TS数据流的解析
- TS数据流的解析
-
文档修改信息
-
1 TS 数据流简介
- 1.1 TS流的构成
- 1.2 TS流的产生
- 1.3 TS流的格式
- 1.4 参考文档
- 1.5 小结
-
2 TS数据流包头的解析
- 2.1 解析步骤
- 2.2 包长解析
- 2.3 PID解析
- 2.4 负载单元开始标志解析
- 2.5 小结
-
3 PAT表的解析
- 3.1 解析步骤
- 3.2 PAT表的描述
- 3.3 PAT表的获取
- 3.4 PAT表信息的解析
- 3.5 小结
-
4 PMT表的解析
- 4.1 解析步骤
- 4.2 PMT表的描述
- 4.3 PMT表的获取
- 4.4 PMT表信息解析
- 4.5 小结
-
5 SDT表的解析
- 5.1 解析步骤
- 5.2 SDT表的描述
- 5.3 SDT表的获取
- 5.4 SDT表信息解析
- 5.5 小结
-
6 NIT表的解析
- 6.1 解析步骤
- 6.2 NIT表的描述
- 6.3 NIT表的获取
- 6.4 NIT表信息解析
- 6.5 小结
-
7 描述符的解析
- 7.1 描述符的介绍
- 7.2 描述符的获取
- 7.3 描述符的解析
- 7.4 小结
-
8 数据包的处理
- 8.1 数据的存储
- 8.2 完整数据包的获取
- 8.3 数据包的合并
- 8.4 小结
-
9 Makefile的编写
-
10 总结
-
11 参考文献
-
TS数据流的解析
文档修改信息
| 版本 | 作者 | 时间 | 备注 |
|---|---|---|---|
| 1.0 | 李海杰 | 2022-03-07 | 搬运到CSDN并修改相关数据 |
1 TS 数据流简介
简单来说,数字机顶盒是能够接收到一段段的码流,这样的码流我们可以称之为TS(Transport Stream,传输流),每个TS流里都携带的有一些信息,例如Video、Audio、PAT、PMT等。
1.1 TS 流的构成
TS 流是一种用于数据传输的单一传输流,它是由一些具有共同时间基准或独立时间基准的一个或多个PES复合而成的。
在这里我们需要知道一些其他数据流:
- ES流(Elementary Stream) 基本码流,不分段的音频、视频或其他信息的连续码流。
- PES流 把基本流ES分割成段,并加上相应头文件打包成形的打包基本码流。
- PS流(Program Stream) 节目流,将具有共同时间基准的一个或多个PES组合(复合)而成的单一数据流(用于播放或编辑系统,如m2p)。
1.2 TS 流的产生

-
从上图可以看出,视频ES和音频ES通过打包器和共同或独立的系统时间基准形成一个个PES,通过TS复用器复用形成的传输流。注意这里的TS流是位流格式,也就是说TS流是可以按位读取的。
-
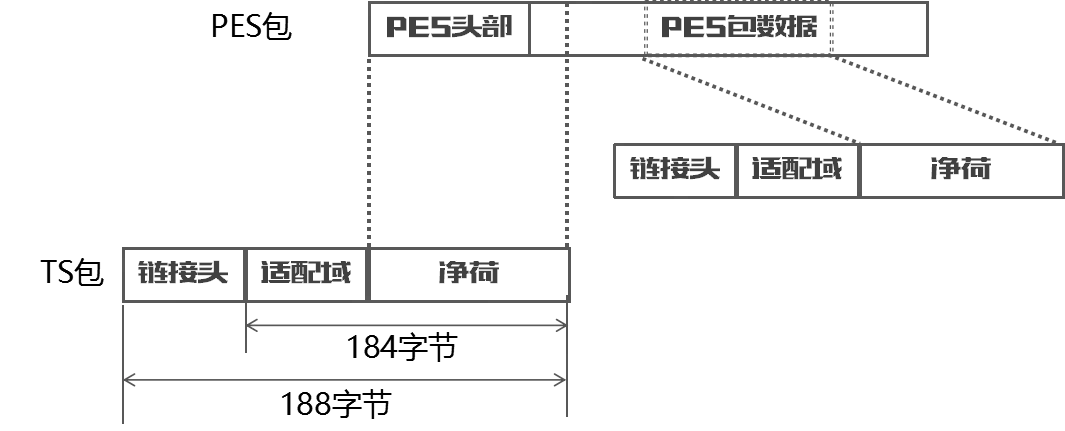
在实际传输中,PES包会被切割后装载到TS包中,上图就是PES和TS之间的关系图。
注意:
- 一个PES包可以装载到不同的TS包。
- 每一个TS包必须只含有从一个PES来的数据。
- PES包头必须跟在TS包的链接头后面。
- 对于一个特定的PES,最后一个TS包可以含有填充比特。
1.3 TS 流的格式
TS流是基于Packet的位流格式,每个包的长度是固定的188个字节(或者204个字节,原因是在188个字节后加上了16个字节的CRC校验数据,其他格式一样)。整个TS流组成形式如下:

- 包头信息
| Packet Header(包头)信息说明 | 标识 | 位数 | 说明 |
|---|---|---|---|
| 1 | sync_byte | 8bits | 同步字节 |
| 2 | transport_error_indicator | 1bit | 错误指示信息(1:该包至少有1bits传输错误) |
| 3 | payload_unit_start_indicator | 1bit | 负载单元开始标志(packet不满188字节时需填充) |
| 4 | transport_priority | 1bit | 传输优先级标志(1:优先级高) |
| 5 | PID | 13bit | Packet ID号码,唯一的号码对应不同的包 |
| 6 | transport_scrambling_control | 2bits | 加密标志(00:未加密;其他表示已加密) |
| 7 | adaptation_field_control | 2bits | 附加区域控制 |
| 8 | continuity_counter | 4bits | 包递增计数器 |
- 上面表格是一个包(Package)的头(Header)的说明,其中需要注意的是:PID是TS流中唯一识别标志,Packet Data是什么内容就是由PID决定的。 如果一个TS流中的一个Packet的Packet Header中的PID是0x0000,那么这个Packet的Packet Data就是DVB的PAT表而非其他类型数据(如Video、Audio或其他业务信息)。
| TS流中PID的分配 | ||
|---|---|---|
| 表 | PID值 | 说明 |
| PAT | 0x0000 | - |
| CAT | 0x0001 | - |
| TSDT | 0x0002 | - |
| 预留 | 0x0003 至0x000F | 无 |
| NIT, ST | 0x0010 | - |
| SDT , BAT, ST | 0x0011 | - |
| EIT, ST | 0x0012 | - |
| RST, ST | 0x0013 | - |
| TDT, TOT, ST | 0x0014 | - |
| 网络同步 | 0x0015 | 无 |
| 预留使用 | 0x0016 至 0x001B | 无 |
| 带内信令 | 0x001C | 无 |
| DIT | 0x001E | 无 |
| SIT | 0x001F | 无 |
- 上面是一些表的PID值,这些值是固定的,不允许更改。
- 包数据结构
- TS流的包数据是承载实际数据的区域,根据不同的PID,有不同的解析方式。
1.4 参考文档
-
《En300468.V1.7.1_Specification for SI in DVB Systems》
-
《数字视频广播中文业务信息规范》
-
DVB和MPEG-II中的表格
1.5 小结
-
TS流是一种位流(当然就是数字的), 它是由ES流分割成PES后复用而成的;它经过网络传输被机顶盒接收到; 数字电视机顶盒接收到TS流后将解析TS流。
-
TS流是由一个个Packet(包)构成的, 每个包都是由Packet Header(包头)和Packet Data(包数据)组成的。 其中Packet Header指示了该Packet是什么属性的,并给出了该Packet Data的数据的唯一网络标识符PID。
-
TS流和PS流的区别:TS流的包结构是长度是固定的;PS流的包结构是可变长度的。 这导致了 TS流的抵抗传输误码的能力强于PS流 (TS码流由于采用了固定长度的包结构, 当传输误码破坏了某一TS包的同步信息时,接收机可在固定的位置检测它后面包中的同步信息,从而恢复同步,避免了信息丢失。 而PS包由于长度是变化的,一旦某一 PS包的同步信息丢失, 接收机无法确定下一包的同步位置,就会造成失步,导致严重的信息丢失。 因此,在信道环境较为恶劣,传输误码较高时,一般采用TS码流;而在信道环境较好,传输误码较低时,一般采用PS码流)。由于TS码流具有较强的抵抗传输误码的能力,因此目前在传输媒体中进行传输的MPEG-2码流基本上都采用了TS码流的包格。
2 TS数据流包头的解析
上面我们对TS数据流进行了简单介绍,了解到了TS数据流的基本结构和组成部分,那么我们就可以着手对TS数据流的解析工作。
2.1 解析步骤
在对TS数据流包头进行分析的时候我们主要获取的信息有三点:数据包长度、PID值、负载单元开始标志。所以我们可以按下面步骤来进行初步解析:
- 获取TS数据流包长度信息。
- 得到TS数据流包头PID信息。
- 确定每个数据包的负载单元开始标志。
2.2 包长解析
我们清楚,TS数据包长度是固定的,188字节或者204字节。那么我们在对数据包长度进行解析时,就只需获取一段完整的TS数据包,然后来判断它是188字节还是204字节。在这里我是采用if语句来进行判断。
首先第一步获取一段完整的TS数据包。因为每一段TS数据包的包头第一个字节都是0x47,那么我们只用找到这个标志位就能开始下一步判断。
int ParseLen(FILE *pTsFile, int TsPosition)
{
int PackageLength = 0;
while(fgetc(pTsFile) != EOF)
{
if(fgetc(pTsFile) == 0x47)
{
if(JudgmentPackageLength(pTsFile, TsPosition) == 204)
{
PackageLength = 204;
break;
}
if(JudgmentPackageLength(pTsFile, TsPosition) == 188)
{
PackageLength = 188;
break;
}
}
}
return PackageLength;
}
- 我们先通过fopen()函数来打开TS文件,并保存文件流指针。然后用fgetc()函数来读取文件中的每个字节数据,再加上while()循环语句来实现遍历读取。当我们遇到为0x47的数据时,就调用一个判断函数来进行下一步的判断。
for(Time = 0; Time < 10; Time++)
{
if(fseek(pTsFile, TsPosition - 1, SEEK_CUR) == -1)
{
printf("fseek error!");
return value;
}
if(feof(pTsFile))
{
value = -1;
return value;
}
fseek(pTsFile,188,SEEK_CUR);
PackageByte = fgetc(pTsFile);
if(PackageByte == 0x47)
{
value = 188;
}
else
{
fseek(pTsFile,203,SEEK_CUR);
PackageByte = fgetc(pTsFile);
if(PackageByte == 0x47)
{
value = 204;
}
else
{
value = -1;
}
}
}
- 在判断函数中我是采用从当前0x47位置向后偏移188字节或者204字节的方式来判断下一段数据是否为0x47。如果是,说明是一段完整数据包;如果不是,说明我们并未找到包头,那么继续遍历。
- 在这里我们为了排除偶然情况,我们可以选择利用for()函数进行一定次数的循环,往后多移动几次来确定所获取的的确是一段完整的TS数据包。
