问题2:有限的相关性判断。在实际应用中,构建具有完全相关性判断的大规模有标签数据进行稠密检索是比较困难的。尽管已经发布了几个大尺寸的基准数据集(例如MS MARCO),但它仍然局限于训练非常大的基于PLM的稠密检索器。此外,这些数据集中的相关性标注还很不完善。因此,很可能出现“假负例”(实际相关但未标注的),这成为训练稠密检索器的一个主要挑战。
问题3:预训练差异。PLMs通常使用预先设计的自监督损失函数进行训练,例如掩盖词预测和下一个句子预测[28]。这些预训练任务并没有专门针对检索任务进行优化[93],[127],[211],因此可能导致次优的检索性能。此外,为了表示文本,现有工作通常采用PLMs的“[CLS]”嵌入作为文本表示,而“[CLS]”嵌入并不是显式地设计来捕获整个文本的语义。考虑到这一问题,需要为底层PLM设计更适合稠密检索的特定预训练任务。
上述3个问题已成为稠密检索的主要技术瓶颈,备受研究关注。接下来,我们将回顾解决上述问题的最新进展,并讨论三种主要的稠密检索技术,具体分为以下三个小节:第5.2节(负例选择)、第5.3节(数据增强)和第5.4节(预训练)。
5.2 负例选择
为了优化稠密检索器(式( 11 ) ),需要一定数量的采样的负例来计算负对数似然损失。因此,如何选择高质量的负例成为提高检索性能的重要问题。接下来,我们将回顾三种主要的负例选择方法,并给出理论上的讨论。
5.2.1 批内负例
一个简单的负例选择方法是随机抽样,即每个正例文本与几个随机的负例配对。然而,大多数PLM在显存有限的GPU上以批处理方式进行优化,这使得在训练过程中使用大量的负例是不可行的。考虑到这个问题,批内负例被用于优化稠密检索器:给定一个查询,与来自同一批次的其余查询配对的正例文本被认为是负例。假设一个批处理中有b个查询( b > 1),每个查询都与一个相关文本相关联。通过批内负例技术,我们可以为同一批次中的每个查询获得b - 1个负例,这在显存限制下大大增加了每个查询可用负例的数量。批处理技术最早在文献[212]中被提出用于智能回复的响应选择任务,而DPR [1]已经明确地将批处理技术用于稠密检索。通过增加负例数量[1],[36],批内负例被证明可以有效地改善双编码器的学习。
同一批次内 匹配的为aa,bb,cc,dd
ab ac ad 为负例
5.2.2 批间负例
通过重用一个批次中的实例,批内负例训练可以以存储高效的方式增加每个查询的负例数。为了进一步优化具有更多负例的训练过程,在多GPU设置下,另一种被称为批间负例[36],[109]的改进策略被提出。其基本思想是跨不同的GPU重用实例。假设有a个GPU用于训练稠密检索器。我们首先在每个GPU上计算文本嵌入,然后让它们在所有GPU上进行通信。这样,来自其他GPU的文本嵌入也可以作为负例使用。对于给定的查询,我们从a个GPU中获a X b - 1得个负例,大约是批内负例的a倍。这样,在训练过程中可以使用更多的负例来提高检索性能。跨批次负例的思想也可以通过梯度缓存技术扩展到单个GPU设置[109],可以累积多个小批量来增加负例的数量(同时需要更大的计算成本)。
不同的GPU之间进行负例的选择
5.2.3 硬负例
尽管批内和批间负例可以增加可用负例的数量,但不能保证生成硬负例,硬负例指的是与查询不相关,但语义相似度较高的文本。为了提高区分相关和不相关文本的能力,引入硬负例显得尤为重要[1],[36],[98]。为了提高检索性能,许多研究设计了不同的硬负例选择策略。根据负例选择器(即基于某种相关性模型的文本集合上的采样器)是否固定或更新,**硬负例大致可以分为静态硬负例和动态硬负例[98],[111]。**此外,选取的硬负例可能包含噪声数据(例如,假负例),因此去噪后的硬负例也被用于训练稠密检索器[36]。接下来,我们对每一类硬负例进行详细的讨论。
