后端接口性能优化分析-3
- 作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 系列专栏:Spring源码、JUC源码
- 如果感觉博主的文章还不错的话,请三连支持一下博主哦
- 博主正在努力完成2023计划中:源码溯源,一探究竟
- 联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
文章目录
- 常见思路
-
- 8.锁粒度避免过粗
-
- synchronized
- redis分布式锁
-
- 非原子操作
- 忘了释放锁
- 释放了别人的锁
- 自旋锁
- 锁重入问题
-
- 加锁
- 解锁
- 锁竞争问题
-
- 读写锁
- 锁分段
- 锁超时问题
- 主从复制的问题
- 数据库分布式锁
-
- 基于数据库表的增删
- 基于数据库排他锁
- 9.切换存储方式:文件中转暂存数据
- 10.优化程序结构
-
- 逻辑结构
- 日志
- 11.压缩传输内容
- 12.线程池设计
-
- **线程池默认使用无界队列,任务过多导致OOM**
- **线程池创建线程过多,导致OOM**
- **共享线程池,次要逻辑拖垮主要逻辑**
- **线程池拒绝策略的坑,使用不当导致阻塞**
- **Spring内部线程池的坑**
- **使用线程池时,没有自定义命名**
- **线程池参数设置不合理**
- **线程池异常处理的坑**
- **线程池使用完毕后,忘记关闭**
- **ThreadLocal与线程池搭配,线程复用,导致信息错乱**
- 13.机器问题 (GC、线程打满、太多IO资源没关闭等等)
-
- GC
- 线程
- 资源
- 提升服务器硬件
- **关于JVM调优部分的内容,将会在后续专门的出一些文章,因为目前笔者对这方面理解还不够,所以暂不多做赘述!!!**
- 14.调用链路优化
-
- 跨地域调用
- 单元化架构:不同的用户路由到不同的集群单元
- 微服务拆分过细会导致Rpc调用较多
- 提前过滤,减少无效调用
- 拆分接口
常见思路
8.锁粒度避免过粗
synchronized
在高并发场景,为了防止超卖等情况,我们经常需要加锁来保护共享资源。但是,如果加锁的粒度过粗,是很影响接口性能的。
什么是加锁粒度呢?
其实就是就是你要锁住的范围是多大。比如你在家上卫生间,你只要锁住卫生间就可以了吧,不需要将整个家都锁起来不让家人进门吧,卫生间就是你的加锁粒度。
不管你是synchronized加锁还是redis分布式锁,只需要在共享临界资源加锁即可,不涉及共享资源的,就不必要加锁。这就好像你上卫生间,不用把整个家都锁住,锁住卫生间门就可以了。
比如,在业务代码中,有一个ArrayList因为涉及到多线程操作,所以需要加锁操作,假设刚好又有一段比较耗时的操作(代码中的slowNotShare方法)不涉及线程安全问题。反例加锁,就是一锅端,全锁住:
//不涉及共享资源的慢方法
private void slowNotShare() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
}
}
//错误的加锁方法
public int wrong() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
//加锁粒度太粗了,slowNotShare其实不涉及共享资源
synchronized (this) {
slowNotShare();
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
正例:
public int right() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
slowNotShare();//可以不加锁
//只对List这部分加锁
synchronized (data) {
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
对于锁的更细致使用来说,在java中提供了synchronized关键字给我们的代码加锁。
通常有两种写法:在方法上加锁 和 在代码块上加锁。
先看看如何在方法上加锁:
public synchronized doSave(String fileUrl) {
mkdir();
uploadFile(fileUrl);
sendMessage(fileUrl);
}
这里加锁的目的是为了防止并发的情况下,创建了相同的目录,第二次会创建失败,影响业务功能。
但这种直接在方法上加锁,锁的粒度有点粗。因为doSave方法中的上传文件和发消息方法,是不需要加锁的。只有创建目录方法,才需要加锁。
我们都知道文件上传操作是非常耗时的,如果将整个方法加锁,那么需要等到整个方法执行完之后才能释放锁。显然,这会导致该方法的性能很差,变得得不偿失。
这时,我们可以改成在代码块上加锁了,具体代码如下:
public void doSave(String path,String fileUrl) {
synchronized(this) {
if(!exists(path)) {
mkdir(path);
}
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
这样改造之后,锁的粒度一下子变小了,只有并发创建目录功能才加了锁。而创建目录是一个非常快的操作,即使加锁对接口的性能影响也不大。
最重要的是,其他的上传文件和发送消息功能,任然可以并发执行。
当然,这种做在单机版的服务中,是没有问题的。但现在部署的生产环境,为了保证服务的稳定性,一般情况下,同一个服务会被部署在多个节点中。
同时它也带来了新的问题:synchronized只能保证一个节点加锁是有效的,但如果有多个节点如何加锁呢?
这就需要使用:分布式锁了。目前主流的分布式锁包括:redis分布式锁 和 数据库分布式锁。
redis分布式锁
在分布式系统中,由于redis分布式锁相对于更简单和高效,成为了分布式锁的首先,被我们用到了很多实际业务场景当中。
public void doSave(String path,String fileUrl) {
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
uploadFile(fileUrl);
sendMessage(fileUrl);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
}
跟之前使用synchronized关键字加锁时一样,这里锁的范围也太大了,换句话说就是锁的粒度太粗,这样会导致整个方法的执行效率很低。
其实只有创建目录的时候,才需要加分布式锁,其余代码根本不用加锁。
于是,我们需要优化一下代码:
public void doSave(String path,String fileUrl) {
if(this.tryLock()) {
mkdir(path);
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
private boolean tryLock() {
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
}
上面代码将加锁的范围缩小了,只有创建目录时才加了锁。这样看似简单的优化之后,接口性能能提升很多。
但是Redis锁也存在着一些弊端情况,如下共有八条总结性建议:
非原子操作
使用redis的分布式锁,我们首先想到的可能是setNx命令。
if (jedis.setnx(lockKey, val) == 1) {
jedis.expire(lockKey, timeout);
}
这段代码确实可以加锁成功,但你有没有发现什么问题?
