PP-OCR笔记
目录
- 检测det
-
- 数据准备
-
- 数据格式
- 训练
-
- 模型微调
-
- 数据选择
- 模型选择
-
- 前沿算法与模型
- 训练超参选择
- 预测超参选择
- 启动训练
- 断点训练
- 更换Backbone 训练
-
- 添加新算法
- 混合精度训练
- 分布式训练
- 知识蒸馏训练
- 其他训练环境
- 评估、预测
- 导出、预测
-
- 模型推理超参数解释教程
- FAQ
-
- 训练模型转inference 模型之后预测效果不一致
- 训练EAST模型提示找不到lanms库
- 识别rec
-
- 数据准备
-
- 数据格式
- 文件结构:
- 字典
- 添加空格类别
- 数据增强
- 训练
-
- 模型微调
-
- 数据选择
-
- 特定字符生成
- 模型选择
-
- 前沿算法与模型
- 训练超参选择
- 训练调优
- 启动训练
- 断点训练
- 更换Backbone 训练
-
- 添加新算法
- 混合精度训练
- 分布式训练
- 知识蒸馏训练
- 多语言模型训练
- 其他训练环境
- 评估、预测
- 导出、预测
-
- 模型推理超参数解释教程
- 模型压缩
-
- 量化
-
- 量化训练
- 导出模型
- 量化模型部署
- det+rec串联推理
- 配置文件内容与生成
检测det
数据准备
数据格式
PaddleOCR 中的文本检测算法支持的标注文件格式如下,中间用"\t"分隔,当transcription为“###”时,表示该文本框无效,在训练时会跳过
" 图像文件名 json.dumps编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
训练
实际使用过程中,建议加载官方提供的预训练模型,在自己的数据集中进行微调
模型微调
- PP-OCR提供的预训练模型有较好的泛化能力
- 加入少量真实数据(检测任务>=500张, 识别任务>=5000张),会大幅提升垂类场景的检测与识别效果
- 在模型微调时,加入真实通用场景数据,可以进一步提升模型精度与泛化性能
- 在图像检测任务中,增大图像的预测尺度,能够进一步提升较小文字区域的检测效果
- 在模型微调时,需要适当调整超参数(学习率,batch size最为重要),以获得更优的微调效果。
数据选择
- 数据量:建议至少准备500张的文本检测数据集用于模型微调。
- 数据标注:单行文本标注格式,建议标注的检测框与实际语义内容一致。如在火车票场景中,姓氏与名字可能离得较远,但是它们在语义上属于同一个检测字段,这里也需要将整个姓名标注为1个检测框。
模型选择
中文检测模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 模型下载 |
|---|---|---|---|---|
| ch_ppocr_server_v2.0_det | 通用模型,支持中英文、多语种文本检测,比超轻量模型更大,但效果更好 | ch_det_res18_db_v2.0.yml | 47.0M | 推理模型/训练模型 |
前沿算法与模型
提示: 可通过 -c 参数选择 configs/rec/ 路径下的多种模型配置进行训练,PaddleOCR支持的检测算法可以参考前沿算法列表
训练超参选择
在模型微调的时候,最重要的超参就是预训练模型路径pretrained_model, 学习率learning_rate与batch_size,部分配置文件如下所示。
Global:
pretrained_model: ./ch_PP-OCRv3_det_distill_train/student.pdparams # 预训练模型路径
Optimizer:
lr:
name: Cosine
learning_rate: 0.001 # 学习率
warmup_epoch: 2
regularizer:
name: 'L2'
factor: 0
Train:
loader:
shuffle: True
drop_last: False
batch_size_per_card: 8 # 单卡batch size
num_workers: 4
PaddleOCR提供的配置文件是在8卡训练(相当于总的batch size是8*8=64)、且没有加载预训练模型情况下的配置文件,因此您的场景中,学习率与总的batch size需要对应线性调整。
预测超参选择
| 参数名称 | 类型 | 默认值 | 含义 |
|---|---|---|---|
| det_db_thresh | float | 0.3 | DB输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点 |
| det_db_box_thresh | float | 0.6 | 检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域 |
| det_db_unclip_ratio | float | 1.5 | Vatti clipping算法的扩张系数,使用该方法对文字区域进行扩张 |
| max_batch_size | int | 10 | 预测的batch size |
| use_dilation | bool | False | 是否对分割结果进行膨胀以获取更优检测效果 |
| det_db_score_mode | str | “fast” | DB的检测结果得分计算方法,支持fast和slow,fast是根据polygon的外接矩形边框内的所有像素计算平均得分,slow是根据原始polygon内的所有像素计算平均得分,计算速度相对较慢一些,但是更加准确一些。 |
启动训练
如果您安装的是cpu版本,请将配置文件中的 use_gpu 字段修改为false