引入与 文本相关 但是与 查询完全不相关的例子 作为负例子
静态硬负例。对于静态硬负例,在稠密检索器的训练过程中,负例选择器是固定的。其目标是挑选出难以被稠密检索器识别的负例。为了达到这个目的,一个直接的方法是从其他一些检索器的顶部检索结果中负例采样,不管这些检索器是稀疏的还是稠密的。由于BM25 [213]通常提供非常有竞争力的检索性能,一些**研究基于BM25选择硬负例,即对BM25返回的词汇相似的文本(但不包含答案)进行采样[1]。**在文献[204]中,多种负例也被混合用于训练,包括检索的负例(基于BM25,粗和细语义相似度)和基于启发式的上下文负例。本研究表明,结合混合硬负例训练的模型的集成方法能够提高检索性能。作为后续研究,作者[104]进一步设计了三种融合策略来结合不同类型的负例,即混合融合、嵌入融合和秩融合。此外,Hofstatter等人[110]提出了一种主题感知的采样方法来组成稠密检索的训练批次,该方法首先在训练之前对查询进行聚类,然后从每个批次的一个聚类中采样查询。这样,一个批次中的实例高度相似,这隐含地导出了具有批内采样技术的硬负例。
**动态(或定期更新)硬负例。**如前所述,**静态硬负例由固定的负例选择器获得。**由于稠密检索器的训练是一个迭代的过程,因此最好使用自适应更新的负例,称为动态硬负例,用于模型训练。**ANCE方法[98]提出从优化过的检索器本身检索到的最好的文本中负例采样,他们称之为全局硬负例。**文献[98]表明,全局选择的负例可以导致更快的学习收敛。为了检索全局负例,需要在更新模型参数后更新索引文本嵌入,这非常耗时。为减少时间开销,ANCE在训练过程中采用异步索引刷新策略,即每隔m个批次进行一次周期性更新。此外,Zhan等人[111]提出了一种新的动态硬负例选择方法ADORE,该方法根据正在更新的查询编码器从动态检索结果中负例采样。与ANCE [98]不同,ADORE固定了文本编码器和文本嵌入索引,并使用自适应查询编码器来检索排名靠前的文本作为硬负例。在每次迭代时,由于用于负例选择的查询编码器在训练时得到了优化,因此它可以为相同的查询生成自适应的负例。需要说明的是,在进行动态硬负例训练之前,需要对模型进行(即BM25和文献[98]中的STAR训练方法)预热。为了更好地理解静态和动态负例的效果,我们大致可以采取对抗的视角来说明它们的区别:对于给定的查询,静态方法在训练(即固定生成器)时使用固定的负例,而动态方法根据正在优化的检索器(即自适应生成器)生成自适应的负例。直观上,动态硬负例对稠密检索器(即,判别器)的训练更有信息量。此外,考虑到大规模的文本语料,动态负例可以潜在地缓解候选空间中的训练-测试差异,因为它可以在训练过程中"看到"更多的信息型负例。
**去噪的硬负例。**负例在稠密检索器的训练中起着关键作用,研究发现稠密检索器实际上对负例的质量很敏感[36],[114]。当采样文本中含有噪声负例时,它们往往会影响检索性能。**对于硬负例来说,这个问题变得更加严重,因为它们更有可能是假负例[74],[214],[215] (也就是说,未标注的正例),因为它们是与查询相关度高的排名第一的检索结果。**为了解决这个问题,Rocket QA [36]提出了一种去噪的负例选择方法,**它利用一个训练好的交叉编码器来过滤排名靠前的可能是假负例文本。由于交叉编码器架构在捕获丰富的语义交互方面更有优势,因此可以利用它从双编码器中精选出硬负例。**给定通过双编码器检索到的排名靠前的文本,仅保留由交叉编码器以置信度评分预测的负例作为最终的硬负例。这样,原本选择的负例就被去噪了,更可靠地用于训练。最近,SimANS [216]提出对排序在正例附近的歧义负例进行采样,这些负例与查询具有适度相似性(既不太难,也不太容易)。他们实证表明,这样的负例信息更丰富,更不可能是假负例。
引入的负例,其实是正例子,成为了噪声
