将随机数设成3407,让你的深度学习模型再涨一个点!文再附3种随机数设定方法
随机数重要性
深度学习已经在计算机视觉领域取得了巨大的成功,但我们是否曾想过为什么同样的模型在不同的训练过程中会有不同的表现?为什么使用同样的代码,就是和别人得到的结果不一样?怎么样才能保证自己每次跑同一个实验得到的结果都是一样的?
其中一个可能的原因就是随机数的选择。在本文中,我们将着重探讨如何通过合理设置随机数来提高深度学习模型的准确性(涨点大法)。以及如何固定随机数来保证实验的可重复性
arxiv上有篇极其离谱又很有深意的文章
torch.manual seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision. 论文链接
是的,你没看错,文章标题就言简意赅告诉你torch.manual seed(3407) is all you need
而且我发现很多群友已经用上了魔法(是我out了)
这篇文章做了很多实验,就解决了三个问题:
-
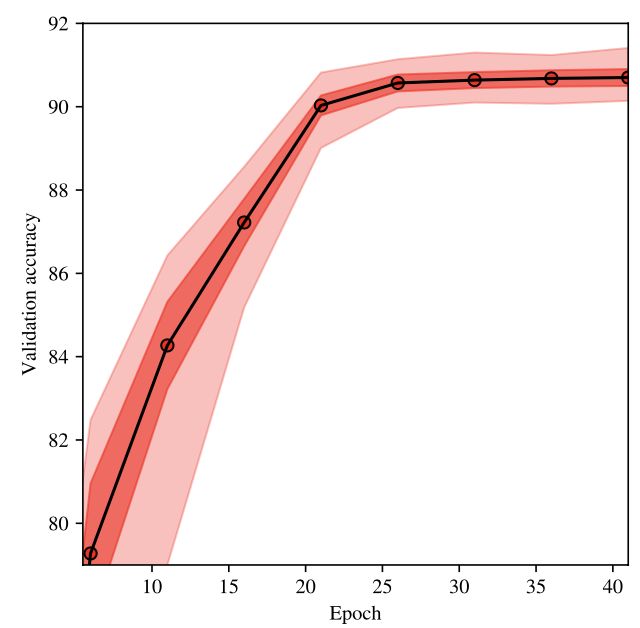
关于随机种子选择的分数分布是什么?答:随机种子变化时的精度分布相对尖锐,这意味着结果相当集中于平均值。一旦模型收敛,这种分布就相对稳定,这意味着有些种子本质上比其他种子好。
-
是否有黑天鹅,即有些种子会产生截然不同的结果?答:是。在对10000个种子的扫描中,作者获得了接近2%的最大和最小精度差异,这高于计算机视觉社区通常使用的重要阈值。(随机数设置的对,没准能涨2个点!)
-
对较大数据集的预处理是否减轻了种子选择引起的差异?答:是,它当然减少了由于使用不同种子而产生的差异,但并没有抹去这种差异,在Imagenet上,最大和最小准确度之间的差异仍然有0.5%
全文总结:随机数的选择很重要,当你涨点无果时,试下3407,没准儿有奇效~
随机数设定
那随机数怎么设置,在哪里设置呢?3种设定方法任你选,最后一种最简单!
1.pytorch中设定随机数
import numpy as np
import torch
import random
import os
seed_value = 3407 # 设定随机数种子
np.random.seed(seed_value)
random.seed(seed_value)
os.environ['PYTHONHASHSEED'] = str(seed_value) # 为了禁止hash随机化,使得实验可复现。
torch.manual_seed(seed_value) # 为CPU设置随机种子
torch.cuda.manual_seed(seed_value) # 为当前GPU设置随机种子(只用一块GPU)
torch.cuda.manual_seed_all(seed_value) # 为所有GPU设置随机种子(多块GPU)
torch.backends.cudnn.deterministic = True
以上代码放在所有使用随机数前就行。我习惯性放在import之后,在做事情前先把随机数设定好,比较安全。
下面进行简单地分析。愿意多看一点的继续,忙的直接粘贴复制上面代码即可。
上述代码的随机数主要是三个方面的设定。
1. python 和 numpy 随机数的设定
np.random.seed(seed_value)
random.seed(seed_value)
os.environ['PYTHONHASHSEED'] = str(seed_value) # 为了禁止hash随机化,使得实验可复现。
如果读取数据的过程采用了随机预处理(如RandomCrop、RandomHorizontalFlip等),那么对python、numpy的随机数生成器也需要设置种子。
2. pytorch 中随机数的设定
torch.manual_seed(seed_value) # 为CPU设置随机种子
torch.cuda.manual_seed(seed_value) # 为当前GPU设置随机种子(只用一块GPU)
torch.cuda.manual_seed_all(seed_value) # 为所有GPU设置随机种子(多块GPU)
pytorch中,会对模型的权重等进行初始化,因此也要设定随机数种子
3. Cudnn 中随机数的设定
cudnn中对卷积操作进行了优化,牺牲了精度来换取计算效率。如果需要保证可重复性,可以使用如下设置:
torch.backends.cudnn.deterministic = True
另外,也有人提到说dataloder中,可能由于读取顺序不同,也会造成结果的差异。这主要是由于dataloader采用了多线程(num_workers > 1)。目前暂时没有发现解决这个问题的方法,但是只要固定num_workers数目(线程数)不变,基本上也能够重复实验结果。
2.为随机数设定代码添加活动模板
这么长的代码,每次都要敲一遍,或者粘贴复制也很麻烦。因此,可以在pycharm里面设定一个模板,就可以快捷输入了。大致过程如下:
想要细节描述的可以百度 pycharm 活动模板的设定。
当我要使用这段代码的时候,敲自己定义的快捷字符串就可以了
3 MONAI框架随机数设定
Monai 对随机数的设定,一行代码就搞定了
from monai.utils import set_determinism
set_determinism(seed=3407)
和pytorch中使用方法是一样的,这个函数就是已经设定好了各种各样的随机数。使用起来更方便。亲测有用。
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连
