《Deep learning for time series classification a review》笔记
《Deep learning for time series classification: a review》
1. 摘要
时间序列分类(TSC)是数据挖掘中一个重要且具有挑战性的问题。随着时间序列数据可用性的增加,已经提出了数百种TSC算法。在这些方法中,只有少数人考虑过深度神经网络(DNN)来执行这项任务。在本文中,我们简介TSC最新DNN架构,研究了TSC深度学习算法的当前最新性能。在此概述了在统一的TSN分类标准下,TSC中各个时间序列域中最成功的深度学习应用程序。
2. 时间序列分类
在介绍不同类型的神经网络架构之前,我们先介绍一下TSC的正式定义。

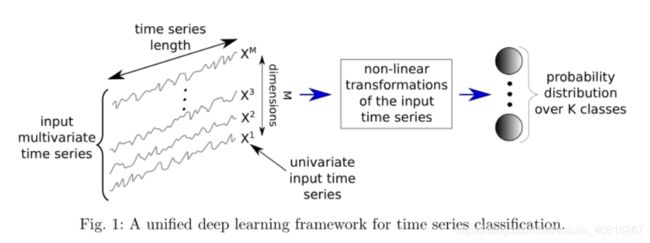
3. 基于深度学习的时间序列分类
In this review we focus on three main DNN architectures used for the TSC task: Multi Layer Perceptron (MLP), Convolutional Neural Network(CNN) and Echo State Network (ESN).
3.1 Multi Layer Perceptrons (多层感知器)
One impediment from adopting MLPs for time series data is that they do not exhibit any spatial invariance . In other words, each time stamp has its own weight and the temporal information is lost: meaning time series elements are treated independently from each other .
3.2 Convolutional Neural Networks (CNN)
在TSC问题中,卷积可以被视为在时间序列上应用和滑动滤波器。 与图像不同的是,滤波器仅显示一个维度(时间)而不是两个维度(宽度和高度)the filters exhibit only one dimension (time) instead of two dimensions (width and height)。 举个例子:如果我们将长度为3的滤波器与单变量时间序列进行卷积(相乘),则将滤波器值设置为等于[1/3,1/3,1/3],卷积将导致应用具有长度为3的滑动窗口的移动平均值。一般形式:
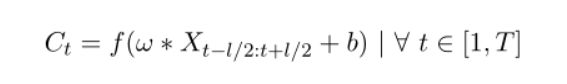
下面这段话很重要:
其中C表示的是长度为T的单变量时间序列X和长度为l的滤波器ω上应用的卷积(点积), 然后添加偏置b,最后输入到非线性激活函数例如整流线性单元(ReLU)中的结果。 一个时间序列X上的卷积(一个滤波器)的结果可以被认为是经历滤波处理的另一个单变量时间序列C. 因此,在时间序列上应用多个滤波器将产生多变量时间序列,其维度等于所使用的滤波器的数量。 在输入时间序列上应用多个过滤器的方法可以学习多个判别特征,这对分类任务有很大帮助。
上面是单变量时间序列,那么对于MTS( M-dimensional ,多变量时间序列)呢?当考虑将MTS作为卷积层的输入时,滤波器不再具有一个维度(time),而且具有等于输入MTS的维度数量的维度。
在这里,pooling(max or average)的作用:采用输入时间序列并通过在其滑动窗口上聚合来减小其长度T. 值得注意的是,当池化的stride等于滑动窗口的size时,T的length会减小为T/size。