# 单机单卡训练 mv3_db 模型
python3 tools/train.py -c configs/det/det_detail_res18_db_v230719.yml -o Global.pretrained_model=./output/det_detail_db_res18_v2.0_230719/best_accuracy
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_detail_res18_db_v230719.yml -o Global.pretrained_model=./output/det_detail_db_res18_v2.0_230719/best_accuracy
断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径
python3 tools/train.py -c configs/det/det_detail_res18_db_v230719.yml -o Global.checkpoints=./output/det_detail_db_res18_v2.0_230719/latest
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
更换Backbone 训练
PaddleOCR将网络划分为四部分,分别在ppocr/modeling下。 进入网络的数据将按照顺序(transforms->backbones-> necks->heads)依次通过这四个部分。
├── architectures # 网络的组网代码
├── transforms # 网络的图像变换模块
├── backbones # 网络的特征提取模块
├── necks # 网络的特征增强模块
└── heads # 网络的输出模块
如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中Backbone部分的参数即可。
如果要使用新的Backbone,更换backbones的例子如下:
- 在 ppocr/modeling/backbones 文件夹下新建文件,如my_backbone.py。
- 在 my_backbone.py 文件内添加相关代码,示例代码如下:
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class MyBackbone(nn.Layer):
def __init__(self, *args, **kwargs):
super(MyBackbone, self).__init__()
# your init code
self.conv = nn.xxxx
def forward(self, inputs):
# your network forward
y = self.conv(inputs)
return y
- 在 ppocr/modeling/backbones/init.py文件内导入添加的
MyBackbone模块,然后修改配置文件中Backbone进行配置即可使用,格式如下:
Backbone:
name: MyBackbone
args1: args1
注意:如果要更换网络的其他模块,可以参考文档。
添加新算法
PaddleOCR将一个算法分解为以下几个部分,并对各部分进行模块化处理,方便快速组合出新的算法。
- 数据加载和处理
- 网络
- 后处理
- 损失函数
- 指标评估
- 优化器
混合精度训练
如果您想进一步加快训练速度,可以使用自动混合精度训练, 以单机单卡为例,命令如下:
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
分布式训练
多机多卡训练时,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID:
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
注意: (1)采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通;(2)训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为ifconfig;(3)更多关于分布式训练的性能优势等信息,请参考:分布式训练教程。
知识蒸馏训练
PaddleOCR支持了基于知识蒸馏的检测模型训练过程,更多内容可以参考知识蒸馏说明文档。
注意: 知识蒸馏训练目前只支持PP-OCR使用的DB和CRNN算法。
其他训练环境
- Windows GPU/CPU 在Windows平台上与Linux平台略有不同: Windows平台只支持
单卡的训练与预测,指定GPU进行训练set CUDA_VISIBLE_DEVICES=0在Windows平台,DataLoader只支持单进程模式,因此需要设置num_workers为0; - macOS 不支持GPU模式,需要在配置文件中设置
use_gpu为False,其余训练评估预测命令与Linux GPU完全相同。 - Linux DCU DCU设备上运行需要设置环境变量
export HIP_VISIBLE_DEVICES=0,1,2,3,其余训练评估预测命令与Linux GPU完全相同。
评估、预测
评估
计算三个OCR检测相关的指标,分别是:Precision、Recall、Hmean(F-Score)。
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。
python tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints="{path/to/weights}/best_accuracy"
预测
测试单张图像:
python tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy"
测试文件夹下所有图像:
python tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/" Global.pretrained_model="./output/det_db/best_accuracy"
调整后处理阈值:
-o PostProcess.box_thresh=0.6 PostProcess.unclip_ratio=2.0
- 注:
box_thresh、unclip_ratio是DB后处理参数,其他检测模型不支持。
导出、预测
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
检测模型转inference 模型方式:
# 加载配置文件`det_mv3_db.yml`,从`output/det_db`目录下加载`best_accuracy`模型,inference模型保存在`./output/det_db_inference`目录下
python tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model="./output/det_db/best_accuracy" Global.save_inference_dir="./output/det_db_inference/"
inference 模型预测:
python tools/infer/predict_det.py --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True
其他检测,比如EAST模型,det_algorithm参数需要修改为EAST,默认为DB算法:
python tools/infer/predict_det.py --det_algorithm="EAST" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True
模型推理超参数解释教程
更多关于推理超参数的配置与解释,请参考:模型推理超参数解释教程。
FAQ
训练模型转inference 模型之后预测效果不一致
此类问题出现较多,问题多是trained model预测时候的预处理、后处理参数和inference model预测的时候的预处理、后处理参数不一致导致的。以det_mv3_db.yml配置文件训练的模型为例,训练模型、inference模型预测结果不一致问题解决方式如下:
- 检查trained model预处理,和inference model的预测预处理函数是否一致。算法在评估的时候,输入图像大小会影响精度,为了和论文保持一致,训练icdar15配置文件中将图像resize到[736, 1280],但是在inference model预测的时候只有一套默认参数,会考虑到预测速度问题,默认限制图像最长边为960做resize的。训练模型预处理和inference模型的预处理函数位于ppocr/data/imaug/operators.py
- 检查trained model后处理,和inference 后处理参数是否一致。
训练EAST模型提示找不到lanms库
执行pip3 install lanms-nova 即可
识别rec
数据准备
PaddleOCR 支持两种数据格式:
lmdb用于训练以lmdb格式存储的数据集(LMDBDataSet);通用数据用于训练以文本文件存储的数据集(SimpleDataSet);
数据格式
txt文件中默认请将图片路径和图片标签用 \t 分割
" 图像文件名 图像标注信息 "
dataset_rec_230309/word_001.jpg 简单可依赖
dataset_rec_230309/word_002.jpg 用科技让复杂的世界更简单
...
PaddleOCR也支持对离线增广后的数据进行训练,训练时会随机选择列表中的一张图片进行训练。
["dataset_rec_230309/11.jpg", "dataset_rec_230309/12.jpg"] 简单可依赖
["dataset_rec_230309/21.jpg", "dataset_rec_230309/22.jpg", "dataset_rec_230309/23.jpg"] 用科技让复杂的世界更简单
dataset_rec_230309/3.jpg ocr
文件结构:
|-dataset_rec
|-train_data
|- train_bbox_table_230309.txt
|- dataset_rec_230309
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
|-test_data
|- test_bbox_table_230309.txt
|- dataset_rec_230309
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
字典
需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 utf-8 编码格式保存:
l
d
a
d
r
n
word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“and” 将被映射成 [2 5 1]
- 内置字典
ppocr/utils/ppocr_keys_v1.txt是一个包含6623个字符的中文字典 - 在
configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml中添加character_dict_path字段, 指向您的字典路径
添加空格类别
