第一次组会汇报(2023/11/18)
目录
一,浅谈学习规划
二, 两个比较典型的注意力机制
㈠SEnet
⒈结构图
⒉机制流程讲解
⒊源码(pytorch框架实现)及逐行解释
⒋测试结果
㈡CBAM
⒈结构图
⒉机制流程讲解
⒊源码(pytorch框架实现)及逐行解释
⒋测试结果
三,钢材表面瑕疵检测
㈠背景及研究意义
㈡钢材种类
㈢缺陷种类
㈣检测面临的难点
㈤瑕疵检测和识别算法流程
一,浅谈学习规划

二, 两个比较典型的注意力机制
㈠SEnet
⒈结构图

⒉机制流程讲解
通道注意力机制的思想是,对于输入进来的特征层,我们在每一个通道学习不同的权重,这些权重与不同通道的特征相关,决定了每个通道在任务中的重要性。
对于SENet而言,它会对输入特征层进行这些操作:
①首先对输入特征层做了global average pooling,也就是全局平均池化,全局平均池化将对当前特征层取平均值,显然,高、宽分别为H、W的特征层经过平均池化操作后会得到一个实数,这个实数就是所有输入特征层的平均值;另外,平均池化并不影响通道数,因此,输入为C*H*W的特征经过平均池化后,H和W两个维度被压缩,就将得到只剩下C(也就是通道数)这一个维度的特征层。
②然后,对于平均池化输出的矩阵,进行两次全连接,第一次全连接和第二次是不完全相同的,区别在于:第一次全连接的通道数不完整,而是取原通道数的1/r,也就是这边的C/r,第二次则是用正常的通道数进行全连接。
这样做的目的是——能够减少通道个数从而降低计算量,并在一定程度上防止网络模型过拟合。(我在学习SEnet的结构时,看到第一次全连接减少通道数这个操作时,就有联想到神经网络的另一个trick,叫做dropout,dropout是一种正则化技巧,通过随机让神经网络中的部分神经元暂时失活,从而减少模型的过拟合风险,当时我以为SEnet的第一个全连接层就是运用了这个trick,但后来查阅资料时发现不是这样,dropout是随机减少全连接层中的部分神经元,而SEnet在这里是固定减少特征图的通道数,只能说有些异曲同工之妙吧),刚刚是在分享我学习过程遇到的小问题,现在说回正题,全连接1只取原通道数的1/r以此来减少计算量与防止过拟合,但是全连接2又用回原通道数——这样做是为了输出与原特征层相同的通道数,以便后续的最重要的reweight操作,也就是通过乘法逐通道加权到原先的输入特征层上。
值得注意的是,两个全连接层不是简单的直接相连,而是在全连接1后面经过一个relu激活函数,这是全连接层中很常规的操作,用来对一个全连接层的输出结果进行非线性变换,如果不这样做,所有的全连接层都只是普通的线性组合,这样训练出来的模型无法理解复杂的非线性数据和特征,可想而知这样的模型的检测效果肯定是很差的。
relu激活函数的公式其实很简单:f(x) = max(0, x),在x大于等于零时是线性函数,但当输入为负数时,输出为零,在负数部分截断了线性部分,将其映射到了一个确定的点上,从而实现了非线性变换。
自绘烂图,将就看。

