硬件加速器及其深度神经网络模型的性能指标理解
前言:
现如今,深度神经网络模型和硬件加速器,如GPU、TPU等的关系可谓是“不分彼此”,随着模型参数的增加,硬件加速器成为了训练、推理深度神经网络不可或缺的一个工具,而近年来硬件加速器的发展也得益于加速人工智能模型的训练和推理。作为在人工智能领域最重要的两个基件,即模型(算法)和硬件(算力)(人工智能三个核心要素:算法、算力、数据),我们有必要去理解每种基件的评价指标以及指标的意义,才能在应用的过程中去选择适合的模型和硬件!
本文主要介绍GPU的性能指标以及深度神经网络模型的性能指标,让你首先对各种性能指标有一个理解,下面贴上目录,根据需要自行跳转哈。
目录
单位换算
GPU指标/性能指标
GPU基础时钟频率 (Base Clock)
GPU加速时钟频率 (Boost Clock)
显存容量(VRAM Capacity)
显存带宽(Memory Bandwidth)
流处理器簇(Streaming Multiprocessors,SMs)
CUDA 核心数量(CUDA Cores)
FP32/FP64/INT32 Cores:
张量核心(Tensor Cores)
TDP (Thermal Design Power)/TGP (Total Graphics Power)
计算速度(FLOPS)
eg. 以A100为例说明参数
深度神经网络性能指标
准确性(Accuracy)
损失(Loss)
模型参数量(Params)
模型计算量(FLOPs、MACs)
训练速度(Training Speed)
推理速度(Inference Speed)
易混指标对比
FLOPS和FLOPs(名称易混)
Params和FLOPs(理解易混)
模型的参数数量与储存大小
单位换算
在性能指标中,通常会使用一些单位换算,先做以说明:
| K(千) | M(百万) | G(十亿) | T(万亿) | P(千亿) | E(百京) |
| 10^3 | 10^6 | 10^9 | 10^12 | 10^15 | 10^18 |
GPU指标/性能指标
GPU性能通常由多个指标来衡量,这些指标可以帮助我们了解GPU的性能水平和适用领域。以下是一些常见的GPU性能指标:
GPU基础时钟频率 (Base Clock)
基本时钟频率是GPU核心的最低工作时钟频率,通常以兆赫兹(MHz) 或千兆赫兹 (GHz)表示。这是GPU在正常工作负载下的最低工作频率,用于处理轻度任务和节能。
GPU加速时钟频率 (Boost Clock)
加速时钟频率是GPU核心能够自动达到的最高工作时钟频率,通常也以兆赫兹 (MHz) 或千兆赫兹(GHz)表示。当GPU需要更多性能以处理复杂任务时它会自动提高时钟频率,以提供额外的计算能力。
Boost Clock的存在允许GPU在需要时提供更大的计算性能,而在轻负载情况下降低时钟频率以降低功耗和温度。这种动态时钟管理可以在不浪费能源的情况下实现更好的性能。
显存容量(VRAM Capacity)
显存容量是GPU用于存储图像和计算数据的内存大小。更大的显存容量适用于处理大型数据集和复杂的深度学习模型。
显存带宽(Memory Bandwidth)
显存带宽是GPU内存与GPU核心之间数据传输的速度,通常以千兆字节每秒(GB/s) 表示。高带宽有助于高速数据传输,提高了计算性能。
流处理器簇(Streaming Multiprocessors,SMs)
GPU SMs 是NVIDIA GPU架构中的关键组成部分,它们用于执行并行计算任务。SMs是一种多用途的硬件单元,每个SM包含多个CUDA核心、寄存器文件和共享内存等资源,用于处理并发工作负载。
以下是有关GPU SMs的一些特点和说明:
- CUDA核心:每个SM包含多个CUDA核心,这些核心可以同时执行多个线程。不同的GPU型号有不同数量的SMs和CUDA核心,从而影响了GPU的总计算能力。
- 寄存器文件:每个SM包含一个寄存器文件,用于存储线程的本地数据和中间结果。这些寄存器用于执行计算任务,但数量是有限的,因此开发者需要优化代码以最大程度地减小寄存器使用。
