14.数据转换之高阶函数数据处理
- 在dataframe中使用apply方法,调用自定义函数对数据进行处理
- 函数apply,axis=0表示对行进行操作,axis=1表示对列进行操作
- 可以使用astype函数对数据进行转换
- 可以使用map函数进行数据转换
f1=lambda x:str(x).strip() and str(x).replace(',','')
farmer_loan['贷款余额']=farmer_loan['贷款余额'].apply(f1)
farmer_loan['贷款发放金额']=farmer_loan['贷款发送金额'].astype(float)
farmer_loan['ID']=farmer_loan['户主身份证号'].apply(lambda x:x[0:3])axis=0是跨行,axis=1是跨列
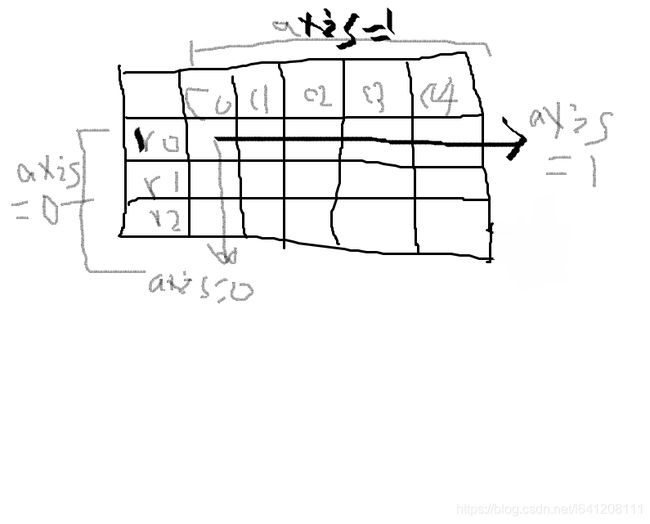
- axis=0:0值表示沿着行的方向或者行标签、索引值向下执行方法
- axis=1:1值表示沿着列的方向或列标签值执行对应的方法
可以看出当axis=0时,遍历的是每行,或者说保存列标签不变,对行进行操作
当axis=1时,遍历的是每列,所有当我们求每列的均值时,应该是遍历每行加总求均值。
df2=pd.read_csv('sam_tianchi_num_baby.csv',dtype=str,encoding='utf-8')
df2.head(10)
#存储函数,将数字转化为汉字
def f(x):
if '0' in str(x):
return '女'
elif '1' in str(x):
return '男'
else:
return '未知'
#结果放在新建'性别'列
df2['性别']=df2['gender'].apply(f)
df2[df2['gender']=='2']
df2.head(10)
del df2['性别']
#map函数,以字典形式传入
df2['性别']=df2['gender'].map({'0':'女','1':'男','2':'未知'})
df2.head(10)
#map函数映射,以自定义函数传入
df2['性别']=df2['gender'].map(f)
df2.head(10)
#拖尾处理,密码可以这样处理
df2['user_id'].apply(lambda x:sr(x).replace(x[1:3],'**'))
#apply应用更广泛,map应用于映射、字符串切片
df2['birthday'].apply(lambda x:x[0:4])#取第1到第五