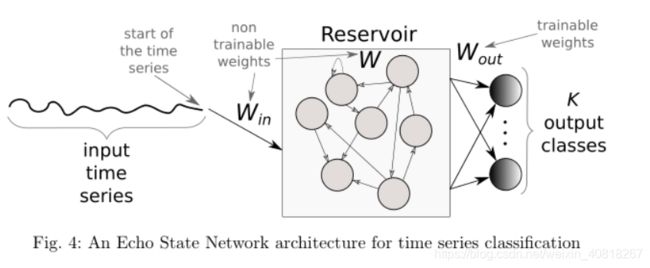
3.3 Echo State Networks(回声状态网络)
在这里,作者提到了Recurrent Neural Network(RNN),但他们发现:除了时间序列预测外,我们发现这些神经网络很少用于时间序列分类。 原因主要有三个方面:
(1) the type of this architecture is designed mainly to predict an output for each element (time stamp) in the time series 被主要设计来预测每个时间stamp处的值
(2)RNNs typically suffer from the vanishing gradient problem due to training on long
time series 由于时间序列过长导致梯度消失问题
(3) RNNs are considered hard to train and parallelize which led the researchers to avoid using them for computational reasons 计算原因
基于以上原因或者说限制, Echo State Networks (ESNs) 出现了:a relatively recent type of recurrent architecture proposed for time series。ESNs 由 Jaeger和Haas 于2004年发明,最早用于 time series prediction in wireless communication channels。
具体网络结构参考链接: https://blog.csdn.net/minemine999/article/details/80861863
4.生成模型和判别模型
TSC的深度学习方法可以分为两大类:生成模型和判别模型。
4.1 生成模型
-
深度信念网络(DBNs)被用于以无监督的方式对潜在特征进行建模,然后利用这些特征对单变量和多变量时间序列进行分类:
http://downloads.hindawi.com/journals/mpe/2017/9549323.pdf -
Ma等人(2016)使用自我预测建模进行时间序列分类,其中ESN首先用于重建时间序列,然后利用储层空间中的学习表示进行分类:
https://www.sciencedirect.com/science/article/pii/S0020025516306661 -
有关TSC的生成性ESN模型的更多细节,我们将感兴趣的读者引到最近的一项实证研究,该研究比较了多变量和单变量时间序列的储层和模型空间的分类:
https://link.springer.com/chapter/10.1007%2F978-3-319-46182-3_17
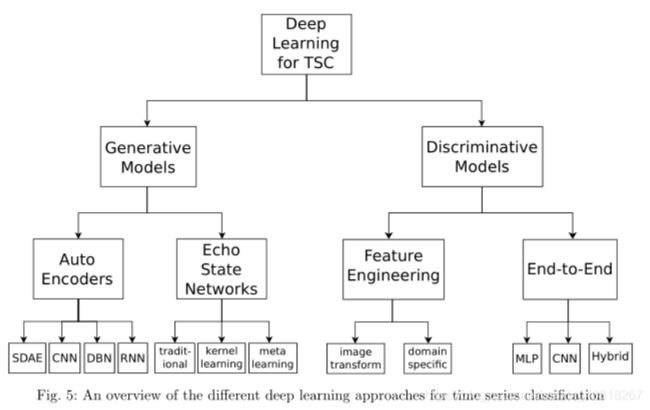
4.2 判别模型
已经提出了几种判别式深度学习架构来解决TSC任务,但是这种类型的模型可以进一步细分为两组:(1)具有手工设计特征的深度学习模型;(2)端到端的深度学习模型。
(1)手工工程方法中最常遇到的和计算机视觉启发的特征提取方法是,使用特定方法将时间序列转换为图像,如 Gramian fields 、 recurrence plots、 Markov transition fields等。
These features are first hand-engineered using some domain knowledge(需要领域知识), then fed to a deep learning discriminative classifier. 举例来说,(Uemura等2018)从放置在外科医生手上的传感器数据中提取若干特征(例如速度),以便确定手术训练期间的技能水平。
(2)与特征工程相比,端到端的深度学习方法旨在在fine-tuning 分类器的过程中incorporate the feature learning process。在作者的研究过程中,发现CNN是TSC问题应用最广泛的架构,作者给出的解释是:这可能是由于它们的稳健性和与复杂架构(如RNN或MLP)相比相对较少的训练时间( due to their robustness and the relatively small amount of training time)。下面这一段基本都是CNN的案例。

此外,还有一些CNN的混合结构:
如,CNN+GRU:https://ieeexplore.ieee.org/document/8169670
The proposed model contains a convolutional network component to extract high-level features and a recurrent network component to enhance the modeling of the temporal characteristics of TS data.
CNN+Attention:https://arxiv.org/pdf/1805.03908.pdf
The encoder is formed of a convolutional neural network whose temporal output is summarized by a convolutional attention mechanism
5 Approaches
本节详细描述了九种不同的深度学习架构及其相应的优点和缺点。
为什么选择判别式端到端方法来进行对比呢?

