PyTorch学习记录
前面已经过了一边opencv的流程,但是opencv和PyTorch关系紧密,因此需要再过一遍PyTorch。
opencv流程已经总结在了这篇文章中
opencv学习记录(三)_追忆苔上雪的博客-CSDN博客
下面开始记录PyTorch学习过程
一.PyTorch框架
<1>PyTorch基本操作
PyTorch基本操作,包括创建矩阵,初始化矩阵,与Numpy协同操作等
import torch
import numpy as np
print(torch.__version__)
"""基本使用方法"""
# 创建一个5行三3列的矩阵
x = torch.empty(5, 3)
print(x)
# 创建一个随机值
y = torch.rand(5, 3)
print(y)
# 初始化一个全零的矩阵
x1 = torch.zeros(5, 3, dtype=torch.long)
print(x1)
# 直接传入数据
x2 = torch.tensor([5.5, 3])
print(x2)
# new_ones返回一个与size大小相同的用1填充的张量
x3 = x.new_ones(5, 3, dtype=torch.double)
print(x3)
# 创建一个与x3相似的矩阵
x4 = torch.randn_like(x3, dtype=torch.float)
print(x4)
# 展示矩阵的大小
print(x.size())
# 基本计算方法
# 加法,下面两种方法是一样的
print(x + y)
print(torch.add(x, y))
# 索引,x[:, 1]表示取x第二列所有数值
print(x[:, 1])
# view操作可以改变矩阵维度
# view()相当于reshape、resize,重新调整Tensor的形状。
x5 = torch.randn(4, 4)
y5 = x5.view(16)
# 注意,-1代表自动算,第二个维度有8个元素,自动计算第一个维度就是2个元素
z5 = x5.view(-1, 8)
print(x5.size(), y5.size(), z5.size())
# 与Numpy的协同操作
a = torch.ones(5) # torch.ones创建的是Tensor的格式
b = a.numpy() # 这样一转换就变成了Numpy可以支持的格式
print(b)
# 下面看看Numpy能不能转Tensor
c = np.ones(5)
d = torch.from_numpy(c)
print(d)<2>自动求导机制
PyTorch框架最厉害的就是帮我们把反向传播全部计算好了,如下图所述的例子
由于自动求导是自动计算的,所以代码很简单,这里要注意的就是:
在计算梯度之前,一定要先调用一下反向传播的算法!!!!!
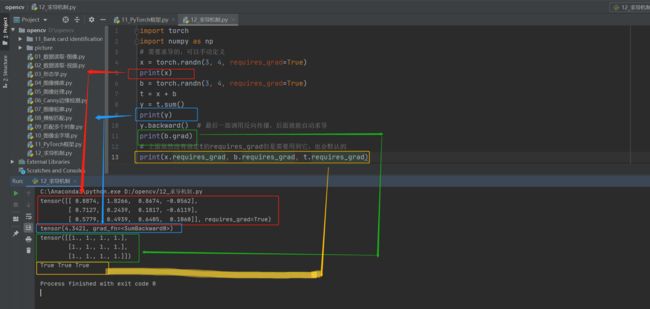
这里看一个例子
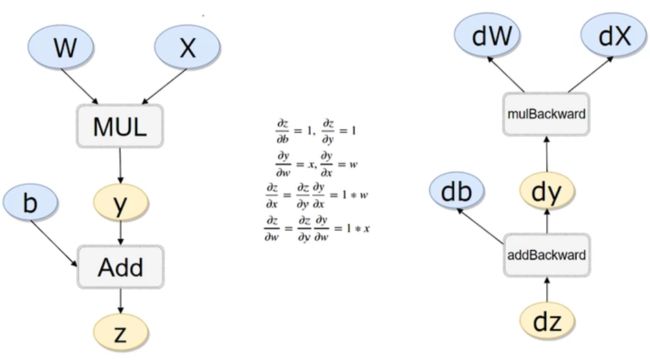
上图左侧
意思是w * x = y; y + b = z;
安装途中的公式,z对参数b和y的偏导是1,y对w和x的偏导分别是x和w
z对x的偏导按照链式法则来算,就能算出来是w,同理对w的偏导是x
用代码来实现上述功能
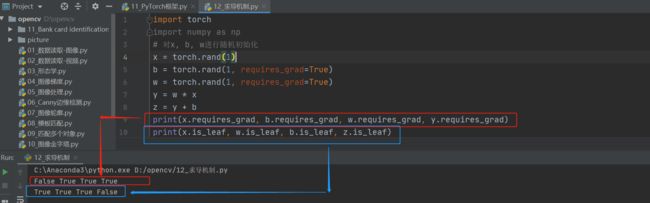
这里要拓展一下is_leaf( )和torch.randn和torch.rand的区别
- is_leaf( )函数
is_leaf —— 查看张量是否为叶张量
requires_grad控制变量是否需要计算梯度,is_leaf控制变量计算完梯度之后是直接清除还是会保留下来,在Pytorch中,默认情况下,非叶节点的梯度值在反向传播过程中使用完后就会被清除,不会被保留。只有叶节点的梯度值能够被保留下来。
- torch.randn和torch.rand的区别
两者主要区别在于数据服从的数据分布不同rand是均匀分布,randn是正态分布,n的意思是normal distribution。
<3>线性回归DEMO
import torch
import torch.nn as nn
import numpy as np
# 构造一组输入数据x和其对应的标签y
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
print(x_train.shape)
y_values = [2*i +1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
print(y_train.shape)
# 线性回归模型
# 其实线性回归就是一个不加激活函数的全连接层
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
out_put_dim = 1
model = LinearRegressionModel(input_dim, out_put_dim)
print(model)
# 指定好参数和损失函数
epochs = 1000
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
criterion = nn.MSELoss()
# 训练模型
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 向前传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch %50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
# 测试模型预测结果
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
print(predicted)
# 模型的保存与读取
torch.save(model.state_dict(), 'model.pkl')
model.load_state_dict(torch.load('model.pkl'))经常会看到类似于 [i for i in range(1,10)] 的表达式,这种表达式称为列表解析(List Comprehensions),类似的还有字典解析、集合解析等等。
列表解析式是将一个列表(实际上适用于任何可迭代对象)转换成另一个列表的工具。在转换过程中,可以指定元素必须符合一定的条件,才能添加至新的列表中,这样每个元素都可以按需要进行转换。
每个列表解析式都可以重写为 for 循环,但不是每个 for 循环都能重写为列表解析式,列表解析比 for 更精简,运行更快。
<4>Tensor常见的形式
0:scalar; 1:vector; 2:matrix; 3:n-dimensional tensor;
# Scalar通常是一个数值
# Vector 例如:[-5., 2., 0.]在深度学习中通常指特征,例如词向量特征 ,某一维度特征等
# Matrix一般计算的都是矩阵,通常都是多维的
import torch
from torch import tensor
# Scalar通常是一个数值
x = tensor(42.)
print(x, x.dim(), 2 * x, x.item())
# Vector 例如:[-5., 2., 0.]在深度学习中通常指特征,例如词向量特征 ,某一维度特征等
v = tensor([1.5, -0.5, 3.0])
print(v, '\n', v.dim(), '\n', v.size())
# Matrix一般计算的都是矩阵,通常都是多维的
M = tensor([[1., 2.], [3., 4.]])
print(M.matmul(M), '\n', tensor([1., 0.]).matmul(M), '\n', M * M)二 .搭建PyTorch神经网络进行气温预测
这里做一个案例先了解神经网络
<1>气温数据集与任务介绍
1.气温数据集
数据集是一个csv文件,打印一下数据集可以看到数据集的信息

