吴恩达机器学习--中文笔记--第五周
吴恩达机器学习
- 第五个星期
-
- 1.代价函数与反向传播
-
- 1.1代价函数
- 1.2反向传播算法
- 1.3反向传播算法的直觉理解
- 2.实战中的反向传播
-
- 2.参数的展开和恢复
- 2.2梯度检查
- 2.3随机初始化
- 2.4步骤小结
- 参考文献
本文是在学习吴恩达老师机器学习课程的基础上结合老师的ppt文献然后加上自身理解编写出来的,有些地方可能有遗漏或错误,欢迎大家批评指正。希望我们一起学习,一起进步!
第五个星期
1.代价函数与反向传播
1.1代价函数
首先,我们需要定义一些后面用到的变量:
- L = 神经网络的层数
- s l = s_l= sl=第 l l l层的单元数(不包括偏置单元)
- K = 输出单元数/类别数
神经网络听起来高大上,其实就是逻辑回归的复杂版。值得注意的一点是,我们用 h Θ ( x ) k h_\Theta(x)_k hΘ(x)k作为假设函数表示第k类输出的节点。回忆一下,我们的逻辑回归的代价函数是
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=-\frac{1}{m}\sum\limits_{i=1}^{m}[y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum\limits_{j=1}^{n}\theta_j^2 J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
在神经网络中,我们的代价函数变为了
J ( Θ ) = − 1 m ∑ i = 1 m ∑ k = 1 K [ y k ( i ) l o g ( ( h Θ ( x ( i ) ) ) k ) + ( 1 − y k ( i ) ) l o g ( 1 − ( h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j , i ( l ) ) 2 J(\Theta)=-\frac{1}{m}\sum\limits_{i=1}^{m}\sum\limits_{k=1}^{K}[y_k^{(i)}log((h_\Theta(x^{(i)}))_k)+(1-y_k^{(i)})log(1-(h_\Theta(x^{(i)}))_k)]+\frac{\lambda}{2m}\sum\limits_{l=1}^{L-1}\sum\limits_{i=1}^{s_l}\sum\limits_{j=1}^{s_{l+1}}(\Theta_{j,i}^{(l)})^2 J(Θ)=−m1i=1∑mk=1∑K[yk(i)log((hΘ(x(i)))k)+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θj,i(l))2
1.2反向传播算法
和前面一样,想要使得模型最优,我们必须要 min J ( Θ ) \min J(\Theta) minJ(Θ),为了实现这一目标,最关键的就是要求解 ∂ ∂ Θ i , j ( l ) J ( Θ ) \frac{∂}{∂\Theta_{i,j}^{(l)}}J(\Theta) ∂Θi,j(l)∂J(Θ)。何以求解?我们遵循下面的步骤就可以了。
反向传播算法步骤:
假设我们有数据集 { ( x ( 1 ) , y ( 1 ) ) . . . ( x ( m ) , y ( m ) ) } \{(x^{(1)},y^{(1)})...(x^{(m)},y^{(m)})\} {(x(1),y(1))...(x(m),y(m))}
- 设置 Δ i . j ( l ) : = 0 \Delta^{(l)}_{i.j}:=0 Δi.j(l):=0,for all(l,i,j).你会得到一个全0的矩阵
对于1至m样本
- 我们让 a ( 1 ) : = x ( t ) a^{(1)}:=x^{(t)} a(1):=x(t)
- 通过前向传播计算 a ( l ) , l = 2 , 3 , . . . , L a^{(l)},l=2,3,...,L a(l),l=2,3,...,L(见下图)