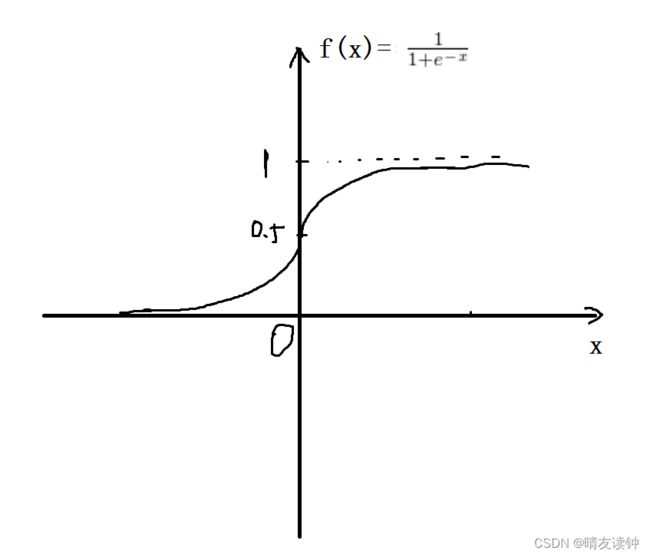
③再然后,需要对全连接2的输出结果映射到sigmoid函数中,sigmoid是很经典的激活函数,它的值域是0到1,画一下函数图像(显然x=0时函数值等于0.5)……然后,它的定义域是整个实数集,值域是0到1,也就是说,全连接2的输出结果映射到sigmoid函数中后,就将得到一组0到1之间的值(因此称此操作为归一化),也就是所谓的不同通道的权重。
公式:![]()
自绘烂图,我真的尽力画了/(ㄒoㄒ)/~~
最后最后,将这组通道权重与原输入2特征层通过乘法逐通道加权,就实现了“增强重要的通道,抑制不重要的通道”,也就是所谓的通道注意力机制
⒊源码(pytorch框架实现)及逐行解释
import torch
from torch import nn
from torchsummary import summary
class SEAttention(nn.Module):
def __init__(self, inputs, ratio=4):
super(SEAttention, self).__init__() # 调用父类构造方法
_, c, _, _ = inputs.size()# NCHW
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.linear1 = nn.Linear(c, c // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.linear2 = nn.Linear(c // ratio, c, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
n, c, _, _ = inputs.size()
x = self.avgpool(inputs).view(n, c)#nchw,池化加reshape压缩维度
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.sigmoid(x)
x = x.view(n, c, 1, 1) #reshape还原维度
return inputs * x
#这边是测试代码,用summary类总结网络模型层
inputs = torch.randn(32, 512, 26, 26) # NCHW
my_model = SEAttention(inputs)
outputs = my_model(inputs)
summary(my_model.cuda(), input_size=(512, 26, 26))
解释:
①依赖包为torch,以及torch里的nn模块(导入这个纯粹是省得还要用torch.nn去调用nn的类或方法),summary类是用来测试的,需要提前下载,命令为->pip install torchsummary
②从整体来看,我们运用封装思想将整个模块封装为类,且这个类继承于nn.Moudule这个类,这个类共两部分,
__init__函数用来对实例化对象进行初始化,在python中这个函数属于类的魔术方法。
#代码逐行解释:
def __init__(self, inputs, ratio=4):#self必须写,inputs接收输入张量,ratio是通道衰减因子
super(SEAttention, self).__init__() # super关键字调用父类(即nn.Moudule类)的构造方法
_, c, _, _ = inputs.size()#获取张量的形状(即NCHW),该模块只关注参数C,其余用占位符忽略
self.avgpool = nn.AdaptiveAvgPool2d(1)#nn模块的自适应二维平均池化,参数1等同于全局平均池化
self.linear1 = nn.Linear(c, c // ratio, bias=False)#nn模块的全连接,这里输入c,输出c//ratio,bias是偏置参数,网络层是否有偏置,默认存在,若bias=False,则该网络层无偏置,图层不会学习附加偏差
self.relu = nn.ReLU(inplace=True)#nn模块的ReLU激活函数,inplace=True表示要用引用传递(即地址传递),估计可以减少张量的内存占用(因为值传递要拷贝一份)
self.linear2 = nn.Linear(c // ratio, c, bias=False)#同全连接1,但输入输出相反
self.sigmoid = nn.Sigmoid()#nn模块的Sigmoid函数forward函数进行前向传播,用初始化好的网络模型对输入特征层进行一系列加工。
#代码逐行解释:
def forward(self, inputs):#self必须写,inputs接收输入特征张量
n, c, _, _ = inputs.size()#获取张量形状(即NCHW),HW被忽略
x = self.avgpool(inputs).view(n, c)#nchw,池化加view方法重塑(reshape)张量形状,因为全连接层之间的张量必须是二维的(一个输入维度一个输出维度),view的参数是(n,c)表示只保留这两个维度
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.sigmoid(x)#上面这四行直接调用初始化好的网络层即可
x = x.view(n, c, 1, 1) #reshape还原维度,因为要和原输入特征相乘,不重塑形状不同无法相乘
return inputs * x#和原输入特征层相乘⒋测试结果
感觉summary类没有很好使。。。有些关键网络层的变换没有体现出来,这里是少了最后reshape的一层,但无伤大雅罢!