关于九种方法的选择:
没有选择尝试解决TSC问题的子任务的方法,例如在Geng和Luo(2018)中,其中CNN被修改以对不平衡的时间序列数据集进行分类。为了证明这一选择,我们强调不平衡的TSC问题可以通过数据增强和修改类权重等几种技术来解决。
另外,一个子任务是:early time series classification 可见:http://ceur-ws.org/Vol-1793/paper4.pdf
九种方法:
(多层感知器MLP、完全卷积神经网络FCN、残差网络ResNet、编码器Encoder、多尺度卷积神经网络MCNN、t-LeNet、多通道深度卷积神经网络MCDCNN、时间卷积神经网络Time-CNN、时不变回波状态网络TWIESN)
1. MLP
2. Fully Convolutional Neural Network
FCNs 的特点:
- 没有 local pooling layers 局部池化层,这意味着在整个卷积中时间序列的长度保持不变;
- 传统CNN中最后的FC层被一个 Global Average Pooling (GAP) layer 代替,这大大减少了神经网络中的参数数量。
- 所有conv 操作的stride=1、 zero padding
3. Residual Network
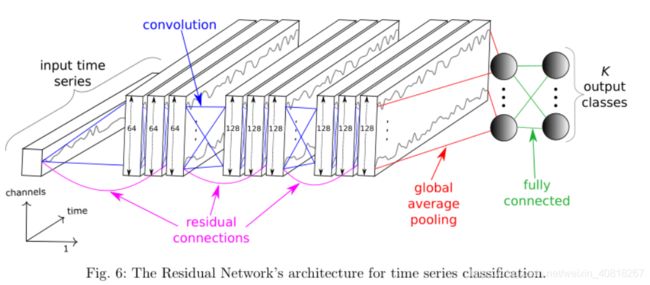

关于上述三种网络可见:
https://www.researchgate.net/publication/310611022_Time_Series_Classification_from_Scratch_with_Deep_Neural_Networks_A_Strong_Baseline
4 Encoder
5 Multi-scale Convolutional Neural Network
多尺度卷积神经网络
-
与传统的CNN网络结构相似
-
非常复杂,因为其 heavy data pre-processing step
Windows Slicing(WS)作为一种 data augmentation的方法:从输入时间序列中抽取subsequences,然后用这些子序列训练网络。在训练之前,子序列还要进行三步处理:(1) identity mapping;(2) down-sampling;(3)smoothing;现在子序列由 univariate 变为 multivariate
6 Time Le-Net
和MCNN一样,也 extracting subsequences to augment the training data。
6 实验数据集
6.1 Univariate archive
http://www.timeseriesclassification.com/index.php
6.2 Multivariate archive

7 实验
97个数据集(85Univariate +12Multivariate )
9种deep learning models (每种model跑10次然后取平均accuracy, 为了reduce the bias due to the weights’ initial values)
a cluster of 60 GPUs, sequential running(单GPU运行)是将近100天,60GPUs集群使得时间降到了一个月以内。
使用 Keras with the Tensorflow back-end
使用 mean accuracy measure averaged over the 10 runs on the test set
8 结果
8.1 Results for univariate time series
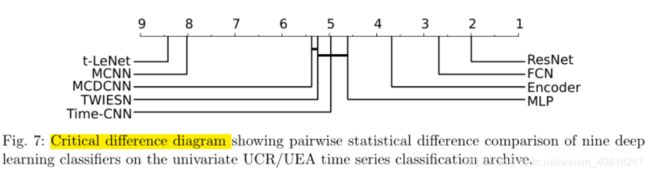
1. ResNet网络的优越性(the most accurate DNN of our study):
The ResNet significantly outperforms the other approaches with an average rank of almost 2. ResNet wins on 50 problems out of 85 and significantly outperforms the FCN architecture.
作者给出的解释:
deeper neural networks are much more successful than shallower architectures ( 何凯明大神., 2016 ) 从2012到2016年,4年时间,神经网络从7层 (AlexNet 2012)到了1000层( ResNet 2016),这种深度网络一般需要大量的数据来进行训练以达到很好的泛化效果。 尽管与数十亿标记图像(如ImageNet 和 OpenImages)相比,实验中使用的数据集相对较小,但最深的网络在UCR/UEA上仍然能达到很高的准确度。
deep CNNs在TSC task上的high accuracies:

2. MCNN 和 t-LeNet==(平均最差表现)==
共同点:都采用了提取子序列以增加训练数据的方法,因此,模型从较短的子序列而不是整个序列中学习。 这两种方法的平均最差表现表明,这种切片时间序列的特殊方法并不能保证时间序列中的判别信息不会丢失。(这种方法可能也是违反直觉的)。最近一些TSC算法的研究也表明,这种基于窗口切片(WS)的方法产生了最低的平均等级。
3. MCDCNN 和 Time-CNN( low performance)
首先,MCDCNN 和 Time-CNN 最早被提出来是用于MTS数据分类,但作者也在univariate UCR/UEA archive 上做了评估。GAP pooling的重要性:

4. Encoder ( relatively high accuracy)
FCN vs Encoder :superiority of the GAP layer compared to Encoder’s attention mechanism. 相比于Encoder的 attention,FCN的GAP更优越。

实验结果表明:ResNet(1st)和FCN(2nd)具有最好的效果。(GAP层的原因?)
Our empirical study strongly suggests to use ==ResNet ==instead of any other deep learning algorithm - it is the most accurate one with similar runtime to FCN(the second most accurate DNN)

8.1 Results for multivariate time series
尽管Time-CNN和MCDCNN是最初为MTS数据提出的架构,但它们的表现不如那三个深度CNN(ResNet,FCN和Encoder)。
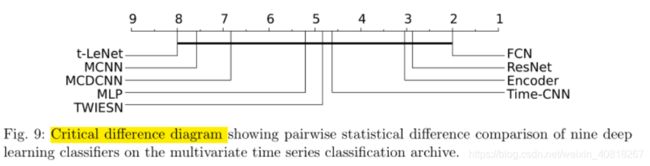
注意,图9中描绘了相应的临界差异图,其中统计测试未能发现九个分类器之间的任何显着差异,这主要是由于与univariate time series classification archive相比, multivariate time series classification 数据集数量较少。与Fig7相比,MTS数据集添加到评估时,各个方法之间的差异没那么显著了(被稀释)。

8.2 dataset’s characteristics 与 方法之间的联系
Dataset’s theme(数据集主题或者类型)

time series length(时间序列长度)
training size of datasets (训练数据大小)

Again, ResNet and FCN still dominate with not much of a difference。
值得注意的一点是, 在DiatomSizeReduction数据集(只有16 training instances)上,ResNet and FCN achieved the worst accuracy (30%) on this dataset while Time-CNN reached the best accuracy (95%),这说明 ResNet 和 FCN 非常容易在这个数据集上过拟合。
所以,训练一个DNN的时候,一个很大的数据集是非常有必要的,下图展示了 ResNet’s accuracy for the TwoPatterns dataset:

the number of classes in a dataset(数据集中类的数量)
大多DNN:categorical cross-entropy(分类交叉熵)作为代价函数和softmax
总结:
总的来说,平均而言,ResNet是最佳架构,FCN和Encoder分别为第二和第三。 ResNet表现得非常好,除了心电图数据集,其表现都优于FCN。 MCNN和t LeNet,其中时间序列被裁剪成子序列,是平均最差的。 我们发现用FC层(MCDCNN,CNN)取代GAP层的方法之间的小差异,这也表现出与TWIESN和MLP类似的性能。