- 第三步,计算 δ ( L ) \delta^{(L)} δ(L)
δ ( L ) = a ( L ) − y ( t ) \delta^{(L)}=a^{(L)}-y^{(t)} δ(L)=a(L)−y(t)
其中,L是神经网络所有层的层数, a ( L ) a^{(L)} a(L)是最后一层激活单元输出的向量, y ( t ) y^{(t)} y(t)是真实向量值 - 计算 δ ( L − 1 ) , δ ( L − 2 ) , δ ( L − 3 ) , . . . , δ ( 2 ) \delta^{(L-1)},\delta^{(L-2)},\delta^{(L-3)},...,\delta^{(2)} δ(L−1),δ(L−2),δ(L−3),...,δ(2)
δ ( l ) = ( ( Θ ( l ) ) T δ ( l + 1 ) ) . ∗ a ( l ) . ∗ ( 1 − a ( l ) ) \delta^{(l)}=((\Theta^{(l)})^T\delta^{(l+1)}).*a^{(l)}.*(1-a^{(l)}) δ(l)=((Θ(l))Tδ(l+1)).∗a(l).∗(1−a(l))
其实 g ′ ( z ( l ) ) = a ( l ) . ∗ ( 1 − a ( l ) ) g'(z^{(l)})=a^{(l)}.*(1-a^{(l)}) g′(z(l))=a(l).∗(1−a(l)),所以,也可以这样写:
δ ( l ) = ( ( Θ ( l ) ) T δ ( l + 1 ) ) . ∗ g ′ ( z ( l ) ) \delta^{(l)}=((\Theta^{(l)})^T\delta^{(l+1)}).*g'(z^{(l)}) δ(l)=((Θ(l))Tδ(l+1)).∗g′(z(l)) - Δ i , j ( l ) = Δ i , j ( l ) + a j ( l ) δ i ( l + 1 ) \Delta_{i,j}^{(l)}=\Delta_{i,j}^{(l)}+a^{(l)}_{j}\delta_{i}^{(l+1)} Δi,j(l)=Δi,j(l)+aj(l)δi(l+1),或者用向量表示 Δ ( l ) = Δ ( l ) + δ ( l + 1 ) ( a ( l ) ) T \Delta^{(l)}=\Delta^{(l)}+\delta^{(l+1)}(a^{(l)})^T Δ(l)=Δ(l)+δ(l+1)(a(l))T
- 加上正则化,我们得到:
D i , j ( l ) = 1 m ( Δ i , j ( l ) + λ Θ i , j ( l ) ) , j ≠ 0 D^{(l)}_{i,j}=\frac{1}{m}(\Delta_{i,j}^{(l)}+\lambda\Theta_{i,j}^{(l)}),j≠0 Di,j(l)=m1(Δi,j(l)+λΘi,j(l)),j=0
D i , j ( l ) = 1 m Δ i , j ( l ) , j = 0 D^{(l)}_{i,j}=\frac{1}{m}\Delta_{i,j}^{(l)},j=0 Di,j(l)=m1Δi,j(l),j=0 - 事实上,经过了这么多步,你可能会一头雾水,说了一大堆,我如何更新 Θ \Theta Θ?不慌,这里悄悄告诉你, ∂ ∂ Θ i , j ( l ) J ( Θ ) = D i , j ( l ) \frac{∂}{∂\Theta_{i,j}^{(l)}}J(\Theta)=D^{(l)}_{i,j} ∂Θi,j(l)∂J(Θ)=Di,j(l)。这样你就可以尽情更新了。
1.3反向传播算法的直觉理解
不得不说,反向传播算法还是比较复杂和晦涩难懂的,吴恩达教授在视频中也提到,其实他也没能完全吃透神经网络这个黑盒子的机制道理。但不得不承认神经网络所训练出来的模型确实好用,准确度很高。
如何理解 δ \delta δ呢?我们还是先回忆一下神经网络的代价函数。