加锁操作和后面的设置超时时间是分开的,并非原子操作。
假如加锁成功,但是设置超时时间失败了,该lockKey就变成永不失效。假如在高并发场景中,有大量的lockKey加锁成功了,但不会失效,有可能直接导致redis内存空间不足。
忘了释放锁
上面说到使用setNx命令加锁操作和设置超时时间是分开的,并非原子操作。
而在redis中还有set命令,该命令可以指定多个参数。
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
其中:
lockKey:锁的标识requestId:请求idNX:只在键不存在时,才对键进行设置操作。PX:设置键的过期时间为 millisecond 毫秒。expireTime:过期时间
set命令是原子操作,加锁和设置超时时间,一个命令就能轻松搞定。
使用set命令加锁,表面上看起来没有问题。但如果仔细想想,加锁之后,每次都要达到了超时时间才释放锁,会不会有点不合理?加锁后,如果不及时释放锁,会有很多问题。
分布式锁更合理的用法是:
- 手动加锁
- 业务操作
- 手动释放锁
- 如果手动释放锁失败了,则达到超时时间,redis会自动释放锁。

那么问题来了,如何释放锁呢?
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}
只在finally中释放锁,就够了吗?
释放了别人的锁
在多线程场景中,可能会出现释放了别人的锁的情况。
假如线程A和线程B,都使用lockKey加锁。线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间。这时候,redis会自动释放lockKey锁。此时,线程B就能给lockKey加锁成功了,接下来执行它的业务操作。恰好这个时候,线程A执行完了业务功能,释放了锁lockKey。这不就出问题了,线程B的锁,被线程A释放了。
那么,如何解决这个问题呢?
不知道你们注意到没?在使用set命令加锁时,除了使用lockKey锁标识,还多设置了一个参数:requestId,为什么要需要记录requestId呢?
答:requestId是在释放锁的时候用的。
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;
在释放锁的时候,先获取到该锁的值(之前设置值就是requestId),然后判断跟之前设置的值是否相同,如果相同才允许删除锁,返回成功。如果不同,则直接返回失败。
换句话说就是:自己只能释放自己加的锁,不允许释放别人加的锁。
当然在这里也需要保证 判断 和 删除的原子性问题
自旋锁
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
此外,还有一种场景:
比如,有两个线程同时上传文件到sftp,上传文件前先要创建目录。假设两个线程需要创建的目录名都是当天的日期,比如:20210920,如果不做如何控制,这样直接并发的创建,第二个线程会失败。
有同学会说:这还不容易,加一个redis分布式锁就能解决问题了,此外再判断一下,如果目录已经存在就不创建,只有目录不存在才需要创建。
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
只是加redis分布式锁是不够的,因为第二个请求如果加锁失败了,接下来,是返回失败呢?还是返回成功呢?

显然肯定是不能返回失败的,如果返回失败了,这个问题还是没有被解决。如果文件还没有上传成功,直接返回成功会有更大的问题。头疼,到底该如何解决呢?
答:使用自旋锁
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
long time = System.currentTimeMillis() - start;
if (time>=timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;
在规定的时间,比如500毫秒内,自旋不断尝试加锁(说白了,就是在死循环中,不断尝试加锁),如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
锁重入问题
我们都知道redis分布式锁是互斥的。如果我们对某个key加锁了,如果该key对应的锁还没失效,再用相同key去加锁,大概率会失败。
假设在某个请求中,需要获取一颗满足条件的菜单树或者分类树。我们以菜单为例,这就需要在接口中从根节点开始,递归遍历出所有满足条件的子节点,然后组装成一颗菜单树。
需要注意的是菜单不是一成不变的,在后台系统中运营同学可以动态添加、修改和删除菜单。为了保证在并发的情况下,每次都可能获取最新的数据,这里可以加redis分布式锁。
加redis分布式锁的思路是对的。但接下来问题来了,在递归方法中递归遍历多次,每次都是加的同一把锁。递归第一层当然是可以加锁成功的,但递归第二层、第三层…第N层,不就会加锁失败了?
递归方法中加锁的伪代码如下:
private int expireTime = 1000;
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}
如果你直接这么用,看起来好像没有问题。但最终执行程序之后发现,等待你的结果只有一个:出现异常。
因为从根节点开始,第一层递归加锁成功,还没释放说,就直接进入第二层递归。因为requestId作为key的锁已经存在,所以第二层递归大概率会加锁失败,然后返回到第一层。第一层接下来正常释放锁,然后整个递归方法直接返回了。
那么这个问题该如何解决呢?
答:使用可重入锁。
我们以redisson框架为例,它的内部实现了可重入锁的功能。
伪代码如下:
private int expireTime = 1000;
public void run(String lockKey) {
RLock lock = redisson.getLock(lockKey);
this.fun(lock,1);
}
public void fun(RLock lock,int level){
try{
lock.lock(5, TimeUnit.SECONDS);
if(level<=10){
this.fun(lock,++level);
} else {
return;
}
} finally {
lock.unlock();
}
}
接下来,聊聊redisson可重入锁的实现原理。
加锁
- 先判断如果锁名不存在,则加锁。
- 然后判断判断如果锁名和requestId值都存在,则使用hincrby命令给该锁名和requestId值计数,每次都加1。注意一下,这里就是重入锁的关键,锁重入一次就加1。
- 如果锁名存在,但值不是requestId,则返回过期时间。
解锁
- 先判断如果锁名和requestId值不存在,则时间返回。
- 如果锁名和requestId值存在,则重入锁减1。
- 如果减1后,重入锁的value值还大于0,说明还有引用,则重试设置过期时间。
- 如果减1后,重入锁的value值还等于0,则可以删除锁,然后发消息通知等待线程抢锁。
锁竞争问题
如果有大量写入的场景,使用普通的redis分布式锁是没有问题的。
但如果有些业务场景,写入的操作比较少,反而有大量读取的操作。直接使用普通的redis分布式锁,性能会不会不太好?
