方差分析(ANOVA)的基本原理及R实现(单因素)
方差分析(analysis of variance,ANOVA)几乎是在统计学分析中最常用的方法,通过分析各变量的主效应(main effect)和交互效应(interaction effect),从而发现因变量(dependent variable)的变异源。另外,通过配合使用多重比较的检验方法,其也常用于比较不同处理导致的因变量的差异。
一、基本原理
假设我们实验获得了这样的一组数据:通过对研究对象(各实验单位)进行不同处理(控制各变量的水平),导致实验对象的某一指标(因变量)在实验单位间出现差异。同时,为了更好的探讨差异的来源,同时提高结果的可靠性,同样的处理我们做了多次重复(一般要大于3)。
1、数学模型
这样就可以将数据的变异划分为组内变异和组间变异,组内变异即各实验重复间的差异,由于随机误差导致。组间变异即各处理组之间的差异,由随机误差和处理效应导致。方差分析的基本思路就是将变异分解为组间变异和组内变异差异的大小(服从 F F F分布),并使用 F F F检验来比较二者差异的显著性。
设实验一共有 k \red{k} k个处理,每个处理有 n \red{n} n个重复,因此第 i \red{i} i个处理的第 j \red{j} j次重复的观测表示为 x i j \red{x_{ij}} xij,且有 μ \mu μ为总体平均数( μ = ∑ μ i k \mu=\frac{\sum\mu_{i}}{k} μ=k∑μi, k k k为处理数, μ i \mu_{i} μi为各处理组的均值), α i \alpha_{i} αi为处理效应(样本为总体时, ∑ α i = 0 \sum\alpha_{i}=0 ∑αi=0), ε i j \varepsilon_{ij} εij为随机误差(相互独立且 ε \varepsilon ε~ N ( o , σ 2 ) N(o,\sigma^{2}) N(o,σ2)),则观测与变异间的关系可表示为:
x i j = μ + α i + ε i j x_{ij}=\mu+\alpha_{i}+\varepsilon_{ij} xij=μ+αi+εij
使用样本统计数表示就是:
x i j = x ‾ + α i + e i j , e i j :样本随机误差 x_{ij}=\overline{x}+\alpha_{i}+e_{ij}~,~e_{ij:\text{样本随机误差}} xij=x+αi+eij , eij:样本随机误差
2、方差分解
在方差分析中,通常使用方差 s 2 s^{2} s2来表征数据的变异,而方差通过平方和和自由度来计算:
S 2 = ∑ ( x i − x ‾ ) d f S^{2}=\frac{\sum(x_{i}-\overline x)}{df} S2=df∑(xi−x)
所以,将总变异分解为组间变异和组内变异实质上就是分解平方和和自由度。
(1)平方和的分解
沿用上述的例子,则总变异的平方和 S S T \red{SS_{T}} SST为:
S S T = ∑ i = 1 k ∑ j = 1 n ( x i j − x ‾ ) 2 SS_{T}= \sum_{i=1}^{k} \sum_{j=1}^{n} (x_{ij}-\overline x)^2 SST=i=1∑kj=1∑n(xij−x)2
化简得:
S S T = ∑ i = 1 k ∑ j = 1 n ( x ‾ i − x ‾ ) 2 + ∑ i = 1 k ∑ j = 1 n ( x i j − x ‾ i ) 2 SS_{T}= \sum_{i=1}^{k} \sum_{j=1}^{n} (\overline x_{i}-\overline x)^2+ \sum_{i=1}^{k} \sum_{j=1}^{n} (x_{ij}-\overline x_{i})^2 SST=i=1∑kj=1∑n(xi−x)2+i=1∑kj=1∑n(xij−xi)2
可以看出组间平方和 S S t \red{SS_t} SSt(处理平方和)为:
S S t = ∑ i = 1 k ∑ j = 1 n ( x ‾ i − x ‾ ) 2 = n ∑ i = 1 k ( x ‾ i − x ‾ ) 2 \begin{aligned} SS_t &=\sum_{i=1}^{k} \sum_{j=1}^{n} (\overline x_{i}-\overline x)^2\\ &=n\sum_{i=1}^{k} (\overline x_{i}-\overline x)^2 \end{aligned} SSt=i=1∑kj=1∑n(xi−x)2=ni=1∑k(xi−x)2
而组内平方和 S S e \red{SS_e} SSe(误差平方和)为:
S S e = ∑ i = 1 k ∑ j = 1 n ( x i j − x ‾ i ) 2 SS_e= \sum_{i=1}^{k} \sum_{j=1}^{n} (x_{ij}-\overline x_{i})^2 SSe=i=1∑kj=1∑n(xij−xi)2
也有 快速计算 \red{快速计算} 快速计算的公式:
{ C = T 2 / ( k n ) S S T = ∑ ∑ x i j 2 − C S S t = ∑ ( T i 2 / n ) − C S S e = S S T − S S t \begin{cases} C&=T^{2}/(kn)\\ SS_T&=\sum\sum x^{2}_{ij}-C\\ SS_t&=\sum(T^2_{i}/n)-C\\ SS_e&=SS_T-SS_t \end{cases} ⎩ ⎨ ⎧CSSTSStSSe=T2/(kn)=∑∑xij2−C=∑(Ti2/n)−C=SST−SSt
(2)自由度的分解
在计算方差的时候,各方差的自由度受对应的平方和的约束,所以可以分别得出总自由度、处理自由度和误差自由度:
总自由度 d f T \red{df_{T}} dfT:
d f T = k n − 1 df_T=kn-1 dfT=kn−1
处理自由度 d f t \red{df_t} dft:
d f t = k − 1 df_{t}=k-1 dft=k−1
误差自由度 d f e \red{df_e} dfe:
d f e = k ( n − 1 ) df_e=k(n-1) dfe=k(n−1)
(3)方差和 F F F统计量
所以通过上述推导可得分解后得自由度和平方和,并以此计算方差(方差分析中表示为 M S \red{MS} MS,即均方):
{ 处理均方: M S t = S S t / d f t 误差均方: M S e = S S e / d f e \begin{cases} 处理均方:\red{MS_t}=SS_t/df_t\\ 误差均方:\red{MS_e}=SS_e/df_e \end{cases} {处理均方:MSt=SSt/dft误差均方:MSe=SSe/dfe
因此, F F F统计量为:
F = M S t M S e \red{F}= \frac{MS_t}{MS_e} F=MSeMSt
通过 F F F统计量即可确定处理效应是否显著( F > F 0.05 F>F_{0.05} F>F0.05)。
3、多重比较
在确定处理均方(处理效应)是否显著后,即可通过多重比较检验各处理组别间差异的显著性。主要的检验方法可大致分为两类:最小显著差数法和最小显著极差法。常用的方法如下:
多重比较 { 最小显著差数法 { L S D test Sidak test Bonferroni test 特点:差数标准固定 最小显著极差法 { Tukey test S-N-K test Tukey’s-b test Duncan test 特点:差数标准随秩次变化 多重比较 \begin{cases} &\text{最小显著差数法} \begin{cases} &LSD~\text{test}\\ &\text{Sidak~test}\\ &\text{Bonferroni~test} \end{cases} 特点:差数标准固定\\ &\text{最小显著极差法} \begin{cases} &\text{Tukey~test}\\ &\text{S-N-K~test}\\ &\text{Tukey's-b~test}\\ &\text{Duncan~test} \end{cases} 特点:差数标准随秩次变化 \end{cases} 多重比较⎩ ⎨ ⎧最小显著差数法⎩ ⎨ ⎧LSD testSidak testBonferroni test特点:差数标准固定最小显著极差法⎩ ⎨ ⎧Tukey testS-N-K testTukey’s-b testDuncan test特点:差数标准随秩次变化
