NLP | SimKGC论文详解及项目实现
本文主要讲解了论文SimKGC:基于预训练语言模型的简单对比知识图谱补全的论文总结以及项目实现。
论文题目:2022_SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models
论文地址:2022.acl-long.295.pdf (aclanthology.org)
代码地址:intfloat/SimKGC: ACL 2022, SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models (github.com)
1.论文主要内容
更多可参考【1】
- KG通常由三元组(h,r,t)组成,其中h是头实体,r是关系,t是尾实体。
- 受对比学习的启发,引入三种类型的负采样来提升基于文本的KGC方法
- 批内负采样(IB)
- 批前负采样(PB)
- 自我负采样(SN)
- 如果两个实体在知识图谱中通过一条短路径连接,两个实体更有可能相互关联。但是基于文本的KGC方法严重依赖语义匹配,而在一定程度上忽略了这种拓扑偏差,因此本文提出一种简单的重排策略(提高头实体的k跳邻居的分数),来缓解此类现象。
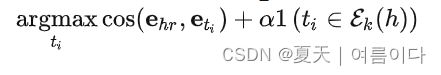
2.项目实现
2.0.环境配置
[我的:Ubuntu20.04+torch2.0.0+cuda11.6]
git clone https://github.com/intfloat/SimKGC
cd SimKGC
pip install scipy2.1.下载数据集
代码中使用了三种数据集
本文只使用一种,也就是wn18rr。项目中提供了脚本文件进行下载并进行数据处理。
bash scripts/preprocess.sh WN18RR
会生成json文件

其中entities.json为实体字典,relations.json为关系,
2.2.训练模型
训练模型并指定输出目录
OUTPUT_DIR=./checkpoint/wn18rr/ bash scripts/train_wn.sh如果运行出错请参考【PS1】,成功的话会打印模型结构参数等