我们都知道,锁的粒度越粗,多个线程抢锁时竞争就越激烈,造成多个线程锁等待的时间也就越长,性能也就越差。
所以,提升redis分布式锁性能的第一步,就是要把锁的粒度变细。
读写锁
众所周知,加锁的目的是为了保证,在并发环境中读写数据的安全性,即不会出现数据错误或者不一致的情况。
但在绝大多数实际业务场景中,一般是读数据的频率远远大于写数据。而线程间的并发读操作是并不涉及并发安全问题,我们没有必要给读操作加互斥锁,只要保证读写、写写并发操作上锁是互斥的就行,这样可以提升系统的性能。
我们以redisson框架为例,它内部已经实现了读写锁的功能。
读锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//业务操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}
写锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//业务操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
将读锁和写锁分开,最大的好处是提升读操作的性能,因为读和读之间是共享的,不存在互斥性。而我们的实际业务场景中,绝大多数数据操作都是读操作。所以,如果提升了读操作的性能,也就会提升整个锁的性能。
下面总结一个读写锁的特点:
- 读与读是共享的,不互斥
- 读与写互斥
- 写与写互斥
锁分段
此外,为了减小锁的粒度,比较常见的做法是将大锁:分段。
在java中ConcurrentHashMap,就是将数据分为16段,每一段都有单独的锁,并且处于不同锁段的数据互不干扰,以此来提升锁的性能。
class ConcurrentHashMap<K, V> {
// 初始化数组,存放 Segment
private Segment[] segments;
public ConcurrentHashMap(int initialCapacity) {
segments = new Segment[16]; // 初始化为 16 个 Segment
for (int i = 0; i < segments.length; i++) {
segments[i] = new Segment();
}
}
// 获取 Segment
private Segment segmentFor(int hash) {
return segments[(segments.length - 1) & hash];
}
// 获取值
public V get(K key) {
int hash = hash(key);
return segmentFor(hash).get(key, hash);
}
// 存入值
public void put(K key, V value) {
int hash = hash(key);
segmentFor(hash).put(key, value, hash);
}
// Segment 类
class Segment {
// 使用 ReentrantLock 作为锁
private final ReentrantLock lock = new ReentrantLock();
// 存放键值对
private Map<K, V> map = new HashMap<>();
public V get(K key, int hash) {
lock.lock();
try {
// 获取值
return map.get(key);
} finally {
lock.unlock();
}
}
public void put(K key, V value, int hash) {
lock.lock();
try {
// 存入值
map.put(key, value);
} finally {
lock.unlock();
}
}
}
}
放在实际业务场景中,我们可以这样做:
比如在秒杀扣库存的场景中,现在的库存中有2000个商品,用户可以秒杀。为了防止出现超卖的情况,通常情况下,可以对库存加锁。如果有1W的用户竞争同一把锁,显然系统吞吐量会非常低。
为了提升系统性能,我们可以将库存分段,比如:分为100段,这样每段就有20个商品可以参与秒杀。
在秒杀的过程中,先把用户id获取hash值,然后除以100取模。模为1的用户访问第1段库存,模为2的用户访问第2段库存,模为3的用户访问第3段库存,后面以此类推,到最后模为100的用户访问第100段库存。
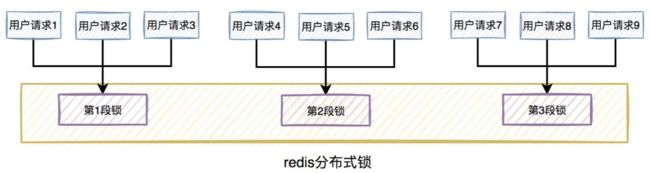
如此一来,在多线程环境中,可以大大的减少锁的冲突。以前多个线程只能同时竞争1把锁,尤其在秒杀的场景中,竞争太激烈了,简直可以用惨绝人寰来形容,其后果是导致绝大数线程在锁等待。现在多个线程同时竞争100把锁,等待的线程变少了,从而系统吞吐量也就提升了。
锁超时问题
前面提到过,如果线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间,这时候redis会自动释放线程A加的锁。
通常我们加锁的目的是:为了防止访问临界资源时,出现数据异常的情况。比如:线程A在修改数据C的值,线程B也在修改数据C的值,如果不做控制,在并发情况下,数据C的值会出问题。
为了保证某个方法,或者段代码的互斥性,即如果线程A执行了某段代码,是不允许其他线程在某一时刻同时执行的,我们可以用synchronized关键字加锁。
但这种锁有很大的局限性,只能保证单个节点的互斥性。如果需要在多个节点中保持互斥性,就需要用redis分布式锁。
假设线程A加redis分布式锁的代码,包含代码1和代码2两段代码。
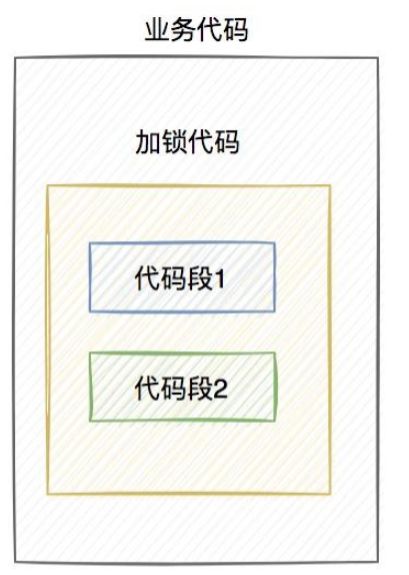
由于该线程要执行的业务操作非常耗时,程序在执行完代码1的时,已经到了设置的超时时间,redis自动释放了锁。而代码2还没来得及执行。

此时,代码2相当于裸奔的状态,无法保证互斥性。假如它里面访问了临界资源,并且其他线程也访问了该资源,可能就会出现数据异常的情况。(PS:我说的访问临界资源,不单单指读取,还包含写入)
那么,如何解决这个问题呢?
