SpringCloud——分布式搜索之初识elasticsearch
分布式搜索(elasticsearch)
目录
- 分布式搜索(elasticsearch)
-
- 一、初识elasticsearch
-
- 1、了解ES
- 2、倒排索引
- 3、ES的一些概念
- 4、安装ES、kibana
- 5、安装IK分词器
一、初识elasticsearch
1、了解ES
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。

 总结:
总结:

2、倒排索引
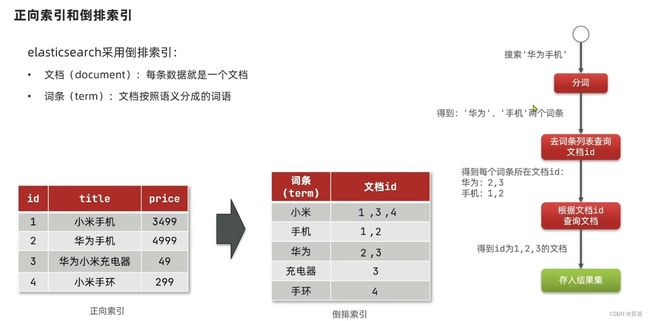
正向索引(正排索引):正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
反向索引(倒排索引):倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
图释:

3、ES的一些概念
上面我们已经说过了一些ES的概念:文档、词条。
文档:每条数据就是一个文档,elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息文档数据会被序列化为json格式后存储在elasticsearch中。
 索引:相同类型的文档的集合。
索引:相同类型的文档的集合。
映射:索引文档中的字段约束信息,类似于表的结构约束。

词条: 文档按照语义分成的词语,对文档中的数据进行分词,得到的就是词条。
ES和MySql的概念对比:
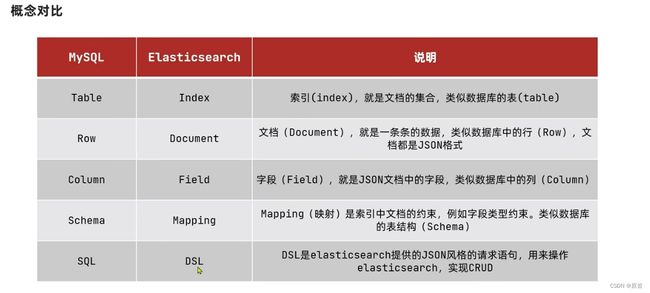 总结:
总结:

4、安装ES、kibana
kibana是什么?:
Kibana 是一个用于 Elasticsearch 的开源数据可视化和分析平台。它提供了一个直观的 Web 用户界面,让用户能够以交互方式浏览、搜索、分析和可视化存储在 Elasticsearch 中的数据。
Kibana 具有丰富的功能,包括实时数据仪表盘、图表和可视化工具、数据检索和过滤、基于时间的数据导航、警报和通知等。它提供了强大的查询和聚合功能,使用户能够从 Elasticsearch 中提取有关数据的洞察力,并以直观和可视化的方式呈现。
通过 Kibana,用户可以轻松创建仪表盘、图表和报告,从而更好地理解和探索存储在 Elasticsearch 中的数据。Kibana 还与其他工具和插件集成,以提供更广泛的数据分析和可视化能力。
总之,我们要操作ES需要使用kibana。接下来我们开始操作安装ES并试着操作。
首先我们要确保自己已经启动了Docker服务:
systemctl start docker
查看Docker的运行状态:
service docker status

