一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
提示:文章目录
文章目录
- 一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
- 基于用户的协同过滤(UserCF)
- user cf具体怎么做?
- 上面那个sim(user,userj)怎么求?计算两个用户之间的相似度
- 上面求sim的公式有个不足之处:
- user cf用于召回的完整流程
- 总结
基于用户的协同过滤(UserCF)
学习本文之前,你务必把基于物品的协同过滤搞清楚:
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
然后你才能轻松理解,其实基于用户的协同过滤,两者本质一样
我们继续学习推荐系统链路上的召回环节,
本文要讲的方法叫做基于用户的协同过滤,简称user cf,
它跟前面介绍的items cf有很多相似之处,
当时我讲Item cf是基于物品之间的相似性做推荐,
而User cf是基于用户之间的相似性做推荐,
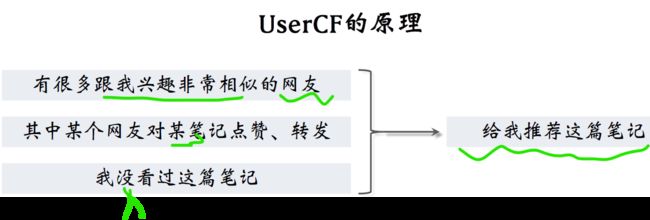
首先解释user cf的原理,作为小红书的用户,我在小红书的点击、点赞、收藏、转发可以体现出我的兴趣爱好。
小红书上至少有几百个跟我兴趣爱好非常相似的网友,
虽然我不认识这些网友,但是小红书可以从大数据中挖掘出来。
小红书知道我们的兴趣爱好非常相似,
今天其中某个跟我兴趣非常相似的网友看了篇笔记,他很感兴趣对笔记点赞转发。
于是小红书就知道他喜欢这篇笔记,而我还没有看过这篇笔记。
那么推荐系统就有可能给我推荐这篇笔记,
推荐的理由就是跟我兴趣爱好相似的网友喜欢这篇笔记。
推荐系统如何找到跟我兴趣非常相似的网友?
一种办法是判断两个人感兴趣的笔记有多少重合,
每个用户都有一个列表,上面存储的点击、点赞、收藏、转发的笔记ID,
对比两个用户的列表,就知道有多大的重合,重合越多,说明两个人的兴趣越相似。

另一种类似的办法不是看笔记的重合,而是看作者的重合。
每个用户都会关注一些作者,对比两个用户关注的作者列表,就知道有多少关注的作者是重合的,
关注的作者重合越多,说明两个人的兴趣越相似。
user cf具体怎么做?
在用user cf做推荐之前,需要先离线算好每两个用户之间的相似度。
计算相似度的方法稍后再讲。
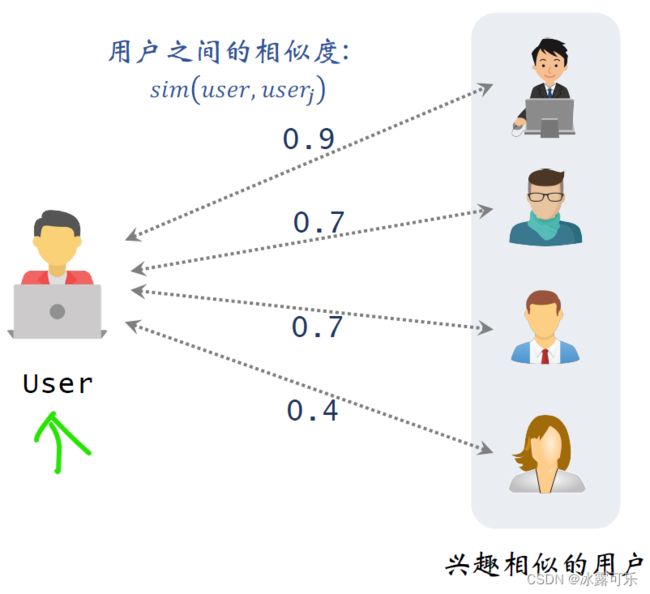
在这个例子中,我们想要给左边的用户做推荐,右边是最相似的四个用户,这些分数表示用户之间的相似度,数值越大表示用户越相似。