答:如果达到了超时时间,但业务代码还没执行完,需要给锁自动续期。
我们可以使用TimerTask类,来实现自动续期的功能:
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自动续期逻辑
}
}, 10000, TimeUnit.MILLISECONDS);
获取锁之后,自动开启一个定时任务,每隔10秒钟,自动刷新一次过期时间。这种机制在redisson框架中,有个比较霸气的名字:watch dog,即传说中的看门狗。
需要注意的地方是:在实现自动续期功能时,还需要设置一个总的过期时间,可以跟redisson保持一致,设置成30秒。如果业务代码到了这个总的过期时间,还没有执行完,就不再自动续期了。
自动续期的功能是获取锁之后开启一个定时任务,每隔10秒判断一下锁是否存在,如果存在,则刷新过期时间。如果续期3次,也就是30秒之后,业务方法还是没有执行完,就不再续期了。
主从复制的问题
如果redis存在多个实例。比如:做了主从,或者使用了哨兵模式,基于redis的分布式锁的功能,就会出现问题。
假设redis现在用的主从模式,1个master节点,3个slave节点。master节点负责写数据,slave节点负责读数据。
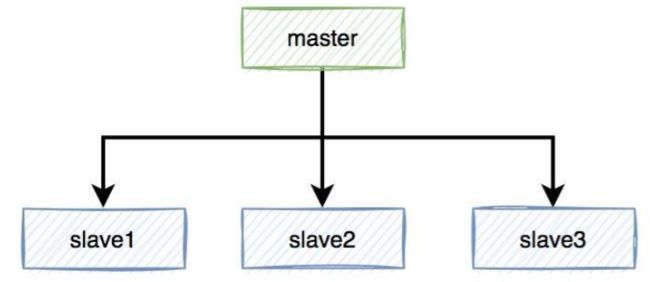
本来是和谐共处,相安无事的。redis加锁操作,都在master上进行,加锁成功后,再异步同步给所有的slave。
突然有一天,master节点由于某些不可逆的原因,挂掉了。
这样需要找一个slave升级为新的master节点,假如slave1被选举出来了。

果有个锁A比较悲催,刚加锁成功master就挂了,还没来得及同步到slave1。
这样会导致新master节点中的锁A丢失了。后面,如果有新的线程,使用锁A加锁,依然可以成功,分布式锁失效了。
那么,如果解决这个问题呢?
答:redisson框架为了解决这个问题,提供了一个专门的类:RedissonRedLock,使用了Redlock算法。
RedissonRedLock解决问题的思路如下:
- 需要搭建几套相互独立的redis环境,假如我们在这里搭建了3套。
- 每套环境都有一个redisson node节点。
- 多个redisson node节点组成了RedissonRedLock。
- 环境包含:单机、主从、哨兵和集群模式,可以是一种或者多种混合。
在这里我们以主从为例,架构图如下:

RedissonRedLock加锁过程如下:
- 循环向所有的redisson node节点加锁,假设节点数为N,例子中N等于5。
- 如果在N个节点当中,有N/2 + 1个节点加锁成功了,那么整个RedissonRedLock加锁是成功的。
- 如果在N个节点当中,小于N/2 + 1个节点加锁成功,那么整个RedissonRedLock加锁是失败的。
- 如果中途发现各个节点加锁的总耗时,大于等于设置的最大等待时间,则直接返回失败。
从上面可以看出,使用Redlock算法,确实能解决多实例场景中,假如master节点挂了,导致分布式锁失效的问题。
但也引出了一些新问题,比如:
- 需要额外搭建多套环境,申请更多的资源,需要评估一下,经费是否充足。
- 如果有N个redisson node节点,需要加锁N次,最少也需要加锁N/2+1次,才知道redlock加锁是否成功。显然,增加了额外的时间成本,有点得不偿失。
数据库分布式锁
基于数据库表的增删
基于数据库表增删是最简单的方式,首先创建一张锁的表主要包含下列字段:方法名,时间戳等字段。
具体使用的方法为:当需要锁住某个方法时,往该表中插入一条相关的记录。需要注意的是,方法名有唯一性约束。如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。执行完毕,需要删除该记录。
基于数据库排他锁
我们还可以通过数据库的排他锁来实现分布式锁。基于 Mysql 的 InnoDB 引擎,可以使用以下方法来实现加锁操作:
public void lock(){
connection.setAutoCommit(false)
int count = 0;
while(count < 4){
try{
select * from lock where lock_name=xxx for update;