1、创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
2、导入ES、kibana并创建容器运行
![]() 采用elasticsearch的7.12.1版本的镜像,将es.tar文件上传到虚拟机上然后运行加载命令即可
采用elasticsearch的7.12.1版本的镜像,将es.tar文件上传到虚拟机上然后运行加载命令即可
#导入es
docker load -i es.tar
docker load -i kibana.tar
docker run -d \ #运行一个新的容器,-d(detached mode)分离模式,后台运行
--name es \ #容器名称为es
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ #设置ES的java虚拟机内存选项,限制堆内存512MB
-e "discovery.type=single-node" \ #设置ES以单节点模式运行,不参与集群发现
-v es-data:/usr/share/elasticsearch/data \ #将一个名为 "es-data" 的 Docker 卷挂载到 Elasticsearch 容器中的 /usr/share/elasticsearch/data 目录,用于持久化存储 Elasticsearch 的数据。
-v es-plugins:/usr/share/elasticsearch/plugins \ #将一个名为 "es-plugins" 的 Docker 卷挂载到 Elasticsearch 容器中的 /usr/share/elasticsearch/plugins 目录,用于存储 Elasticsearch 插件。
--privileged \ #在容器内部开启特权模式,允许访问所有设备。
--network es-net \ #将容器连接到名为 "es-net" 的 Docker 网络,以便容器可以与其他容器进行通信。
-p 9200:9200 \ #将容器的 9200 端口映射到主机的 9200 端口,允许通过主机访问 Elasticsearch 的 REST API。
-p 9300:9300 \ #将容器的 9300 端口映射到主机的 9300 端口,允许通过主机访问 Elasticsearch 的集群通信端口。
elasticsearch:7.12.1 #指定要运行的容器镜像,此处为 Elasticsearch 的版本 7.12.1
当我们运行该命令时候,Docker 将创建并运行一个名为 “es” 的 Elasticsearch 容器,根据指定的配置进行设置,包括内存大小、数据挂载、网络设置和端口映射。
 现在我们可以试着访问es,可以看到一些es的信息
现在我们可以试着访问es,可以看到一些es的信息
 但是我们需要进行可视化操作,所以我们需要再运行一个Kibana:
但是我们需要进行可视化操作,所以我们需要再运行一个Kibana:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1

创建之后我们就可以访问了(虚拟机ip+kibana容器暴露的端口):
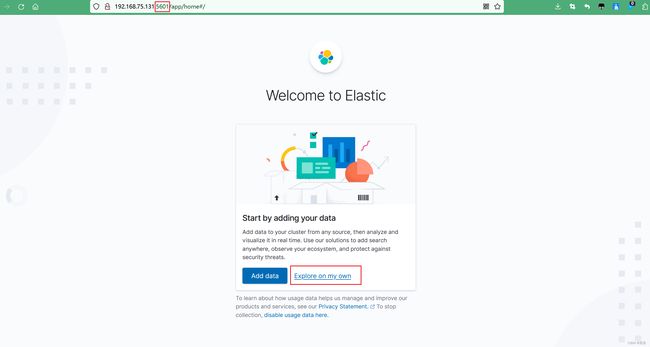 当我们关闭虚拟机后下次在想访问时候再次启动容器就行,网络会在虚拟机启动之后默认启动:
当我们关闭虚拟机后下次在想访问时候再次启动容器就行,网络会在虚拟机启动之后默认启动:
docker pa -a
docker restart 容器id
![]()
5、安装IK分词器
我们试着进行一些分词操作,在Kibana中的Dev Tools中:
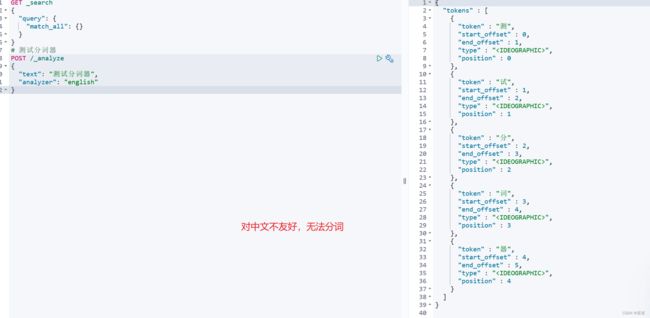 我们对上面的语句进行一下简单的解释:
我们对上面的语句进行一下简单的解释:
POST /_analyze:这是 Analyze API 的端点,用于执行文本分析操作。
“text”: “测试分词器”:这是要进行分析的文本。在这个例子中,我们将分析文本 “测试分词器”。
“analyzer”: “english”:这是指定要使用的分词器。在这个例子中,我们选择了英文分词器。
可以看见分词效果并不好,我们的汉字被分成一个一个字了,但是我们想要的效果是:测试、分词器 这种效果,推荐使用IK分词器
简介:IK 分词器是一个常用的中文分词工具,它是基于 Java 开发的开源项目。IK 分词器可以将中文文本切分成一个个独立的词语,方便后续的文本处理和分析。
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好,所以我们需要使用IK分词器。
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins #获取有关指定卷(volume)的详细信息
es-plugins是我们刚才创建的容器时候指定的卷名,经过查看我们发现:

挂载点是 /var/lib/docker/volumes/es-plugins/_data,该路径存储了卷 “es-plugins” 的实际数据。我们可以在该路径下查看和操作与该卷相关的文件和目录。
将ik分词器上传到文件夹
 我们再重启一下容器:
我们再重启一下容器:
docker restart es
#查看日志
docker logs -f es

