lambda表达式c++
介绍
可调用对象
对于一个表达式,如果可以对其使用调用运算符(),则称它为可调用对象。如函数就是一个可调用对象,当我们定义了一个函数f(int)时,我们可以通过f(5)来调用它。
可调用对象有:
- 函数
- 函数指针
- 重载了函数调用运算符的类
- lambda表达式
lamdba表达式语法结构
lambda表达式又称匿名函数,可以简单的理解为一个内联函数,它通常被写在一个普通函数的内部定义和使用,其语法结构为

使用参数列表
参数列表很好理解,类似于我们在定义一个普通函数的时候,要使用的参数,如
void sol() {
auto f = [](int a,int b) {return a+b; };
cout << f(2,3) << endl;
}上述代码中,我们定义了一个普通函数sol,并在其中定义了一个lambda表达式,在参数列表中定义了两个参数,并返回这两个参数的和
需要注意的是,与普通函数不同,lambda表达式中的参数列表中不能使用默认参数
使用捕获列表
捕获列表是一个lamdba表达式所在的普通函数的局部变量的列表,听起来很拗口,我们举例来说
void sol() {
auto f1 = [](int a,int b) {return a+b; };
cout << f1(2,3) << endl;
int x = 3, y = 4;
auto f2 = [x, y]() {return x + y; };
cout << f2() << endl;
}
上述代码中,我们在sol的普通函数中定义了两个lambda表达式,其中f1使用了参数列表,f2使用了捕获列表,二者的区别在于,lambda表达式f1的参数列表是自定义的,而lambda表达式f2中的捕获列表是使用了sol普通函数中的局部变量x和y
也就是说,如果你想在lambda表达式中使用所在函数的局部变量,就要使用捕获列表进行捕获,否则将无法使用该局部变量
为了强调说明这一问题,我们在sol函数中再次定义一个变量z,在捕获列表中不写入它,但在函数体中使用它,来观察结果
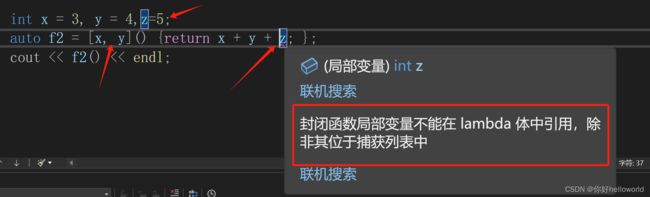
由此可见,捕获列表中存放的是lambad表达式所在函数的已经存在的局部变量
lambda表达式使用案例
接下来,我们从一个案例中来看lambda表达式的使用场景
问题描述
假如现在我们有一些单词,这些单词包含重复,现在我想知道这些单词的长度大于等于给定长度的单词有几个,比如,有以下单词序列:
"the","quick","red","fox","jumps","over","the","slow","red","turtle"其中单词长度大于等于5的单词有三个,分别是jumps、quick、turtle
问题分析
首先我们需要明确的是,由于单词序列中包含重复的单词,因此我们首先需要对单词序列进行去重,其次,我们可以将单词按照其长度大小按照从小到大进行排序,此后找到第一个大于等于给定长度的单词,那么后边的单词都满足条件,统计其个数即可,即
- 对单词序列进行去重
- 按照单词的长度进行从小到大进行排序
- 对排序后的单词序列进行遍历,找到第一个大于等于给定长度的单词,此后的单词就都满足条件,统计个数
问题解决
为了方便观察输出结果,我们首先重载输出运算符
ostream& operator<<(ostream& os, vector words)
{
for (string word : words)
os << word << " ";
return os;
} 上述代码中使用到了范围for循环语句,详情请移步
c++范围for语句-CSDN博客
输入数据
vector words = { "the","quick","red","fox","jumps","over","the","slow","red","turtle" };
数据去重
- 按照单词的字典序进行排序,这样相同的单词必然会紧邻
- 对排序后的单词使用泛型算法unique进行去重
void elimDups(vector& words)
{
sort(words.begin(), words.end());//按照字典序进行排序
//unique算法将重排输入序列,将相邻的重复项进行“消除”,并返回一个指向不重复值范围末尾的迭代器
auto end_unique = unique(words.begin(), words.end());
//unique去重后,vector中对多出来删除的空余位置,删除unique后的空余位置
words.erase(end_unique, words.end());
}
输入数据并去重
vector words = { "the","quick","red","fox","jumps","over","the","slow","red","turtle" };
cout << words << endl;
elimDups(words);
cout << words << endl;

按照单词长度进行排序
sort(words.begin(), words.end(), [](string w1,string w2) {
return w1.size() < w2.size();
});