㈡CBAM
⒈结构图
下面这个是自绘的,有些许草率。。。
因为CBAM机制是由通道和空间两部分组成的,所以有这两个模块(左边是通道注意力机制,右边是空间注意力机制)

下面这两个是官方论文里的:


⒉机制流程讲解
SEnet只关注了通道注意力机制而忽略了空间上的一些简单特征,相比之下,CBAM将通道注意力机制和空间注意力机制进行一个结合,对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理,而是是先通道后空间,也就是第一张结构图表达的意思。
①首先是通道机制:
对于输入特征层,分别作全局最大池化和全局平均池化,输出结果分别送入一个共享全连接层(官方源码在这里和SEnet的全连接层一模一样),为什么叫共享全连接层?因为最大池化和平均池化的两条路线用的是这同一个全连接层。然后对两个结果(maxout和avgout)做加法,最后进行归一化操作,获得通道上的权重矩阵。
②然后是空间机制:
对于输入特征层,在每一个特征点的通道上取最大值和平均值,(这里和通道机制的最大池化和平均池化完全不同,通道机制里是在H、W两个维度求最大或平均,空间机制是在C一个维度上求最大和平均。)然后对两个结果(maxout和avgout)做拼接,也就是maxout的1*H*W与avgout的1*H*W进行拼接,得到2*H*W的张量,因此紧接着下一步就要进行一个7*7的卷积(conv)将通道压缩回1,最后还是进行归一化操作,获得空间上的权重矩阵。
③整体上:
对于输入特征层,输入特征层先乘上通道机制的输出权重(channel_out),然后再乘上空间上的输出权重(spatial_out)
⒊源码(pytorch框架实现)及逐行解释
import torch
from torch import nn
from torchsummary import summary
class ChannelModule(nn.Module):
def __init__(self, inputs, ratio=16):
super(ChannelModule, self).__init__()
_, c, _, _ = inputs.size()
self.maxpool = nn.AdaptiveMaxPool2d(1)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.share_liner = nn.Sequential(
nn.Linear(c, c // ratio),
nn.ReLU(),
nn.Linear(c // ratio, c)
)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
x = self.maxpool(inputs).view(inputs.size(0), -1)#nc
maxout = self.share_liner(x).unsqueeze(2).unsqueeze(3)#nchw
y = self.avgpool(inputs).view(inputs.size(0), -1)
avgout = self.share_liner(y).unsqueeze(2).unsqueeze(3)
return self.sigmoid(maxout + avgout)
class SpatialModule(nn.Module):
def __init__(self):
super(SpatialModule, self).__init__()
self.maxpool = torch.max
self.avgpool = torch.mean
self.concat = torch.cat
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
maxout, _ = self.maxpool(inputs, dim=1, keepdim=True)#n1hw
avgout = self.avgpool(inputs, dim=1, keepdim=True)#n1hw
outs = self.concat([maxout, avgout], dim=1)#n2hw
outs = self.conv(outs)#n1hw
return self.sigmoid(outs)
class CBAM(nn.Module):
def __init__(self, inputs):
super(CBAM, self).__init__()
self.channel_out = ChannelModule(inputs)
self.spatial_out = SpatialModule()
def forward(self, inputs):
outs = self.channel_out(inputs) * inputs
return self.spatial_out(outs) * outs解释:
①依赖包和SEnet解释的一样。
②整体上看,将通道机制和空间机制分别封装成类,再封装一个CBAM类来对这两个机制调用,其中用到的__init__构造方法(python称魔术方法)和foward函数(前向传播过程),这些模板和上面介绍SEnet时是一模一样的。
先来看通道机制:
class ChannelModule(nn.Module):#继承nn模块的Module类