- 共享内存:SMs还包含共享内存,它是一种高速的内存,可用于线程之间的通信和协作。共享内存对于一些计算任务的性能至关重要。
- 调度和执行:SMs负责调度线程块(Thread Blocks)的执行。线程块是一组线程的集合,它们可以协作执行任务。SMs会将线程块分配给CUDA核心,以便并行执行任务。
- 并行性级别:不同GPU型号具有不同数量的SMs,每个SM又包含不同数量的CUDA核心。因此,GPU的并行性级别取决于SMs的数量和CUDA核心的数量。更多的SMs和CUDA核心通常意味着更高的并行计算性能。
我们可以使用NVIDIA的CUDA编程模型来利用GPU SMs,将计算任务并行化以提高性能。通过合理利用CUDA核心、寄存器文件和共享内存等资源,可以实现高效的GPU并行计算。
CUDA 核心数量(CUDA Cores)
CUDA核心是GPU上的计算单元,它们执行并行计算任务,不仅限于图形处理。每个CUDA核心可以执行一些特定的计算操作,如浮点数运算、整数运算,更多核心通常意味着更高的并行计算能力,有助于处理大规模并行计算任务。
以下是有关CUDA核心的一些特点:
- 并行性:CUDA核心是为并行计算而设计的。一块GPU通常包含数百到数千个CUDA核心,这使得GPU非常适合高度并行化的工作负载,如深度学习、科学计算和密码学等。
- 单指令多线程(SIMT):CUDA核心采用了单指令多线程的执行模型,这意味着它们可以同时执行多个线程,每个线程都执行相同的指令,但可以处理不同的数据。这有助于提高计算效率。
- 数据类型支持:CUDA核心支持多种数据类型,包括单精度浮点数、双精度浮点数、整数等,这使得GPU在不同类型的计算任务中都具有广泛的应用。
- 并行性级别:NVIDIA的GPU通常有不同的架构和型号,每种型号的CUDA核心数量和性能都会有所不同。更高端的GPU通常包含更多的CUDA核心,从而具有更高的计算性能。
CUDA核心的存在使得GPU成为了强大的通用计算设备,可以用于加速各种科学和工程计算任务。我们可以使用CUDA编程模型来利用这些核心,将计算任务并行化以提高性能。
FP32/FP64/INT32 Cores:
GPU(图形处理单元)通常包含不同类型的核心,以执行不同类型的计算任务。其中,FP32(单精度浮点数)核心、FP64(双精度浮点数)核心和INT32(整数)核心是常见的核心类型。它们在执行不同类型的计算时具有不同的性能和精度。
- FP32 Cores(单精度浮点数核心):这些核心主要用于执行单精度浮点数计算,通常用于图形渲染、机器学习、深度学习等需要高性能但不需要高精度的应用。单精度浮点数使用32位存储,提供了较高的计算速度,但牺牲了一些精度。
- FP64 Cores(双精度浮点数核心):这些核心用于执行双精度浮点数计算,通常用于科学计算、工程模拟和其他需要高精度计算的应用。双精度浮点数使用64位存储,提供了更高的精度,但计算速度相对较慢。
- INT32 Cores(整数核心):这些核心用于执行整数计算。整数计算通常用于控制流程、逻辑运算和其他不需要浮点数计算的任务。整数计算核心通常能够提供高性能,特别是在需要大量整数运算的情况下。
不同的GPU架构和制造商可能采用不同的核心配置,以满足不同类型的应用需求。在选择GPU时,您应该根据您的具体应用需求来考虑这些核心类型的比例和性能。
张量核心(Tensor Cores)
Tensor Cores是一种特殊的GPU核心,主要用于进行深度学习和人工智能(AI)工作负载中的张量运算。这些核心最初由NVIDIA引I入,并在一些高端GPU中出现,如NVIDIA的Volta和Ampere架构。Tensor Cores旨在加速深度神经网络训练和推理等计算密集型任务。
Tensor Cores通常支持混合精度计算,即同时处理半精度(16位)和单精度(32位)数据。这种精度混合可加速训练过程,因为它在减少计算需求的同时保持足够的数值精度
TDP (Thermal Design Power)/TGP (Total Graphics Power)