5.2.4 负例采样效果的讨论
如前文所述,为了提高检索性能,发展了多种负例采样方法。在这里,我们对负例采样对稠密检索的影响进行了一些讨论。
研究表明,批内采样( 5.2 . 1节)不能产生足够多的信息性负例用于稠密检索[98],[104],[204]。特别地,Lu等[104]分析了为什么批内负例可能不包含信息性负例。他们把带有批内负例的负对数似然目标作为基于排序的噪声对比估计( NCE )的一个特例。批内采样不是从整个集合中采样一个负例,而是考虑一个相当小的集合(反映了不同的分布)进行采样,即查询集中与查询相关的注释文本。文献[98]也给出了关于批内负例信息含量的类似讨论:由于批次大小和信息性负例数量明显小于集合大小,从随机批次(或小批次)中采样信息性负例的概率趋近于零。此外,文献[98]的研究表明,从梯度范数收敛速度的角度来看,负例的信息性是训练稠密检索模型的关键。
此外,Zhan等[111]的研究表明,随机负例采样和硬负例采样确实优化了不同的检索目标:随机负例采样主要最小化总的成对误差,这可能过分强调了对困难查询的优化;相比之下,硬负例采样使靠前的成对误差最小化,更适合优化靠前排序。
在机器学习中,负例采样是一种常用的在大候选空间上进行优化的学习策略[217],[218],在文献中得到了广泛的研究。在这里,我们将讨论的范围限制为稠密检索。
5.3 数据增强
为了训练基于PLM的稠密检索器,相对于大量的模型参数,可用的相关性判断量通常是有限的。因此,提高(伪)相关性判断数据的可用性是很重要的。在本节中,我们讨论两种主要的数据增强方法:前者融合了额外的标注数据集,而后者通过知识蒸馏生成伪相关标记。
5.3.1 辅助标注数据集
一些研究提出纳入辅助标注数据集以丰富相关性判断。Karpukhin等人[1]收集了NQ [33]、Trivia QA [56]、WebQuestions [58]、TREC [59]和SQuAD [55] 等5个数据集,然后利用所有的训练数据(不包括SQuAD数据集)训练一个多数据集编码器,并在5个数据集的每个数据集上测试统一编码器。如文献[1]所示,大多数数据集上的性能收益得益于更多的训练样本,尤其是这5个数据集中最小的数据集。他们进一步进行了一项分析实验,只在NQ数据集上训练DPR,并在WebQuestions和CuratedTREC数据集上进行测试。实验结果表明,DPR在不同的数据集(专注于QA任务)上都有很好的迁移效果,并有轻微的性能损失。此外,Maillard等人[219]提出在多个检索任务中训练一个通用的稠密检索器。具体来说,他们设计了DPR的两个简单变体(变体1:用于多任务的独立查询编码器和共享段落编码器;变体2:用于多任务的共享查询和段落编码器),并通过多数据集训练来检测其通用检索能力。他们表明这样一个多任务训练的模型可以产生与任务特定的模型相当的性能,并且在少样本的情况下实现了更好的性能。
除了利用多个QA数据集,人们还可以利用不同类型的数据源。Oguz等人[107]通过利用文本、表格、列表和知识库等多种资源,提出了一种统一的开放域问答方法。其基本思想是将结构化的数据扁平化成文本,这样就可以将这些数据以统一的文本形式进行处理。如[107]所示,总的来说,在5个QA数据集上的实验中,在单数据集和多数据集上的实验中,结合多个数据源是有用的。
当目标任务没有训练数据时,就变成了零样本检索。在这种情况下,虽然我们可以利用辅助数据集来缓解数据的稀缺性,但需要注意的是,最终的性能受这些辅助数据集的影响很大[220]-[222] (详见8.1节)。
5.3.2 知识蒸馏
考虑到人工生成的相关性判断是有限的,知识蒸馏成为提高双编码器性能的重要方法。在机器学习中,知识蒸馏是指将知识从能力较强的模型(称为教师)转移到能力较弱的模型(称为学生)的过程[223]。遵循这一惯例,我们的目标是在给定的标注数据集上用更强大的模型(教师)改进标准的双编码器(学生)。