8.3 Effect of random initializations ( 随机初始化的影响 )
这里介绍随机初始化参数对ResNet和FCN的影响:
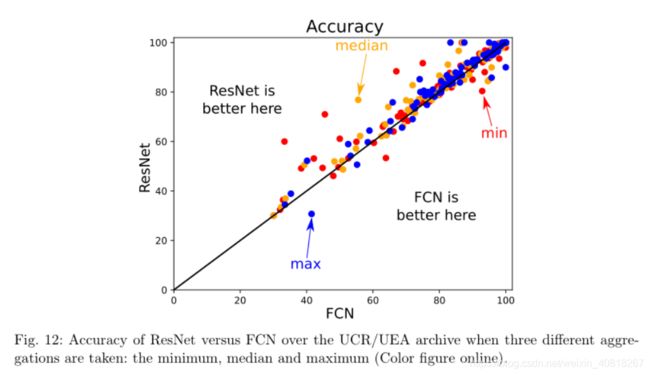
上图显示了使用三种不同函数(最小值,中值和最大值)处理10个随机初始化时的情况。
从图中可以看出:
- 首先,ResNet在大多数数据集中都具有比FCN更好的性能,这和之前的结论一致;
- FCN的性能更加的不稳定,权重的初始值可以很容易地降低FCN的准确性,而ResNet在初始权重值较差时保持相对较高的准确度。
- 研究不同的权重初始化技术,例如利用预先训练的神经网络的权重,可以产生更好和更稳定的结果,如使用迁移学习:https://arxiv.org/abs/1811.01533 first training a base network on a source dataset, and then transferring the learned features (the network’s weights) to a second network to be trained on a target dataset.
9 可视化
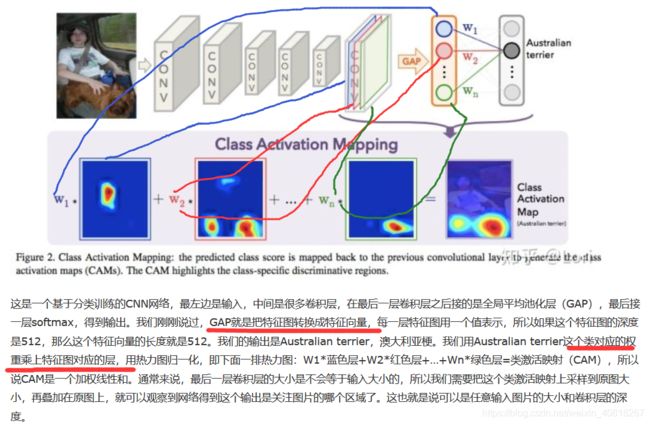
Class Activation Mapping(CAM):类激活映射 出自论文《 Learning deep features for discriminative localization》
而在《Time series classification from scratch with deep neural networks:
A strong baseline》中提出了一种应用于TSC的一维CAM,关于这篇文章作者的评价是:

需注意的是:employing the CAM is only possible for the approaches with a GAP layer preceding the softmax classifier,这也是为什么作者只选了ResNet和FCN进行可视化。
关于CAM和GAP替代FC层: https://blog.csdn.net/weixin_40955254/article/details/81191896
什么是类激活映射呢?CAM是一个帮助我们可视化CNN的工具。