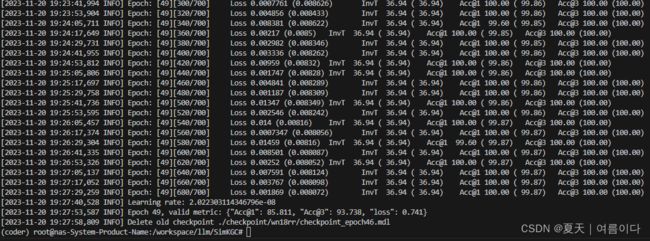
默认是50个epoch,
checkpoint 保存为mdl文件

2.3.验证
bash scripts/eval.sh ./checkpoint/wn18rr/model_last.mdl WN18RR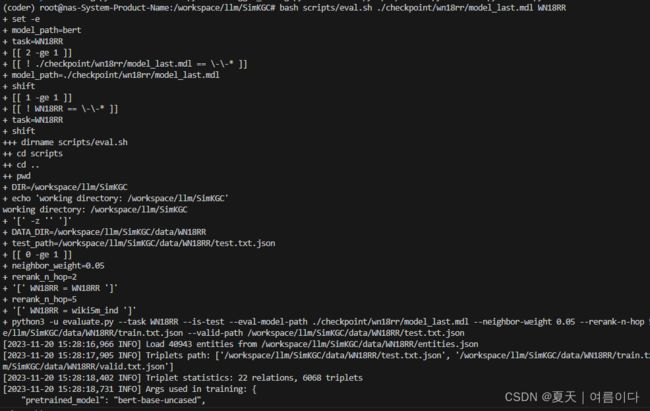
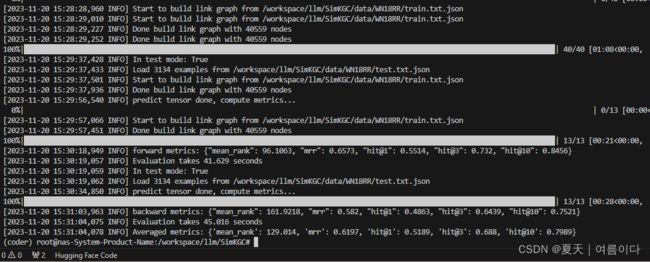
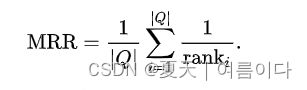
评价标准为MRR【3】
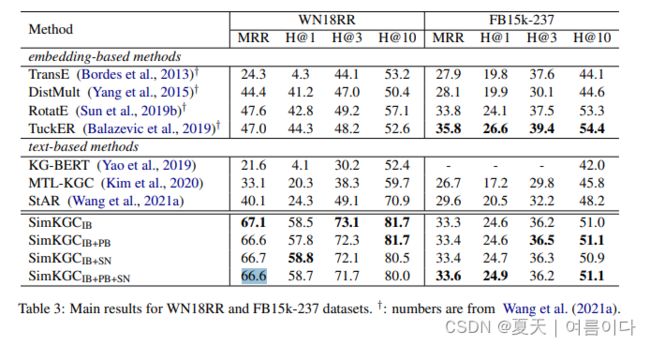
只训练了18个epoch,结果与论文中相似~
3.代码详解
3.1.models.py
使用模型CustomBertModel
使用bert的预训练权重,微调模型,返回知识图谱三要素的向量(logits,labels,hr_vector, tail_vector,head_vector)
3.2.trainer.py
输入:head_id, relation, tail_id
round()
使用方法:round(number,digits)
digits>0,四舍五入到指定的小数位
digits=0, 四舍五入到最接近的整数
digits<0 ,在小数点左侧进行四舍五入
如果round()函数只有number这个参数,等同于digits=0
四舍五入规则:
要求保留位数的后一位<=4,则舍去3,如5.214保留小数点后两位,结果是5.21
要求保留位数的后一位“=5”,且该位数后面没有数字,则不进位,如5.215,结果为5.21
要求保留位数的最后一位“=5”,且该位数后面有数字,则进位,如5.2151,结果为5.22
要求保留位数的最后一位“>=6”,则进位。如5.216,结果为5.22
3.3.evaluate.py
定义平均秩和mrr的算法
3.4.triplet.py
知识图谱中三元组定义,实体id,实体名,实体描述都为字符串。
在实体字典中,包含了EntityDict,LinkGraph的基础定义。
3.5.proprocess.py
定义了三个数据集的数据预处理方法
过程中遇到的问题与解决【PS】
【PS1】RuntimeError: Failed to import transformers.models.bert.modeling_bert because of the following error (look up to see its traceback):too many values to unpack (expected 4)

系统默认模型

修改/SimKGC/scripts/train_wn.sh 脚本文件后
显示ValueError: too many values to unpack (expected 4)
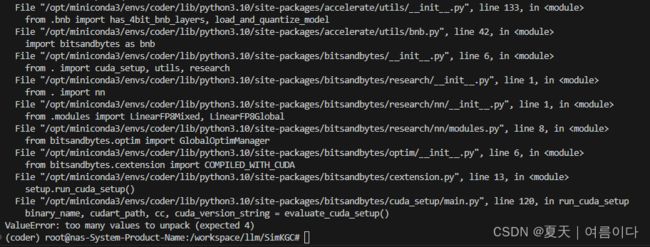
参考CUDA setup · Issue #95 · TimDettmers/bitsandbytes (github.com)
#先查看自己nvcc版本
nvcc --version
#根据自己的版本去修改
git clone https://github.com/TimDettmers/bitsandbytes
cd bitsandbytes
CUDA_VERSION=116 make cuda11x
python setup.py install

运行后就好使啦~
参考文献
【1】【精选】知识图谱顶会论文(ACL-2022) ACL-SimKGC:基于PLM的简单对比KGC_simkgc: simple contrastive knowledge graph complet_Cheng_0829的博客-CSDN博客
【2】论文浅尝 | SimKGC:基于预训练语言模型的简单对比知识图谱补全-CSDN博客
【3】Mean reciprocal rank - Wikipedia