训练教师网络。为了实现教师网络,我们可以采用训练好的交叉编码器进行知识蒸馏,因为它更有能力建模跨查询和文本的细粒度语义交互。通常情况上下,教师网络的训练独立于学生网络的训练。作为一种改进的方法,RocketQA[36]在训练教师网络时,引入了一种整合教师和学生之间的信息交互的改进策略。其基本思想是从学生网络中随机抽取排名靠前的文本作为训练教师的负例。这种策略使得交叉编码器能够根据双编码器的检索结果进行调整。此外,采用分别用成对负例和批内负例训练的双教师来提高学生网络的检索性能[110]。进一步地,进行了一项实证研究[101]分析了用单个教师和教师集成进行知识蒸馏的有效性,并且发现随着单个教师或教师集成有效性的增加,知识蒸馏的效果会得到改善。同时,需要注意的是,教师网络并不一定是交叉编码器。原则上,任何比基础学生网络强的检索器都可以作为教师网络。例如,Lin等人[103]探索使用增强型双编码器(即使用延迟交互的ColBERT[95])作为教师网络的可能性。作为另一个有趣的工作,Yu等人[224]利用训练好的ad-hoc稠密检索器来改进对话式稠密检索器中的查询编码器,以便模仿相应的ad-hoc查询表示。
为学生网络蒸馏。在对教师网络进行训练后,我们利用其对学生网络进行改进。其基本思想是在无标签的(甚至有标签的)数据上运行训练好的教师网络,产生伪相关标签用于训练学生网络。根据衍生标签的类型,我们可以将蒸馏方法分为两大类,即硬标签蒸馏和软标签蒸馏。
硬标签蒸馏。在给定未标注文本的情况下,第一种方法直接根据教师网络的相关度分数为未标注文本设置二元相关度标签。由于教师网络的预测可能包含噪声或错误,通常采用阈值化方法去除置信度较低的文本。例如,RocketQA [36]根据排序分数为排名靠前的段落生成伪相关性标签:正例(高于0.9)和负例(低于0.1),并以不自信的预测丢弃其余段落。他们还人工检查了少量去噪后的文本,发现该方法通常对去除假负例或正例上是有效的。
软标签蒸馏。除了使用硬标签,我们还可以通过调整学生网络来近似教师网络的输出。形式上,设和分别表示文本d相对于由教师网络和学生网络分配的查询q的相关性分数。接下来,我们介绍几种蒸馏函数。
MSE损失。该函数使用均方误差损失直接最小化教师和学生之间的相关性分数之间的差值:
其中Q和D分别表示查询和文本的集合。
KL散度损失。该函数首先通过查询将候选文档的相关性得分归一化为概率分布,分别用和表示,然后降低它们的KL散度损失:
最大边际损失。该函数采用最大间隔损失来惩罚检索器产生的逆序:
式中:,,,为间隔,为符号函数,表示该值是正值、负值还是零。
Margin - MSE损失。该函数通过MSE损失,减小教师和学生之间正负样例对的差值:
为了检验不同蒸馏函数的有效性,Izacard等人[105]对上述损失函数进行了实证比较,发现对于问答任务,KL散度损失比MSE损失和最大边际损失具有更好的蒸馏性能。更进一步,研究人员通过实证发现Margin-MSE损失比其他选型更有效[101],[110],例如,逐点MSE损失。
先进的蒸馏方法。最近的研究[225]、[226]表明,当教师和学生模型之间存在较大的性能差距时,知识蒸馏可能会变得不那么有效。因此,在使用强教师模型时,应采用渐进式蒸馏方法[140]、[141]、[154],而不是直接蒸馏,这可以通过两种方式实现。作为第一种方式,我们在蒸馏的不同阶段使用逐渐增强的教师模型,以适合学生模型的学习。PROD [154]提出使用具有改进模型架构和增加网络层数的教师模型渐进链:12层双编码器→12层交叉编码器→24层交叉编码器(给定6层双编码器作为学生模型)。ERNIE-Search [141]引入了两种蒸馏机制来减少教师和学生模型之间的大性能差距,即( i )延迟交互模型(例如,ColBERT)到双编码器,( ii )交叉编码器到延迟交互模型再到双编码器。