如果希望支持识别"空格"类别, 请将yml文件中的 use_space_char 字段设置为 True。
数据增强
PaddleOCR提供了多种数据增强方式,默认配置文件中已经添加了数据增广。
默认的扰动方式有:颜色空间转换(cvtColor)、模糊(blur)、抖动(jitter)、噪声(Gasuss noise)、随机切割(random crop)、透视(perspective)、颜色反转(reverse)、TIA数据增广。
训练过程中每种扰动方式以40%的概率被选择,具体代码实现请参考:rec_img_aug.py
由于OpenCV的兼容性问题,扰动操作暂时只支持Linux
训练
实际使用过程中,建议加载官方提供的预训练模型,在自己的数据集中进行微调
模型微调
数据选择
- 数据量:不更换字典的情况下,建议至少准备5000张的文本识别数据集用于模型微调;如果更换了字典(不建议),需要的数量更多。
- 数据分布:建议分布与实测场景尽量一致。如果实测场景包含大量短文本,则训练数据中建议也包含较多短文本,如果实测场景对于空格识别效果要求较高,则训练数据中建议也包含较多带空格的文本内容。
- 数据合成:针对部分字符识别有误的情况,建议获取一批特定字符数据,加入到原数据中使用小学习率微调。其中原始数据与新增数据比例可尝试 10:1 ~ 5:1, 避免单一场景数据过多导致模型过拟合,同时尽量平衡语料词频,确保常用字的出现频率不会过低。
- 通用中英文数据:在训练的时候,可以在训练集中添加通用真实数据(如在不更换字典的微调场景中,建议添加LSVT、RCTW、MTWI等真实数据),进一步提升模型的泛化性能。
特定字符生成
可以使用 TextRenderer 工具,合成例子可参考 数码管数据合成 ,合成数据语料尽量来自真实使用场景,在贴近真实场景的基础上保持字体、背景的丰富性,有助于提升模型效果。
模型选择
中文识别模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 模型下载 |
|---|---|---|---|---|
| ch_ppocr_server_v2.0_rec | 通用模型,支持中英文、数字识别 | rec_chinese_common_train_v2.0.yml | 94.8M | 推理模型/训练模型/预训练模型 |
说明: 训练模型是基于预训练模型在真实数据与竖排合成文本数据上finetune得到的模型,在真实应用场景中有着更好的表现,预训练模型则是直接基于全量真实数据与合成数据训练得到,更适合用于在自己的数据集上finetune。
前沿算法与模型
提示: 可通过 -c 参数选择 configs/rec/ 路径下的多种模型配置进行训练,PaddleOCR支持的识别算法可以参考前沿算法列表
训练超参选择
最重要的超参就是预训练模型路径pretrained_model, 学习率learning_rate与batch_size
Global:
pretrained_model: # 预训练模型路径
Optimizer:
lr:
name: Piecewise
decay_epochs : [700, 800]
values : [0.001, 0.0001] # 学习率
warmup_epoch: 5
regularizer:
name: 'L2'
factor: 0
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/
label_file_list:
- ./train_data/train_list.txt
ratio_list: [1.0] # 采样比例,默认值是[1.0]
loader:
shuffle: True
drop_last: False
batch_size_per_card: 128 # 单卡batch size
num_workers: 8
PaddleOCR提供的配置文件是在8卡训练(相当于总的batch size是8*128=1024)、且没有加载预训练模型情况下的配置文件,因此您的场景中,学习率与总的batch size需要对应线性调整,例如:
- 如果您的场景中是单卡训练,单卡batch_size=128,则总的batch_size=128,在加载预训练模型的情况下,建议将学习率调整为
[1e-4, 2e-5]左右(piecewise学习率策略,需设置2个值,下同)。 - 如果您的场景中是单卡训练,因为显存限制,只能设置单卡batch_size=64,则总的batch_size=64,在加载预训练模型的情况下,建议将学习率调整为
[5e-5, 1e-5]左右。
如果有通用真实场景数据加进来,建议每个epoch中,垂类场景数据与真实场景的数据量保持在1:1左右。
训练调优
训练过程并非一蹴而就的,完成一个阶段的训练评估后,建议收集分析当前模型在真实场景中的 badcase,有针对性的调整训练数据比例,或者进一步新增合成数据。通过多次迭代训练,不断优化模型效果。
启动训练
可在配置文件中设置训练和评估交替进行, eval_batch_step 设置评估频率,默认每500个iter评估一次。
#多卡训练,通过--gpus参数指定卡号
python -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0_230727.yml -o Global.pretrained_model=./output/rec_chinese_common_v2.0_230727_v2/best_accuracy
注意,预测/评估时的配置文件请务必与训练一致。
训练中文数据,推荐使用ch_PP-OCRv3_rec_distillation.yml,如您希望尝试其他算法在中文数据集上的效果,请参考下列说明修改配置文件:
以 ch_PP-OCRv3_rec_distillation.yml 为例:
Global:
...