def __init__(self, inputs, ratio=16):#self必写,inputs接收输入特征张量,ratio是通道衰减因子
super(ChannelModule, self).__init__()#调用父类构造
_, c, _, _ = inputs.size()#获取通道数
self.maxpool = nn.AdaptiveMaxPool2d(1)#nn模块的自适应二维最大池化
self.avgpool = nn.AdaptiveAvgPool2d(1)#nn模块的自适应二维平均池化
self.share_liner = nn.Sequential(
nn.Linear(c, c // ratio),
nn.ReLU(),
nn.Linear(c // ratio, c)
)#这个共享全连接的3层和SEnet的一模一样,这里借助Sequential这个容器把这3个层整合在一起,方便forward函数去执行,直接调用share_liner(x)相当于直接执行了里面这3层
self.sigmoid = nn.Sigmoid()#nn模块的Sigmoid函数
def forward(self, inputs):
x = self.maxpool(inputs).view(inputs.size(0), -1)#对于输入特征张量,做完最大池化后再重塑形状,view的第一个参数inputs.size(0)表示第一维度,显然就是n;-1表示会自适应的调整剩余的维度,在这里就将原来的(n,c,1,1)调整为了(n,c*1*1),后面才能送入全连接层(fc层)
maxout = self.share_liner(x).unsqueeze(2).unsqueeze(3)#做完全连接后,再用unsqueeze解压缩,也就是还原指定维度,这里用了两次,分别还原2维度的h,和3维度的w
y = self.avgpool(inputs).view(inputs.size(0), -1)
avgout = self.share_liner(y).unsqueeze(2).unsqueeze(3)#y走的平均池化路线的代码和x是一样的解释
return self.sigmoid(maxout + avgout)#最后相加两个结果并作归一化再来看空间机制:(重复的模板就不再反复赘述了)
class SpatialModule(nn.Module):
def __init__(self):
super(SpatialModule, self).__init__()
self.maxpool = torch.max
self.avgpool = torch.mean
#和通道机制不一样!这里要进行的是在C这一个维度上求最大和平均,分别用的是torch库里的max方法和mean方法
self.concat = torch.cat#torch的cat方法,用于拼接两个张量
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)#nn模块的二维卷积,其中的参数分别是:输入通道(2),输出通道(1),卷积核大小(7*7),步长(1),灰度填充(3)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
maxout, _ = self.maxpool(inputs, dim=1, keepdim=True)#maxout接收特征点的最大值很好理解,为什么还要一个占位符?因为torch.max不仅返回张量最大值,还会返回索引,索引用不着所以直接忽略,dim=1表示在维度1(也就是nchw的c)上求最大值,keepdim=True表示要保持原来张量的形状
avgout = self.avgpool(inputs, dim=1, keepdim=True)#torch.mean则只返回张量的平均值,至于参数的解释和上面是一样的
outs = self.concat([maxout, avgout], dim=1)#torch.cat方法,传入一个列表,将列表中的张量在指定维度,这里是维度1(也就是nchw的c)拼接,即n*1*h*w拼接n*1*h*w得到n*2*h*w
outs = self.conv(outs)#卷积压缩上面的n*2*h*w,又得到n*1*h*w
return self.sigmoid(outs)最后看整体:
class CBAM(nn.Module):
def __init__(self, inputs):
super(CBAM, self).__init__()
self.channel_out = ChannelModule(inputs)#获得通道权重
self.spatial_out = SpatialModule()#获得空间权重
def forward(self, inputs):
outs = self.channel_out(inputs) * inputs #先乘上通道权重
return self.spatial_out(outs) * outs #在乘完通道权重的基础上再乘上空间权重⒋测试结果
大问题没有,但还是少了一些关键层,尤其是空间机制那里的拼接maxout和avgout,通道变为2再用卷积压缩回1的过程都没体现。。。只能说summary确实不太好使,或者说我没用对?网络层简写导致的?(最不可能是这个原因,因为我拿官方的源码测试也是summary出这些结果)