第二种方式固定强教师模型,逐步增加蒸馏知识的难度。CL-DRD [140]提出了一种课程学习方法,通过增加难度的方式对蒸馏过程进行调度:难度更大的样本在安排在稍后阶段 (具有较大的查询-文本相似度)。在上文中,我们假设教师模型在蒸馏过程中是固定不变的。Rocket QA-v2 [38]通过引入动态列表蒸馏机制对蒸馏方式进行了扩展:检索器(学生)和重排序器(教师)都是相互更新和改进的。基于KL散度损失(公式( 18 ) ),教师模型也可以根据学生模型进行调整,从而得到更好的蒸馏性能。
上述两种方法可以直接产生伪监督信号,用于微调底层PLM以进行密集检索。除此之外,还有其他与增强相关的稠密检索方法,如合成数据生成[116]、[227]、[228]和对比学习[132]、[229]、[230]等,这些方法更多地与预训练相关。我们在5.4节中对这些问题进行了讨论。
5.4 稠密检索模型的预训练
PLMs的最初目的是学习能够跨不同任务泛化的通用语义表示。然而,由于缺乏特定于任务的优化[92],[93],[127],[211],这类表示往往导致下游应用的性能次优。
考虑到这个问题,最近的研究采用任务相关的预训练策略进行稠密检索。除了减少预训练差异(问题2),这些方法还可以缓解有标注的相关性数据的稀缺性(问题3) (11)。下面,我们详细介绍稠密检索的预训练方法。
5.4.1 任务自适应预训练
这一系列预训练任务本质上遵循BERT [28]中使用的方法,但尝试以自监督的方式模仿检索任务。下面,我们列举了几个具有代表性的稠密检索预训练任务。
逆向完形填空任务(Inverse Cloze Task,ICT) [92]:ICT随机选择给定文本的一个句子作为查询,其余句子视为真实匹配文本。该任务旨在捕获句子的语义上下文,增强查询与相关上下文之间的匹配能力。
正文优先选择(Body First Selection,BFS) [93]:BFS利用维基百科文章的第一部分的句子作为锚,锚定到文本的其余部分。它将从第一节中随机抽取的句子作为查询,并将随后各节中随机抽取的段落作为匹配文本。
维基链接预测( Wiki Link Prediction,WLP ) [93]:WLP利用超链接将查询与文本相关联,其中从维基百科页面的第一个部分抽取的句子被认为是查询,从包含超链接链接的另一篇文章到查询页面的段落被认为是文本。
循环跨度检索(Recurring Span Retrieval,RSR) [127]:RSR提出使用循环跨度(即,在语料库中出现多次的ngram)关联相关段落,并进行无监督预训练进行稠密检索。给定一个循环跨度,它首先收集一个包含循环跨度的段落集合,然后将其中一个段落转化为查询,并将其余段落视为正例。
代表词预测(Representation wOrds Prediction,ROP ) [211]:ROP利用文档语言模型为给定文本采样一对词集。然后,一个可能性更高的词集被认为对文档更具有"代表性",并预训练PLM来预测两组词之间的成对偏好。继ROP之后,另一种变体B-ROP [231]用BERT模型代替unigram语言模型,从基于文档特定的和随机词分布构造的对比词分布中采样代表词。
5.4.2 生成增强预训练
尽管上述预训练任务可以在一定程度上提高检索性能,但它们仍然依赖于源自原始文本的自监督信号。考虑到这一问题,有几项研究提出直接生成用于检索任务的伪问题-文本对。特别地,这些数据生成方式可以分为两大类,要么是流水线方式,要么是端到端方式。
