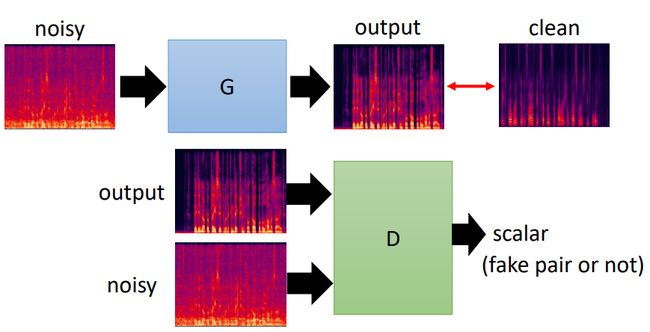
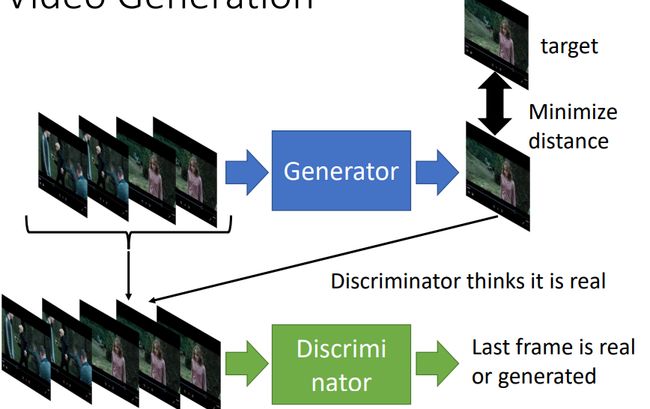
- 使用Dall-E生成图像:文本到图像的魔力
shuoac
计算机视觉人工智能python
使用Dall-E生成图像:文本到图像的魔力技术背景介绍Dall-E是OpenAI开发的一个强大的文本到图像生成模型,它能够根据自然语言描述创造出全新的数字图像。这一技术基于深度学习的方法,使得创意与AI图像生成的结合更具可能性。本文将介绍如何调用Dall-EAPI来生成图像,从而使开发者能够将这一技术应用到自己的项目中。核心原理解析Dall-E利用大型语言模型(LLM)从用户提供的文本描述中提取详
- DS/ML:数据科学技术之数据科学生命周期(四大层次+机器学习六大阶段+数据挖掘【5+6+6+4+4+1】步骤)的全流程最强学习路线讲解之详细攻略
一个处女座的程序猿
资深文章(前沿/经验/创新)DataScienceML数据科学数据科学的生命周期机器学习
DS/ML:数据科学技术之数据科学生命周期(四大层次+机器学习六大阶段+数据挖掘【5+6+6+4+4+1】步骤)的全流程最强学习路线讲解之详细攻略导读:本文章是博主在数据科学和机器学习领域,先后实战过几百个应用案例之后的精心总结,应该是完全覆盖了数据科学的整个生命周期及其各个阶段的要点。其中机器学习领域六大阶段更是在整个数据科学生命周期中扮演着极其重要的角色。同时,因为涉及到博主出书中出版社要求在
- 【深度学习|地学应用】滑坡灾害早期隐患的概念、特征及识别方法,同时解释其与人工边坡、滑坡易发性之间的联系与区别。
985小水博一枚呀
深度学习人工智能
【深度学习|地学应用】滑坡灾害早期隐患的概念、特征及识别方法,同时解释其与人工边坡、滑坡易发性之间的联系与区别。【深度学习|地学应用】滑坡灾害早期隐患的概念、特征及识别方法,同时解释其与人工边坡、滑坡易发性之间的联系与区别。文章目录【深度学习|地学应用】滑坡灾害早期隐患的概念、特征及识别方法,同时解释其与人工边坡、滑坡易发性之间的联系与区别。1.滑坡灾害早期隐患的概念与特征概念主要特征2.通过光学
- 给普通人看的深度学习说明书:用快递系统理解AI如何思考
嵌入式Jerry
PythonAI人工智能深度学习
第一章:理解AI的思维方式(快递版)1.1快递分拣站的故事假设你管理一个快递分拣站:传统方法:手动制定规则(比如根据邮编分拣)机器学习:观察老员工的分拣记录,总结规律深度学习:搭建自动分拣流水线,自主发现隐藏规则1.2神经网络就像智能分拣机传送带(输入层):接收包裹信息(图片像素/文字等)#就像扫描快递单input_data=[0.2,0.7,0.1]#归一化后的特征数据分拣工人(隐藏层):每个工
- 简单理解机器学习中top_k、top_p、temperature三个参数的作用
无级程序员
机器学习人工智能
在机器学习中,top_k、top_p和temperature是用于控制生成模型(如语言模型)输出质量的参数,尤其在文本生成任务中常见。然而,网上文章很多很全,但大多晦涩难懂,今天我们来用最简单的语言谈谈它们的具体作用:1.点菜式筛选法:top_k参数英文全称:top-k中文名称:前k个具体意义:top_k参数就像是你在餐厅点菜时,服务员只给你推荐菜单上前k名的招牌菜。在AI文本生成中,top_k参
- 解析大模型归一化:提升训练稳定性和性能的关键技术
秋声studio
口语化解析深度学习人工智能大模型归一化