- 通过这几步骤的循环判断,我们就可解析出我们的数据包长度是188字节还是204字节。
2.3 PID解析
当我们解析出一段完整的数据包后就可以利用一个数组来对这一段完整的数据进行保存,方便我们后面的解析。对包头解析时我们需要知道我们的包头结构,每个字节代表什么含义,每个数据有占有多少字节位数。下面就是我们的包头结构表:
| Packet Header(包头)信息说明 | 标识 | 位数 | 说明 |
|---|---|---|---|
| 1 | sync_byte | 8bits | 同步字节 |
| 2 | transport_error_indicator | 1bit | 错误指示信息(1:该包至少有1bits传输错误) |
| 3 | payload_unit_start_indicator | 1bit | 负载单元开始标志(packet不满188字节时需填充) |
| 4 | transport_priority | 1bit | 传输优先级标志(1:优先级高) |
| 5 | PID | 13bit | Packet ID号码,唯一的号码对应不同的包 |
| 6 | transport_scrambling_control | 2bits | 加密标志(00:未加密;其他表示已加密) |
| 7 | adaptation_field_control | 2bits | 附加区域控制 |
| 8 | continuity_counter | 4bits | 包递增计数器 |
我们可以看出我们所想获取到的PID是包头的第2个字节的5bits加上第3个字节的8bits,那么我们可以先创建一个结构体,来对包头数据进行存储。
typedef struct TS_Package_Head
{
unsigned sync_byte :8;
unsigned transport_error_indicator :1;
unsigned payload_unit_start_indicator :1;
unsigned transport_priority :1;
unsigned PID :13;
unsigned transport_scrambling_control :2;
unsigned adaptation_field_control :2;
unsigned continuity_counter :4;
}TS_Package_Head;
- 因为我们知道,TS数据包的包头是固定4个字节。那么我们就将之前所保存的数据包数据取出前四个字节来放入结构体中。这样一来我们就能够通过结构体来获取到我们该段数据包的PID数据。
TS_Package_Head ParseTS_PackageHead(TS_Package_Head TS_PackageHead, unsigned char PackageHead_data[4])
{
TS_PackageHead.sync_byte = PackageHead_data[0];
TS_PackageHead.transport_error_indicator = PackageHead_data[1] >> 7;
TS_PackageHead.payload_unit_start_indicator = (PackageHead_data[1] >> 6) & 0x01;
TS_PackageHead.transport_priority = (PackageHead_data[1] >> 5) & 0x01;
TS_PackageHead.PID = ((PackageHead_data[1] & 0x1F) << 8) | PackageHead_data[2];
TS_PackageHead.transport_scrambling_control = PackageHead_data[3] >> 6;
TS_PackageHead.adaptation_field_control = (PackageHead_data[3] >> 4) & 0x03;
TS_PackageHead.continuity_counter = PackageHead_data[3] & 0x0f;
return TS_PackageHead;
}
- PID是不同的表之间的重要标识,所以我们可以通过PID来获取到我们所需要解析的表的数据包。
2.4 负载单元开始标志解析
同PID获取方式一样,我们所保存的结构体里payload_unit_start_indicator就是负载单元开始的标志。通俗来说:
- 当该位置为’1’时,说明这段数据包含有该pid表的首张数据表,并且有效数据从该数据包的第五个字节开始。
- 当该位置为’0’时,说明这段数据包不包含该pid表的首张数据表,而是该pid表的后续数据。有效数据从该数据包的第四个字节开始。
- 这个标志位是我们获取pid表的第一张表的有效标志。
2.5 小结
对于包头的解析是我们分析一段数据包的开始,我们可以从解析出来的数据中可以得知该段数据包是不是我们所需要的数据包。在这里我们需要注意的问题就是:
- 我们对数据进行遍历的时候,可以将所获的一段完整数据包给单独提取出来进行保存。这样我们在进行解析的时候就可以对这段保存的数据来进行操作,避免了反复移动文件指针来进行数据的操作,极大的方便了我们代码的可阅读性。
- 在进行下一步解析之前我们就应该构思好我们代码的初步框架,避免后来出现代码逻辑混乱和反复循环读取数据的情况。
- 包头的PID,payload_unit_start_indicator, continuity_counter,这三个重要数据是我们判断一个完整数据包的依据。
3 PAT表的解析
PAT表是我们解析TS流的起点,也是机顶盒接收的入口点,使它获取数据的开始。PAT表定义了我们当前TS流中所有的节目,其PID固定为0x0000。它是PSI的根节点,要查询节目必须从PAT表开始。
3.1 解析步骤
- 寻找到PID为0x0000的TS数据包
- 根据解析出来的负载单元开始标志,确定数据包除包头外的有效数据起始位置,将有效数据提取保存。
- 将获取的有效数据存入PAT表的对应结构体中,方便保存。
3.2 PAT表的描述
- PAT表主要携带有以下信息:
| TS流ID | transport_stream_id | 该ID标志唯一的流ID |
|---|---|---|
| 节目频道号 | program_number | 该号码标志TS流中的一个频道,该频道可以包含很多的节目(即可以包含多个Video PID和Audio PID) |
| PMT的PID | program_map_PID | 表示本频道使用哪个PID做为PMT的PID,因为可以有很多的频道,因此DVB规定PMT的PID可以由用户自己定义 |
- PAT表的结构:
| # | 字段名 | 占位 | 次序 | 说明 |
|---|---|---|---|---|
| 0* | table_id | 8 bits | 第0个字节 | PAT的table_id只能是0x00 |
| 1* | section_syntax_indicator | 1 bit | 第1、2个字节 | 段语法标志位,固定为1 |
| 2* | zero | 1 bit | 第1、2个字节 | |
| 3* | reserved | 2 bits | 第1、2个字节 | |
| 4* | section_length | 12 bits | 第1、2个字节 | 意思是 段长度为29字节 |
| 5* | transport_stream_id | 16 bits | 第3、4个字节 | TS的识别号 |
| 6* | reserved | 2 bits | 第5个字节 | TS的识别号 |
| 7* | version_number | 5 bits | 第5个字节 | 一旦PAT有变化,版本号加1 |
| 8* | current_next_indicator | 1 bit | 第5个字节 | 当前传送的PAT表可以使用,若为0则要等待下一个表 |
| 9* | section_number | 4 bits | 第6个字节 | 给出section号,在sub_table中, 第一个section其section_number为"0x00", 每增加一个section,section_number加一 |
| 10* | last_section_number | 4 bits | 第7个字节 | sub_table中最后一个section的section_number |
| 循环开始(循环内的数据解析见下一节内容!) | ||||
| - | program_number | 16 bits | – | 节目号 |
| - | reserved | 3 bits | – | - |
| - | network_id 或 program_map_PID | 13 bits | – | program_number为0x0000时, 这里是network_id(NIT的PID); 其余情况是program_map_PID(PMT的PID) |
| 循环结束 | ||||
| - | CRC_32 | 32 bits | 最后4个字节 | - |
注意:
- 从for()开始,就是描述了当前流中的频道数目(N),每一个频道对应的PMT PID是什么。解复用程序需要接收所有的频道号码和对应的PMT 的PID,并把这些信息在缓冲区中保存起来。在后部的处理中需要使用到PMT的 PID。
- 由以上几个表可以分析出PAT表和PMT表有着内在的联系。也就是之前提到的。PAT表描述了当前流的NIT(Network Information Table,网络信息表)中的PID、当前流中有多少不同类型的PMT表及每个PMT表对应的频道号。
3.3 PAT表的获取
因为我们了解到了,所有PAT表的PID都固定是0x0000,所以在对PAT表获取时就只用利用if()判断语句来判断哪个数据包的PID是0x0000,即可找到PAT表。
if(fgetc(pTsFile) == 0x47)
{
fseek(pTsFile, -TsPackage_len, SEEK_CUR);
fseek(pTsFile, TsPosition - 1, SEEK_CUR);
fread(TSdata, 1, TsPackage_len, pTsFile);
TS_PackageHead = ParseTS_Type();
}
if(TS_PackageHead.PID == 0 && value == 0)
{
TS_PackagePAT = ParseTS_PAT(TsPackage_len, TS_PackageHead);
value++;
}
3.4 PAT表信息解析
找到PAT表以后,我们就能够把我们的数据保存在结构体中。