# 添加自定义字典,如修改字典请将路径指向新字典
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
...
# 识别空格
use_space_char: True
Optimizer:
...
# 添加学习率衰减策略
lr:
name: Cosine
learning_rate: 0.001
...
...
Train:
dataset:
# 数据集格式,支持LMDBDataSet以及SimpleDataSet
name: SimpleDataSet
# 数据集路径
data_dir: ./train_data/
# 训练集标签文件
label_file_list: ["./train_data/train_list.txt"]
transforms:
...
- RecResizeImg:
# 修改 image_shape 以适应长文本
image_shape: [3, 48, 320]
...
loader:
...
# 单卡训练的batch_size
batch_size_per_card: 256
...
Eval:
dataset:
# 数据集格式,支持LMDBDataSet以及SimpleDataSet
name: SimpleDataSet
# 数据集路径
data_dir: ./train_data
# 验证集标签文件
label_file_list: ["./train_data/val_list.txt"]
transforms:
...
- RecResizeImg:
# 修改 image_shape 以适应长文本
image_shape: [3, 48, 320]
...
loader:
# 单卡验证的batch_size
batch_size_per_card: 256
...
log输出:
![]()
| 字段 | 含义 |
|---|---|
| epoch | 当前迭代轮次 |
| iter | 当前迭代次数 |
| lr | 当前学习率 |
| loss | 当前损失函数 |
acc |
当前batch的准确率 |
norm_edit_dis |
当前 batch 的 编辑距离 |
| reader_cost | 当前 batch 数据处理耗时 |
| batch_cost | 当前 batch 总耗时 |
| samples | 当前 batch 内的样本数 |
| ips | 每秒处理图片的数量 |
注:norm_edit_dis越大,表示当前字段和正确的越接近
断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0_230727.yml -o Global.checkpoints=./output/rec_chinese_common_v2.0/latest
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
更换Backbone 训练
PaddleOCR将网络划分为四部分,分别在ppocr/modeling下。 进入网络的数据将按照顺序(transforms->backbones->necks->heads)依次通过这四个部分。
├── architectures # 网络的组网代码
├── transforms # 网络的图像变换模块
├── backbones # 网络的特征提取模块
├── necks # 网络的特征增强模块
└── heads # 网络的输出模块
如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中Backbone部分的参数即可。
如果要使用新的Backbone,更换backbones的例子如下:
- 在 ppocr/modeling/backbones 文件夹下新建文件,如my_backbone.py。
- 在 my_backbone.py 文件内添加相关代码,示例代码如下:
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class MyBackbone(nn.Layer):
def __init__(self, *args, **kwargs):
super(MyBackbone, self).__init__()
# your init code
self.conv = nn.xxxx
def forward(self, inputs):
# your network forward
y = self.conv(inputs)
return y
- 在 ppocr/modeling/backbones/init.py文件内导入添加的
MyBackbone模块,然后修改配置文件中Backbone进行配置即可使用,格式如下:
Backbone:
name: MyBackbone
args1: args1
注意:如果要更换网络的其他模块,可以参考文档。
添加新算法
PaddleOCR将一个算法分解为以下几个部分,并对各部分进行模块化处理,方便快速组合出新的算法。