if(结果不为空){
//代表获取到锁
return;
}
}catch(Exception e){
}
//为空或者抛异常的话都表示没有获取到锁
sleep(1000);
count++;
}
throw new LockException();
}
在查询语句后面增加 for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。其他没有获取到锁的就会阻塞在上述 select 语句上,可能的结果有 2 种,在超时之前获取到了锁,在超时之前仍未获取到锁。
获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行业务逻辑,执行完业务之后释放锁。
9.切换存储方式:文件中转暂存数据
如果数据太大,落地数据库实在是慢的话,就可以考虑先用文件的方式暂存。先保存文件,再异步下载文件,慢慢保存到数据库。
比如说一个转账接口,如果是并发开启,10个并发度,每个批次1000笔转账明细数据,数据库插入会特别耗时,大概6秒左右;这个跟我们公司的数据库同步机制有关,并发情况下,因为优先保证同步,所以并行的插入变成串行啦,就很耗时。
数据库同步机制可能导致并行的插入变成串行的原因有很多,下面列举了一些可能的情况:
- 锁竞争:当多个事务同时尝试向相同的数据页或数据行插入数据时,数据库系统可能会使用锁来确保数据的一致性。如果同步机制导致大量的锁竞争,那么并行插入操作可能会被迫等待其他事务释放锁,从而导致串行化。
- 同步点阻塞:某些数据库同步机制可能会引入同步点,要求所有的写操作都必须在这些同步点进行同步,这样就会导致并行的写操作变成串行化。
- 冲突检测与重试:在数据库同步的过程中,可能会发生数据冲突,系统需要检测并解决这些冲突。这种检测和解决过程可能会导致并行插入变成串行化,因为某些操作需要等待其他操作完成后才能执行。
- 数据复制延迟:如果数据库采用了主从复制或者集群复制的机制,数据同步可能会引入一定的延迟。在这种情况下,并行的插入操作可能会因为数据尚未完全同步而变成串行化。
优化前,1000笔明细转账数据,先落地DB数据库,返回处理中给用户,再异步转账。如图:
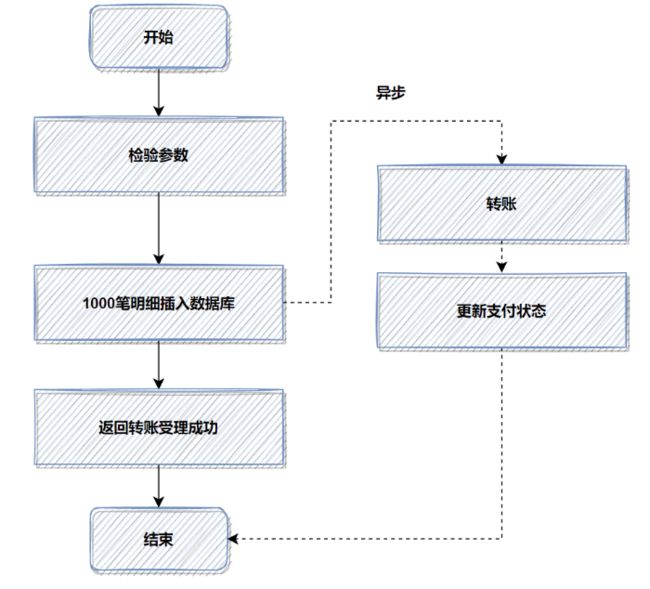
记得当时压测的时候,高并发情况,这1000笔明细入库,耗时都比较大。所以我转换了一下思路,把批量的明细转账记录保存的文件服务器,然后记录一笔转账总记录到数据库即可。接着异步再把明细下载下来,进行转账和明细入库。最后优化后,性能提升了十几倍。
优化后,流程图如下:
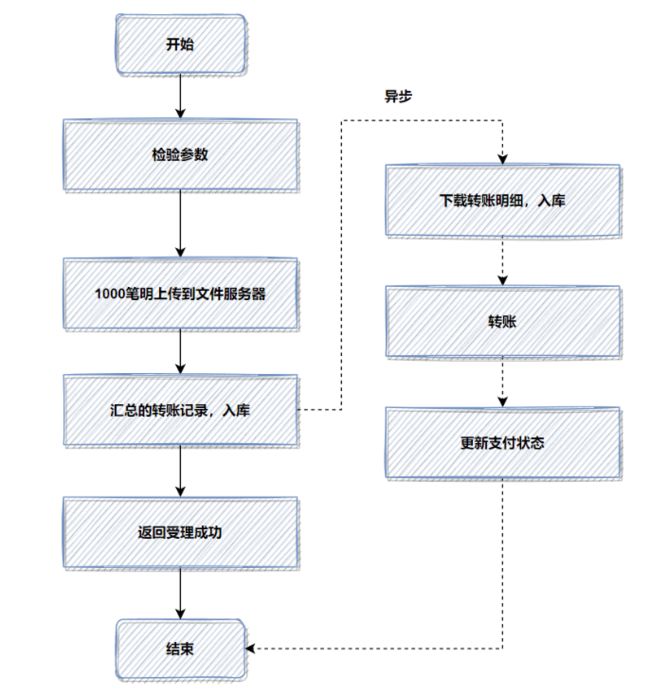
如果你的接口耗时瓶颈就在数据库插入操作这里,用来批量操作等,还是效果还不理想,就可以考虑用文件或者MQ等暂存。有时候批量数据放到文件,会比插入数据库效率更高。
10.优化程序结构
逻辑结构
优化程序逻辑、程序代码,是可以节省耗时的。比如,你的程序创建多不必要的对象、或者程序逻辑混乱,多次重复查数据库、又或者你的实现逻辑算法不是最高效的,等等。
我举个简单的例子:复杂的逻辑条件,有时候调整一下顺序,就能让你的程序更加高效。
假设业务需求是这样:如果用户是会员,第一次登陆时,需要发一条感谢短信。如果没有经过思考,代码直接这样写了
if(isUserVip && isFirstLogin){
sendSmsMsg();
}
假设有5个请求过来,isUserVip判断通过的有3个请求,isFirstLogin通过的只有1个请求。那么以上代码,isUserVip执行的次数为5次,isFirstLogin执行的次数也是3次,如下:

如果调整一下isUserVip和isFirstLogin的顺序:
if(isFirstLogin && isUserVip ){
sendMsg();
}
isFirstLogin执行的次数是5次,isUserVip执行的次数是1次:

程序是不是变得更高效了呢?
日志
在高并发的查询场景下,打印日志可能导致接口性能下降的问题。
在排查问题时顺手打印了日志并且带上线。高峰期时发现接口的 tp99 耗时大幅增加,同时 CPU 负载和垃圾回收频率也明显增加,磁盘负载也增加很多。日志删除后,系统回归正常。
特别是在日志中包含了大数组或大对象时,更要谨慎,避免打印这些日志。
不打日志,无法有效排查问题。怎么办呢?