TS_PAT TSpatTable(TS_PAT TS_PackagePAT, unsigned char PATtable[204])
{
int PAT_Length = 0;
TS_PackagePAT.table_id = PATtable[0];
TS_PackagePAT.section_syntax_indicator = PATtable[1] >> 7;
TS_PackagePAT.zero = (PATtable[1] >> 6) & 0x1;
TS_PackagePAT.reserved_1 = (PATtable[1] >> 4) & 0x3;
TS_PackagePAT.section_length = ((PATtable[1] & 0x0F) << 8) | PATtable[2];
TS_PackagePAT.transport_stream_id = (PATtable[3] << 8) | PATtable[4];
TS_PackagePAT.reserved_2 = PATtable[5] >> 6;
TS_PackagePAT.version_number = (PATtable[5] >> 1) & 0x1F;
TS_PackagePAT.current_next_indicator = (PATtable[5] << 7) >> 7;
TS_PackagePAT.section_number = PATtable[6];
TS_PackagePAT.last_section_number = PATtable[7];
PAT_Length = 3 + TS_PackagePAT.section_length;
TS_PackagePAT.CRC_32 = (PATtable[PAT_Length - 4] << 24) | (PATtable[PAT_Length - 3] << 16)
| (PATtable[PAT_Length - 2] << 8) | PATtable[PAT_Length - 1];
return TS_PackagePAT;
}
for(PatProgramPosition = 8; PatProgramPosition < PAT_Length - 4; PatProgramPosition += 4)
{
if (0x00 == ((PATtable[PatProgramPosition ] << 8) | PATtable[1 + PatProgramPosition ]))
{
TS_PackagePAT.network_PID = ((PATtable[2 + PatProgramPosition ] & 0x1F) << 8) | PATtable[3 + PatProgramPosition ];
printf("the network_PID %0x\n", TS_PackagePAT.network_PID);
}
else
{
TS_PackagePAT.astPAT_Program[PAT_ProgramCount].program_number = (PATtable[PatProgramPosition ] << 8)
| PATtable[1 + PatProgramPosition ];
TS_PackagePAT.astPAT_Program[PAT_ProgramCount].reserved_3 = PATtable[2 + PatProgramPosition ] >> 5;
TS_PackagePAT.astPAT_Program[PAT_ProgramCount].program_map_PID = ((PATtable[2 + PatProgramPosition ] & 0x1F) << 8)
| PATtable[3 + PatProgramPosition ];
PAT_ProgramCount++;
}
}
注意:
-
一定要对负载单元开始标志进行判读,确定好有效数据读取位置。
-
在PAT表中有个循环,代表了存储的节目号信息。所以要在位运算时格外注意,一旦位置出错,后面的数据存储也会出错。
-
PAT表会在TS流中循环发送,所以我们只用解析一次,无需一直解析。
-
虽然PAT表只用解析一次,但是表里的节目号等信息是有很多,一定要解析完整。
3.5 小结
PAT表是我们解析的第一张表,解析方法各有不同,但是需要想好。因为后面随着表的数量的增加,如果方法过于复杂,会导致后续表格的解析也会同样复杂,这样就导致了整体代码显的冗长。而且在初步解析时我们同样要理清自己的解析思路,避免后续出现逻辑错误。
4 PMT表的解析
PMT是连接节目号与节目元素的桥梁,主要提供节目numbers和节目elements之间的映射关系。在一个TS流中包含有多少个频道,就包含多个PID不同的PMT表。
我们知道,一个电视节目至少包含了视频和音频数据,而每一个节目的视音频数据都是以包的形式在TS流中传输的; 所以说,一个TS流包含了多个节目的视频和音频数据包。 要想过滤出一个TS流中其中一个节目的视频和音频,则需要知道这个节目中视频和音频的标识号PID。 PMT表的作用就在于,它提供了每个节目视频、音频(或其他)数据包的PID。
4.1 解析步骤
- 结合PAT表的信息,寻找到各个PMT表的PID,并提取对应的TS数据包
- 根据解析出来的负载单元开始标志,确定数据包除包头外的有效数据起始位置,将有效数据提取保存。
- 将获取的有效数据存入PMT表的对应结构体中,方便保存。
4.2 PMT表的描述
PMT表中包含的数据如下:
-
当前频道中所包含的所有Video数据的PID。
-
当前频道中所包含的所有Audio数据的PID。
-
和当前频道关联在一起的其他数据的PID(如数字广播,数据通讯等使用的PID)。
所以,当我们解析了PMT表之后,我们就能够获取到频道中所有的PID信息,例如当前频道包含多少Video、共多少个Audio和其他数据,还能知道每种数据对应的PID分别是什么。这样如果我们要选择其中一个Video和Audio收看,那么只需要把要收看的节目的Video PID和Audio PID保存起来,在处理Packet的时候进行过滤即可实现。
PMT表的结构如下:
Syntax(句法结构) No. of bits(所占位数) Identifier(识别符) Note(注释) program_map_section(){ table_id 8 uimsbf 表标识符 Section_syntax_indicator 1 bslbf 段语法指示符,通常设置为“1” “0” 1 bslbf zero Reserved 2 bslbf 保留 Section_length 12 uimsbf 段长度,从program_number开始,到CRC_32(含)的字节总数 program_number 16 uimsbf 频道号码,表示当前的PMT关联到的频道 Reserved 2 bslbf 保留 Version_number 5 bslbf 版本号码,如果PMT内容有更新,则它会递增1通知解复用程序需要重新接收节目信息 Current_next_indicator 1 bslbf 当前未来标志符 Section_number 8 uimsbf 当前段号码 last_section_number 8 uimsbf 最后段号码,含义和PAT中的对应字段相同 reserved 3 bslbf 保留 PCR_PID 13 uimsbf PCR(节目参考时钟)所在TS分组的PID reserved 4 bslbf 保留 program_info_length 12 uimsbf 节目信息长度(之后的是N个描述符结构,一般可以忽略掉,这个字段就代表描述符总的长度,单位是Bytes)紧接着就是频道内部包含的节目类型和对应的PID号码了,头两位为“00” for(i=0;i descriptor() } for(i=0;i stream_type 8 uimsbf 流类型,标志是Video还是Audio还是其他数据 reserved 3 bslbf 保留 elementary_PID 13 uimsbf 该节目中包括的视频流,音频流等对应的TS分组的PID reserved 4 bslbf 保留 ES_info_length 12 uimsbf 头两位为"00" for(i=0;i descriptor() } } CRC_32 32 rpchof 32位, 表示CRC的值 }
注意:
- 在PMT表结构中我们发现了有两个地方有Descriptor(),这是描述符数据。第一个Descruptor()数据的长度是由program_info_length来决定的,后面一个Descruptor()数据长度是由ES_info_length来决定的。
- 这里的描述符可能为Mosaic descriptor(马赛克描述符)、Service move descriptor(业务转移描述符)、Stream identifier descriptor(流标识符描述符)、Teletext descriptor(图文电视描述符)。
4.3 PMT表的获取
在这里我们就需要同PAT表的获取做对比。因为在一段TS流中PAT表我们只用解析一次即可,但是PMT表不可以只获取一张。因为PMT表有多张,且携带的信息也不同。我采用的方法是在PAT表解析时,利用一个数组来保存所有的PMT的PID信息,然后在通过循环遍历来找到每一张PMT表。
if((TS_PackageHead.PID == TS_PackagePAT.astPAT_Program[PMTCount].program_map_PID) &&
(TS_PackagePAT.astPAT_Program[PMTCount].program_map_PID != 0))
{
TS_Program = ParseTS_PMT(TsPackage_len, TS_PackageHead);
PMTCount++;
}
注意:
- 为了避免重复解析,我利用标号来记录解析表的序号。又因为PMT表的PID不可能是0x0000。所以加上一个判断条件来避免空数据的错误解析。
4.4 PMT表信息解析
TS流的几张表的解析方式都差不多,同PAT表一样,我们根据负载单元开始标志来确定数据包的有效数据的起始位置。然后将数据存入到对应的结构体当中。
//判断负载单元开始的标志
for(int i = 0; i < PmtStreamCount; i++)
{
if((TS_PackagePMT.astPMT_Stream[i].stream_type == 0x01)|| (TS_PackagePMT.astPMT_Stream[i].stream_type == 0x02)
|| (TS_PackagePMT.astPMT_Stream[i].stream_type ==0x1b))
{
TS_Program.VideoPID = TS_PackagePMT.astPMT_Stream[i].elementary_PID;