最右边是候选物品【这个物品当然是相似用户们看过的】,左边的用户还没有看过这个候选物品。
我们想要预估左边的用户对右边的候选物品的兴趣有多大?
历史数据反映了中间这些跟我相似的用户对物品item的兴趣。
比如点击、点赞、收藏、转发这四种行为各算一分,
不妨设四位用户对候选物品的兴趣分数分别是0,1,3,0,分数越大表示用户对物品越感兴趣,
0表示用户没有看过物品或者对物品不感兴趣,
用下面这个公式来预估用户对候选物品的兴趣,
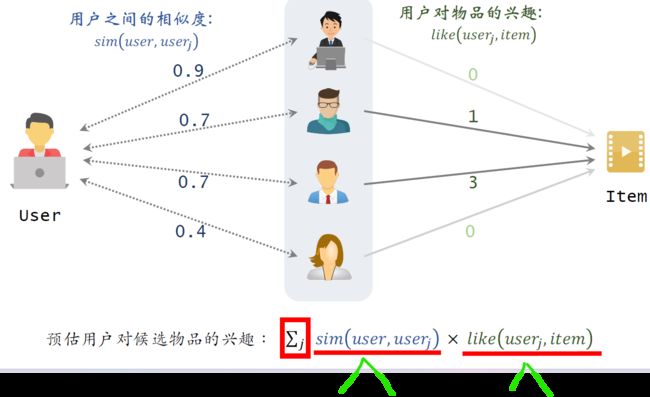
sim(user,userj)这一项是左边用户user与userj这个用户之间的相似度。
我user和其他四个相似度也就是图中左边的分数,0.9,0.7,0.7,0.4,
like(userj,item)这一项是第j这个用户对候选物品item的兴趣,
也就是图中右边的分数:0,1,3,0
把各个相似度和兴趣分数相乘,再把所有的乘积都加起来,
得到总分rate,表示用户对候选物品的兴趣。
在这个例子中,从左边用户到右边的候选物品有四条路径,所以要计算四个分数,然后把它们相加。
计算0.9乘以零
加0.7乘以1
加0.7乘以3
加0.4乘以零,
这里的0.9,0.7,0.7,0.4是左边用户与中间四个用户之间的相似度,
0,1,3,0表示四个用户对右边候选物品的兴趣,
四个分数相加等于2.8,表示左边用户对候选物品的兴趣。【1–5之间的分数的胡啊,2.8算中下等级别的喜欢程度】
举个例子,有2000个候选物品,
我们逐一计算用户user对候选物品item们的兴趣分数,
然后返回其中分数最高的100个物品,就是咱们召回推荐的结果
上面那个sim(user,userj)怎么求?计算两个用户之间的相似度
这里的相似度指的是用户有共同的兴趣点。
跟那个物品之间的相似度非常非常像,当时讲物品的相似度就是用户共同的特性,尤其是从喜欢他们的用户交集出发看相似性
再看用户也很类似,就看用户都喜欢过哪些物品,看看物品有没有交集?这样就能得到用户的相似度
因此,求物品相似度,看喜欢这些物品的用户的状况
反之,求用户相似度,看用户喜欢过的物品的状况
我先举例说明什么样的用户相似或者不相似。

这个例子中的两个用户不相似,他们喜欢的物品没有重合。
这个例子中的两个用户被判定为相似,
这是因为两个用户喜欢的物品重合度非常高,他们的兴趣点相似,

两个用户的相似度是这样计算的,
把用户U1喜欢的物品记作集合J1
把用户U2喜欢的物品记作集合J2
把集合J1 J2的交集记作集合I,集合大I包含两个用户共同喜欢的物品。

用这个公式计算用户U1 u2的相似度
公式中的分子是集合大I的大小,代表这两个用户共同喜欢的物品的个数,
分母是结合J1 J2大小的乘积取根号,这样计算出的相似度是介于零到一之间的数,数值越接近1表示两个用户越相似。
上面求sim的公式有个不足之处:
公式同等对待热门和冷门的物品,这是不对的。

拿书籍推荐举个例子,哈利波特是非常热门的物品,不论是大学教授还是中学生都喜欢看哈利波特。
既然所有人都喜欢看哈利波特,那么哈利波特对于计算用户相似度是没有价值的。
越热门的物品越无法反映出用户独特的兴趣,对计算相似度就没有用。
反过来,重合的物品越冷门越能反映出用户的兴趣。
如果两个用户都喜欢deep learning这本书,说明两个人很可能是同行。
如果两个用户都喜欢更冷门一些的书,比如深度学习在语音识别中的应用,说明两个人是小同行。
为了更好的计算用户兴趣的相似度,我们需要降低热门物品的权重,
前面计算用户相似度的公式可以等价改写成这种形式,