4、方差分析表
为了更好的解读方差分析结果,有必要按特定的规范书写方差分析,一般方差分析的结果可表示为:
变异源 S S d f M S F 处理效应 S S t = ∑ ( T i 2 / n ) − C d f t = k − 1 M S t = S S t / d f t F = M S t / M S e ∗ ∗ ∗ 随机误差 S S e = S S T − S S t d f e = k ( n − 1 ) M S e = S S e / d f e 总变异 S S T = ∑ ∑ x i j 2 − C d f T = k n − 1 \begin{array}{ccccc} 变异源 & SS & df & MS & F\\ \hline 处理效应 & SS_t=\sum(T^2_{i}/n)-C & df_{t}=k-1 & MS_t=SS_t/df_t & F=MS_t/MS_e^{***}\\ 随机误差 & SS_e=SS_T-SS_t & df_e=k(n-1) & MS_e=SS_e/df_e & ~\\ 总变异 & SS_T=\sum\sum x^{2}_{ij}-C & df_T=kn-1 & ~ & ~\\ \end{array} 变异源处理效应随机误差总变异SSSSt=∑(Ti2/n)−CSSe=SST−SStSST=∑∑xij2−Cdfdft=k−1dfe=k(n−1)dfT=kn−1MSMSt=SSt/dftMSe=SSe/dfe FF=MSt/MSe∗∗∗
F F F值得上标 ∗ ∗ ∗ \red{***} ∗∗∗表示处理效应显著性,有时也会额外加一列表示处理效应的显著性,例如R中agricolae包的结果:

二、R实现
1、方差分析
R中提供了很多用于方差分析得包,这里以stats包为例:
setwd("your workspace")
#加载包
library(agricolae)
#R version(4.0.5)
#读取数据
data <- read.csv("data.csv",header = T)
数据集data.csv是某一作物在不同激素浓度处理(Treat, k = 4 , n = 5 k=4,n=5 k=4,n=5)下对叶长(Length)生长量的影响。
单因素方差分析:
#描述性统计
#方差分析
fit <- aov(Length ~ Treat, data = data)
#结果
summary(fit)
输出结果如下:

可看出不同激素处理对叶长生长量的变化( F = 12.02 F=12.02 F=12.02)极显著( P = 0.000227 P=0.000227 P=0.000227)。
2、多重比较
使用 L S D test LSD~\text{test} LSD test(agricolae包)进行多重比较:
#显著性检验(LSD检验)
var<- LSD.test(fit, "Treat")
#结果
var
输出结果如下:
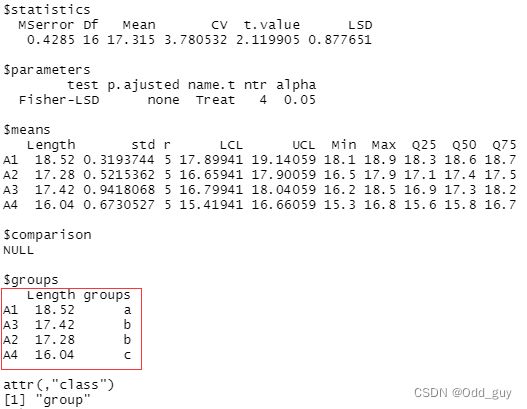
从结果中可看出四种处理下叶长生长量大小关系为: A 1 > A 3 > A 2 > A 4 A1>A3>A2>A4 A1>A3>A2>A4,其中 A 2 A2 A2和 A 3 A3 A3处理的差异并不显著。另外,结果中还列出了均值、标准差、分位数、 α \alpha α等关键信息。
3、可视化
单因素方差分析结果一般辅以箱型图来展示,可有效的提供处理效应显著性、差异显著性、数据分布等有效信息。