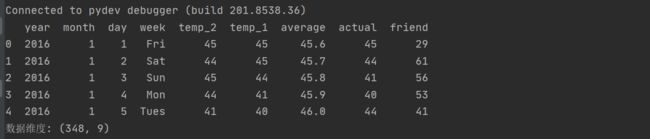
数据表中
*year, moth, day, week分别表示的具体的时间
*temp_2:前天的最高温度值
*temp_1:昨天的最高温度值
*average:在历史中,每年这一天的平均最高温度值
*actual:这就是我们的标签值了,当天的真实最高温度
*friend:这一列是凑热闹的,朋友猜测的可能值,咱们不管它就好了
相关代码解析
1.pd.read_csv()
使用pandas做数据处理的第一步就是读取数据,数据源可以来自于各种地方,csv文件便是其中之一。
2.Pandas中head( )函数
Pandas读取数据之后使用pandas的head()函数的时候,来观察一下读取的数据, head( )函数只能读取前五行数据
3.features.shape
打印数据维度: (348, 9),可以看见数据集有348天的气温数据,每个数据有9个特征
2.处理时间数据
后续可能对时间会有一些操作,但是直接对数据表的列操作不太方便,所以这里要对时间数据进行一些处理
这里把时间数据处理成一些标准格式,import datetime这个模块进行处理
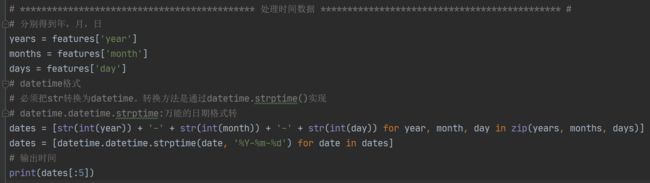
输出如下
![]()
相关代码解析
1.import datetime
datetime模块提供了五个常用类:date、time、datetime、timedelta、tzinfo,接下来对datetime进行说明。
datetime类可以看作date和time类的合体,其包含了这两个类中的全部参数,其中创建datetime类的类方法如下:
import datetime
print("现在的时间是:",datetime.datetime.today())
print("返回现在的时间是:",datetime.datetime.now())
print("当前UTC日期和时间是:",datetime.datetime.utcnow())
print("对应时间戳的日期和时间是:",datetime.datetime.fromtimestamp(1234567896))
print("对应UTC时间戳的日期和时间是:",datetime.datetime.utcfromtimestamp(1234567896))
print("公历序列对应的日期和时间是:",datetime.datetime.fromordinal(1))
print("日期和时间的合体为:",datetime.datetime.combine(datetime.date(2020, 8, 31), datetime.time(12, 12, 12)))输出结果如下