}
if((TS_PackagePMT.astPMT_Stream[i].stream_type == 0x03)|| (TS_PackagePMT.astPMT_Stream[i].stream_type == 0x04)
|| (TS_PackagePMT.astPMT_Stream[i].stream_type ==0x0f) || (TS_PackagePMT.astPMT_Stream[i].stream_type == 0x11))
{
TS_Program.AudioPID[ProgramPoint] = TS_PackagePMT.astPMT_Stream[i].elementary_PID;
ProgramPoint++;
}
}
//将数据存入结构体当中
TS_PMT TSPMT_table(TS_PMT TS_PackagePMT, unsigned char PMTtable[204])
{
int PMT_Length = 0;
unsigned char descriptor[204] = {0};
TS_PackagePMT.table_id = PMTtable[0];
TS_PackagePMT.section_syntax_indicator = PMTtable[1] >> 7;
TS_PackagePMT.zero = (PMTtable[1] >> 6) & 0x01;
TS_PackagePMT.reserved_1 = (PMTtable[1] >> 4) & 0x03;
TS_PackagePMT.section_length = ((PMTtable[1] & 0x0F) << 8) | PMTtable[2];
TS_PackagePMT.program_number = (PMTtable[3] << 8) | PMTtable[4];
TS_PackagePMT.reserved_2 = PMTtable[5] >> 6;
TS_PackagePMT.version_number = (PMTtable[5] >> 1) & 0x1F;
TS_PackagePMT.current_next_indicator = (PMTtable[5] << 7) >> 7;
TS_PackagePMT.section_number = PMTtable[6];
TS_PackagePMT.last_section_number = PMTtable[7];
TS_PackagePMT.reserved_3 = PMTtable[8] >> 5;
TS_PackagePMT.PCR_PID = ((PMTtable[8] << 8) | PMTtable[9]) & 0x1FFF;
TS_PackagePMT.reserved_4 = PMTtable[10] >> 4;
TS_PackagePMT.program_info_length = ((PMTtable[10] & 0x0F) << 8) | PMTtable[11];
if (0 != TS_PackagePMT.program_info_length)
{
memcpy(TS_PackagePMT.program_info_descriptor, PMTtable + 12, TS_PackagePMT.program_info_length);
ParseTS_Descriptor(TS_PackagePMT.program_info_descriptor);
}
PMT_Length = TS_PackagePMT.section_length + 3;
TS_PackagePMT.CRC_32 = (PMTtable[PMT_Length - 4] << 24) | (PMTtable[PMT_Length - 3] << 16)
| (PMTtable[PMT_Length - 2] << 8) | PMTtable[PMT_Length - 1];
return TS_PackagePMT;
}
//循环存放
for(PmtStreamPosition += TS_PackagePMT.program_info_length; PmtStreamPosition < (PMT_Length - 4); PmtStreamPosition += 5)
{
unsigned char descriptor[204] = {0};
TS_PackagePMT.astPMT_Stream[PmtStreamCount].stream_type = PMTtable[PmtStreamPosition];
TS_PackagePMT.astPMT_Stream[PmtStreamCount].reserved_5 = (PMTtable[PmtStreamPosition + 1]) >> 5;
TS_PackagePMT.astPMT_Stream[PmtStreamCount].elementary_PID = ((PMTtable[PmtStreamPosition + 1] & 0x1f) << 8)
| PMTtable[PmtStreamPosition + 2];
TS_PackagePMT.astPMT_Stream[PmtStreamCount].reserved_6 = (PMTtable[PmtStreamPosition + 3] >> 4);
TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length = ((PMTtable[PmtStreamPosition + 3] & 0xf) << 8)
| PMTtable[PmtStreamPosition + 4];
if(TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length != 0)
{
memcpy(TS_PackagePMT.astPMT_Stream[PmtStreamCount].descriptor, PMTtable + PmtStreamPosition + 5,
TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length);
PmtStreamPosition += TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length;
ParseTS_Descriptor(TS_PackagePMT.astPMT_Stream[PmtStreamCount].descriptor);
}
}
这样我们就能够获取到PMT表当中的信息。
注意:
- 因为PMT表结构中涉及到循环,所以我们在对for()循环里面的数据进行存储时,可以再将循环体里面的信息建立一个单独的结构体。再在主结构体当中建立它的结构体数组,这样我们就能够存储相关信息
- 在进行数据存储时,一定要记得计算Descriptor()描述符的长度,再做位运算的时候记得加上或删去该段长度。
4.5 小结
相对于解析PAT表,在解析PMT表的过程中增加了对结构体循环数据的存储,和描述符的数据存储。在后面的表格数据存储中,几乎每一张都涉及到了这两个方面。总体来说就是位运算和对每个字节信息的理解。对于关键的信息我们要加强记忆,遇到不懂或者含义不清的地方要及时参考标准文档。
5 SDT表的解析
在解析TS流的时候,首先寻找PAT表,根据PAT获取所有PMT表的PID;再寻找PMT表,获取该频段所有节目数据并保存。这样,只需要知道节目的PID就可以根据PacketHeade给出的PID过滤出不同的Packet,从而观看不同的节目。这些就是PAT表和PMT表之间的关系。而由于PID是一串枯燥的数字,用户不方便记忆、且容易输错,所以需要有一张表将节目名称和该节目的PID对应起来,DVB设计了SDT表来解决这个问题。 该表格标志一个节目的名称,并且能和PMT中的PID联系起来,这样用户就可以通过直接选择节目名称来选择节目了。
5.1 解析步骤
- 获取到PID = 0x0011的数据包,再根据table_id = 0x42(现行TS) ||table_id = 0x46(非现行TS),找到SDT表
- 根据解析出来的负载单元开始标志,确定数据包除包头外的有效数据起始位置,将有效数据提取保存。
- 将获取的有效数据存入SDT表的对应结构体中,方便保存。
5.2 SDT表的描述
“SDT描述了业务内容及信息,连接了NIT、EIT和PMT(PSI)”
SDT表主要提供关于Service的信息,如Service name,Service provider 等。
这里所说的业务,即Service;CCTV 1是一个Service(我们说“频道”),湖南卫视也是一个Service
PID = 0x0011
table_id = 0x42 (discribe actual TS,现行TS)
table_id = 0x46 (discribe not actual TS,非现行TS)
-
SDT表被切分成业务描述段(service_description_section),由PID为0x0011的TS包传输(BAT段也由PID为0x0011的TS包传输,但table_id不同)。
-
描述现行TS(即包含SDT表的TS)的SDT表的任何段的table_id都为0x42,且具有相同的table_id_extension(transport_stream_id)以及相同的original_network_id。 指向非现行TS的SDT表的任何段的table_id都应取0x46。
-
业务描述表SDT(见下一节的SDT表结构)中的每一个子表,都用来描述包含于一个特定的传输流中的业务。 该业务可能是现行传输流中的一部分,也可能是其他传输流中的一部分,可以根据table_id 来确定区分上述两种情况。
下表是SDT的结构:
| Syntax(句法结构) | No. of bits(所占位数) | Identifier(识别符) | Note(注释) |
|---|---|---|---|
| service_description_section(){ | |||
| table_id | 8 | uimsbf | 表标识符 |
| Section_syntax_indicator | 1 | bslbf | 段语法指示符,通常设置为“1” |
| Reserved_future_use | 1 | bslbf | 预留使用 |
| Reserved | 2 | bslbf | 保留 |
| Section_length | 12 | uimsbf | 段长度,12位,指出了此Section的长度,头两位为“00”,值不超过1021 |
| transport_stream_id | 16 | uimsbf | 传输流标识符,给出TS的识别号 |