三,钢材表面瑕疵检测
㈠背景及研究意义
钢板是制造业很多商品不可缺少的原料,钢板的轧制过程中,因为加工工艺等缘故,钢板表面会出現刮痕、孔眼、鳞片等缺陷,这种缺陷严重影响钢板的品质和性能指标。
钢板表面缺陷检测技术始于20世纪50年代,从人工检测到现在的机器视觉检测,共经历60多年的发展,按时间的先后顺序大致可以分为非自动化检测、自动化检测和机器视觉检测共三个阶段。
下表列出了各类缺陷检测技术的对比——

㈡钢材种类
根据工艺,可分热轧带钢和冷轧带钢
下表我列出两种不同工艺生产的钢材的区别——

㈢缺陷种类
由东北大学(NEU)发布的表面缺陷数据库(NEU-DET),收集了热轧钢带的六种典型表面缺陷,轧制氧化皮(RS),斑块 (Pa),开裂(Cr),点蚀表面(PS),内含物(In)和划痕(Sc)
- rolled-in scale (RS)
- patches (Pa)
- crazing (Cr)
- pitted surface (PS)
- inclusion (In)
- scratches (Sc)
㈣检测面临的难点
目前,国内外对冷轧带钢表面在线检测技术研究比较多,并且也取得了一些成功应用的实例。与冷轧带钢表面检测相比,热轧带钢表面检测具有更大的难度。
原因是,除了热轧带钢生产线的环境恶劣,表面检测设备的安装与防护难度很大之外,热轧带钢表面瑕疵的检测与识别算法是另外一个难点。
由于热轧带钢表面温度高,辐射光强度大,并且存在大量的水、氧化铁皮及光照不均现象,会对缺陷检测与识别的算法造成很大的影响。而冷轧带钢表面没有辐射光,并且基本不存在水的干扰,氧化铁皮及光照不均现象也非常少,因此,热轧带钢表面瑕疵检测与识别算法的开发难度更大。
- 热轧环境下钢板表面容易产生雾化效果,并且光线传播容易变形,利用摄像头进行采集的时候容易发生光线偏移,造成图像变形或者影响图像的整体质量,增加图像中的噪声。
- 受环境、光照、生产工艺和噪声等多重因素影响,检测系统的信噪比一般较低,微弱信号难以检出或不能与噪声有效区分。如何构建稳定、可靠、精准的检测系统,以适应光照变化、噪声以及其他外界不良环境的干扰,是要解决的问题之一。
- 由于检测对象多样、表面缺陷种类繁多、形态多样、背景复杂,对于众多缺陷类型产生的机理以及其外在表现形式之间的关系尚不明确,致使对缺陷的描述不充分,缺陷的特征提取有效性不高,缺陷目标分割困难;同时,很难找到“标准”图像作为参照,这给缺陷的检测和分类带来困难,造成识别率尚有待提高。
- 从机器视觉表面检测的准确性方面来看,尽管一系列优秀的算法不断出现,但在实际应用中准确率仍然与满足实际应用的需求尚有一定差距,如何解决准确识别与模糊特征之间、实时性与准确性之间的矛盾仍然是目前的难点。
㈤瑕疵检测和识别算法流程
①冷轧带钢
冷轧带钢的瑕疵检测与识别流程如下图所示。可以看到,数字图像需要经过 4 个步骤来处理:
目标检测、图像分割、特征提取和缺陷分类。