2.datetime.datetime.strptime()

datetime.datetime.strptime:万能的日期格式转换,根据指定的格式把一个时间字符串解析为时间元组。
这里说了字符串和格式类似于time.stiptime()

python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00-59)
%S 秒(00-59)
<2>准备画图
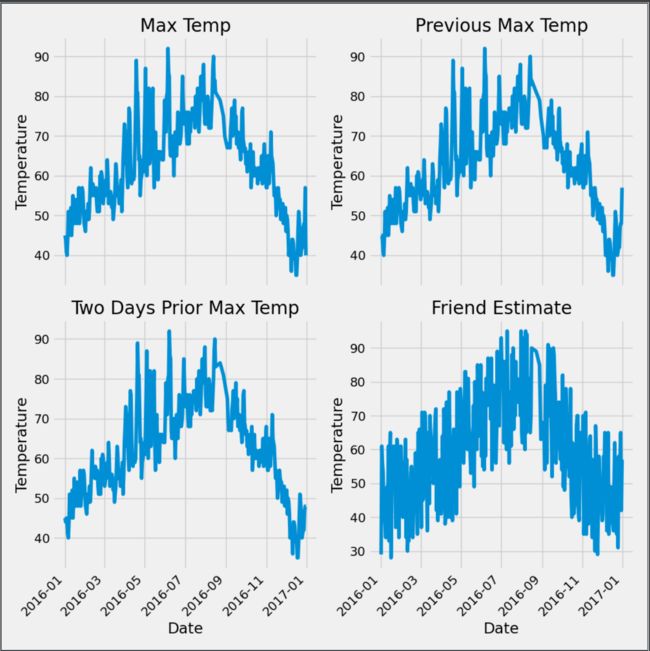
画图看一下数据分布
# 准备画图,指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))
# x轴上旋转45度并且右对齐
fig.autofmt_xdate(rotation=45)
# 标签值 第一幅图
ax1.plot(dates, features['actual'])
ax1.set_xlabel('')
ax1.set_ylabel('Temperature')
ax1.set_title('Max Temp')
# 昨天 第二幅图
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel('')
ax2.set_ylabel('Temperature')
ax2.set_title('Previous Max Temp')
# 前天 第三幅图
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date')
ax3.set_ylabel('Temperature')
ax3.set_title('Two Days Prior Max Temp')
# 朋友 第四幅图
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date')
ax4.set_ylabel('Temperature')
ax4.set_title('Friend Estimate')
# 自动调整子图参数,使之填充整个图像区域,这是个实验特性,可能在一些情况下不工作,它仅仅检查坐标轴标签,刻度标签以及标题的部分
plt.tight_layout(pad=2)
# 显示图片
plt.show()
# 独热编码
features = pd.get_dummies(features)
print(features.head(5))输出结果图如下
这里输出数据有个问题,就是Pycharm输出窗口有省略号,数据显示不全