上述代码中,我们使用sort函数对去重后的单词序列进行排序,排序规则是单词的长度,并且按照从小到大进行排序,在sort函数的第三个参数中使用lambda表达式定义排序规则,上述代码等价于:
bool compare(const string& s1, const string& s2)
{
return s1.size() < s2.size();
}
void sol()
{
sort(words.begin(), words.end(), compare);
}
可以看到,我们用lambda表达式代替了compare函数,也就是说
- lambda表达式可以直接在需要调用函数的位置定义短小精悍的函数,而不需要预先定义好函数
找到满足条件的单词位置
对单词序列按照长度进行排序后,我们只需要找到单词长度大于等于给定长度的单词位置即可,我们使用find_if函数来查找第一个具有特定大小的元素,如下:
vector::size_type sz = 5;
auto wc = find_if(words.begin(), words.end(),
[sz](string word) {
return word.size() >= sz;
});
decltype(sz) count = words.end() - wc;
cout << count << endl; 上述代码中,我们同样使用lambda表达式作为find_if函数的查找规则,其中捕获列表中的参数sz是为我们在函数中定义的给定长度,至此案例开头给出的问题就解决了,下边是完整代码,详细解释可见《c++ primer》第五版P343~P349
#include
#include
#include
#include
using namespace std;
#if 1
ostream& operator<<(ostream& os, vector words)
{
for (string word : words)
os << word << " ";
return os;
}
void elimDups(vector& words)
{
sort(words.begin(), words.end());//按照字典序进行排序
//unique算法将重排输入序列,将相邻的重复项进行“消除”,并返回一个指向不重复值范围末尾的迭代器
auto end_unique = unique(words.begin(), words.end());
//unique去重后,vector中对多出来删除的空余位置,删除unique后的空余位置
words.erase(end_unique, words.end());
}
void sol()
{
vector words = { "the","quick","red","fox","jumps","over","the","slow","red","turtle" };
cout << words << endl;
elimDups(words);
cout << words << endl;
sort(words.begin(), words.end(), [](string w1,string w2) {
return w1.size() < w2.size();
});
cout << words << endl;
vector::size_type sz = 5;
auto wc = find_if(words.begin(), words.end(),
[sz](string word) {
return word.size() >= sz;
});
decltype(sz) count = words.end() - wc;
cout << count << endl;
}
int main()
{
sol();
return 0;
}
#endif
lambda表达式语法结构详解
通过以上案例我们已经知道了lambda表达式的使用场景,接下来我们详细说明lambda表达式语法结构中各参数的使用
捕获列表
类似于参数传递,捕获列表在捕获函数中的局部变量时,也可分为值捕获与引用捕获;其中采用值捕获的前提是变量可以被拷贝,但与普通函数的参数值传递不同,被捕获的变量的值是在lambdb创建时拷贝,而不是调用时拷贝。
值捕获
void sol() {
int a = 41;
auto f1 = [a]() {return a; };
a=0;//修改啊的值
cout << f1() << endl;//41
}
上述代码中,我们使用值捕获来捕获sol函数中的局部变量a,之后改变a的值再次输出,发现lambda表达式中的值仍旧是改变前的值,说明此时被捕获的变量a是在lambda创建时拷贝过去的,因此后续a的改变将不影响lambda内的值
引用捕获
void sol() {
int a = 41;
auto f1 = [&a]() {return a; };
a=0;
cout << f1() << endl;//0
}
与上述实验不同,我们使用引用捕获方式捕获局部变量a,此时在改变a的值后,lambda表达式输出的是改变后的值,因为使用的是引用捕获,因此lambda内所捕获的变量a与sol函数的a使用的是同一份内存,故对局部变量a的改变也会影响到lambda表达式中a的值
隐式捕获