GPU的最大功耗参数通常被称为TDP 或TGP 。这是一个重要的性能指标,它表示GPU在正常工作条件下可以消耗的最大功率。
TDP是一个由GPU制造商提供的参数,表示在设计和散热解决方案允许的情况下,GPU能够持续消耗的最大功率。这个值通常以瓦特(W)为单位表示。TDP是一个指导性的参考,用于确定需要多大的散热解决方案来保持GPU在适当的温度范围内运行。较高的TDP通常表示更高的性能,但也可能需要更强大的散热系统
TGP是一个相似的参数,但它通常包括了GPU、显存和其他与图形外理相关的组件的总功耗。TGP更全面地考虑了整个图形卡的功耗,而不仅仅是GPU核心。这对于笔记本电脑等紧凑型设备非常重要,因为它们需要有效管理整个图形系统的热量和功耗。
计算速度(FLOPS)
FLOPS(每秒浮点运算数)是衡量计算设备性能的一种常用指标,特别是在科学计算、机器学习和深度学习等领域。它表示一个设备每秒能够执行的浮点运算的数量。例如,一个拥有10 TFLOPS的GPU能够在一秒内执行10万亿次浮点运算。
要计算一个GPU的FLOPS,我们通常需要考虑以下几个因素:
- 核心数量:GPU中的处理单元数量。每个核心都能够执行浮点运算。
- 时钟频率:GPU的工作频率,以赫兹(Hz)为单位。它表示每秒钟执行的时钟周期数。
- 每个周期的浮点运算数:这是每个时钟周期内每个核心可以执行的浮点运算数。
计算公式如下:
FLOPS = 核心数量 * 时钟频率 * 每个周期的浮点运算数
对于特定数据类型的FLPOS计算也可以使用下式:
FLOPS = GPU SM数量 * 特定数据类型的指令吞吐 * 时钟频率 * 每个周期的浮点运算数
举例来说,如果一个GPU拥有1000个核心,每个核心能够在1 GHz时钟频率下执行2次浮点运算,那么它的理论峰值性能将是2 TFLOPS。
需要注意的是,实际的性能可能会受到许多因素的影响,包括内存带宽、缓存大小、架构设计等。因此,TFLOPS只是一个理论上的性能指标,实际应用中的性能可能会有所下降。
eg. 以A100为例说明参数
下图为A100的一个SM,即一个流处理器,可以看到,FP32 Cores有64个,FP64 Cores有32个,INT32 Cores有64个,Tensor Cores有4个,而A100像这样的SM足足有108个。另外,一个SM中有64个CDUA Cores,
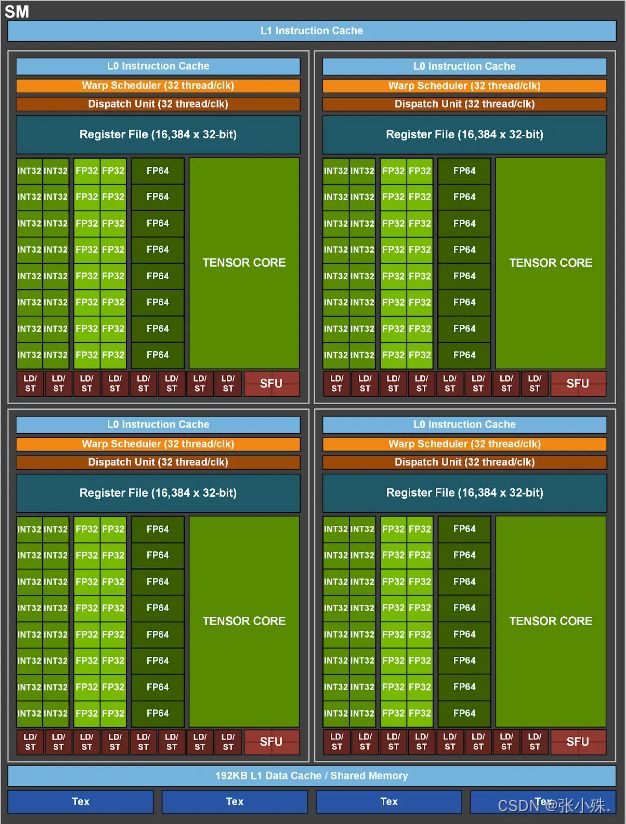
下面是A100的一些基本性能参数:
- GPU基础时钟频率 (Base Clock):1410MHz
- GPU加速时钟频率 (Boost Clock):1530 MHz
- 显存容量(VRAM Capacity):80GB
- 显存带宽(Memory Bandwidth):2039GB/s
- 流处理器簇(Streaming Multiprocessors,SMs): 108
- CUDA 核心数量(CUDA Cores): 6912(64 * 108)
- FP32/FP64/INT32 Cores:6912/3456/6912(64/32/64 * 108)
- 张量核心(Tensor Cores):432(4 * 108)
- TDP (Thermal Design Power)/TGP (Total Graphics Power):400W
计算速度(FLOPS):
FP32 FLOPS = FP32 核心数量 * 时钟频率 * 每个周期的浮点运算数 = 6912 * 1410 MHz * 2 =19.5 TFLOPS
FP64 FLOPS = FP64 核心数量 * 时钟频率 * 每个周期的浮点运算数 = 3456 * 1410 MHz * 2 = 9.7 TFLOPS
对于A100的特定数据类型的FPLOS计算,我们可以先查阅A100特定数据类型的指令吞吐如下表所示:

我们可以参照上表进行计算,例如FP16 FPLOS/FP16 TC FPLOS:
FP16 FPLOS = GPU SM数量 * 特定数据类型的指令吞吐 * 时钟频率 * 每个周期的浮点运算数
=108 * 256 * 1410 MHz * 2=78 TFLOPS