| Reserved | 2 | bslbf | 保留 |
| Version_number | 5 | bslbf | sub_table的版本号,值为0~31,当sub_table信息改变时,值加1,若值已为31,则变化后值为0(循环),若curren_next_indicator的值为“1”,version_number指当前sub_table,若curren_next_indicator的值为“0”,version_number指下一个sub_table |
| Current_next_indicator | 1 | bslbf | 当前后续指示符,1位,“1”指sub_table是current, “0”指sub_table是next |
| Section_number | 8 | uimsbf | 段号,8位,给出section号,在sub_table中,第一个section其section_number为"0x00",每增加一个section,section_number加一 |
| last_section_number | 8 | uimsbf | 最后段号,sub_table中最后一个section的section_number |
| original_nerwork_id | 16 | uimsbf | 原始网络标识符,16位,给出originating delivery system中的网络识别号 |
| reserved_future_use | 8 | bslbf | 预留使用 |
for(i=0;i|
|
|
| |
| service_id | 16 | uimsbf | 业务标识符,16位,用来标识TS中的Service,等同于program_map_section中的program_number |
| reserved_future_use | 8 | bslbf | 预留使用 |
| EIT_schedule_flag | 1 | bslbf | EIT时间表标志,1位,若为“1”,则EIT schedule信息在当前TS中,为“0”,则TS中不存在EIT schedule信息 |
| EIT_present_following_flag | 1 | bslbf | EIT当前后续标志,1位,若为“1”,则EIT_present_following 信息在当前TS中,为“0”,则TS中不存在EIT_present_following信息。 |
| running_status | 3 | uimsbf | |
| freed_CA_mode | 1 | bslbf | 自由条件接收模式,1位,“0”表示无CA,“1”表示有CA |
| descriptors_loop_length | 12 | uimsbf | 描述符循环长度 |
for(i=0;i|
|
|
| |
| descriptor() | |||
| } | |||
| } | |||
| CRC_32 | 32 | rpchof | 32位, 表示CRC的值 |
| } |
注意:
- 在SDT表中也包含Descriptor()描述符。主要有Bouquet name descriptor(业务群名称描述符)、CA identifier descriptor(CA系统控制字描述符)、Country availability descriptor(有效国家描述符)、Data broadcast descriptor(数据广播描述符)、Linkage descriptor(链接描述符)、Mosaic descriptor(马赛克描述符)、Multilingual service descriptor(多语言服务描述符)、NVOD reference descriptor(NVOD参考描述符)、Service descriptor(业务描述符)、Telephone descriptor(电话描述符)、Time shifted service descriptor(时移业务描述符)
- 同样,描述符的数据长度由descriptors_loop_length()决定。
5.3 SDT表的获取
由上面信息可知道,SDT表的PID为0x0011,但是PID为0x0011的表还有BAT, ST。所以我们不能仅仅从PID这一条信息里找到准确的SDT数据包。所以我们在PID = 0x0011的基础上再判断其除包头外的有效字节的第一个字节(table_id)是否为0x0042或者0x0046。结合这两条判断条件,我们就可以准确筛选出来SDT表。
if(TS_PackageHead.PID == 0x0011)
{
value2 = SDT_BAT(TsPackage_len,TS_PackageHead,value2);
}
int SDT_BAT(int TsPackage_len,TS_Package_Head TS_PackageHead, int value2)
{
if(TS_PackageHead.payload_unit_start_indicator == 0)
{
if(TSdata[4] == 0x42 && value2 == 1)
{
ParseTS_SDT(TsPackage_len, TS_PackageHead);
value2++;
return value2;
}else if (TSdata[4] == 0x4a)
{
}
}
if(TS_PackageHead.payload_unit_start_indicator == 1)
{
if(TSdata[5] == 0x42 && value2 == 0)
{
ParseTS_SDT(TsPackage_len, TS_PackageHead);
value2++;
return value2;
}else if (TSdata[5] == 0x4a)
{
}
}
return value2;
}
注意:
- 因为PAT表和PMT表无需判断table_id就能够筛选出来,但是SDT表判断table_id。所以我们在提取数据包时要先判断包头的负载单元开始标志,防止table_id的信息出错。
5.4 SDT表信息解析
一样的顺序,我们需要先建立结构体,再描述符的循环里面可以创建一个unsigned char 类型的数组来保存描述符数据。
TS_SDT TSSDT_Table(TS_SDT TS_PackageSDT, unsigned char SDTtable[204])
{
int SDT_Length = 0;
TS_PackageSDT.table_id = SDTtable[0];
TS_PackageSDT.section_syntax_indicator = SDTtable[1] >> 7;
TS_PackageSDT.reserved_future_use_1 = (SDTtable[1] >> 6) & 0x01;
TS_PackageSDT.reserved_1 = (SDTtable[1] >> 4) & 0x03;
TS_PackageSDT.section_length = ((SDTtable[1] & 0x0F) << 8) | SDTtable[2];
TS_PackageSDT.transport_stream_id = (SDTtable[3] << 8) | SDTtable[4];
TS_PackageSDT.reserved_2 = SDTtable[5] >> 6;
TS_PackageSDT.version_number = (SDTtable[5] >> 1) & 0x1F;
TS_PackageSDT.current_next_indicator = (SDTtable[5] << 7) >> 7;
TS_PackageSDT.section_number = SDTtable[6];
TS_PackageSDT.last_section_number = SDTtable[7];
TS_PackageSDT.original_network_id = (SDTtable[8] << 8) | SDTtable[9];
TS_PackageSDT.reserved_future_use_2 = SDTtable[10];
SDT_Length = TS_PackageSDT.section_length + 3;
TS_PackageSDT.CRC_32 = (SDTtable[SDT_Length - 4] << 24) | (SDTtable[SDT_Length - 3] << 16)
| (SDTtable[SDT_Length - 2] << 8) | SDTtable[SDT_Length - 1];
return TS_PackageSDT;
}
TS_SDT ParseSDT_Section(TS_SDT TS_PackageSDT, unsigned char SDTtable[204])
{
int SDT_Length = 0;
int ServiceCount = 0;
int ServicePosition = 11;
unsigned char descriptor[204];
SDT_Length = TS_PackageSDT.section_length + 3;
for (ServicePosition = 11; ServicePosition < SDT_Length - 4; ServicePosition += 5)
{
TS_PackageSDT.SDT_Service[ServiceCount].service_id = (SDTtable[ServicePosition] << 8)
| SDTtable[ServicePosition + 1];
TS_PackageSDT.SDT_Service[ServiceCount].reserved_future_use = SDTtable[ServicePosition + 2] >> 2;
TS_PackageSDT.SDT_Service[ServiceCount].EIT_schedule_flag = (SDTtable[ServicePosition + 2] & 0x03) >> 1;
TS_PackageSDT.SDT_Service[ServiceCount].EIT_present_following_flag = SDTtable[ServicePosition + 2] & 0x01;
TS_PackageSDT.SDT_Service[ServiceCount].running_status = SDTtable[ServicePosition + 3] >> 5;
TS_PackageSDT.SDT_Service[ServiceCount].free_CA_mode = (SDTtable[ServicePosition + 3] & 0x1F) >> 4;
