PyTorch深度学习原理与实现
PyTorch深度学习原理与实现
1. 引言
深度学习发展历程
-
感知机网络(解决线性可分问题,20世纪40年代)
-
BP神经网络(解决线性不可分问题,20世纪80年代)
-
深度神经网络(海量图片分类,2010年左右)
常见深度神经网络:CNN、RNN、LSTM、GRU、GAN、DBN、RBM ……
深度应用领域
-
计算机视觉
-
语音识别
-
自然语言处理
-
人机博弈
深度学习、机器学习以及人工智能

深度学习VS传统机器学习


深度神经网络 VS 浅层神经网络
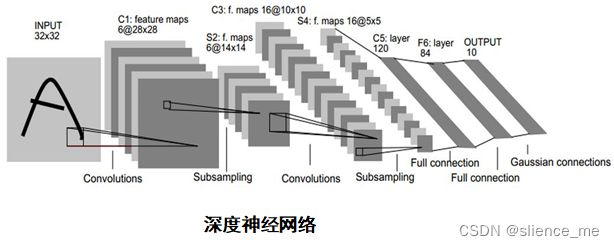
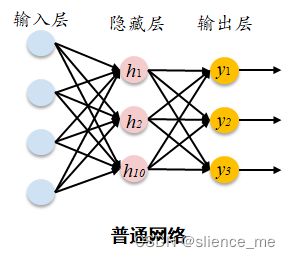
2. 卷积神经网络CNN
BP神经网络缺陷
-
不能移动
-
不能变形
-
运算量大
解决办法
-
大量物体位于不同位置的数据训练
-
增加网络的隐藏层个数。
-
权值共享(不同位置拥有相同权值)
卷积神经网络结构[深度学习(DEEP LEARNING)]
covolutional layer(卷积)、ReLu layer(非线性映射)、pooling layer(池化)、
fully connected layer(全连接)、output(输出)的组合,例如下图所示的结构。

全连接与局部连接(权值共享)
在CNN中,先选择一个局部区域(filter),用这个局部区域去扫描整张图片。 局部区域所圈起来的所有节点会被连接到下一层的一个节点上。
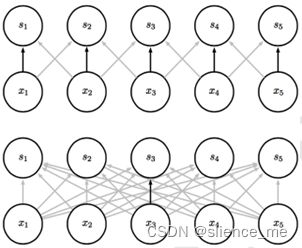
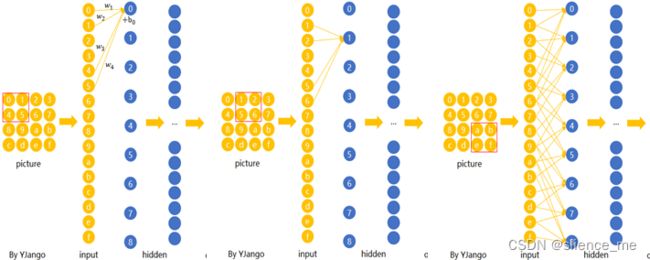
2.1 卷积层-权值共享
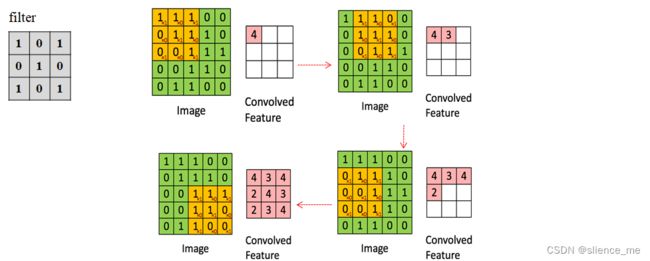

