视觉SLAM十四讲学习笔记——第九讲 后端优化(1)
经过前端(视觉里程计)估计得到的轨迹和地图由于存在累计误差,在长时间内是不准确的。因此希望构建一个针对全局的更大规模的优化问题,得到最优的轨迹和地图,这里主要有两种解决思路:
(1)基于马尔可夫性假设的卡尔曼滤波器:马氏性假设可以简单地理解为“当前时刻状态只与上一时刻有关”。针对SLAM问题(非线性)的卡尔曼滤波器给出了单次线性近似下的最大后验估计,或者说是优化过程中一次迭代的结果。
(2)非线性优化:非线性优化考虑了当前及之前所有时刻的状态,同时优化所有时刻的相机位姿以及各个特征点的空间位置。使用光束法平差(BA)求得最优解。
一般情况下认为非线性优化算法比滤波器占有明显优势,因此重点关注BA求解与图优化。
1.问题分析
首先针对全局的BA本质上仍是一个最小化重投影误差的问题:结合任意时刻的相机外部参数(位姿)、内部参数及拍摄到的特征点的三维坐标,计算其投影到图像像素坐标系下的坐标,最小化与实际提取结果之间的误差。所涉及的变量均为前端估计得到的,在这个过程中同时调整相机参数及路标(特征点)坐标。

确定优化问题后,一般我们可以使用常见的优化算法直接求解,计算雅克比矩阵和海塞矩阵求解增量方程,但是由于考虑了过去的所有状态和路标,因此方程的维度极大,很难满足实时性,求解过程中需要进行优化。这里考虑到H矩阵的稀疏性,利用Schur消元(也可以称为边缘化)显著降低计算量,加速运算。不过在实际应用中Ceres和g2o库都可以帮助我们完成这一过程。
最后为削弱异常数据对整个优化过程的影响,提高鲁棒性,提出来几种常用的鲁棒核函数,确保每条边的误差不会大的没边而掩盖其他的边,使优化结果更稳健。
2.示例代码分析
首先是数据读取,这里选择创建了一个BALProblem类,来管理读取到的数据。
/// 从文件读入BAL dataset
class BALProblem {
public:
/// 加载文件数据
explicit BALProblem(const std::string &filename, bool use_quaternions = false);
~BALProblem() {
delete[] point_index_;
delete[] camera_index_;
delete[] observations_;
delete[] parameters_;
}
/// 存储数据到.txt
void WriteToFile(const std::string &filename) const;
/// 存储点云文件
void WriteToPLYFile(const std::string &filename) const;
/// 归一化
void Normalize();
/// 给数据加噪声
void Perturb(const double rotation_sigma,
const double translation_sigma,
const double point_sigma);
/// 相机参数数目:是否使用四元数
int camera_block_size() const { return use_quaternions_ ? 10 : 9; }
/// 特征点参数数目:3
int point_block_size() const { return 3; }
/// 相机视角数目
int num_cameras() const { return num_cameras_; }
/// 关键点数目
int num_points() const { return num_points_; }
/// 观测结果数目:多个视角下共观测到多少个特征点(同一特征点多次出现)
int num_observations() const { return num_observations_; }
/// 待估计的参数数目
int num_parameters() const { return num_parameters_; }
/// 观测结果:特征点编号首地址
const int *point_index() const { return point_index_; }
/// 观测结果:相机视角编号首地址
const int *camera_index() const { return camera_index_; }
/// 观测结果:观测点坐标首地址
const double *observations() const { return observations_; }
/// 所有待估计参数首地址(相机位姿参数+特征点坐标)
const double *parameters() const { return parameters_; }
/// 相机位姿参数首地址
const double *cameras() const { return parameters_; }
/// 特征点参数首地址
const double *points() const { return parameters_ + camera_block_size() * num_cameras_; }
/// mutable 易变的
double *mutable_cameras() { return parameters_; }
double *mutable_points() { return parameters_ + camera_block_size() * num_cameras_; }
/// 查找对应信息
double *mutable_camera_for_observation(int i) {
return mutable_cameras() + camera_index_[i] * camera_block_size();
}
double *mutable_point_for_observation(int i) {
return mutable_points() + point_index_[i] * point_block_size();
}
const double *camera_for_observation(int i) const {
return cameras() + camera_index_[i] * camera_block_size();
}
const double *point_for_observation(int i) const {
return points() + point_index_[i] * point_block_size();
}
private:
void CameraToAngelAxisAndCenter(const double *camera,
double *angle_axis,
double *center) const;
void AngleAxisAndCenterToCamera(const double *angle_axis,
const double *center,
double *camera) const;
int num_cameras_;
int num_points_;
int num_observations_;
int num_parameters_;
bool use_quaternions_;
int *point_index_; // 每个observation对应的point index
int *camera_index_; // 每个observation对应的camera index
double *observations_;
double *parameters_;
};其中在读取稳健数据时使用了一个fscanf函数,他的特点是在完成读取后文件指针自动向下移,这就能解释整个过程是如何读取文件内所有数据的。
void FscanfOrDie(FILE *fptr, const char *format, T *value) {