FP16 TC FPLOS = GPU SM数量 * 特定数据类型的指令吞吐 * 时钟频率 * 每个周期的浮点运算数
=108 * 1024 * 1410 MHz * 2=312 TFLOPS
深度神经网络性能指标
准确性(Accuracy)
神经网络的准确性可以通过多种指标来衡量,具体选择哪些指标取决于任务的性质。以下是一些常见的神经网络准确性指标:
1. 准确率(Accuracy):是最基本的评估指标,表示模型正确分类样本的比例。计算方式是正确分类的样本数除以总样本数。
\[ \text{准确率} = \frac{\text{正确分类的样本数}}{\text{总样本数}} \]
2. 精确度(Precision):在所有被模型判定为正类别的样本中,真正为正类别的比例。适用于关注假正例的任务,如垃圾邮件检测。
\[ \text{精确度} = \frac{\text{真正例}}{\text{真正例 + 假正例}} \]
3. 召回率(Recall):在所有实际正类别的样本中,被模型正确判定为正类别的比例。适用于关注假负例的任务,如癌症检测。
\[ \text{召回率} = \frac{\text{真正例}}{\text{真正例 + 假负例}} \]
4. F1分数:精确度和召回率的调和平均数,综合考虑了两者的性能。F1分数越高,模型在精确度和召回率之间取得了更好的平衡。
\[ F1 = \frac{2 \times \text{精确度} \times \text{召回率}}{\text{精确度} + \text{召回率}} \]
5. ROC曲线和AUC(Area Under the Curve):用于评估二分类模型性能,ROC曲线表示真正例率(召回率)和假正例率之间的权衡,AUC则是ROC曲线下的面积,AUC越大,模型性能越好。
6.IOU(Intersection over Union):IOU是目标检测任务中常用的评估指标之一,用于衡量模型检测结果与真实标注框之间的重叠程度。
IOU的计算方法是通过计算检测框(通常是矩形框)与真实标注框之间的交集面积与并集面积的比值来衡量重叠程度。具体计算公式如下:
IOU = 交集面积 / 并集面积
其中,交集面积是检测框和真实标注框重叠的部分的面积,而并集面积是两个框的总面积。
IOU的取值范围在0到1之间,越接近1表示检测框与真实标注框的重叠程度越高,即检测结果越准确。常用的IOU阈值是0.5,即当IOU大于等于0.5时,认为检测结果是正确的。在目标检测任务中,IOU常用于计算模型的准确率、召回率以及平均精确度(mAP)。通过设置不同的IOU阈值,可以得到不同的评估结果,从而评估模型在不同重叠程度下的性能。
总之,IOU是一种常用的用于衡量目标检测模型性能的指标,它能够量化检测结果与真实标注框之间的重叠程度,帮助评估模型的准确性和鲁棒性。
7.平均精确度均值(Mean Average Precision,mAP):mAP是目标检测任务中常用的重要度量指标之一。它用于综合评估模型在多类别目标检测中的性能。
mAP的计算过程包括以下步骤:
- 计算每个类别的精确度-召回率曲线(Precision-Recall Curve):对于每个目标类别,计算模型的精确度和召回率,并生成精确度-召回率曲线。这通常涉及在不同阈值下计算精确度和召回率的值。
- 计算每个类别的平均精确度(Average Precision,AP):对于每个类别,计算其精确度-召回率曲线下的面积(曲线下积分),这个面积就是AP。AP反映了模型在单个类别上的性能。
- 计算所有类别的mAP:将所有类别的AP取平均值,得到mAP。mAP综合考虑了模型在多个类别上的性能,因此可以更全面地评估目标检测模型。
通常情况下,mAP值范围在0到1之间,越接近1表示模型性能越好。mAP是一种很有用的指标,特别是在多类别目标检测任务中,因为它考虑了不同类别之间的性能差异,提供了一个全局性的性能度量。在评估目标检测算法时,我们经常关注mAP值,以确定模型的优劣,并进行改进和比较。
这些指标提供了对模型性能不同方面的评估,选择合适的指标取决于任务的特性和关注的重点。在实际应用中,可以根据具体需求综合考虑多个指标来全面评估。