这里的分子还是集合I的大小,只不过换了种写法,写成了对一的连加。
连加符号中的字母小L是物品的序号,
连加中的一是物品的权重,所有物品的权重都相同,
不论是冷门还是热门物品,权重都是一。【显然这不合理】
刚才我们讨论了物品的重要性,应该跟热门程度相关,越热门的物品权重应该越低,
因此,我们把分子中的1换成1除以log(1+nl)

就是标为红色的那一项。
公式中的其他部分没有变,1除以log(1+nl)表示物品的权重,
nl是喜欢物品l的用户数量,反映物品的热门程度。
喜欢哈利波特的人数很多,nl自然就会很大,物品越热门,
nl越大,1除以log(1+nl)就越小,也就是说物品的权重越小。
这样一来,哈利波特对相思路的贡献就会很小,
同理,而冷门物品的贡献会比较大。
懂?
小结一下前面讲的内容,User cf的基本思想是根据用户的相似度做推荐,
如果用户1跟用户2相似,而且用户2喜欢某物品,那么用户1也很可能喜欢这个物品。
用user cf做召回的时候,需要预估用户user对物品item的兴趣分数rate,选出分数最高的物品做推荐。

预估兴趣分数要用这个公式,我们找到跟用户user最相似的若干个用户记作userj,
用sim表示两个用户之间的相似度,这个相似度是事先在线下算好的,
我们还知道用户userjJ对物品items的兴趣,记作like,
把sim和like个数值相乘,然后关于用户J去连加,
作为用户user对候选物品items的兴趣分数的预估,
这个公式需要知道每两个用户之间的相似度,我们会事先计算用户两两之间的相似度并保存起来。
我们这样计算两个用户之间的相似度,把每个用户表示为一个稀疏向量,
向量每个元素对应一个物品,如果用户对该物品不感兴趣,元素就是零,如果感兴趣,元素就是一或者是一除以物品的热门程度。
相似度sim函数就是两个向量夹角的余弦。
user cf用于召回的完整流程
我已经讲完了user cf的数学原理,
最后过一遍user cf用于召回的完整流程。
为了能在线上做到实时的推荐,系统必须要事先做离线计算,建立两个索引。
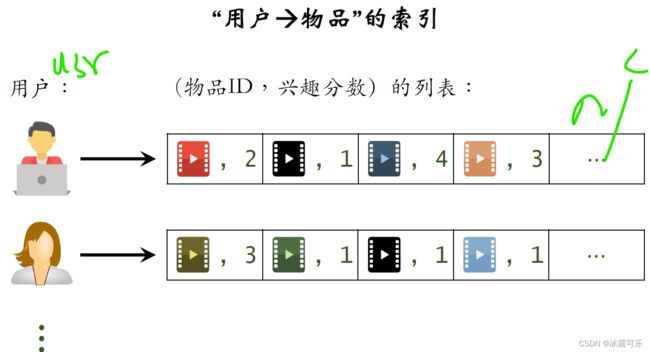
一个索引是用户到物品索引,记录每个用户最近点击过和交互过的物品ID,以及记录用户对物品的兴趣分数。
前面课程讲item cf的时候用到了相同的索引,所以这里我就不细讲了,

另一个索引是用户到用户的索引,这跟item cf不同,
item cf用的是物品到物品的索引,
这里用的是用户到用户的索引,

当然了,建立索引的方法跟item cf几乎相同,
对于每个用户索引它最相似的K个用户,比如K等于十或者100,这个计算量会比较大,
有了这个用户到用户的索引之后。
给定任意用户ID,可以快速找到它最相似的K个用户,而且知道用户相似度的分数。
这个是用户到物品的索引,跟item cf用的索引完全相同。这里我就不多解释了,
给定用户ID,可以取回他最感兴趣的物品的列表,以及兴趣分数。
另一个索引是用户到用户的索引,索引的key值是用户的ID索引,
记录每个用户最相似的K个用户的ID和相似度分数。

上面这些是第一个用户最相似的cake用户的列表,其中分数,0.7,0.6,0.6,0.3,0.3,表示相似度从高到低排列。
下面这些是第二个用户最相似的k个用户的列表,也记录了用户的ID和相似度。
给定任意一个用户的ID,用这个索引可以快速找到它最相似的k个用户。
有了索引之后,我们可以在线上给用户做实时推荐,