解决办法就是借助pandas库来控制窗口的显示:

"display.max_rows"是设置输出窗口显示的最多行数,超过则将多余数据用省略号表示;
"display.max_columns"是设置输出窗口显示的最多列数,超过则将多余的列用省略号表示;
"display.width"是设置输出窗口显示的最大宽度,如果一行数据的宽度多余所设置的最大宽度会将多余的列数据换行显示。
重新设置后如下:

相关代码解析
1.plt.style.use('fivethirtyeight')
用Python里的Matplotlib库画出的分析图可能往往如下图所示:它看起来很普通
然而,我们只要稍稍调整一下风格,它立刻就变成:
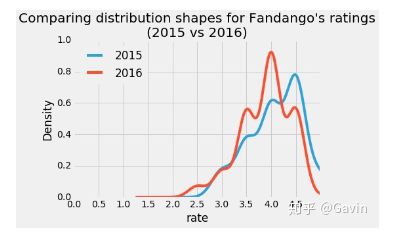
这里我们用的是经典的fivethirtyeight 风格,所需的代码很简单,只需加上一行:
plt.style.use('fivethirtyeight')
fivethirtyeight 是matplotlib众多风格的一种,我们可以通过以下代码查看各种风格;
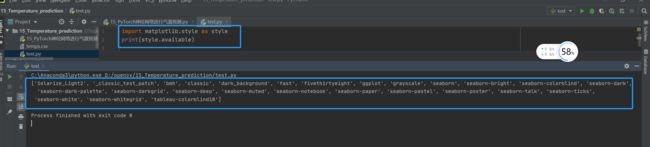
2.get_dummies 是 pandas 实现one hot encode的方式。
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。