(1)ggplot法
ggplot系列包因为可以图层叠加,可以极大的节省后期修图的工作量,目前基本已成为R语言可视化的首选。
下列代码以ggplot2绘制箱型图,数据集仍为data.csv,最后使用ggsignif标记差异显著性。
绘制箱形图:
#加载ggplot2包
library(ggplot2)
#绘制箱型图
boxplot=
ggplot(data, aes(x=Treat, y=Length, fill=Treat))+#定义图形属性
geom_boxplot()+#以箱型图显示
#添加图例、标题等信息
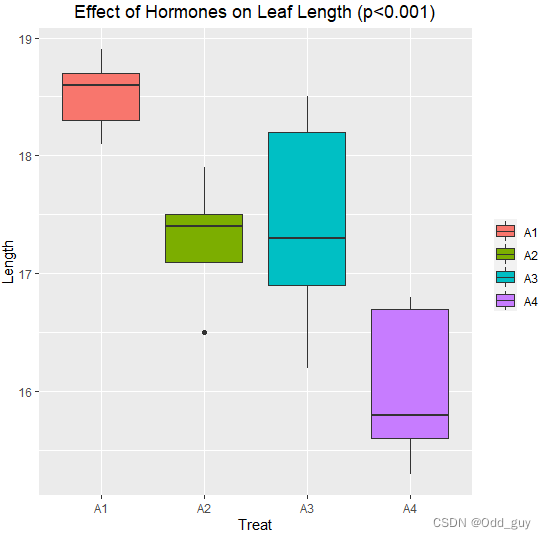
labs(title="Effect of Hormones on Leaf Length (p<0.001)", x="Treat", y="Length")+
theme(plot.title=element_text(hjust=0.5),
legend.title=element_blank())#定义主题
#查看可视化结果
boxplot
添加差异显著性标签:
#加载ggsignif
library(ggsignif)
#添加差异显著性标签
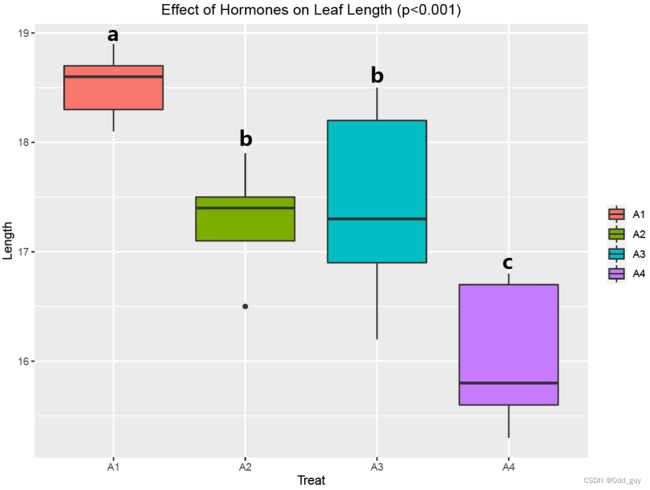
boxplot = boxplot +
#A1对A2
geom_signif(comparisons = list(c(1, 2)),#处理组对比对
y_position = 18.9, #标签位置对应y轴的值
tip_length = 0, #标签竖线长度
annotations = "P < 0.05")+ #标签文本
#A1对A3
geom_signif(comparisons = list(c(1, 3)),
y_position = 15.9,
tip_length = 0,
annotations = "P < 0.05")+
#A1对A4
geom_signif(comparisons = list(c(1, 4)),
y_position = 15,
tip_length = 0,
annotations = "P < 0.05")+
#A3对A4
geom_signif(comparisons = list(c(3, 4)),
y_position = 18.5,
tip_length = 0,
annotations = "P < 0.05")+
#A2对A4
geom_signif(comparisons = list(c(2, 4)),
y_position = 18.7,
tip_length = 0,
annotations = "P < 0.05")
#查看结果
boxplot

可以看出,在比较组别较多的时候ggsignif包的方法得到的结果会过于复杂,违反了直观性原则。因此,也可以直接使用AI根据多重比较结果进行标记。
(2)基础绘图法
基础绘图也提供了可视化方法,使用上述的方差分析结果fit进行多重比较(TukeyHSD test),并使用data数据集绘制均值图,涉及的包为gplots:
#加载包
library(gplots)
#绘图
par(mfcol=c(1,2))
par(las = 2)
plotmeans(data = data,
Length ~ Treat,
xlab = "Treatment",
ylab = "Length",
main = "Effect of Hormones on Leaf Length (p<0.001)")
#使用ukey HSD进行多重比较并可视化
Tukey = TukeyHSD(fit)
par(las = 2)
plot(Tukey)
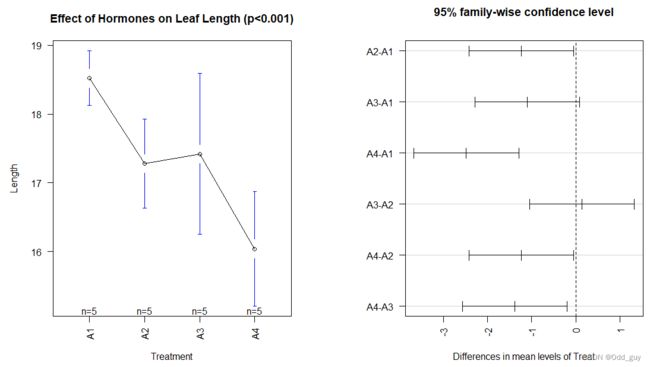
不难看出,使用不同方法进行多重比较,获得的结果并不相同,这是因为两类检验方法在确定显著性的标准上有一定的差异。因此,在实际操作中,需要根据自己的数据集特点,选择合适的检验方法。