浅谈下递归
----最近学习到了递归相关的知识,浅谈一下自己对递归的认识
1.递归的定义是什么
递归的本质是再调用函数的时候使用堆栈
我们在学习c语言时就已经接触了递归,只不过那时没有对递归进行深入的学习。在数学和计算机科学里面,递归通常被我们认识为“在函数的定义里面使用函数本身的方法”。通俗一点,递归就是函数自我复制的过程。就像衔尾蛇进入循环一样。

例如,当两面镜子以平行的方式面对面摆放时,镜子里面嵌套的图像就是通过无限递归的方式所呈现的。而在计算机编程语言里面,我们可以通过限制条件使得递归结束。
2.如何去理解递归
对于一个普通的调用函数,我们都是先对其进行定义,之后在函数的外面(也许是main函数,也可能是其他函数等等)对其进行调用
void Print(int a){
printf("%d/n",&a);
}
而下面是一个打印从0到“a”所有值的递归函数。
不知道大家在学习C语言的时候是否出现过和我一样的疑惑,对于下面这个递归函数
void Print(int a){
if(a>=0) {
Print(a--);
printf("%d/n",&a);
}
return;
}
在调用函数,我们在函数外面进行调用。而在使用递归函数的时候,为什么函数主体里面可以写调用函数本身?这个递归函数又是怎么执行整个过程的?
除了这个问题,我在学习结构体的时候,也产生过一个类似的疑问
我们可以在结构体外面定义一个结构体指针。
struct Node{
int a;
int b;
};
struct Node *List;
然而在下面的结构体里面,当我们写到 struct Node *List;这条语句的时候,这条语句到底算不算结构体的成员呢?如果算作一个成员,那么在写这条语句的时候,结构体应当算作没有完成全部定义,为什么可以在结构体里面包含一个自己类型的结构体指针?其实这个问题根递归有着异曲同工之妙。
struct Node{
int a;
int b;
struct Node *List;
};
这种递归的写法可以算作编程语言的一种格式,其本质是在调用函数时使用堆栈
上面的例子很简单,可以轻易的看出函数的目的是什么。但是在一些比较复杂的函数里面,递归的方法往往不是那么容易理解。为了更好地理解递归函数执行的过程和执行的结果,我个人的方法是不把函数里面的递归语句当作函数语句,搞清楚其他语句的作用,再通过分析递归语句的位置对函数进行分析(下面有一些例子)。
3.一些栗子
先从上面的Print函数说起
void Print(int a){
if(a>0) {
Print(a--);
printf("%d/n",&a);
}
return;
}
我个人喜欢把递归的方法通俗地成为“打开”,比如上面这个函数,称之为对“a”进行打开。在这个递归函数里面,由于递归语句写在了printf语句的前面,函数会先进行分配空间,再进行输出。
当我们对a输入数值的时候,例如a=3。系统先对第一个a=3时候的函数分配一定的空间,由于3大于0,故执行if里面的语句,对a–,也就是2进行调用。而printf会在递归调用结束之后运行。下面使用Print代表一个递归函数,用括号代表函数里面的语句,以逗号的形式将两个语句隔开,其运行过程会是这样:
Print(3)–> Print(Print(2),printf(3)) 函数会先执行2的递归也就是Print(2),再执行printf(3) 打印出3。而Print(2)又会变成Print(Print(1),printf(2)),Print(1)变成Print(Print(0),printf(1))。0不再满足if条件,所以可以直接把这些写在一起,就变成了:Print(Print(Print(Print(0),printf(1)),printf(2)),printf(3))(请看清楚“()”的位置) 。0不再大于0,故Print(0)跳过if语句,不执行递归,直接return。之后进入到同级别的语句printf(1),把1打印出来。之后Print(2)左侧执行完毕,执行对2的打印,并在之后执行对3的打印。至此,递归执行完毕。
不难发现,递归函数是非常占用空间的,因为每递归一次,都会对新递归出的函数进行分配空间,唯有直到递归结束,才会开始对分配的空间进行一个一个的回收。如果递归的数据较大,就会导致计算机空间不够,出现“溢出”,程序直接崩溃。
顺带一提,如果我们将递归语句跟printf语句位置交换,把代码写为
void Print(int a){
if(a>0) {
printf("%d/n",&a);
Print(a--);
}
return;
}
打印顺序会直接相反,变成从大到小的降序排列打印。
还有一个十分重要的示例就是二叉树
在二叉树里面,我们在建立节点以及遍历节点的时候,都使用了递归相关的语法。
首先下面是一个链式存储二叉树结点的表示
typedef struct TreeNode *BinTree;
struct TreeNode{
int Data;
BinTree Left;
BinTree Right;
}
通过这种方法定义的二叉树由指针相连,具体结构如下:

二叉树的遍历方法有先序遍历,中序遍历,后序遍历等。而这三种遍历方法都采用了递归的方法。
下面是先序遍历的代码:
void PreOrder(BinTree BT){
if(BT){
printf("%d",BT->Data)
PreOrder(BT->Left)
PreOrder(BT->Right)
}
}
在这个遍历方法里面,我们把指向头结点的指针地址作为参数传递给遍历函数,其遍历顺序如下
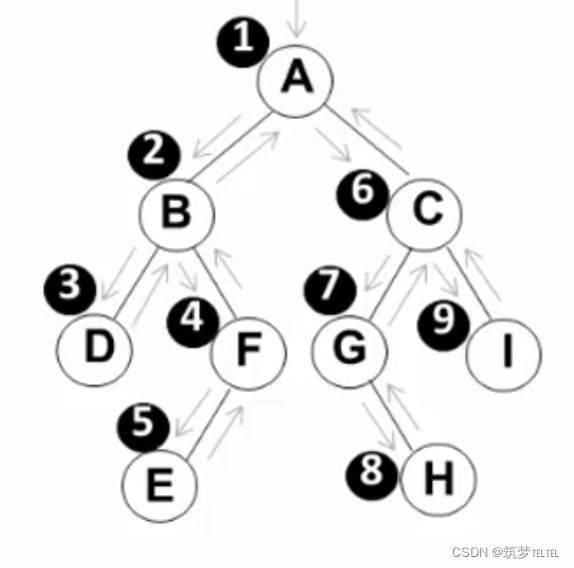
然后是相关解析
在先序遍历的函数里面,我们先对结点里面的数据进行了打印,之后分别进行了对左指针和右指针的递归
我把遍历一次通俗的称为“对该结点进行了打开”。当我们把根节点的指针传给遍历函数时,函数先打开该指针,通过if语句判断其指向的数据是否存在。该指针指向根节点,于是先执行打印语句,把A节点的Data进行打印。之后通过PreOrder(BT->Left)对该节点里面的Left指针进行打开。如果打开失败(即左指针指空),函数会打开右指针。由于该指针指向B节点,所以在第一次遍历的过程中,必须先把Left指针打开后的操作完成后,才能进一步打开右指针。于是我们在第一次遍历的过程里面进行了第二次遍历。打开B结点之后,先对B里面的数据进行打印,所以B的遍历顺序为2。向上面一样,之后再次通过PreOrder(B->Left) (这只是对访问B节点左指针的一种表示,不是真实的代码) 语句进入第三次遍历,所以D的打印顺序为3。打印完D之后程序试图打开D的左指针,但是指空。于是执行下一条语句PreOrder(D.->Right),打开D的右指针,进入第四次遍历。同理打印出F,之后打开F的左指针。于是程序开始访问E。再打印完E之后,其左右指针都指空,所以对E的遍历结束,程序返回上一级,打开F的右指针。
这里的返回上一级并不是程序真的自己跳转回到了上级,而是对上一个结点的左指针里面的内容访问完毕,开始按照代码顺序访问其右指针
由于F的右指针也指空,所以对F的遍历也结束,程序再次返回上一级。至此,B结点的右指针也已经遍历完成。于是最开始对A结点左指针的访问PreOrder(BT->Left)结束,开始对右指针进行打开遍历。
这就是该二叉树左边部分先序遍历的过程,右边同理。
中序遍历和后序遍历的原理与先序遍历一样,仅仅需要把代码位置进行移动。
这是中序遍历:
void PreOrder(BinTree BT){
if(BT){
PreOrder(BT->Left);
printf("%d",BT->Data);
PreOrder(BT->Right);
}
}
这是后序遍历:
void PreOrder(BinTree BT){
if(BT){
PreOrder(BT->Left);
PreOrder(BT->Right);
printf("%d",BT->Data);
}
}
三种遍历方式都是采用的递归的方法。无论是哪种,其在二叉树上走过的路径都是一样的

只不过我们通过改变代码顺序,就改变了输出的顺序。
4.小结
总的来说,递归是一种十分方便的方法。其代码具有较高的可辨识度。我们只需要对代码做一点变化,就可以得到不同的运行顺序。其缺点也十分明显。递归会连续的进行分配空间,如果递归次数过多,容易造成堆溢出导致程序崩溃。