TS_PackageSDT.SDT_Service[ServiceCount].descriptors_loop_length = ((SDTtable[ServicePosition + 3] & 0x0F) << 8)
| SDTtable[ServicePosition + 4];
if (TS_PackageSDT.SDT_Service[ServiceCount].descriptors_loop_length != 0)
{
memcpy(TS_PackageSDT.SDT_Service[ServiceCount].descriptor, SDTtable + 5 + ServicePosition,
TS_PackageSDT.SDT_Service[ServiceCount].descriptors_loop_length);
ServicePosition += TS_PackageSDT.SDT_Service[ServiceCount].descriptors_loop_length;
ParseTS_Descriptor(TS_PackageSDT.SDT_Service[ServiceCount].descriptor);
}
ServiceCount++;
}
return TS_PackageSDT;
}
void ParseTS_SDT(int TsPackage_len,TS_Package_Head TS_PackageSDTHead)
{
TS_SDT TS_PackageSDT = {0};
unsigned char SDTtable[204] = {0};
if(TS_PackageSDTHead.payload_unit_start_indicator == 0)
{
memcpy(SDTtable, TSdata+4, TsPackage_len-4);
TS_PackageSDT = TSSDT_Table(TS_PackageSDT, SDTtable);
}
if(TS_PackageSDTHead.payload_unit_start_indicator == 1)
{
memcpy(SDTtable, TSdata+5, TsPackage_len-5);
TS_PackageSDT = TSSDT_Table(TS_PackageSDT, SDTtable);
}
TS_PackageSDT = ParseSDT_Section(TS_PackageSDT, SDTtable);
}
这样我们就可保存并获取到SDT表的信息。
注意:
- 在解析函数外进行负载单元开始标志的判断是为了甄别出SDT表,而解析函数内的负载单元开始标志的判断是为了区别出有效数据的位置。
5.5 小结
在SDT表的获取过程中,有两个难点。第一个就是对SDT表的获取,如何甄别出SDT,BAT和ST。第二个就是对于描述符的处理,所包含的信息很多。总而言之,每张表的在解析方法上都基本大同小异。
6 NIT表的解析
NIT描述了数字电视网络中与网络相关的信息。
6.1 解析步骤
- 通过PID = 0x0010 和 table_id = 0x40 || table_id = 0x41 来判断,获取到含有NIT表的数据包。
- 根据解析出来的负载单元开始标志,确定数据包除包头外的有效数据起始位置,将有效数据提取保存。
- 将获取的有效数据存入NIT表的对应结构体中,方便保存。
6.2 NIT表的描述
NIT表主要提供物理网络本身的一些信息。
PID = 0x0010
table_id = 0x40 (discribe actual newwork)
table_id = 0x41 (discribe not actual newwork)
-
NIT描述了数字电视网络中与网络相关的信息,但这个表本身的信息有限,更多的信息是依靠插入表中的描述符来提供的。 NIT常用的描述符有:网络名称描述符(network_name_descriptor)、有线传送系统(cable_delivery_system_descriptor)、业务列表描述符(service_list_descriptor)和链接描述符(linkage_descriptor)。
-
网络信息表NIT传递了与通过一个给定的网络传输的复用流/TS流的物理结构相关的信息,以及与网络自身特性相关的信息。在本标准应用的范围内,original_network_id 和 transport_stream_id 两个标识符相结合唯一确定了网络中的TS流。各网络被分配独立的 network_id值作为网络的唯一识别码。这些码字的分配见ETR 162。当NIT表在生成TS流的网络上传输时,network_id和original_network_id将取同一值。
-
当转换频道时,为了使存取时间最小,IRD可以在非易失性存储器上存储NIT表信息。除现行网络外,也可以为其他网络传输NIT表信息。现行网络的NIT表与其他网络的NIT表使用不同的table_id值来区分。
NIT的结构如下表:
Syntax(句法结构) No. of bits(所占位数) Identifier(识别符) Note(注释) network_information_section(){ table_id 8 uimsbf 表标识符 Section_syntax_indicator 1 bslbf 段语法指示符,通常设置为“1” Reserved_future_use 1 bslbf 预留使用 Reserved 2 bslbf 保留 Section_length 12 uimsbf 段长度,12位,指出了此Section的长度,头两位为“00”,值不超过1021 Network_id 16 uimsbf 网络标识符,16位字段。NIT表所描述的传输系统的网络标识,用以区别其他的传输系统。 Reserved 2 bslbf 保留 Version_number 5 uimsbf sub_table的版本号,值为0~31,当sub_table信息改变时,值加1,若值已为31,则变化后值为0(循环),若curren_next_indicator的值为“1”,version_number指当前sub_table,若curren_next_indicator的值为“0”,version_number指下一个sub_table Current_next_indicator 1 bslbf 当前后续指示符,1位,“1”指sub_table是current, “0”指sub_table是next Section_number 8 uimsbf 段号,8位,给出section号,在sub_table中,第一个section其section_number为"0x00",每增加一个section,section_number加一 last_section_number 8 uimsbf 最后段号,sub_table中最后一个section的section_number Reserved_future_use 4 bslbf 预留使用 Network_descriptors_length 12 uimsbf 网络描述符长度 for(i=0;i descriptor() First descriptor loop reserved_future_use 4 bslbf - transport_stream_loop_length 12 uimsbf 传输流循环长度 for(i=0;i transport_stream_id 16 uimsbf 传输流标识符,16位, 给出TS的识别号 original_network_id 16 uimsbf 原始网络标识符,16位,给出originating delivery system中的网络识别号 reserved_future_use 4 bslbf 预留使用 transport_descriptors_length 12 uimsbf 传输流描述符长度 for(i=0;i descriptor() Second descriptor loop Second descriptor loop } } CRC_32 32 rpchof 32位, 表示CRC的值 }
注意:
- 在这里我们注意到NIT结构里出现了两个循环,分别成为第一层循环和第二层循环; 每层循环都插入了一个描述符,也就是一共插入了两个描述符。 这两个描述符的特点如下:
| 第一层描述符 | 作用域是针对整个网络的,如插入网络名称描述符、链接描述符等 |
|---|---|
| 第二层描述符 | 作用域是第一层循环所代表的一个TS流,如插入有线传输系统描述符 |
-
第一层包含的描述符:Linkage descriptor(链接描述符)、Multiligual network name descriptor(多语种网络名称描述符)、Network name descriptor(网络名称描述符);
-
第二层包含的描述符:Delivery system descriptor(交付系统描述符)、Service list descriptor(业务列表描述符)、Frequency list descriptor(频率列表描述符);
-
此外,NIT表还有如下特点:
-
NIT表被切分为网络信息段(network_information_section)
-
任何NIT的段都必须由PID为0x0010的TS包传输
-
现行网络的NIT表任何段的table_id值应为0x40,且具有相同的table_id_extension即(network_id);
-
现行网络以外的其他网络NIT表的段table_id值应为0x41
6.3 NIT表的获取
由上面信息可知道,NIT表的PID为0x0010,但是PID为0x0010的表还有 ST。所以我们不能仅仅从PID这一条信息里找到准确的NIT数据包。所以我们在PID = 0x0010的基础上再判断其除包头外的有效字节的第一个字节(table_id)是否为0x0040或者0x0041。结合这两条判断条件,我们就可以准确筛选出来NIT表。
int ParseTS_NIT(int TsPackage_len,TS_Package_Head TS_PackageNITHead, int NITCount)
{
TS_NIT TS_PackageNIT = {0};
unsigned char NITtable[204] = {0};
if(TS_PackageNITHead.payload_unit_start_indicator == 0 && TSdata[4] == 0x40 )
{
memcpy(NITtable, TSdata+4, TsPackage_len-4);
TS_PackageNIT = TSNIT_Table(TS_PackageNIT, NITtable);
ParseNIT_Section(TS_PackageNIT, NITtable);