//fscanf:文件指针自动向下移动
int num_scanned = fscanf(fptr, format, value);
if (num_scanned != 1)
std::cerr << "Invalid UW data file. ";
}所读取的problem-16-22106-pre.txt文件的内容包括:
(1)先读取前三个数:分别是相机视角数量、特征点数量、观测结果数量,也就是16张图像,共提取到22106个特征点,这些特征点共出现了83718次(同一特征点在多个视角下重复出现)。
(2)观测结果:每行四个数据包括图像编号(相机视角编号)、特征点编号、像素坐标。例如“10 2 5.826200e+02 3.637200e+02”就表明2号特征点在10号图像内的成像坐标为(582.6,363.7)。
(3)最后是相机参数及路标点世界坐标:每个视角相机参数共有9个,3轴旋转角度、3轴平移向量、焦距、2个畸变系数,如果转化为四元数表达旋转,就对应10个参数。每个路标点世界坐标包括三个参数。
求解方法主要关注g2o的应用,在前面的示例中大多数应用的都是“一个节点+多条一元边”,也就是仅对一组参数进行优化,而对全局的后端优化是“两类多个节点+多条二元边”。这里两类节点分别是:“相机参数节点”和“路标点坐标节点”。
 一个节点+多个一元边
一个节点+多个一元边
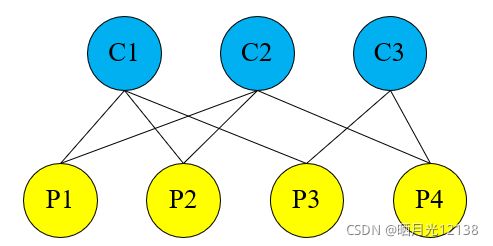 两类多个节点+多个二元边
两类多个节点+多个二元边
首先定义相机参数结构体:
/// 姿态和内参的结构
struct PoseAndIntrinsics {
PoseAndIntrinsics() {}
/// set from given data address
explicit PoseAndIntrinsics(double *data_addr) {
rotation = SO3d::exp(Vector3d(data_addr[0], data_addr[1], data_addr[2]));//旋转向量
translation = Vector3d(data_addr[3], data_addr[4], data_addr[5]);//平移向量
focal = data_addr[6];//焦距
k1 = data_addr[7];//畸变系数
k2 = data_addr[8];
}
/// 将估计值放入内存
void set_to(double *data_addr) {
auto r = rotation.log();
for (int i = 0; i < 3; ++i) data_addr[i] = r[i];
for (int i = 0; i < 3; ++i) data_addr[i + 3] = translation[i];
data_addr[6] = focal;
data_addr[7] = k1;
data_addr[8] = k2;
}
SO3d rotation;
Vector3d translation = Vector3d::Zero();
double focal = 0;
double k1 = 0, k2 = 0;
};定义相机参数节点:包括重投影过程
/// 位姿加相机内参的顶点,9维,前三维为so3,接下去为t, f, k1, k2
class VertexPoseAndIntrinsics : public g2o::BaseVertex<9, PoseAndIntrinsics> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
VertexPoseAndIntrinsics() {}
virtual void setToOriginImpl() override {
_estimate = PoseAndIntrinsics();
}
//更新变量时旋转向量使用指数映射,其他量直接+
virtual void oplusImpl(const double *update) override {
_estimate.rotation = SO3d::exp(Vector3d(update[0], update[1], update[2])) * _estimate.rotation;
_estimate.translation += Vector3d(update[3], update[4], update[5]);
_estimate.focal += update[6];
_estimate.k1 += update[7];
_estimate.k2 += update[8];
}
/// 根据估计值投影一个点
Vector2d project(const Vector3d &point) {
Vector3d pc = _estimate.rotation * point + _estimate.translation;
pc = -pc / pc[2];
double r2 = pc.squaredNorm();
double distortion = 1.0 + r2 * (_estimate.k1 + _estimate.k2 * r2);
return Vector2d(_estimate.focal * distortion * pc[0],
_estimate.focal * distortion * pc[1]);
}
virtual bool read(istream &in) {}
virtual bool write(ostream &out) const {}
};定义路标点坐标节点:
class VertexPoint : public g2o::BaseVertex<3, Vector3d> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
VertexPoint() {}
virtual void setToOriginImpl() override {
_estimate = Vector3d(0, 0, 0);
}
virtual void oplusImpl(const double *update) override {
_estimate += Vector3d(update[0], update[1], update[2]);
}
virtual bool read(istream &in) {}
virtual bool write(ostream &out) const {}
};定义二元边:计算重投影误差
class EdgeProjection :
public g2o::BaseBinaryEdge<2, Vector2d, VertexPoseAndIntrinsics, VertexPoint> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
virtual void computeError() override {
auto v0 = (VertexPoseAndIntrinsics *) _vertices[0];
auto v1 = (VertexPoint *) _vertices[1];
auto proj = v0->project(v1->estimate());
_error = proj - _measurement;
}
// use numeric derivatives
virtual bool read(istream &in) {}
virtual bool write(ostream &out) const {}
};最后添加节点和边,要注意节点与边的连接关系,只有相机拍摄到的路标点会存在重投影误差,才可以在相机参数节点和路标点节点间连接一条边。