<3>处理数据
处理数据:设置标签与特征,标准化之后数据收敛会更快一些
观察数据,有些特征的数据数值很大有些则很小,我们需要做标准化。从机器学习的学习得知,我们可以利用sklearn的库来进行标准化。
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features = features.drop('actual', axis=1)
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
# 转换成合适的格式
features = np.array(features)
print(features.shape)
input_features = preprocessing.StandardScaler().fit_transform(features)
print(input_features[0])相关代码解析
1.input_features = preprocessing.StandardScaler().fit_transform(features)
在机器学习的sklearn.preprocessing中,当需要对训练和测试数据进行标准化时,使用两个不同的函数
- 训练数据,采用fit_transform()函数
- 测试数据,采用tansform()函数
<4>构建网络模型
相关功能注释已经在代码中体现,因此后面只会对一些特别的代码进行展开
# 需要将输出到网络模型中的数据转换为网络能接受的张量格式
# 将array转为张量
x = torch.tensor(input_features, dtype=float)
y = torch.tensor(labels, dtype = float)
# 我们打算搭建具有一个隐藏层的多层感知机,为此,我们设定两个线性模型及参数,并且随机初始化它们。
# 观察训练集的特征为14,所以输出层的w必须是(14,m),其中m我随意指定为128,意为将14个输入特征转化为隐藏层的128个隐藏特征。
# 由矩阵相乘知识可以得出的是348×128的矩阵,所以我们的biases指定为(128×1)。隐藏层同理
# 权重参数初始化
weights = torch.randn((14, 128), dtype = float, requires_grad = True) # 权重参数1
biases = torch.randn(128, dtype = float, requires_grad = True) # 偏置参数1
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True) # 权重参数2
biases2 = torch.randn(1, dtype = float, requires_grad = True) # 偏置参数2
# 指定学习率和存放每次计算所得损失的列表
learning_rate = 0.001
losses = []
# 对网络模型进行梯度下降
# 指定梯度下降次数1000次
for i in range(1000):
# 计算隐藏层-线性模型
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果计算,输出值
predictions = hidden.mm(weights2) + biases2
# 计算损失-平方损失函数
loss = torch.mean((predictions - y) ** 2)
# 将每次的损失转换成numpy格式并添加到损失列表中
losses.append(loss.data.numpy())
# 打印损失值
if i % 100 == 0:
print('loss:', loss)
# 返向传播计算
loss.backward()
# 更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
# 每次迭代后清空梯度
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
print(predictions.shape)相关代码解析
1.torch.randn((14, 128), dtype = float, requires_grad = True)
表示将输入的14个特征转化为128个隐层的特征。
输出结果如下
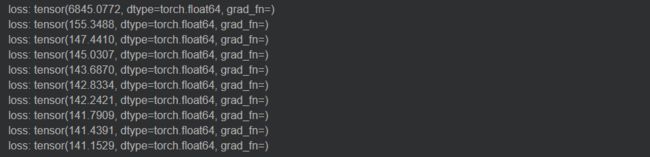
<5>简化神经网络模型
我们前面“基本上”是从零搭建了神经网络模型。而事实上,torch为我们提供了丰富的API帮我们实现神经网络,我们试着再一次实现。
# **************************************** 简化实现神经网络模型 **************************************** #
"""
前面“基本上”是从零搭建了神经网络模型。而事实上,torch为我们提供了丰富的API帮我们实现神经网络,我们试着再一次实现。
"""
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr=0.001)
# *************************************************************************************************** #输出结果如下

<6>构建训练网络和预测训练结果
我们可以尝试用下面的代码去评估,代码较复杂,复制下去跑出看看效果即可
# ******************************************* 训练网络 ********************************************** #
losses = []
for i in range(1000):
batch_loss = []
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype=torch.float, requires_grad=True)
yy = torch.tensor(labels[start:end], dtype=torch.float, requires_grad=True)
prediction = my_nn(xx)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100 == 0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
# *************************************************************************************************** #
# ******************************************* 预测训练结果 ********************************************* #
x = torch.tensor(input_features, dtype=torch.float)
predict = my_nn(x).data.numpy()
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data={'date': dates, 'actual': labels})
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in
zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data={'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
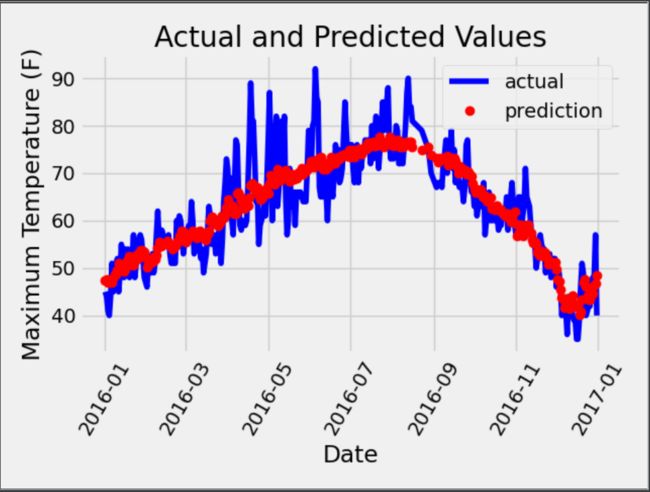
plt.plot(true_data['date'], true_data['actual'], 'b-', label='actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label='prediction')
plt.xticks(rotation='60')
plt.legend()
# 图名
plt.xlabel('Date')
plt.ylabel('Maximum Temperature (F)')
plt.title('Actual and Predicted Values')输出结果如下