- 数据加载和处理
- 网络
- 后处理
- 损失函数
- 指标评估
- 优化器
混合精度训练
如果您想进一步加快训练速度,可以使用自动混合精度训练, 以单机单卡为例,命令如下:
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy \
Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
分布式训练
多机多卡训练时,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID:
python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml \
-o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
注意: (1)采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通;(2)训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为ifconfig;(3)更多关于分布式训练的性能优势等信息,请参考:分布式训练教程。
知识蒸馏训练
PaddleOCR支持了基于知识蒸馏的检测模型训练过程,更多内容可以参考知识蒸馏说明文档。
注意: 知识蒸馏训练目前只支持PP-OCR使用的DB和CRNN算法。
多语言模型训练
PaddleOCR目前已支持80种(除中文外)语种识别,configs/rec/multi_languages 路径下提供了一个多语言的配置文件模版: rec_multi_language_lite_train.yml。
其他训练环境
- Windows GPU/CPU 在Windows平台上与Linux平台略有不同: Windows平台只支持
单卡的训练与预测,指定GPU进行训练set CUDA_VISIBLE_DEVICES=0在Windows平台,DataLoader只支持单进程模式,因此需要设置num_workers为0; - macOS 不支持GPU模式,需要在配置文件中设置
use_gpu为False,其余训练评估预测命令与Linux GPU完全相同。 - Linux DCU DCU设备上运行需要设置环境变量
export HIP_VISIBLE_DEVICES=0,1,2,3,其余训练评估预测命令与Linux GPU完全相同。
评估、预测
注意,预测/评估时的配置文件请务必与训练一致。
评估
# GPU 评估, Global.checkpoints 为待测权重
python -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints={path/to/weights}/best_accuracy
预测
# 预测英文结果
python tools/infer_rec.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/
导出、预测
识别模型转inference模型与检测的方式相同,如下:
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0_230727.yml -o Global.pretrained_model=./output/rec_chinese_common_v2.0_230727_v2/best_accuracy Global.save_inference_dir=./output_inference/rec_chinese_common_v2.0_230727_v2/
inference模型预测
注意:若训练修改了字典,预测需要通过--rec_char_dict_path指定使用的字典路径
# 通过--rec_char_dict_path指定使用的字典路径
python tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/" --rec_model_dir="./output_inference/rec_chinese_common_v2.0_230727_v2" --rec_char_dict_path="./ppocr/utils/ppocr_keys_v2.txt"
模型推理超参数解释教程
更多关于推理超参数的配置与解释,请参考:模型推理超参数解释教程。
模型压缩
量化
量化训练
量化训练包括离线量化训练和在线量化训练,在线量化训练效果更好,需加载预训练模型,在定义好量化策略后即可对模型进行量化。
量化训练的代码位于slim/quantization/quant.py 中,比如训练检测模型,以PPOCRv3检测模型为例,训练指令如下:
python deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model='./ch_PP-OCRv3_det_distill_train/best_accuracy' Global.save_model_dir=./output/quant_model_distill/
如果要训练识别模型的量化,修改配置文件和加载的模型参数即可。
导出模型
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
量化模型部署
上述步骤导出的量化模型,参数精度仍然是FP32,但是参数的数值范围是int8,导出的模型可以通过PaddleLite的opt模型转换工具完成模型转换。
量化模型移动端部署的可参考 移动端模型部署
备注:量化训练后的模型参数是float32类型,转inference model预测时相对不量化无加速效果,原因是量化后模型结构之间存在量化和反量化算子,如果要使用量化模型部署,建议使用TensorRT并设置precision为INT8加速量化模型的预测时间。
--use_tensorrt=True
--precision="int8"

det+rec串联推理
注意 PP-OCRv3的识别模型使用的输入shape为3,48,320, 如果使用其他识别模型,则需根据模型设置参数--rec_image_shape。此外,PP-OCRv3的识别模型默认使用的rec_algorithm为SVTR_LCNet,注意和原始SVTR的区别。
在执行预测时,需要通过参数image_dir指定单张图像或者图像集合的路径,也支持PDF文件、参数det_model_dir,cls_model_dir和rec_model_dir分别指定检测,方向分类和识别的inference模型路径。参数use_angle_cls用于控制是否启用方向分类模型。use_mp表示是否使用多进程。total_process_num表示在使用多进程时的进程数。可视化识别结果默认保存到 ./inference_results 文件夹里面。
# 使用方向分类器
python tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --cls_model_dir="./cls/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=true
# 不使用方向分类器
python tools/infer/predict_system.py --image_dir="/data/ocr/ocr_data/test_detail_4rec/开集测试图片_crop/" --det_model_dir="./output_inference/det_detail_res18_db_v230719_test/" --rec_model_dir="./output_inference/rec_chinese_common_v2.0_230727_v2_test/" --use_angle_cls=false --drop_score=0.0 --rec_char_dict_path='./ppocr/utils/ppocr_keys_v2.txt' --det_db_box_thresh=0.5 --det_db_unclip_ratio=2.2 --det_db_thresh=0.9999999
# 使用多进程
python tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=false --use_mp=True --total_process_num=6
# 使用PDF文件,可以通过使用`page_num`参数来控制推理前几页,默认为0,表示推理所有页
python tools/infer/predict_system.py --image_dir="./xxx.pdf" --det_model_dir="./ch_PP-OCRv3_det_infer/" --cls_model_dir="./cls/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=true --page_num=2
配置文件内容与生成
-
可选参数列表
以下列表可以通过--help查看

-
配置文件参数介绍
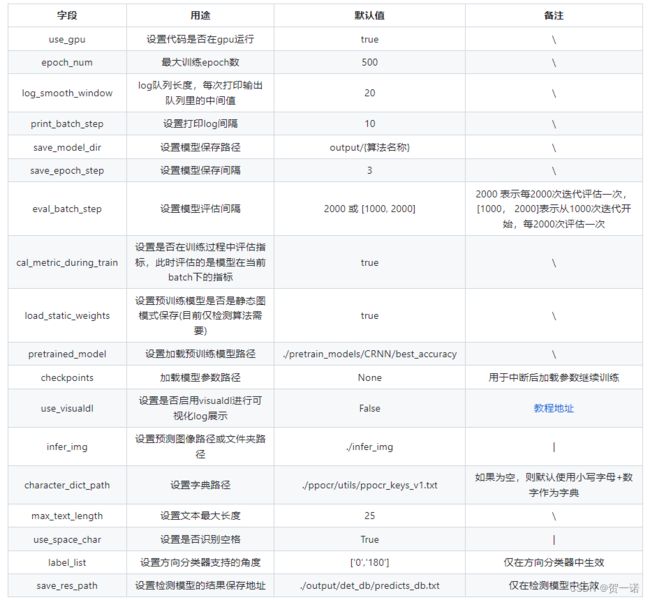
Global
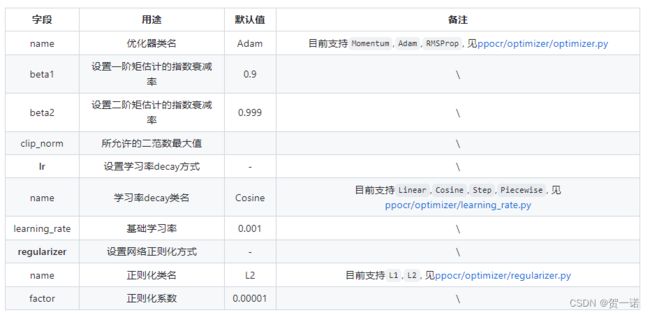
Optimizer (ppocr/optimizer)
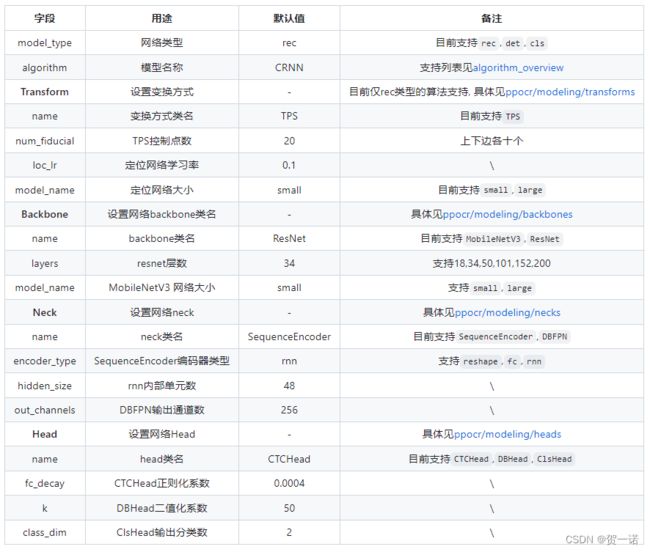
Architecture (ppocr/modeling)
在PaddleOCR中,网络被划分为Transform,Backbone,Neck和Head四个阶段
Loss (ppocr/losses)

PostProcess (ppocr/postprocess)

Metric (ppocr/metrics)

Dataset (ppocr/data)