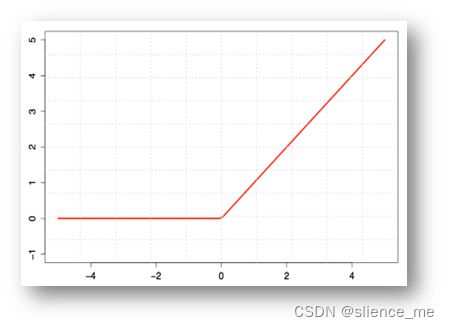
2.2 非线性映射ReLU
非线性映射(Rectified Linear Units)
和前馈神经网络一样,经过线性组合和偏移后,会加入非线性增强模型的拟合能力。
经过线性组合和偏移后,会加入非线性增强模型的拟合能力,将卷积所得的Feature Map经过ReLU变换。
下图函数解释:(小于零部分为零,大于零部分等于它本身)
2.3 池化(pooling)

import matplotlib.pyplot as plt
import torch
# 读取照片
image = plt.imread('_5_PyTorch深度学习/8.jpg')
# 将照片转为卷积层能接受的形式
image = image.reshape([-1, 1, 28, 28])
# 构建卷积层
# in_channels通道,当前灰度图片,通道为1; out_channels为过滤层filter的个数; kernel_size为过滤层纬度 5×5
conv2d = torch.nn.Conv2d(in_channels=1, out_channels=32, kernel_size=5)
# 执行卷积操作
result_conv = conv2d(torch.tensor(image, dtype=torch.float32))
# 卷积可视化
plt.figure(figsize=(10, 8)) # 创建一张画布
for i in range(20):
plt.subplot(4, 5, i+1)
plt.imshow(result_conv.data.numpy()[0, i, :, :], cmap='gray') # 绘制子图
plt.axis('off') # 关闭坐标轴
plt.show()
# 构建池化层
# kernel_size过滤层纬度 2×2 每次跳转间隔
max_pool2d = torch.nn.MaxPool2d(kernel_size=2, stride=2)
# 执行池化操作
result_pool = max_pool2d(result_conv)
# 池化可视化
plt.figure(figsize=(10, 8)) # 创建一张画布
for i in range(20):
plt.subplot(4, 5, i+1)
plt.imshow(result_pool.data.numpy()[0, i, :, :], cmap='gray') # 绘制子图
plt.axis('off') # 关闭坐标轴
plt.show()
原图:

第一次卷积结果:

第一次池化结果:

2.4 全连接层
卷积–>池化–>卷积–>池化–>全连接–>全连接–>高斯连接
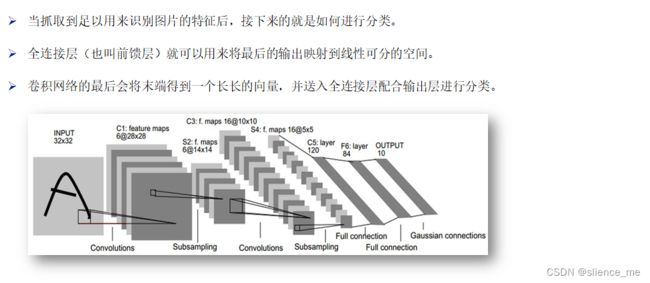
输入 32×32
-> 通过6个不同的filter(5×5)卷积后 -> 6@28×28
-> 池化后 -> 6@14×14
-> 通过16个不同的filter(5×5)卷积后 -> 16@10×10
-> 池化后 -> 6@5×5
-> 全连接
3. 循环神经网络RNN
传统神经网络结构

-
对一般的神经网络,无论是arrive Beijing还是leave Beijing,Beijing作为BP神经网络的输入时,输出的都是Destination
-
Input 一样的内容,Output就是一样的内容
-
**我们希望神经网络有记忆,记得 ** Beijing 前的 arrive 或者 leave
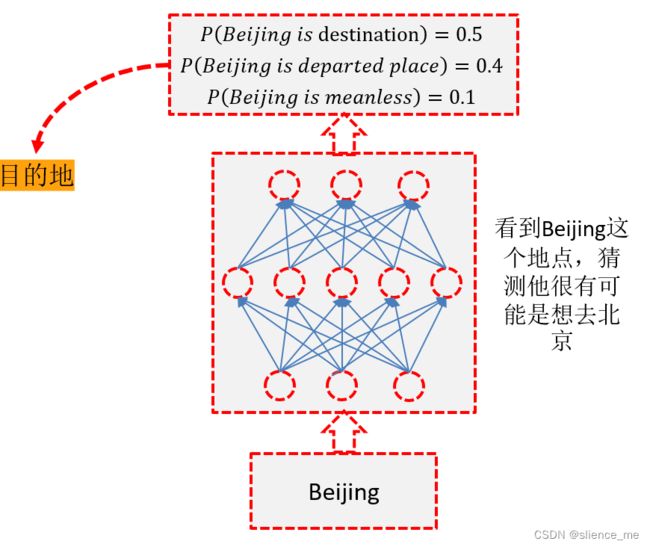