引言在深度学习领域,特别是在处理大型神经网络模型时,归一化(Normalization)是一项至关重要的技术。它可以提高模型的训练稳定性和性能,在加速收敛方面发挥了重要作用。本文将深入探讨大模型归一化的原理、常见方法及其应用场景,并结合实际案例和代码示例进行说明。一、归一化的作用与理论基础归一化的主要目的是为了提高模型的训练稳定性和性能。具体来说,归一化有以下几个关键作用:提高训练稳定性:在神经网
- 小白零基础学数学建模系列-引言与课程目录
川川菜鸟
数学建模小白到精通系列数学建模
目录引言一、我们的专辑包含哪些内容?第一周:数学建模基础与工具第二周:高级数学建模技巧与应用第三周:机器学习基础与数据处理第四周:监督学习与无监督学习算法第五周:神经网络二、学完本专辑能收获到什么?三、适合什么样的人群学习?四、如何学习本专辑?课程目录第1周:数学建模基础与工具第1天:数学建模入门介绍第2天:数学建模工具介绍第3天:线性回归与曲线拟合第4天:线性规划第5天:动态规划第2周:高级数学
- 深入解析深度学习中的过拟合与欠拟合诊断、解决与工程实践
古月居GYH
深度学习人工智能
一、引言:模型泛化能力的核心挑战在深度学习模型开发中,欠拟合与过拟合是影响泛化能力的两个核心矛盾。据GoogleBrain研究统计,工业级深度学习项目中有63%的失败案例与这两个问题直接相关。本文将从基础概念到工程实践,系统解析其本质特征、诊断方法及解决方案,并辅以可复现的代码案例。二、核心概念与通熟易懂解释简单而言,欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在
- 初始OpenCV
指尖下的技术
OpenCVopencv人工智能计算机视觉
OpenCV是一个功能强大、应用广泛的计算机视觉库,它为开发人员提供了丰富的工具和算法,可以帮助他们快速构建各种视觉应用。随着计算机视觉技术的不断发展,OpenCV也将会继续发挥重要的作用。OpenCV提供了大量的计算机视觉算法和图像处理工具,广泛应用于图像和视频的处理、分析以及机器学习领域。所以学习人计算机视觉或者图像处理方面的知识,OpenCV是一个要重点学习的工具库。首先介绍一下OpenCV
- 机器学习结合伏羲模型高精度多尺度气象分析与降尺度实现
Hardess-god
WRF算法人工智能
随着人工智能的发展,机器学习技术在气象预报领域展现出巨大潜力。本文详细探讨如何结合机器学习(ML)和伏羲模型进行高精度多尺度气象模拟分析,并提供详细的实现步骤和相关代码。1.研究目标与技术路线目标:结合机器学习模型与伏羲气象模式,实现区域和局地高精度降尺度。技术路线:伏羲模型提供大尺度气象数据和预报使用机器学习模型(如CNN、LSTM、XGBoost)进行降尺度2.数据准备与处理2.1气象数据获取
- Umi-OCR 实践教程:离线、免费、高效的图像文字识别工具
几道之旅
人工智能智能体及数字员工ocr人工智能
一、工具简介Umi-OCR是一款开源、免费且支持离线运行的OCR(光学字符识别)工具,适用于Windows和Linux系统。它基于深度学习技术,能够高效提取图像中的文字,支持多语言识别、批量处理、截屏识别等功能,尤其适合对隐私敏感或网络受限的场景。核心亮点:离线运行:无需联网,保护隐私。多引擎支持:提供Paddle(高性能)和Rapid(低配兼容)两种引擎。批量处理:支持图片、PDF、电子书等多格
- 基于ChatGPT、GIS与Python机器学习的地质灾害风险评估、易发性分析、信息化建库及灾后重建高级实践
weixin_贾
防洪评价风险评估滑坡泥石流地质灾害