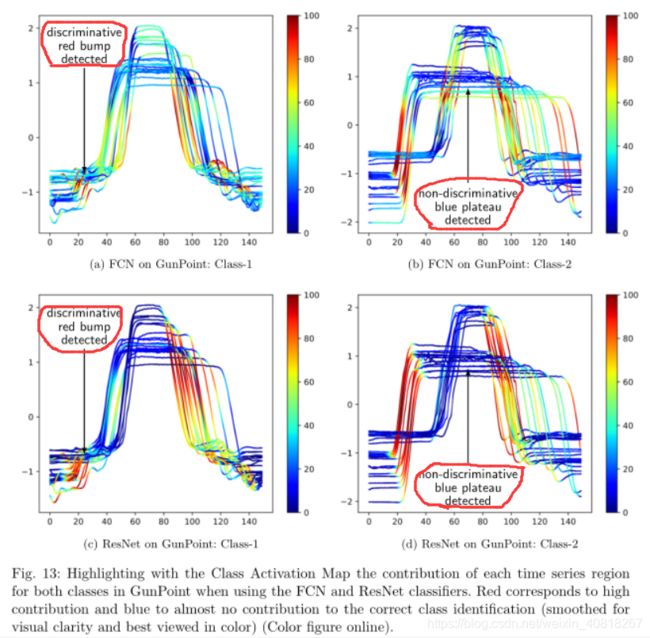
9.1 GunPoint dataset
该数据集涉及一个男性和一个女性演员执行两个动作(Gun-Draw和Point),这使其成为二元分类问题。 对于Gun-Draw(下图中的Class-1),演员首先将他们的手放在他们的两侧,然后从髋部安装的枪套中取出一把枪,将其指向目标一秒钟,然后最后将枪放入皮套同时把他们的手放回原先位置。 与Gun-Draw类似,对于Point(下图中的Class-2),演员遵循相同的步骤,但不是指枪,而是指食指。 对于每个任务,跟踪了X和Y轴上的演员右手的质心并且看起来非常相关,因此数据集仅包含一个单变量时间序列:X轴。
9.2 Meat dataset
Meat是食品光谱仪数据集,通常用于化学计量学中以对食品类型进行分类。该数据集中有三个类别:鸡肉,猪肉和火鸡,分别对应于下图中的1,2和3类。这些数据是通过使用具有衰减全反射(ATR)采样的傅立叶变换红外(FTIR)光谱从60个独立样本中取得的。与GunPoint类似,此数据集易于可视化,并且不包含非常嘈杂的时间序列。 此外,三个类便于理解和分析。 与GunPoint数据集不同的是,两种方法ResNet和FCN在Meat上的结果达到了显着不同的结果,准确度分别为97%和83%。
下图中左边是 FCN’s CAM ,右边是 ResNet’s CAM :
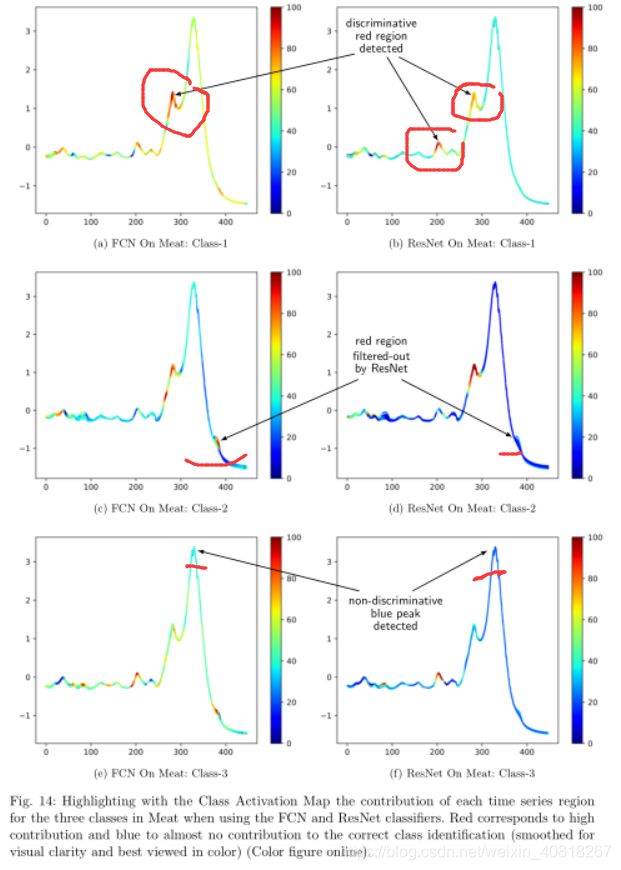
作者解释了为什么ResNet比FCN的精度高:

这里非常值得注意的一点是:

很明显,(c)和(e)图中右下角的红色部分是a non-discriminative part,因为在时间序列上,二者都检测到是一个bump。而在(d)和(f)中,这部分被过滤掉了。
10. 结论
- End-to-end deep learning can achieve the current state-of-the-art performance for TSC with architectures such as Fully Convolutional Neural Networks and deep Residual Networks。
- CAM可视化的使用可以展示输入时间序列中哪些部分对确定分类的贡献程度最大。
- 对于TSC的深度学习,仍然缺乏对 Data augmentation (数据增强) 和 transfer learning(迁移学习) 的全面研究。数据增强可见:
https://blog.csdn.net/lanmengyiyu/article/details/79658545 (主要是图像方面) - TSC领域一个重要挑战是,需要构建一个类似于计算机视觉中的大型数据集,如ImageNet。