IK 分词器支持两种分词模式:细粒度分词和智能分词。细粒度分词模式会将文本切分成更细小的词语,适用于需要更详细的分词结果的场景。智能分词模式则会在保留重要词语的同时进行合理的切分,适用于一般的文本分析任务。
ik_smart:智能分词
ik_max_word:细粒度分词
现在我们可以在kibana中使用Dev Tools来进行一些操作:
在kibana中找到Dev Tools 智能分词测试(ik_smart):
智能分词测试(ik_smart):
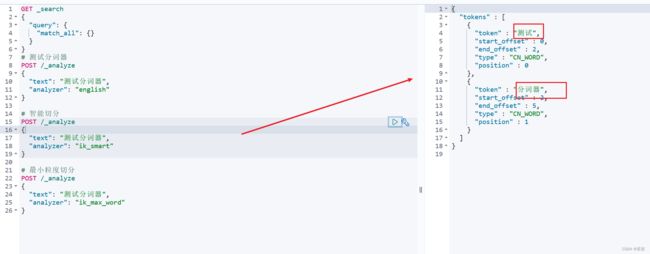
细粒度分词测试(ik_max_word):
 但是有时候会出现无法分词的场景:
但是有时候会出现无法分词的场景:
 所以这里就需要我们使用ik分词器支持添加自己的词库,也可以停用字典
所以这里就需要我们使用ik分词器支持添加自己的词库,也可以停用字典
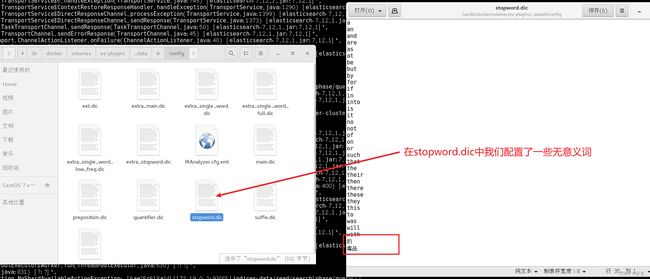
在 IK 分词器中停用字典(stopwords)是一种用于过滤文本中常见词汇的机制。停用字典包含一组常见词汇,这些词汇在分词过程中会被忽略,不作为独立的词项进行索引。
拓展字典:
我们需要新建ext.dic
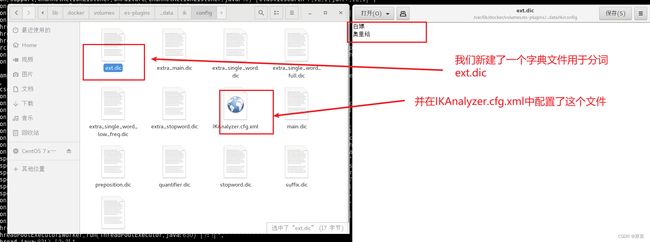
我们只需要找到配置文件,这里我们拓展一个名为ext.dic的字典:
同时我们也配置一些停用字典:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.tic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
配置完成之后别忘了重启容器:
docker restart es
测试


总结:
ik分词器的作用是什么?ik分词器有几种模式?ik分词器如何扩展词条和停用词条?
IK 分词器是一种常用的中文分词器,主要用于将中文文本切分成单个词语或词汇单元,以便进行文本处理、分析和搜索。
IK 分词器具有以下几种常用的分词模式:
细粒度切分模式(ik_smart):在这个模式下,IK 分词器会尽可能地将文本切分成较短的词语,对于长词可能进行细粒度的切分。
智能切分模式(ik_max_word):在这个模式下,IK 分词器会尽可能地将文本切分成较长的词语,对于一些具有歧义的词汇会进行智能判断,以得到更准确的切分结果。
在 IK 分词器中,可以通过扩展词典和停用词典来自定义词条的添加和停用,利用config目录的lkAnalyzer.cfg.xml文件添加拓展词典和停用词典
扩展词典(ext_dict):可以将需要扩展的词语添加到扩展词典中,以确保它们被正确切分。您可以在扩展词典中添加自定义的词语,以适应特定的文本处理需求。
停用词典(ext_stopwords):可以将不需要进行切分的常用词汇添加到停用词典中,以避免对这些词汇进行切分。停用词通常是一些常见的无实际意义的词汇,例如“的”、“是”、“在”等。添加停用词可以减少不必要的切分结果。
通过编辑 IK 分词器的配置文件,可以指定扩展词典和停用词典的路径,使分词器在切分过程中使用这些自定义的词条信息。