比如现在有个用户刷小红书,系统要开始做推荐,系统知道这个用户的ID,
首先用用户到用户的索引,快速找到与这位用户最相似的K的用户。
对于这K的用户,利用用户到物品的索引,找到他每个人近期感兴趣的物品的列表,也就是用户的last an物品
有了K的相似用户,每个用户有N个物品。
那么一共取回了N乘以K的物品,对于取回的N乘以K的物品,
用公式预估用户对物品的兴趣分数rate,
按照分数从高到低对物品做排序,
返回分数最高的100个物品作为召回的结果。
这100个物品就是user cf这个召回通道的输出。
最后我演示一下user cf做召回的流程。
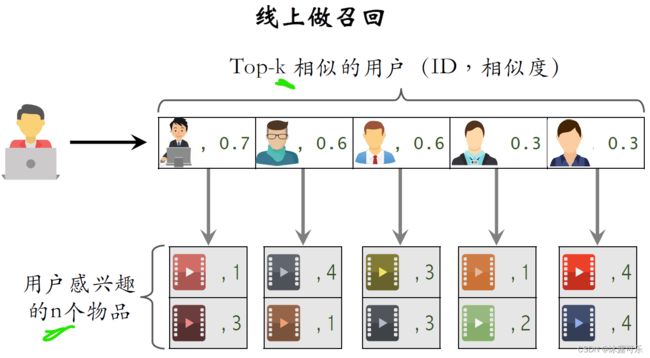
用户刷小红书之后,系统要给这位用户做推荐,知道用户的ID,
利用用户到用户的索引找到最相似的k个用户,取回列表中记录的top k的用户的ID和相似度。
接下来,我们要利用用户到物品的索引,找到每个用户近期感兴趣的物品,
知道这个用户的ID,取回他近期感兴趣的物品。
我们把这些物品叫做last n,
这些就是用户最近感兴趣的物品的ID和兴趣分数。
在这个例子中,n等于2
用同样的方法,根据用户到物品的索引,找到其他的每个用户近期感兴趣的物品,
一共用了k相似用户,每个用户最多有N个感兴趣的物品,
因此会取回N乘以k个物品,
用前面介绍过的公式计算用户对这N乘以k物品的兴趣分数rate。
根据算出的兴趣分数rate做排序,返回排在前100的物品,
也就是说,从这N乘以K物品中选出100个作为user cf的召回结果。
做计算的时候需要用到这些列表中的数值,

用到上面列表中用户之间的相似度,
用到下面列表中用户对物品的兴趣分数,
把上面的相似度跟下面的兴趣分数相乘,得到预估的兴趣分数rate。
如果取回的物品有重复的就做,去重把分数加起来。
用这种方法做召回,在线上做计算的速度非常快
okay,最后总结一下文本的内容。
user cf的原理是这样的,如果用户U1跟用户U22个人的兴趣相似,而且U2喜欢某物品,那么,U1也可能喜欢该物品
用户的相似度是根据交互过的物品来定的。
如果用户U1和U2喜欢的物品有很大的重叠,
那么,用户U1和U2很显然有相似的兴趣爱好。

具体是用这个公式计算用户U1和U2的相似度分子是两个用户共同喜欢的物品的数量,也就是集合J1和J2的交集。
分母式做归一化,让相似度分数介于零到一之间。
在工业界的推荐系统中,Item CF和user CF都是主要的召回通道
为了在线上做非常快速的召回,需要离线维护两个索引,
一个索引是从用户到物品列表,记录了每个用户近期交互过的N个物品,
另一个索引是从用户到用户列表,记录了每个用户像素最高的K个用户
在线上做召回的时候要用到这两个索引,每次取回N乘以K个物品。

取回之后还要做个筛选,只保留分数最高的那一小部分物品。
user cf用这个公式预估用户对每个物品的兴趣分数。
这个公式用到了用户与用户的相似度和用户对物品的兴趣分数。
两种分数分别记录在两个索引上,用公式给物品打分,
返回分数最高的100个物品作为user cf最终的召回结果
user cf的内容就讲到这里,相比你已经熟悉了!
item cf和user cf非常相似
item cf就是根据物品是否相似来决定推荐item给user与否?
user cf就是根据用户是否相似来决定推荐item给user与否?
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:因此,求物品相似度,看喜欢这些物品的用户的状况,反之,求用户相似度,看用户喜欢过的物品的状况;越热门的物品越无法反映出用户独特的兴趣,对计算相似度就没有用;item cf和user cf非常相似,item cf就是根据物品是否相似来决定推荐item给user与否?user cf就是根据用户是否相似来决定推荐item给user与否?