对于第一类问题,Alberti等人[227]提出一种从大型文本语料中构建问答对的流水线方法。它由答案抽取、问题生成和往返过滤三个主要阶段组成。实验结果表明,在合成数据上的预训练显著提高了SQuAD 2.0和NQ数据集上的问答性能。类似地,Lewis等人[228]进一步引入段落选择和全局过滤,构建了一个名为PAQ的问答数据集,该数据集包含来自维基百科的6500万个综合生成的问答对。基于PAQ数据集,一个相关研究[116]对双编码器检索器进行预训练,相比于ICT和BFS任务预训练的变体获得了一致的性能提升(第5.4.1节)。
不使用流水线的方式,Shakeri等人[232]提出了一种端到端的方法,通过使用预训练的LM (例如,BART)来生成基于机器阅读理解的问题答案对。它旨在训练一个序列到序列的网络,用于生成以输入文本为条件的一对问答。Reddy等人[234]进一步扩展了这种方法,通过引入额外的选择步骤来增强生成的问题-文本对用于检索任务。
此外,一些研究[99],[126],[234],[235]也探索了零样本场景下的生成增强的预训练方法,其中没有目标领域训练数据集。他们的结果表明,生成增强的预训练有助于提高稠密检索器的零样本检索能力。我们将在8.1节中进一步讨论零样本检索。
5.4.3 检索增强的预训练
为了增强PLMs的建模能力,另一行预训练任务是通过丰富相关上下文来整合外部检索器。基本思想是用来自知识检索器的更多参考上下文来增强掩盖语言建模(MLM)任务的训练。
作为代表性工作,REALM [ 94 ]用知识检索器从大型背景语料中检索相关文本,并对检索到的文本进行进一步的编码和关注,以增强语言模型预训练。在REALM中,其基本思想是根据检索到的上下文是否有助于提高掩盖词的预测,对检索者进行奖励或惩罚。在不使用显式人工标注的情况下,通过语言建模预训练进一步训练上下文检索器,其中检索到的文本通过边缘似然由一个潜变量建模。通过对模型的微调,REALM在开放域问答任务上表现良好。进一步提出采用基于最大内积搜索的异步优化方法。
作为扩展工作,Balachandran等人[236]在多种QA任务上对REALM进行了全面的调优。他们用多种训练技巧进行了广泛的实验,包括使用精确的向量相似性搜索,用更大的批次进行训练,为读者检索更多的文档,并将人类的注释用于证据段落。他们的实验表明REALM对于微调的训练不够充分,设计合适的训练和监督策略对于改进开放域问答系统具有重要意义。这一部分也与检索增强语言模型的主题相关,将在第8.4节进行讨论。
5.4.4 表示增强的预训练
对于基于双编码器的稠密检索器,一个典型的方法是利用插入的“[CLS]”token来获得查询或文本的表示。然而,原始的“[CLS]”嵌入并没有被明确地设计来表示整个文本的意义。因此,这可能导致次优的检索性能,需要更有效的方法增强“[CLS]”嵌入来进行稠密检索。
自编码器增强预训练。受自动编码器在数据表示学习中的成功[237],[240]的启发,一些研究探索使用自动编码器来增强文本表示以进行稠密检索。其基本思想是通过使用编码器网络将文本信息压缩到“[CLS]”嵌入中,然后使用配对解码器重构基于“[CLS]”嵌入的原始文本。通过这种方式,学习到的“[CLS]”嵌入在PLM中被强制以捕获比原始注意力机制更充分的文本语义。Gao等[112]提出了由早期编码器骨干层、晚期编码器骨干层和condenser头部层(仅在预训练时使用)三个有序部分组成的condenser架构。关键之处在于Condenser移除了晚期层和condenser头部层之间的全连接注意力,同时保持了早期层到冷凝器头部层的短路。由于凝聚器头层只能通过后期的“[CLS]”接收到后期主干层的信息,因此采用后期的“[CLS]”嵌入来尽可能聚合整个文本的信息,以恢复被掩盖的token。TSDAE [90]也做了类似的尝试,它是一种基于Transformer的序列去噪自编码器,用于增强文本表示。此外,co-Condenser [78]在检索语料的基础上,通过引入查询不相关的对比损失,将文本片段从同一文档中拉近,同时将其他不相关的片段推开,扩展了Condenser架构。遵循信息瓶颈原理[241],最近的研究[145],[152]将旨在捕获上述自编码器方法中所有重要语义的关键表示(例如,“[CLS]”嵌入)称为表示瓶颈。