为了有效地排查问题,建议引入白名单机制。具体做法是,在打印日志之前,先判断用户是否在白名单中,如果不在,则不打印日志;如果在,则打印日志。通过将公司内的产品、开发和测试人员等相关同事加入到白名单中,有利于及时发现线上问题。当用户提出投诉时,也可以将相关用户添加到白名单,并要求他们重新操作以复现问题。
这种方法既满足了问题排查的需求,又避免了给线上环境增加压力。(在测试环境中,可以完全开放日志打印功能)
11.压缩传输内容
压缩传输内容,传输报文变得更小,因此传输会更快啦。10M带宽,传输10k的报文,一般比传输1M的会快呀。
打个比喻,一匹千里马,它驮着100斤的货跑得快,还是驮着10斤的货物跑得快呢?
再举个视频网站的例子:
如果不对视频做任何压缩编码,因为带宽又是有限的。巨大的数据量在网络传输的耗时会比编码压缩后,慢好多倍。
压缩文本数据可以有效地减少该数据所需的存储空间,从而提高数据库和缓存的空间利用率。然而,压缩和解压缩的过程会增加CPU的负载,因此需要仔细考虑是否有必要进行数据压缩。此外,还需要评估压缩后数据的效果,即压缩对数据的影响如何。
比如说使用GZIP压缩算法的cpu负载和耗时都是比较高的。使用压缩非但不能起到降低接口耗时的效果,可能导致接口耗时增加,要谨慎使用。除此之外,还有其他压缩算法在压缩时间和压缩率上有所权衡。可以选择适合的自己的压缩算法。
12.线程池设计
我们使用线程池,就是让任务并行处理,更高效地完成任务。但是有时候,如果线程池设计不合理,接口执行效率则不太理想。
一般我们需要关注线程池的这几个参数:核心线程、最大线程数量、阻塞队列。
- 如果核心线程过小,则达不到很好的并行效果。
- 如果阻塞队列不合理,不仅仅是阻塞的问题,甚至可能会
OOM - 如果线程池不区分业务隔离,有可能核心业务被边缘业务拖垮。
下面是线程池设计建议总结:
线程池默认使用无界队列,任务过多导致OOM
JDK开发者提供了线程池的实现类,我们基于Executors组件,就可以快速创建一个线程池。日常工作中,一些小伙伴为了开发效率,反手就用Executors新建个线程池。写出类似以下的代码:
public class NewFixedTest {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
});
}
}
}
使用newFixedThreadPool创建的线程池,是会有坑的,它默认是无界的阻塞队列,如果任务过多,会导致OOM问题。运行一下以上代码,出现了OOM。
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371)
at com.example.dto.NewFixedTest.main(NewFixedTest.java:14)
这是因为newFixedThreadPool使用了无界的阻塞队列的LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长(比如,上面demo代码设置了10秒),会导致队列的任务越积越多,导致机器内存使用不停飙升, 最终出现OOM。
看下newFixedThreadPool的相关源码,是可以看到一个无界的阻塞队列的,如下:
//阻塞队列是LinkedBlockingQueue,并且是使用的是无参构造函数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//无参构造函数,默认最大容量是Integer.MAX_VALUE,相当于无界的阻塞队列的了
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
因此,工作中,建议大家自定义线程池,并使用指定长度的阻塞队列。
线程池创建线程过多,导致OOM
有些小伙伴说,既然Executors组件创建出的线程池newFixedThreadPool,使用的是无界队列,可能会导致OOM。那么,Executors组件还可以创建别的线程池,如newCachedThreadPool,我们用它也不行嘛?
我们可以看下newCachedThreadPool的构造函数:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
它的最大线程数是Integer.MAX_VALUE。大家应该意识到使用它,可能会引发什么问题了吧。没错,如果创建了大量的线程也有可能引发OOM!
所以我们使用线程池的时候,还要当心线程创建过多,导致OOM问题。大家尽量不要使用newCachedThreadPool,并且如果自定义线程池时,要注意一下最大线程数。
共享线程池,次要逻辑拖垮主要逻辑
要避免所有的业务逻辑共享一个线程池。比如你用线程池A来做登录异步通知,又用线程池A来做对账。如下图:
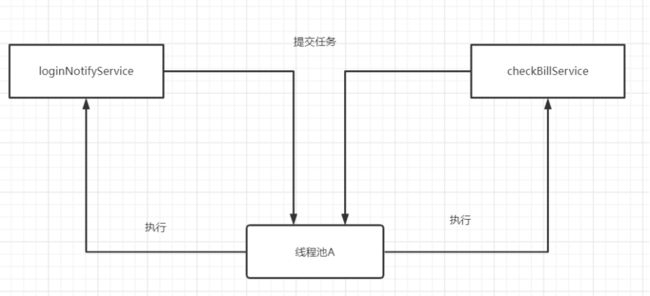
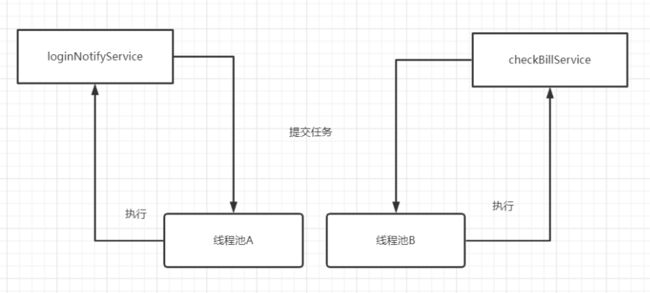
如果对账任务checkBillService响应时间过慢,会占据大量的线程池资源,可能直接导致没有足够的线程资源去执行loginNotifyService的任务,最后影响登录。就这样,因为一个次要服务,影响到重要的登录接口,显然这是绝对不允许的。因此,我们不能将所有的业务一锅炖,都共享一个线程池,因为这样做,风险太高了,犹如所有鸡蛋放到一个篮子里。应当做线程池隔离!