J ( Θ ) = − 1 m ∑ i = 1 m ∑ k = 1 K [ y k ( i ) l o g ( ( h Θ ( x ( i ) ) ) k ) + ( 1 − y k ( i ) ) l o g ( 1 − ( h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j , i ( l ) ) 2 J(\Theta)=-\frac{1}{m}\sum\limits_{i=1}^{m}\sum\limits_{k=1}^{K}[y_k^{(i)}log((h_\Theta(x^{(i)}))_k)+(1-y_k^{(i)})log(1-(h_\Theta(x^{(i)}))_k)]+\frac{\lambda}{2m}\sum\limits_{l=1}^{L-1}\sum\limits_{i=1}^{s_l}\sum\limits_{j=1}^{s_{l+1}}(\Theta_{j,i}^{(l)})^2 J(Θ)=−m1i=1∑mk=1∑K[yk(i)log((hΘ(x(i)))k)+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θj,i(l))2
如果我们假设我们是二分类(K=1),而且没有正则化。那么代价函数为:
c o s t ( t ) = y ( t ) l o g ( h Θ ( x ( t ) ) ) + ( 1 − y ( t ) ) l o g ( 1 − h Θ ( x ( t ) ) ) cost(t)=y^{(t)}log(h_{\Theta}(x^{(t)}))+(1-y^{(t)})log(1-h_\Theta(x^{(t)})) cost(t)=y(t)log(hΘ(x(t)))+(1−y(t))log(1−hΘ(x(t)))
直观来看, δ j ( l ) \delta^{(l)}_j δj(l)就是 a j ( l ) a^{(l)}_{j} aj(l)的相对于准确值误差,更正规地来讲, δ j ( l ) \delta^{(l)}_j δj(l)是代价函数的导数值。
即: δ j ( l ) = ∂ ∂ z j ( l ) c o s t ( t ) \delta^{(l)}_j=\frac{∂}{∂z_{j}^{(l)}}cost(t) δj(l)=∂zj(l)∂cost(t)
接下来用一个例子来演示一下。
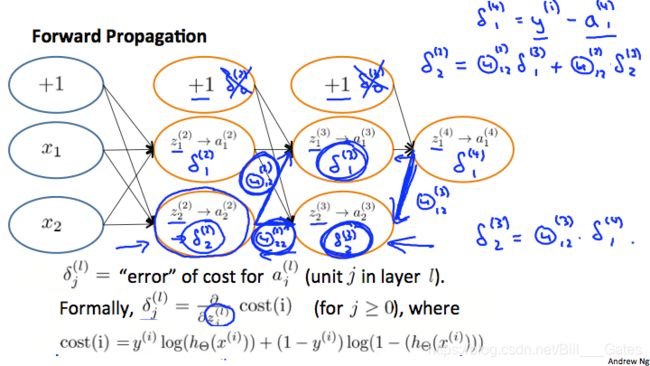
看上面这张图,假设我们要计算 δ 2 ( 2 ) \delta^{(2)}_2 δ2(2),我们需要找到其所在节点右侧连接的下一层的所有节点及其连接边( δ 1 ( 3 ) , δ 2 ( 3 ) , Θ 12 ( 2 ) , Θ 22 ( 2 ) \delta^{(3)}_1,\delta^{(3)}_2,\Theta^{(2)}_{12},\Theta^{(2)}_{22} δ1(3),δ2(3),Θ12(2),Θ22(2))。然后计算 δ 2 ( 2 ) = Θ 12 ( 2 ) δ 1 ( 3 ) + Θ 22 ( 2 ) δ 2 ( 3 ) \delta^{(2)}_2=\Theta^{(2)}_{12}\delta^{(3)}_1+\Theta^{(2)}_{22}\delta^{(3)}_2 δ2(2)=Θ12(2)δ1(3)+Θ22(2)δ2(3)。
按照这个规律,我们就是从右至左,利用下一层的信息和连接边的权重,不断的更新 δ j ( l ) \delta^{(l)}_j δj(l),这就是反向传播。
2.实战中的反向传播
2.参数的展开和恢复
为了更好的用代码实现反向传播过程,有时候,我们要把一些参数进行展开,向量化。比如:
Θ ( 1 ) , Θ ( 2 ) , Θ ( 3 ) , . . . \Theta^{(1)},\Theta^{(2)},\Theta^{(3)},... Θ(1),Θ(2),Θ(3),...
D ( 1 ) , D ( 2 ) , D ( 3 ) , . . . D^{(1)},D^{(2)},D^{(3)},... D(1),D(2),D(3),...