损失(Loss)
神经网络的损失指标用于衡量模型在训练过程中预测结果与实际目标之间的差异。这些损失指标帮助优化算法调整模型参数,以最小化误差。以下是一些常见的神经网络损失指标:
1. 均方误差(Mean Squared Error,MSE):用于回归任务,它计算模型预测值与实际目标值之间的平方差的平均值。
\[ \text{MSE} = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2 \]
其中,\(y_i\) 是实际目标值,\(\hat{y}_i\) 是模型的预测值,\(N\) 是样本数量。
2. 均方根误差(Root Mean Squared Error,RMSE):MSE的平方根。
\[ \text{RMSE} = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2} \]
3. 平均绝对误差(Mean Absolute Error,MAE):也用于回归任务,计算模型预测值与实际目标值之间的绝对差的平均值。
\[ \text{MAE} = \frac{1}{N} \sum_{i=1}^{N} |y_i - \hat{y}_i| \]
4. 交叉熵损失(Cross-Entropy Loss):常用于分类任务,特别是二分类和多分类问题。对于二分类问题,交叉熵损失如下:
\[ \text{二分类交叉熵损失} = - (y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})) \]
其中,\(y\) 是实际目标,\(\hat{y}\) 是模型的预测概率。对于多分类问题,可以扩展为多类别交叉熵损失。
5. 对数损失(Log Loss):类似于交叉熵损失,通常用于二分类和多分类问题的概率输出。对数损失在实际目标是二进制值或多类别标签时很有用。
这些损失指标各自适用于不同类型的任务,选择正确的损失函数对于训练神经网络非常重要,因为它直接影响着模型的性能和收敛速度。通常,在训练神经网络时,目标是最小化这些损失指标。
模型参数量(Params)
神经网络模型的参数量是指网络中需要学习的权重和偏差的总数量。参数量是一个关键的指标,因为它直接影响模型的容量、训练速度和内存占用。
神经网络的总参数量是所有层的参数数量之和。在深层神经网络中,参数量可能会非常庞大,这也需要考虑训练和推理时的计算和内存需求。通常,为了减小参数量和防止过拟合,可以采用技巧如参数共享、权重正则化等。
了解模型的参数量有助于决定网络的复杂度,选择适当的模型结构,以及在不同硬件和资源限制下进行部署。在实际应用中,模型参数量通常会在训练前和模型选择时被仔细考虑。
模型计算量(FLOPs、MACs)
神经网络的计算量是指在前向传播(inference)和反向传播(backpropagation)过程中所执行的浮点运算的总数量。计算量是评估模型复杂度和性能的关键指标之一。以下是常见的用于计算神经网络计算量的指标:
1. 浮点运算次数(Floating-Point Operations,FLOPs,s表示复数):神经网络的计算量通常以浮点运算的数量来表示。这包括乘法、加法、除法等浮点运算。浮点运算次数可以用来估算在不同硬件上的计算时间和资源需求。
2. MACs(Multiply-Accumulate Operations):MACs是乘法累加操作的缩写,1MACs包含一个乘法操作与一个加法操作,大约是2FLOPs,通常用于衡量卷积神经网络的计算量。每个卷积核在每个位置执行乘法和加法操作通常数量一样。
计算量通常是在模型设计和部署阶段考虑的重要因素之一。较大的计算量可能需要更多的计算资源,例如GPU或TPU,以便高效地训练和推理神经网络模型。在移动设备或边缘计算环境中,计算量的减小对于模型的实际可用性至关重要。因此,在设计和选择神经网络模型时,通常会综合考虑模型的性能、精度和计算需求
训练速度(Training Speed)