基于非平衡自编码器的预训练。最近,Lu等[124]报道了一个有趣的发现,一个更强的解码器可能会导致自动编码器的序列表示更差。这被解释为旁路效应:当解码器较强时,它可能不参考编码器的信息表示,而是根据先前的token进行序列生成。它们提供对这一发现进行理论分析,并实现了一个基于浅层Transformer的弱解码器,限制了对先前上下文的访问。这样,它显式地增强了解码器对编码器的依赖性。这项工作启发了一些使用"强编码器,简单解码器"架构进行无监督文本表示预训练的研究。基于这种不平衡的体系结构,SimLM [145]使用替换语言建模预训练编码器和解码器,其目的是恢复替换后的原始token。为了优化稠密检索器,它进一步采用了多级训练过程,其中使用了硬负例训练和交叉编码器蒸馏。此外,RetroMAE [142]提出对解码器使用较大的掩码比例(50 ~ 90 %),而对编码器使用普通的掩码比例( 15 % )。它还引入了具有双流注意力和位置特定注意力掩码的增强解码机制。基于RetroMAE,Liu等[242]提出了一种严格的两阶段预训练方法(即通用语料库预训练和领域特定的继续预训练),在多种基准数据集上表现出较强的性能。此外,LexMAE [152]将这种表示增强的预训练策略应用于基于PLM的学习稀疏检索(例如,SPLADE),其中融入了基于词贷的表示瓶颈(即,具有学习到的术语权重的连续词袋表示)进行预训练。
对比学习增强了预训练。另一个有前景的方向是应用对比学习(无论是无监督还是有监督)来增强文本表示进行稠密检索。对比学习起源于计算机视觉领域(由SimCLR和MoCo的工作开创),其核心思想是通过拉近相似的图像来学习图像的表示,反之亦然。通常情况下,对比学习分两个主要步骤进行。首先,使用各种变换方法(例如,裁剪和旋转)为每幅图像生成增强视图。增强后的视图通常被认为是对原始图像的正例,而随机取样的实例则被认为是对原始图像的负例。这样的数据增广过程对对比学习的最终表现尤为重要。其次,设计一个辨别任务,假设正例应该比负例更接近原文。遵循同样的思路,我们可以生成大规模的正负文本对,用于文本嵌入的无监督预训练。作为代表性研究,SimCSE [229]通过应用不同的dropout掩码产生一个样本文本的正例,并使用批内负例。ConSERT [230]使用4种方式为文本生成不同的视图(即,正例),包括对抗攻击、token混排、cutoff和dropout。Contriever [130]提出使用ICT和裁剪(即从一个文本中抽取两个独立的跨度组成一个正例对)生成正例,使用批内和批间文本生成负例。实验结果表明,无监督对比预训练在零样本和少样本情况下都有良好的性能[130]。类似地,LaPraDoR [132]通过使用ICT和dropout生成正例,并提出了一种迭代对比学习方法,以替代的方式训练查询和文档编码器。与自编码器增强的预训练不同,Ma等人[139]进一步提出使用新的对比跨度预测任务预训练一个只包含编码器的网络,旨在充分降低解码器的旁路效应。它设计了分组对比损失,将文本的表征及其包含的跨度视为正例,将跨文本表征视为负例。此外,有研究表明无监督对比预训练[245] (使用文本对和文本-代码对进行预训练)也可以同时提高文本和代码检索性能。
讨论。与前面部分(第5.4.1、5.4.2和5.4.3节)中的预训练方法相比,表示增强的预训练并没有明确地使用检索(或类似检索)任务作为优化目标。相反,它旨在增强文本表示的信息性,即“[CLS]”嵌入。为了进行稠密检索,文本表示应该能够捕获整个文本的语义。通过设计有效的预训练策略(自编码器或对比学习),这些方法可以产生更多的信息文本表示,从而提高检索性能[78],[90],[124],[132],[145]。此外,研究表明,即使在零样本或低资源环境下,这些方法也可以提高检索性能[112],[130],[132],这也缓解了相关性判断的稀缺性问题。