3.1 隐状态(Hidden State)h

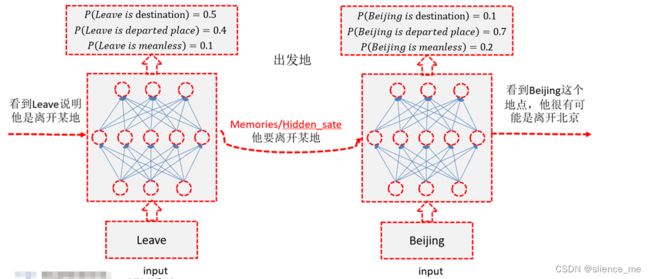
3.2 输出状态

3.3 随时间反向传播(BPTT)算法




3.4 N VS 1 RNN结构
n个输入一个输出

3.5 1 VS N RNN结构
1个输入n个输出

3.6 N vs M
n个输入m个输出

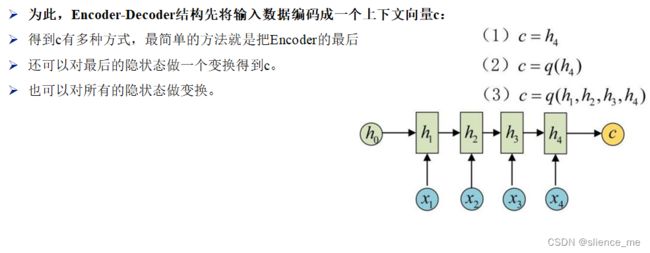


4. 长短时记忆网络LSTM
在 RNN 中,因为通常前期的层会因为梯度消失而停止学习,RNN 会忘记它在更长的序列中看到的东西,从而只拥有短期记忆。

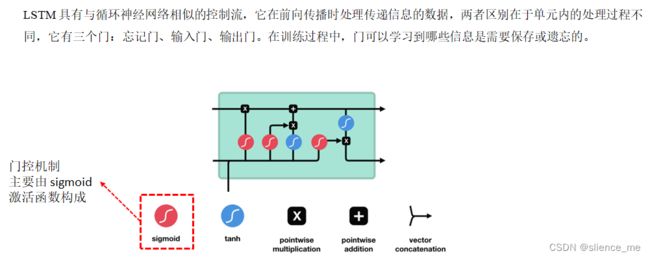
4.1 遗忘门(forget gate)遗忘或保存

4.2 输入门(input gate)更新单元状态
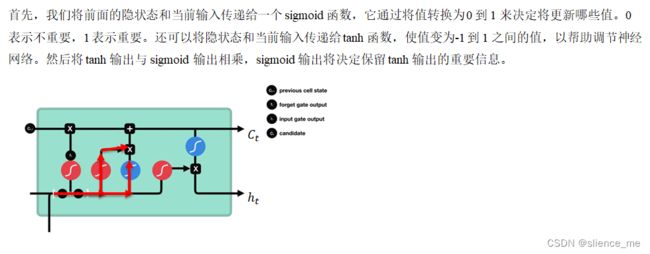
4.3 单元状态

4.4 输出门(output gate)
决定下一个隐藏状态
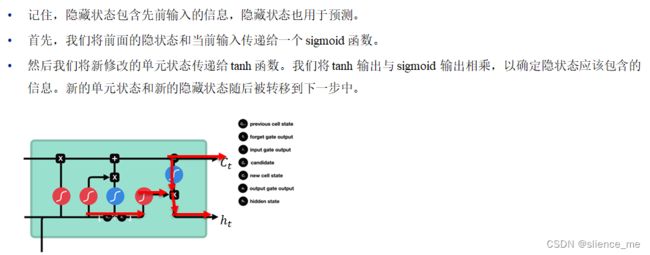
4.5 示例




5. 利用RNN&LSTM实现手写数字识别
任务实现
-
加载数据
-
数据加工
-
构建模型(搭建网络)
-
模型配置
-
模型训练
-
性能验证

import matplotlib.pyplot as plt
import torch
# 读取照片
image = plt.imread('_5_PyTorch深度学习/8.jpg')
# 将照片转为卷积层能接受的形式
image = image.reshape([-1, 28, 28])
# 构建LSTM
# 一个序列放进去,序列中一个向量中元素的个数 ,input_size输入数据的个数
# hidden_size 设置神经元个数
# batch_first 样本个数在第一位
rnn = torch.nn.LSTM(input_size=28, hidden_size=100, batch_first=True)
# 执行LSTM
output, (_, _) = rnn(torch.tensor(image, dtype=torch.float32))
plt.imshow(output.data.numpy()[0].T, cmap='gray')
plt.show()


import numpy as np
import torch
# 1. 加载数据
mnist = np.load('_5_PyTorch深度学习/mnist.npz', allow_pickle=True) # 读取数据
mnist.files
X_train, y_train, X_test, y_test = mnist['x_train'], mnist['y_train'], mnist['x_test'], mnist['y_test']
# 2. 数据加工
X_train_tensor = torch.tensor(X_train/255, dtype=torch.float32) # 将训练集样本自变量转为tensor
X_test_tensor = torch.tensor(X_test/255, dtype=torch.float32) # 将测试集样本自变量转为tensor
y_train_tensor = torch.tensor(y_train, dtype=torch.int64) # 将训练集样本标签转为tensor