线程池拒绝策略的坑,使用不当导致阻塞
我们知道线程池主要有四种拒绝策略,如下:
- AbortPolicy: 丢弃任务并抛出
RejectedExecutionException异常。(默认拒绝策略) - DiscardPolicy:丢弃任务,但是不抛出异常。
- DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务。
- CallerRunsPolicy:由调用方线程处理该任务。
如果线程池拒绝策略设置不合理,就容易有坑。我们把拒绝策略设置为DiscardPolicy或DiscardOldestPolicy并且在被拒绝的任务,Future对象调用get()方法,那么调用线程会一直被阻塞。
温馨提示,日常开发中,使用 Future.get() 时,尽量使用带超时时间的,因为它是阻塞的。
future.get(1, TimeUnit.SECONDS);
Spring内部线程池的坑
工作中,个别开发者,为了快速开发,喜欢直接用spring的@Async,来执行异步任务。
@Async
public void testAsync() throws InterruptedException {
System.out.println("处理异步任务");
TimeUnit.SECONDS.sleep(new Random().nextInt(100));
}
Spring内部线程池,其实是SimpleAsyncTaskExecutor,这玩意有点坑,它不会复用线程的,它的设计初衷就是执行大量的短时间的任务。
也就是说来了一个请求,就会新建一个线程!大家使用spring的@Async时,要避开这个坑,自己再定义一个线程池。正例如下:
@Bean(name = "threadPoolTaskExecutor")
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor=new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setThreadNamePrefix("tianluo-%d");
// 其他参数设置
return new ThreadPoolTaskExecutor();
}
使用线程池时,没有自定义命名
使用线程池时,如果没有给线程池一个有意义的名称,将不好排查回溯问题。这不算一个坑吧,只能说给以后排查埋坑
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(20));
executorOne.execute(()->{
throw new NullPointerException();
});
}
}
运行结果:
Exception in thread "pool-1-thread-1" java.lang.NullPointerException
at com.example.dto.ThreadTest.lambda$main$0(ThreadTest.java:17)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
可以发现,默认打印的线程池名字是pool-1-thread-1,如果排查问题起来,并不友好。因此建议大家给自己线程池自定义个容易识别的名字。其实用CustomizableThreadFactory即可,正例如下:
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(20),new CustomizableThreadFactory("Tianluo-Thread-pool"));
executorOne.execute(()->{
throw new NullPointerException();
});
}
}
线程池参数设置不合理
线程池最容易出坑的地方,就是线程参数设置不合理。比如核心线程设置多少合理,最大线程池设置多少合理等等。当然,这块不是乱设置的,需要结合具体业务。
比如线程池如何调优,如何确认最佳线程数?
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
我们的服务器CPU核数为8核,一个任务线程cpu耗时为20ms,线程等待(网络IO、磁盘IO)耗时80ms,那最佳线程数目:( 80 + 20 )/20 * 8 = 40。也就是设置 40个线程数最佳。
线程池异常处理的坑
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(20),new CustomizableThreadFactory("Tianluo-Thread-pool"));
for (int i = 0; i < 5; i++) {
executorOne.submit(()->{
System.out.println("current thread name" + Thread.currentThread().getName());
Object object = null;
System.out.print("result## " + object.toString());
});
}
}
}
按道理,运行这块代码应该抛空指针异常才是的,对吧。但是,运行结果却是这样的;
current thread nameTianluo-Thread-pool1
current thread nameTianluo-Thread-pool2
current thread nameTianluo-Thread-pool3
current thread nameTianluo-Thread-pool4
current thread nameTianluo-Thread-pool5
这是因为使用submit提交任务,不会把异常直接这样抛出来。最好就是try...catch捕获
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(20),new CustomizableThreadFactory("Tianluo-Thread-pool"));
for (int i = 0; i < 5; i++) {
executorOne.submit(()->{
System.out.println("current thread name" + Thread.currentThread().getName());
try {
Object object = null;
System.out.print("result## " + object.toString());
}catch (Exception e){
System.out.println("异常了"+e);
}
});
}
}
}
也可以使用Future.get来获取异常。
线程池使用完毕后,忘记关闭
如果线程池使用完,忘记关闭的话,有可能会导致内存泄露问题。所以,大家使用完线程池后,记得关闭一下。同时,线程池最好也设计成单例模式,给它一个好的命名,以方便排查问题。
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(20), new CustomizableThreadFactory("Tianluo-Thread-pool"));