return ++NITCount;
}
if(TS_PackageNITHead.payload_unit_start_indicator == 1 && TSdata[5] == 0x40)
{
memcpy(NITtable, TSdata+5, TsPackage_len-5);
TS_PackageNIT = TSNIT_Table(TS_PackageNIT, NITtable);
ParseNIT_Section(TS_PackageNIT, NITtable);
return ++NITCount;
}
return NITCount;
}
注意:
- 因为网络情况是不断变化的,相对应NIT表也是会变化的,所以我们在解析时就不可以同PAT表那样只获取一次NIT表。
6.4 NIT表信息解析
我们以文档为标准,建立好NIT的结构体,然后通过位运算,将数据保存在结构体中。
TS_NIT TSNIT_Table(TS_NIT TS_PackageNIT, unsigned char NITtable[204])
{
int NetworkDescriptorLen = 0;
int NIT_Length = 0;
TS_PackageNIT.table_id = NITtable[0];
TS_PackageNIT.section_syntax_indicator = NITtable[1] >> 7;
TS_PackageNIT.reserved_future_use_1 = (NITtable[1] >> 6) & 0x01;
TS_PackageNIT.reserved_1 = (NITtable[1] >> 4) & 0x03;
TS_PackageNIT.section_length = ((NITtable[1] & 0x0F) << 8) | NITtable[2];
TS_PackageNIT.network_id = (NITtable[3] << 8) | NITtable[4];
TS_PackageNIT.reserved_2 = NITtable[5] >> 6;
TS_PackageNIT.version_number = (NITtable[5] >> 1) & 0x1F;
TS_PackageNIT.current_next_indicator = (NITtable[5] << 7) >> 7;
TS_PackageNIT.section_number = NITtable[6];
TS_PackageNIT.last_section_number = NITtable[7];
TS_PackageNIT.reserved_future_use_2 = NITtable[8] >> 4;
TS_PackageNIT.network_descriptors_length = ((NITtable[8] & 0x0F) << 8) | NITtable[9];
NetworkDescriptorLen = TS_PackageNIT.network_descriptors_length;
memcpy(TS_PackageNIT.network_descriptor, NITtable + 10, NetworkDescriptorLen);
ParseTS_Descriptor(TS_PackageNIT.network_descriptor);
TS_PackageNIT.reserved_future_use_2 = NITtable[10 + NetworkDescriptorLen] >> 4;
TS_PackageNIT.transport_stream_loop_length = ((NITtable[10 + NetworkDescriptorLen] & 0x0F) << 8)
| NITtable[10 + NetworkDescriptorLen + 1];
NIT_Length = TS_PackageNIT.section_length + 3;
TS_PackageNIT.CRC_32 = (NITtable[NIT_Length - 4] << 24) | (NITtable[NIT_Length - 3] << 16)
| (NITtable[NIT_Length - 2] << 8) | NITtable[NIT_Length - 1];
return TS_PackageNIT;
}
TS_NIT ParseNIT_Section(TS_NIT TS_PackageNIT, unsigned char NITtable[204])
{
int NIT_Length = 0;
int TransportPosition = 0;
int TranportCount = 0;
int NetworkDescriptorLen = 0;
NetworkDescriptorLen = TS_PackageNIT.network_descriptors_length;
NIT_Length = TS_PackageNIT.section_length + 3;
for (TransportPosition = 10 + NetworkDescriptorLen + 2; TransportPosition < NIT_Length - 4; TransportPosition += 6)
{
TS_PackageNIT.astNIT_Transport[TranportCount].transport_stream_id = (NITtable[TransportPosition] << 8)
| NITtable[TransportPosition + 1];
TS_PackageNIT.astNIT_Transport[TranportCount].original_network_id = (NITtable[TransportPosition + 2] << 8)
| NITtable[TransportPosition + 3];
TS_PackageNIT.astNIT_Transport[TranportCount].reserved_future_use = NITtable[TransportPosition + 4] >> 4;
TS_PackageNIT.astNIT_Transport[TranportCount].transport_descriptors_length = ((NITtable[TransportPosition + 4] & 0x0F) << 8)
| NITtable[TransportPosition + 5];
if (0 != TS_PackageNIT.astNIT_Transport[TranportCount].transport_descriptors_length)
{
memcpy(TS_PackageNIT.astNIT_Transport[TranportCount].descriptor, NITtable + 6 + TransportPosition,
TS_PackageNIT.astNIT_Transport[TranportCount].transport_descriptors_length);
TransportPosition += TS_PackageNIT.astNIT_Transport[TranportCount].transport_descriptors_length;
ParseTS_Descriptor(TS_PackageNIT.astNIT_Transport[TranportCount].descriptor);
}
TranportCount++;
}
return TS_PackageNIT;
}
注意:
- NIT表中大部分数据存在于Descriptor()中。
- 有些NIT表不是由一段数据包发送完成,而是通过好几个数据包来分段发送,所以在这里需要注意数据包获取的完整性和数据包合并的正确性。
6.5 小结
- 在解析NIT表时会遇到许多描述符,我们可以参考标准文档《En300468.V1.7.1_Specification for SI in DVB Systems》来查找相关描述符的信息。
- TS流中还有其他的表类型,例如:
- CAT表: CAT描述了节目的加密方式。
- EIT表:EIT按时间顺序提供每一个业务所包含的事件信息。
- BAT表:BAT将网络中的所有业务分成了多个业务群,以此界定用户。
- 这些表的解析方法步骤与上面列举的表的解析方法步骤类似,我们就按照标准文档为依据,进行逐步解析就可以了。
7 描述符的解析
描述符的类型也有很多,在标准文档中列举了各个描述符的作用含义和每个数据位所携带的信息。下面主要针对于部分描述符来做一个介绍和解析。
7.1 描述符的介绍
下表列出了部分在标准文档中声明或定义的描述符,并提供了描述符标签值和在SI表中的预期位置。但是这并不意味着它们在其他表中的使用受到限制。
| Descriptor | Tag value | NIT | BAT | SDT | EIT | TOT | PMT | SIT (see note 1) |
|---|---|---|---|---|---|---|---|---|
| network_name_descriptor | 0x40 | * | ||||||
| service_list_descriptor | 0x41 | * | * | |||||
| stuffing_descriptor | 0x42 | * | * | * | * | * | ||
| satellite_delivery_system_descriptor | 0x43 | * | ||||||
| cable_delivery_system_descriptor | 0x44 | * | ||||||
| VBI_data_descriptor | 0x45 | * | ||||||
| VBI_teletext_descriptor | 0x46 | * | ||||||
| bouquet_name_descriptor | 0x47 | * | * | * | ||||
| service_descriptor | 0x48 | * | * | |||||
| country_availability_descriptor | 0x49 | * | * | * | ||||
| linkage_descriptor | 0x4A | * | * | * | * | * | ||
| NVOD_reference_descriptor | 0x4B | * | * | |||||
| time_shifted_service_descriptor | 0x4C | * | * | |||||