5.5 RocketQA的实证性能分析
前文已经广泛讨论了各种优化技术,以改进稠密检索器的训练。本节以RocketQA [36]为研究模型,在基准数据集上考察不同优化技术如何提高其检索性能。
5.5.1 实验设置
为了准备我们的实验,我们采用了广泛使用的MS MARCO段落检索数据集[32]进行评估,该数据集的详细统计数据报告在表1中。
作为对比,我们考虑了RocketQA的两个变体,即RocketQA [36]和RocketQAV2 [38],以及一个相关的扩展RocketQAPAIR [37]。对于RocketQA,它使用了3个主要的训练技巧,即批间负例(第5.2.2节)、去噪硬负例(第5.2.3节)和基于蒸馏的数据增强(第5.3.2节)。对于RocketQAV2,它加入了一种新的软便签蒸馏机制,称为动态列表蒸馏(5.3.2)。对于RocketQAPAIR,它建立在RocketQA的基础上,并结合了以段落为中心的预训练技术(5.1.1节)。考虑到这些模型的可调配置(例如,负例数量和批次大小),我们包含了不同设置的多重比较。
虽然RocketQA变体没有包括第5节介绍的所有优化技术,但它们通过以相对公平的方式检查不同优化技术的效果,提供了一个统一的基本模型。作为对比,我们纳入了经典的BM25 [16]和DPR [1]方法作为基线。
为了复现本部分的实验,我们在https://github.com/PaddlePaddle/RocketQA链接上实现了一个用于稠密检索的代码库,并发布脚本或代码来复现表4中的结果。该代码库是基于PaddlePaddele实现的,包括RocketQA、RocketQAPAIR和RocketQAV2。为了进行公平的比较,我们用PaddlePaddele [246]库重新实现了DPR模型,并以ERNIE模型[176]作为基础PLM对其进行了增强。为简单起见,我们仅显示了重现表5中这些比较结果的关键命令或代码。
5.5.2 结果与分析
表4给出了不同方法或变体在MS MARCO数据集上针对段落检索任务的性能比较。我们有以下观察:
首先,批间技术能够提高检索性能。与DPRERNIE相比,RocketQA的变体2a~2g除了采用批间技术外,其余的配置和实现都是相同的。这种技术可以带来显著的改进,即在绝对MRR@10性能(变体1 v.s. 2a)中提高0.9个百分点。此外,我们可以看到,在批间训练过程中使用尽可能多的负例是关键,这意味着应该使用较大的批次大小。
其次,使用去噪硬负例是有效的,使绝对MRR@10性能(变体2a v.s. 2i)有3.1个百分点的显著提升。作为对比,当使用非去噪硬负例时,性能下降较快。一个可能的原因是硬负例更有可能是会损害最终性能的假负例。
第三,数据增强可以通过批间技术和去噪硬负例进一步提高检索性能,使绝对MRR@10性能(变体2i v.s. 2l)有0.6个百分点的大幅提升。此外,正如我们所看到的,性能随着伪标注数据量的增加而提高。
第四,以段落为中心的预训练可以提升性能,使绝对MRR@10性能(变体3a v.s. 3b)有0.7个百分点的大幅提升。该技术刻画了查询、正例文本和负例文本之间更全面的语义关系.
最后,采用动态列表蒸馏的变体(变体4e)在所有RocketQA变体中取得了最好的性能。动态列表蒸馏技术提供了一种基于软标签蒸馏(详见第7.2.3节)的检索器和重排序器的联合训练方法。
总结本部分的讨论可知,对于稠密检索器而言,有效的优化技术是获得良好检索性能的关键。
作者:小牛翻译NiuTrans https://www.bilibili.com/read/cv26592944/ 出处:bilibili