- 目标检测:检测图像中是否可能存在缺陷,如果可能存在缺陷,则该图像存入计算机缓存,以便下一步处理。如果没有缺陷,则不保存这幅图像。
- 图像分割:找出缺陷所在的区域,即对缓存中的图像进行处理,确定图像中缺陷所在的区域。
- 特征提取:根据缺陷所在的区域计算缺陷的特征值,以便对缺陷进行分类。
- 缺陷分类:通过输入的特征值,对缺陷进行分类,以确定缺陷的类型和严重程度。
②热轧带钢
冷轧带钢表面瑕疵检测与识别流程中的一个重要步骤是目标检测,即判断采集到的图像中是否存在着缺陷,只有存在缺陷的图像才被存到计算机缓存中,以便下一步处理。由于冷轧带钢表面质量好,背景比较简单,缺陷或伪缺陷的区域相对较少因此,经过这一步骤可以大大减少下一步处理的图像数量,减轻下面步骤需要的处理时间。
但是对于热轧带钢来说,由于其表面存在着大量的水、氧化铁皮及光照不均现象,如果用简单算法判断的话,存在这些现象的图像都会被认为有缺陷,那么目标检测步骤达不到减少图像数量的目的,起不到该步骤应有的作用。
采取删除目标检测步骤,但是增加了 4 种不同类型的缺陷检测步骤,这一变化是根据热轧带钢表面的特点作出的,目的是为了筛选可疑区域,减少由伪缺陷组成的可疑区域数量。

⒈图像分割步骤:
寻找可能存在缺陷的区域,该区域称为可疑区域,可疑区域可能由缺陷形成,也可能由伪缺陷形成。可疑区域的数据保存在计算机缓存中,以便进一步处理。由于每幅图像都要经过这一步骤,所以这一步骤需要实时完成,只能使用简单的算法。这一步骤的关键是要尽可能把所有的缺陷区域都找出来,以便避免缺陷的漏识,但同时又不能找出太多的伪缺陷,以便减少可疑区域的数量,减轻下面步骤的运算量。
⒉缺陷检测步骤:
由于可疑区域中会包含一些伪缺陷,如果将这些伪缺陷直接用于缺陷分类,那么会造成大量的误识,即将伪缺陷识别成缺陷。所以需要对可疑区域进行筛选,保证可疑区域尽可能由真缺陷组成。可疑区域筛选有两种方法,一种方法是去除伪缺陷,另一种是挑选真缺陷。由于伪缺陷基本由水、氧化铁皮与光照不均现象引起,很难找到算法将它们直接去除,因此只能采取第二种方案——
热轧带钢表面缺陷从其形态与分布上可以分为下面4类:
- 纵向缺陷:沿带钢轧制方向分布,一般在轧制方向有大的尺寸,但在宽度方向上的尺寸比较小,如纵裂和划伤等。
- 横向缺陷:沿带钢宽度方向分布,一般在带钢宽度方向上有大的尺寸,但在轧制方向上的尺寸比较小,如横裂和横向辊印等。
- 单个缺陷:一些面积比较大的缺陷,这些缺陷不具有明显纵向分布和横向分布特点,如夹杂、气泡、结疤和折叠等。
- 分布式缺陷:这在一定范围内密集分布,虽然单个缺陷的面积不大,但是分布的面积比较广,如麻面、某些压痕等。

根据这 4 类缺陷的特点,对可疑区域进行筛选,从可疑区域中找出具有上述特征的 4 类缺陷,并组成缺陷区域。
⒊特征提取与缺陷分类步骤:
经过缺陷检测步骤,大部分的伪缺陷被去除了,但是还会存在一些伪缺陷。而且,需要对检测到的缺陷进行自动分类,该步骤就用于对缺陷进行自动分类,以识别缺陷的类型,并去除剩余的伪缺陷。
由于每幅图像都要经过图像分割步骤,所以图像分割步骤需要实时完成。而图像分割步骤后得到的可疑区域保存到计算机缓存中,因此,缺陷检测步骤可以在 CPU 有空闲的时候进行,采取准时处理的方式。经过缺陷检测步骤后得到的缺陷区域保存到服务器中,因此,特征提取与缺陷分类步骤可以在换卷时再进行。
通过实时处理、准时处理和换卷时处理这三种方式,可以既保证数据处理的实时性,同时也保证缺陷的检出率与识别率。