| short_event_descriptor | 0x4D | * | * | |||||
| extended_event_descriptor | 0x4E | * | * | |||||
| time_shifted_event_descriptor | 0x4F | * | * | |||||
| component_descriptor | 0x50 | * | * | * | ||||
| mosaic_descriptor | 0x51 | * | * | * | ||||
| stream_identifier_descriptor | 0x52 | * | ||||||
| CA_identifier_descriptor | 0x53 | * | * | * | * | |||
| content_descriptor | 0x54 | * | * | |||||
| parental_rating_descriptor | 0x55 | * | * | |||||
| teletext_descriptor | 0x56 | * | ||||||
| telephone_descriptor | 0x57 | * | * | * | ||||
| … | … |
注意:
- 该表在《ETSI EN 300 468 V1.7.1 (2006-05)》文档的Page28。
7.2 描述符的获取
从表中我们可以得知不同的描述符的table_id,这个table_id就是我们在解析不同的表中的descriptor()部分的第一个字节。并且我们可以从其他信息中得知descriptor()部分的数据长度,所以我们很容易提取出来描述符的数据。
if(TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length != 0)
{
memcpy(TS_PackagePMT.astPMT_Stream[PmtStreamCount].descriptor, PMTtable + PmtStreamPosition + 5,
TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length);
PmtStreamPosition += TS_PackagePMT.astPMT_Stream[PmtStreamCount].ES_info_length;
ParseTS_Descriptor(TS_PackagePMT.astPMT_Stream[PmtStreamCount].descriptor);
}
注意:
- 有些结构体中的descriptor()是循环结构,所以一定要写好与之对应的数据存储方式。
7.3 描述符的解析
- 从描述符的介绍中我们了解到,区别于不同描述符之间的标识就是table_id。那么我们就可以用switch()选择语句来让不同的描述符数据传到对应的解析函数中。
void ParseTS_Descriptor(unsigned char Descriptor[204])
{
switch (Descriptor[0])
{
case 0x41:
Service_List_Descriptor(Descriptor);
break;
case 0x42:
Stuffing_Descriptor(Descriptor);
break;
case 0x48:
Service_Descriptor(Descriptor);
break;
case 0x52:
Stream_Identifier_Descriptor(Descriptor);
break;
default:
break;
}
}
- 而描述符的数据存储依旧需要使用到结构体,我们以table_id = 0x41为例:
void Service_List_Descriptor(unsigned char Descriptor[204])
{
SERVICR_LIST_DESCRIPTOR ServiceListTable = {0};
int ServiceListPosition = 0;
int ServiceInfoPosition = 0;
ServiceListTable.descriptor_tag = Descriptor[ServiceListPosition];
ServiceListTable.descriptor_length = Descriptor[ServiceListPosition+1];
for(int i = ServiceListPosition+2; i < ServiceListTable.descriptor_length; i += 3)
{
ServiceListTable.service_info[ServiceInfoPosition].service_id = Descriptor[i] << 8 | Descriptor[i+1];
ServiceListTable.service_info[ServiceInfoPosition].service_type = Descriptor[i+2];
ServiceInfoPosition++;
}
}
这样我们就能够得到table_id = 0x41的描述符信息。其他描述符的解析步骤与之类似,需要查看文档来帮助解析。
7.4 小结
描述符的信息有很多,种类也有很多。不过在代码结构上,我们只需写出各自的解析函数,然后通过switch()语句使之自行对号入座。
8 数据包的处理
因为在解析过程中需要获取到我们想要的数据,从而得到有用的信息。那么我们就要对解析出来的数据进行数据处理。
8.1 数据的存储
这次解析过程中,我主要通过链表的形式来对解析到的表格数据进行保存。首先建立每种类型表的首链表,作为我们提取数据的钥匙。
void List()
{
PmtPoint = (TS_PMT *)malloc(sizeof(TS_PMT));
PmtPoint->next = NULL;
PmtPoint->Previous = NULL;
TS_PackagePmtPoint = PmtPoint;
NitPoint = (TS_NIT *)malloc(sizeof(TS_NIT));
NitPoint->next = NULL;
NitPoint->Previous = NULL;
TS_PackageNitPoint = NitPoint;
BatPoint = (TS_BAT *)malloc(sizeof(TS_BAT));
BatPoint->next = NULL;
BatPoint->Previous = NULL;
TS_PackageBatPoint = BatPoint;
SdtPoint = (TS_SDT *)malloc(sizeof(TS_SDT));
SdtPoint->next = NULL;
SdtPoint->Previous = NULL;
TS_PackageSdtPoint = SdtPoint;
EitPoint = (TS_EIT *)malloc(sizeof(TS_EIT));
EitPoint->next = NULL;
EitPoint->Previous = NULL;
TS_PackageEitPoint = EitPoint;
}
然后在对每个表进行解析的时候进行链表连接操作,这样我们就能将每种类型的表很好的保存起来。
8.2 完整数据包的获取
因为有些表的数据长度超过了188个字节,故而无法通过一个数据包来传送,会利用多个数据包来进行分段传送。但是TS流数据包的发送又是随机的,所以我们需要通过一定的过滤机制来过滤出类型正确,顺序正确的数据包。
- 首先是通过payload_unit_start_indicator标志为’1’来确定含有首张表的数据包。
- 然后用一个变量来记录下这个数据包的continuity_counter。因为它的下一个数据包将会时continuity_counter+1。
- 再通过PID进行过滤,这样一来利用这三个过滤条件就可以得到我们想要的数据包。
8.3 数据包的合并
得到完整的数据包后,我们就要将它们有序的放在一起,然后通过结构体放进我们的链表里。
- 这里我定义了一个容量很大的数组,足够放下一段1027个字节。
- 然后通过过滤出的有序的顺序,利用memcpy函数将它们复制进这个新创立的数组中。
- 最后将这个数组放入结构体中进行保存。
8. 小结
这里要注意几点:
- 连接数组不能用strcat函数,因为他们会自动合并’\0’,所以当数组中存在数据0时就会被合并,从而导致数据错位。
- 因为TS流是随机发送,有些数据包会乱序,因此要做好标记位,并且对数组及时清零,避免因残留数据而导致数据错位。
- 这里对数据处理时,可以通过CRC校验位来防止对一张同样的表进行重复保存。
9 Makefile的编写
在代码的结构中,我将不同表的解析函数作为各自的.c文件,结构体和宏定义信息写为各自的.h文件。所以这次的Makefile语句就很简单。
CFLAGS += -g
src = $(wildcard ./*.c)
obj = $(patsubst %.c,%.o,$(src))
target = ts
$(target) : $(obj)
gcc $(obj) -o $(target)
%.o : %.c
gcc $(CFLAGS) -c $< -o $@
.PHONY: clean
clean:
rm -rf $(obj) $(target)
10 总结
- TS数据流的解析不单单只是拆解各种表,也不仅仅是打印出描述符的字节信息。而是需要知道TS流的产生,作用,含义;代码的构思,框架,优化。我们还要在这个过程中强化我们编程语言的基础,发散我们的编程思路,巩固所学知识,做到灵活运用。
- 本次对TS流的解析工作还没有完全做完,在整体代码框架上出现了许多问题,例如:无法灵活提取想用的信息;没有很好的解决不同表的解析次数问题;以及内存分配过剩;代码执行整体效率过低。在解析内容上的问题,例如:TOT表、EIT表等还未完成解析函数的编写;描述符解析函数也未编写完整;无法很好的兼容不同的测试文件;整个代码会因为建立过多无效链表而导致浪费多余空间。在自身能力上的问题,例如:基础知识掌握不牢固;数据结构无法灵活运用;英文文档的阅读能力还要加强。
- 总而言之,还是要不断学习理论知识,增加自己的代码编写量,仔细分析问题所在,找到解决问题的方法,继续完成本次任务。
问题:
- TS现行流和非现行流区别。
- 一张表中,提取了204字节数据包,发现表中section_length大于204个字节,后续数据在那里?是否与非现行流相关。
11 参考文献
- 百度百科;
- 《ETSI EN 300 468 V1.7.1 (2006-05)》;
- 《is138181》;
- 《DVB和PSI/SI的基础知识》;
- 《【PSI/SI学习系列】从TS流到PAT和PMT》
- 《PSI与SI入门详细介绍》