executorOne.execute(() -> {
});
//关闭线程池
executorOne.shutdown();
}
}
ThreadLocal与线程池搭配,线程复用,导致信息错乱
使用ThreadLocal缓存信息,如果配合线程池一起,有可能出现信息错乱的情况。先看下一下例子:
private static final ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(() -> null);
@GetMapping("wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
//设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
}
按理说,每次获取的before应该都是null,但是呢,程序运行在 Tomcat 中,执行程序的线程是Tomcat的工作线程,而Tomcat的工作线程是基于线程池的。
线程池会重用固定的几个线程,一旦线程重用,那么很可能首次从 ThreadLocal 获取的值是之前其他用户的请求遗留的值。这时,ThreadLocal 中的用户信息就是其他用户的信息。
把tomcat的工作线程设置为1
server.tomcat.max-threads=1
用户1,请求过来,会有以下结果,符合预期:
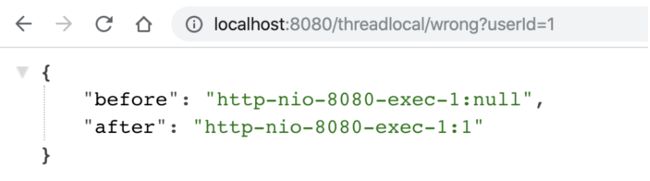
用户2请求过来,会有以下结果,「不符合预期」:
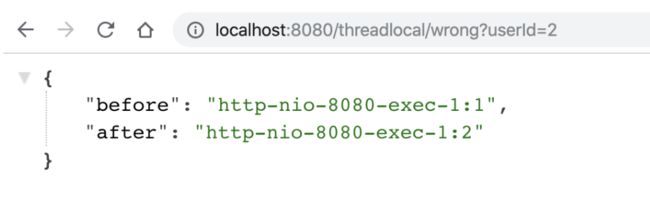
因此,使用类似 ThreadLocal 工具来存放一些数据时,需要特别注意在代码运行完后,显式地去清空设置的数据,正例如下:
@GetMapping("right")
public Map right(@RequestParam("userId") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}
13.机器问题 (GC、线程打满、太多IO资源没关闭等等)
有时候,我们的接口慢,就是机器处理问题。主要有fullGC、线程打满、太多IO资源没关闭等等。
GC
比如说要导出60W+的excel的时候,卡死了,接着收到了监控告警。排查得出,代码是Apache POI生成的excel,导出excel数据量很大时,当时JVM内存吃紧会直接Full GC了。
无论是Young GC还是Full GC,在进行垃圾回收时都会暂停所有的业务线程。因此,需要关注垃圾回收的频率,以确保对业务的影响尽可能小。
一般情况下,通过调整堆大小和新生代大小可以解决大部分垃圾回收问题。其中,新生代是用于存放新创建的对象的区域。对于Young GC的频率增加的情况,一般是系统的请求量大量增长导致。但如果young gc增长非常多,就需要考虑是否需要增加新生代的大小。
因为如果新生代过小,很容易被打满。这导致本可以被Young GC掉的对象被晋升(Promotion)到老年代,过早地进入老年代。这样一来,不仅Young GC频繁触发,Full GC也会频繁触发。
线程
如果线程打满了,也会导致接口都在等待了。所以。如果是高并发场景,我们需要接入限流,把多余的请求拒绝掉。
资源
如果IO资源没关闭,也会导致耗时增加。这个大家可以看下,平时你的电脑一直打开很多很多文件,是不是会觉得很卡。
提升服务器硬件
如果cpu负载较高 可以考虑提高每个实例cpu数量,提高实例个数。同时关注网络IO负载,如果机器流量较大,网卡带宽可能成为瓶颈。
高峰期和低峰期如果机器负载相差较大,可以考虑设置弹性伸缩策略,高峰期之前自动扩容,低峰期自动缩容,最大程度提高资源利用率。
关于JVM调优部分的内容,将会在后续专门的出一些文章,因为目前笔者对这方面理解还不够,所以暂不多做赘述!!!
14.调用链路优化
在评估接口性能时,我们需要首先找出最耗时的部分,并优化它,这样优化效果才会立竿见影。
跨地域调用
假如说北京到上海的跨地域调用需要耗费大约30毫秒的时间,这个耗时是相当高的,所以我们应该特别关注调用链路上是否存在跨地域调用的情况。这些跨地域调用包括Rpc调用、Http调用、数据库调用、缓存调用以及MQ调用等等。在整理调用链路的时候,我们还应该标注出跨地域调用的次数,例如跨地域调用数据库可能会出现多次,在链路上我们需要明确标记。我们可以考虑通过降低调用次数来提高性能,因此在设计优化方案时,我们应该特别关注如何减少跨地域调用的次数。
举个例子,在某种情况下,假设上游服务在上海,而我们的服务在北京和上海都有部署,但是数据库和缓存的主节点都在北京,这时候就无法避免跨地域调用。那么我们该如何进行优化呢?考虑到我们的服务会更频繁地访问数据库和缓存,如果让我们上海节点的服务去访问北京的数据库和缓存,那么跨地域调用的次数就会非常多。因此,我们应该让上游服务去访问我们在北京的节点,这样只会有1次跨地域调用,而我们的服务在访问数据库和缓存时就无需进行跨地域调用。
单元化架构:不同的用户路由到不同的集群单元
如果主数据库位于北京,那么南方的用户每次写请求就只能通过跨地域访问来完成吗?实际上并非如此。数据库的主库不仅可以存在于一个地域,而是可以在多个地域上部署主数据库。将每个用户归属于最近的地域,该用户的请求都会被路由到所在地域的数据库。这样的部署不仅提升了系统性能,还提高了系统的容灾等级,即使单个机房发生故障也不会影响全网的用户。
这个思想类似于CDN(内容分发网络),它能够将用户请求路由到最近的节点。事实上,由于用户的存储数据已经在该地域的数据库中,用户的请求极少需要切换到其他地域。
为了实现这一点,我们需要一个用户路由服务来提供用户所在地域的查询,并且能够提供高并发的访问。
除了数据库之外,其他的存储中间件(如MQ、Redis等)以及Rpc框架都需要具备单元化架构能力。
微服务拆分过细会导致Rpc调用较多
微服务拆分过细会导致更多的RPC调用,一次简单的请求可能就涉及四五个服务,当访问量非常高时,多出来的三五次Rpc调用会导致接口耗时增加很多。
每个服务都需要处理网络IO,序列化反序列化,服务的GC 也会导致耗时增加,这样算下来一个大服务的性能往往优于5个微服务。
当然服务过于臃肿会降低开发维护效率,也不利于技术升级。微服务过多也有问题,例如增加整体链路耗时、基础架构升级工作量变大、单个需求代码变更的服务更多等弊端。需要你权衡开发效率、线上性能、领域划分等多方面因素。
提前过滤,减少无效调用
在某些活动匹配的业务场景里,相当多的请求实际上是不满足条件的,如果能尽早的过滤掉这些请求,就能避免很多无效查询。例如用户匹配某个活动时,会有非常多的过滤条件,如果该活动的特点是仅少量用户可参加,那么可首先使用人群先过滤掉大部分不符合条件的用户。
拆分接口
前面提到如果Http接口功能过于庞大,核心数据和非核心数据杂糅在一起,耗时高和耗时低的数据耦合在一起。为了优化请求的耗时,可以通过拆分接口,将核心数据和非核心数据分别处理,从而提高接口的性能。
而在Rpc接口方面,也可以使用类似的思路进行优化。当上游需要调用多个Rpc接口时,可以并行地调用这些接口。优先返回核心数据,如果处理非核心数据或者耗时高的数据超时,则直接降级,只返回核心数据。这种方式可以提高接口的响应速度和效率,减少不必要的等待时间。