神经网络模型的训练速度是一个关键性能指标,它涉及到训练时间、资源利用率和迭代次数等方面。以下是常见用于衡量神经网络模型训练速度的指标:
1. 训练时间:训练时间是训练一个神经网络模型所需的实际时间。通常以小时、分钟或秒为单位来表示。较短的训练时间通常被认为是一个训练速度较快的指标。
2. 收敛速度:模型的收敛速度指的是模型在训练过程中达到所需性能的速度。一个快速收敛的模型将在较少的迭代次数内达到所需的精度水平,从而加快训练速度。
3. 每秒处理的样本数(Samples Per Second,SPS):SPS表示在训练过程中每秒处理的训练样本数量。较高的SPS表明模型训练速度更快。通常,使用GPU或TPU等硬件可以提高SPS。
4. 硬件资源利用率:训练速度还涉及到硬件资源的有效利用。高效的模型训练流程应该能够充分利用计算资源,例如GPU或多核CPU,以提高训练速度。
5. 迭代次数:模型训练需要的迭代次数也是一个衡量训练速度的指标。较少的迭代次数通常表示训练速度较快。
6. 分布式训练:分布式训练是指将训练任务分配到多个计算节点或设备上,以加快训练速度。衡量分布式训练速度通常涉及到通信开销、数据同步和并行计算等因素。
7. 批处理大小:批处理大小是指在每个训练迭代中用于更新模型参数的样本数量。较大的批处理大小通常可以加快训练速度,但也可能增加内存需求。
综合考虑这些指标可以帮助评估神经网络模型的训练速度。快速的训练速度对于快速迭代模型设计和调试、减少资源成本以及实时应用中的性能至关重要。同时,训练速度还受到硬件性能、数据集大小、模型架构和超参数设置等因素的影响。
推理速度(Inference Speed)
1. 推理时间(Inference Time):推理时间是神经网络模型执行单个推断任务所需的实际时间,通常以毫秒(ms)为单位表示。推理时间越短,意味着模型的推理速度越快。
2. 每秒推理次数(Inferences Per Second,IPS):IPS表示模型在一秒内可以完成的推理任务数量,通常以次/秒来表示。IPS越高,模型的推理速度越快。
3. 延迟(Latency):延迟是指模型从接收输入数据到生成输出结果之间的时间间隔。低延迟是实时应用中的关键要求,例如视频流处理和自动驾驶。
4. 吞吐量(Throughput):吞吐量是指在一定时间内,模型可以处理的输入数据量。通常以每秒处理的数据量来表示,例如图像的数量或文本的字数。
5. 模型尺寸(Model Size):模型尺寸表示模型所占用的内存或磁盘空间大小。较小的模型尺寸通常可以更快地加载到内存中,从而减少推理时间。
6. 硬件资源利用率:硬件资源利用率指的是在推理过程中,模型如何有效地利用硬件资源,如CPU、GPU或TPU。高效的硬件资源利用率可以提高推理速度。
7. 批处理大小(Batch Size):批处理大小表示一次并行处理的输入数据数量。较大的批处理大小通常可以提高硬件的利用率,但也会增加内存需求。
8. 模型精度(Model Accuracy):模型精度是指模型在推理过程中生成的输出结果与实际标签的一致性。在追求更快推理速度时,需要权衡模型精度,以确保不牺牲太多的准确性。
这些指标在不同应用场景中具有不同的重要性。例如,在移动设备上运行的应用可能更关注低延迟和较小的模型尺寸,而云端服务器上的应用可能更侧重于高IPS和吞吐量。综合考虑这些指标,可以选择适当的神经网络模型、硬件加速和优化方法,以满足特定应用的需求。
易混指标对比
FLOPS和FLOPs(名称易混)
FLOPS和FLOPs是两个与计算性能相关的术语,它们有一些区别和不同的含义。
- FLOPS(Floating Point Operations Per Second):FLOPS是指每秒执行的浮点运算次数。它是衡量计算设备(如CPU、GPU、TPU等)的计算能力的指标。FLOPS通常用于衡量计算设备的理论峰值性能,表示设备在理想情况下每秒钟可以执行的浮点运算次数。
- FLOPs(Floating Point Operations):FLOPs是指浮点运算的总次数。它是衡量计算任务中实际执行的浮点运算数量的指标。FLOPs可以用于衡量神经网络模型的计算复杂度,即模型中浮点运算的总量。