它们用下面的代码展开:
thetaVector = [ Theta1(:); Theta2(:); Theta3(:); ]
deltaVector = [ D1(:); D2(:); D3(:) ]
如果Theta1的维度是10*11,Theta2的维度是10*11,Theta3的维度是1*11,我们通过下面的代码可以转换回来。
Theta1 = reshape(thetaVector(1:110),10,11)
Theta2 = reshape(thetaVector(111:220),10,11)
Theta3 = reshape(thetaVector(221:231),1,11)

2.2梯度检查
为了保证导数计算出的梯度的正确性,我们使用传统数学方法粗略的计算某一点附近的( − ϵ , ϵ -\epsilon,\epsilon −ϵ,ϵ)大致梯度,从而实施梯度检查。
我们知道,一个函数的导数可以这样写:
∂ ∂ Θ J ( Θ ) ≈ J ( Θ + ϵ ) − J ( Θ − ϵ ) 2 ϵ \frac{∂}{∂\Theta}J(\Theta)≈\frac{J(\Theta+\epsilon)-J(\Theta-\epsilon)}{2\epsilon} ∂Θ∂J(Θ)≈2ϵJ(Θ+ϵ)−J(Θ−ϵ)
当存在多变量时, ∂ ∂ Θ j J ( Θ ) ≈ J ( Θ 1 , . . . , Θ j + ϵ , . . . , Θ n ) − J ( Θ 1 , . . . , Θ j − ϵ , . . . , Θ n ) 2 ϵ \frac{∂}{∂\Theta_j}J(\Theta)≈\frac{J(\Theta_1,...,\Theta_j+\epsilon,...,\Theta_n)-J(\Theta_1,...,\Theta_j-\epsilon,...,\Theta_n)}{2\epsilon} ∂Θj∂J(Θ)≈2ϵJ(Θ1,...,Θj+ϵ,...,Θn)−J(Θ1,...,Θj−ϵ,...,Θn)
一般情况下 ϵ = 1 0 − 4 \epsilon=10^{-4} ϵ=10−4,效果比较好,太小会导致数值问题。
对应的matlab代码如下:
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus))/(2*epsilon)
end;
值得注意的一点是,一旦你确定了偏微分的正确性,便可以禁用梯度检查代码。因为如果不这样做,代码运行速度会大大降低。
2.3随机初始化
在神经网络中,如果将 Θ \Theta Θ全部初始为0,那么神经网络将无法被良好的训练,因为这样的情况下,经过反向传播,同一层所有节点都会被更新到相同的值和状态,也就是说,同一层节点再多也没用。
那么如何进行随机初始化呢?,请看下图:

总之,就是要将 Θ \Theta Θ随机限定在 [ − ϵ , ϵ ] [-\epsilon,\epsilon] [−ϵ,ϵ]内。
对应MATLAB代码如下:
If the dimensions of Theta1 is 10x11, Theta2 is 10x11 and Theta3 is 1x11.
Theta1 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
2.4步骤小结
首先选择一个合适的神经网络结构,包括:
- 输入特征数量
- 隐藏层数量及其每层节点数(通常情况下,隐藏层越多,分类效果越好)
- 输出层数量,也就是分类的个数
- 如果有多个隐藏层,建议每个隐藏层保持同样数量的节点
接着训练神经网络,步骤为:
- 权重参数随机初始化
- 实现前向传播计算 h Θ ( x ) h_\Theta(x) hΘ(x)
- 计算代价函数
- 实现反向传播计算偏微分
- 使用梯度检查方法确保反向传播正常运行,发现没问题后记得禁用梯度检查
- 使用梯度下降或高级优化方法来最小化代价函数 J ( Θ ) J(\Theta) J(Θ),并更新 Θ \Theta Θ值
下面这张图演示了当反向传播计算时,代价函数的变化情况:
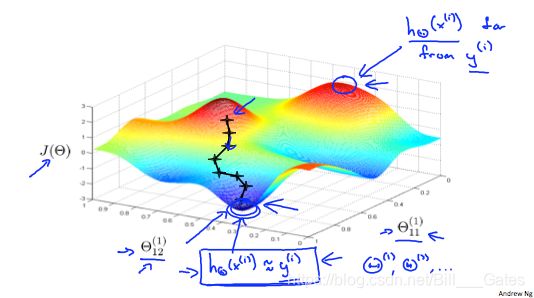
可以看出,有时候,我们可能不会进入全局最优,而会陷入局部最优。
参考文献
链接: Coursera Machine Learning.