train_ds = torch.utils.data.TensorDataset(X_train_tensor, y_train_tensor) # 将训练数据转为tensordata格式
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=32, shuffle=True) # 执行打乱和分批操作
class Rnn(torch.nn.Module):
def __init__(self):
super(Rnn, self).__init__()
self.lstm = torch.nn.LSTM(input_size=28, hidden_size=100, batch_first=True) # 定义LSTM层
self.fc = torch.nn.Linear(in_features=100, out_features=10) # 全连接(隐藏层)
def forward(self, x):
x, (_, _) = self.lstm(x) # 执行LSTM操作
x = self.fc(x[:, -1, :]) # 获取最后一个第28个(即-1)
return x
# 3. 构建模型(搭建网络)
network = Rnn() # 实例化得到一个网络模型
# 4. 模型配置
loss_fn = torch.nn.CrossEntropyLoss() # 定义交叉商损失函数
optimizer = torch.optim.SGD(network.parameters(), lr=0.01) # 定义优化器 learning rate学习率
# 5. 模型训练与保存
for epoch in range(20):
for image, label in train_dl:
y_pre = network(image) # 前向传播
loss = loss_fn(y_pre, label) # 计算模型损失
network.zero_grad() # 将网络中所有参数的梯度进行清零
loss.backward() # 计算梯度
optimizer.step() # 对网络参数(参数和阈值)进行优化
print(f'第{epoch}轮训练的最后一批样本的训练损失值为: {loss.item()}')
# 6. 性能验证
predicted = network(X_test_tensor) # 调用已训练好的模型对测试样本进行预测
result = predicted.data.numpy().argmax(axis=1) # 模型对测试样本的预测标签
acc_test = (y_test == result).mean() # 测试精度
torch.save(network.state_dict(), 'mnist_2.pt') # 保存已经训练好的模型(参数) 权值阈值
# 对网络参数(参数和阈值)进行优化
print(f'第{epoch}轮训练的最后一批样本的训练损失值为: {loss.item()}')
# 6. 性能验证
predicted = network(X_test_tensor) # 调用已训练好的模型对测试样本进行预测
result = predicted.data.numpy().argmax(axis=1) # 模型对测试样本的预测标签
acc_test = (y_test == result).mean() # 测试精度
torch.save(network.state_dict(), 'mnist_2.pt') # 保存已经训练好的模型(参数) 权值阈值