理解上的区别在于,FLOPS是指计算设备的计算能力,而FLOPs是指计算任务中的实际计算量。FLOPS通常用于评估硬件设备的性能,而FLOPs用于评估计算任务的复杂度。
举个例子来说,如果一台计算设备的峰值性能为100 TFLOPS(每秒执行1万亿次浮点运算),而一个神经网络模型的计算复杂度为10 GFLOPs(总共执行10亿次浮点运算),那么这个模型在这台设备上的推理速度可能会受到设备性能的限制,无法达到峰值性能。
Params和FLOPs(理解易混)
"Params" 和 "FLOPs" 是两个与神经网络模型相关的术语,它们有不同的含义和用途。
- Params(Parameters):Params是指神经网络模型中的参数数量。这些参数是模型中的可学习权重和偏差,它们在训练过程中通过反向传播算法进行学习。Params通常以数量来表示,比如百万(Million)或千万(Ten Million)个参数。参数的数量通常反映了模型的容量和复杂度,更多的参数通常意味着更复杂的模型。
- FLOPs(Floating Point Operations):FLOPs是指神经网络模型在推理或训练时执行的浮点运算的总数量。这包括加法、乘法等浮点运算。FLOPs通常以数量来表示,例如十亿(GigaFLOPs)或千亿(TeraFLOPs)次浮点运算。 FLOPs是一种衡量模型计算复杂度的指标,它可以用来估计模型在硬件上的计算需求。
理解上的区别在于,"Params" 是关于模型的规模和容量的度量,而 "FLOPs" 是关于模型的计算复杂度的度量。更多的参数通常会增加模型的容量,使其更容易拟合复杂的数据,但也会增加训练和推理的计算成本。同时,模型的 "FLOPs" 数量可以帮助我们估计模型在不同硬件上的运行性能,例如在CPU、GPU或TPU上的速度。
总之,Params是关于模型参数的数量,而FLOPs是关于模型计算复杂度的度量,它们各自提供了不同角度的信息,用于评估神经网络模型。
模型的参数数量与储存大小
神经网络模型的参数数量与储存大小之间存在直接关系,因为模型的参数数量直接影响了模型的存储需求。以下是参数数量和储存大小之间的关系:
- 参数数量:神经网络模型的参数数量是指模型中可学习的权重和偏差的数量。通常以百万(Million)或千万(Ten Million)为单位来表示。更多的参数通常表示模型的容量更大,可以更好地拟合复杂的数据。
- 储存大小:神经网络模型的储存大小是指将模型保存在磁盘或内存中所需的空间。模型的储存大小与参数数量成正比,因为每个参数通常需要一个浮点数或整数来表示。参数的储存通常使用字节(Bytes)为单位来表示,但也可以使用更大的单位如千字节(Kilobytes)、兆字节(Megabytes)、千兆字节(Gigabytes)等。
一般来说,可以使用以下公式来估算模型的储存大小:
储存大小(Bytes) = 参数数量 × 参数数据类型大小
在估算储存大小时,还需要考虑模型的权重和偏差的数据类型,通常是浮点数(float)或整数(int)。例如,一个具有1000万个参数,每个参数使用4字节(32位浮点数)表示的神经网络模型,其储存大小将是约40兆字节(40 MB)。
注意,模型的储存大小不仅包括参数,还包括模型的架构和元数据等信息。因此,总储存大小可能略大于参数数量估算的大小。
在部署和存储模型时,需要考虑模型的储存大小,特别是在资源受限的环境中。对于移动设备、嵌入式系统或边缘计算设备,模型的大小可能是一个关键考虑因素。如果需要减小模型的储存大小,可以采取模型剪枝、压缩和量化等技术。
最后的最后,希望本文能为你带来帮助,如果你觉得有用,希望能三连支持,你的鼓励是我持续创作的动力!要是本文中出现错误,也欢迎指正!
参考:
NVIDIA A100 深度解密(一):GPU 峰值计算那些事 - 知乎 (zhihu.com)
[GPU硬件架构]NVIDIA Ampere 架构:第三代 Tensor Core - 简书 (jianshu.com)
深度学习中FLOPS和FLOPs的区别与计算_一直特立独行的猫1994的博客-CSDN博客