上述捕获都属于显示捕获,也就是说我们想在lambda中使用哪个局部变量就在捕获列表中填入哪个,但有时我们希望使用sol函数中所有的局部变量时,一个一个填入捕获列表显然就会很麻烦,因此使用隐式捕获,就表示我们在lambda表达式中可以使用所在普通函数中所有局部变量。
同显示捕获一样,隐式捕获也分为值捕获与引用捕获
值传递隐式捕获
void sol() {
int a = 3,b=4;
auto f = [=]() {return a + b; };
cout << f() << endl;
}上述代码的lambda表达式中的捕获列表=表示,该lambda表达式可以使用sol函数的全部的局部变量,且使用方式为值捕获
引用传递隐式捕获
同样的道理,下述lambda表达式可以使用sol函数的全部的局部变量,且使用方式为引用捕获
void sol() {
int a = 3,b=4;
auto f = [&]() {return a + b; };
cout << f() << endl;
}
混合捕获
[=, &a, &b]表示以引用传递的方式捕捉变量a和b,以值传递方式捕捉其它所有变量。
int index = 1;
int num = 100;
auto function = ([=, &index, &num]{
num = 1000;
index = 2;
std::cout << "index: "<< index << ", "
<< "num: "<< num << std::endl;
}
);
function();
可变规则mutable
默认情况下,对于值捕获方式捕获到的变量,lambda在内部不能改变其值,如果想改变就需要使用mutable关键字。
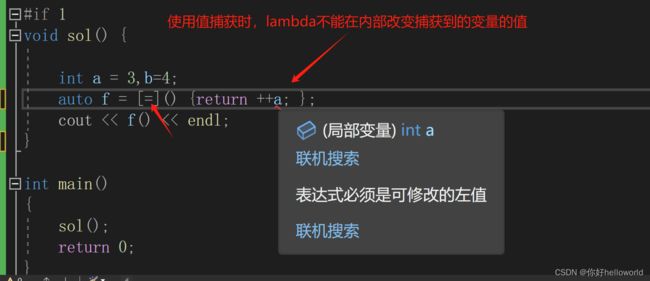
如上述代码的那样报错,如果想在lambda内部改变值捕获到的变量,需要加入mutable关键字,如下所示:
void sol() {
int a = 3,b=4;
auto f = [=]() mutable{return ++a; };
cout << f() << endl;
}
对于引用捕获获取到的变量,lambda在内部是否可以改变,取决于该局部变量是否是const的,如:

返回类型
Lambda表达式的返回类型会自动推导,但仅限于其函数体内只有一个return语句,否则当lambda函数体中包含了return之外的任何语句,编译器都会假定此lambda返回的是void类型。除非你指定了返回类型,否则不必使用关键字。
void sol() {
vector v = { -1,2,-3,4 };
vector result;
//lambda函数体中只有一个return语句,将自动推断返回类型为int
transform(v.begin(), v.end(), back_inserter(result),
[](int i) {return i < 0 ? -i : i; });
//使用for_each打印vector
for_each(v.begin(), v.end(), [](int x) {
cout << x << " ";
});
cout << endl;
for_each(result.begin(), result.end(), [](int x) {
cout << x << " ";
});
}

上述代码使用泛型算法transform将v中的数据变为其绝对值,并将转换后的结果存放到result中,其中back_insert是一个插入迭代器(效果等同于push_back),整个transform语句表示遍历vector的每个元素v,判断其是否小于0,如果是就返回其相反数,并将结果push_back到result中
此外代码中还使用了for_each泛型算法遍历vector,在此我们再次看到了在泛型算法中使用lambda表达式的优势所在
但是,如果我们将上述代码改为如下代码,则编译器将会报错:
transform(v.begin(), v.end(), back_inserter(result),
[](int i)
{
if (i < 0) return -i;
else return i;
});因为这段代码中的lambda函数体有两个return语句,编译器将返回void类型,但笔者在vs上进行实验时,发现并没有报错,后查阅资料发现是c++进行了隐式类型转换?
但还是建议使用显示说明的返回类型
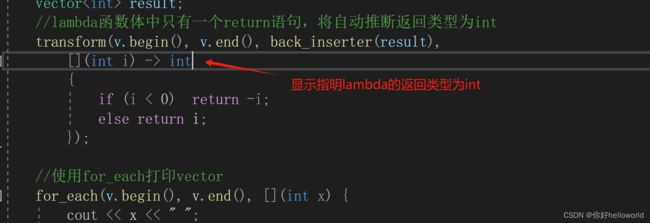
lambda表达式工作原理
编译器会把一个Lambda表达式生成一个匿名类的匿名对象,并在类中重载函数调用运算符,实现了一个
operator()方法。
如下所示:
auto print = []{cout << "Hello World!" << endl; };
编译器会把上面这一句翻译为下面的代码:
class print_class
{
public:
void operator()(void) const
{
cout << "Hello World!" << endl;
}
};
// 用构造的类创建对象,print此时就是一个函数对象
auto print = print_class();
参考:
《c++ primer》
【精选】C++ Lambda表达式详解-CSDN博客