第一章、ChatGPT、DeepSeek大语言模型提示词与地质灾害基础及平台介绍【基础实践篇】1、什么是大模型?大模型(LargeLanguageModel,LLM)是一种基于深度学习技术的大规模自然语言处理模型。代表性大模型:GPT-4、BERT、T5、ChatGPT等。特点:多任务能力:可以完成文本生成、分类、翻译、问答等任务。上下文理解:能理解复杂的上下文信息。广泛适配性:适合科研、教育、行
- anythingLLM 使用教程
惟贤箬溪
穷玩AiAIGC人工智能
一、anythingLLM简介anythingLLM是一款灵活且功能强大的语言模型,它基于先进的深度学习架构构建,旨在为用户提供多样化的自然语言处理服务。其设计理念注重通用性和可扩展性,能够适应多种领域和任务,无论是文本生成、智能问答,还是翻译、摘要提取等,都能展现出出色的性能。与同类模型相比,anythingLLM具有训练数据丰富、模型优化程度高的优势,能够生成更符合逻辑、更具实用性的文本内容。
- 深度解析大模型推理框架:原理、应用与实践
百度_开发者中心
人工智能大模型自然语言处理
在当今数据驱动的时代,大模型推理框架已经成为人工智能领域的重要支柱。本文将通过简明扼要、清晰易懂的方式,带领读者深入了解大模型推理框架的原理、应用领域和实践经验,帮助读者更好地掌握这一技术,并在实际工作中发挥其价值。一、大模型推理框架简介大模型推理框架是指一种基于深度学习技术的推理框架,主要用于解决大规模数据集下的复杂问题。该框架通过对海量数据进行高效的训练和推理,能够快速地对各种复杂场景进行分析
- 大模型推理框架:从理论到实践的全面解析
百度_开发者中心
人工智能大模型自然语言处理
在数据驱动的时代,深度学习技术已经渗透到各个行业,从图像识别到自然语言处理,从推荐系统到智能客服,其应用无处不在。然而,深度学习模型的训练和推理过程往往涉及大量数据和复杂计算,传统的计算框架难以满足需求。因此,大模型推理框架应运而生,成为解决这一问题的关键。一、大模型推理框架基本概念大模型推理框架是一种基于深度学习技术的推理框架,它通过对海量数据进行高效的训练和推理,能够快速地对各种复杂场景进行分
- 人脸识别的一些代码
饿了就干饭
CV相关人脸识别
1、cv2入门函数imread及其相关操作2、(详解)opencv里的cv2.resize改变图片大小Python3、机器学习之人脸识别face_recognition使用4、使用face_recognition进行人脸校准5、简单的人脸识别通用流程示意图(这个看着写的挺好的)6、face_recognition和图像处理中left、top、right、bottom解释7、使用pillow库对图片
- 探索Python中的集成方法:Stacking
Echo_Wish
Python笔记Python算法python开发语言
在机器学习领域,Stacking是一种高级的集成学习方法,它通过将多个基本模型的预测结果作为新的特征输入到一个元模型中,从而提高整体模型的性能和鲁棒性。本文将深入介绍Stacking的原理、实现方式以及如何在Python中应用。什么是Stacking?Stacking,又称为堆叠泛化(StackedGeneralization),是一种模型集成方法,与Bagging和Boosting不同,它并不直
- 【Python】 Stacking: 强大的集成学习方法
音乐学家方大刚
Pythonpython集成学习开发语言
我们都找到天使了说好了心事不能偷藏着什么都一起做幸福得没话说把坏脾气变成了好沟通我们都找到天使了约好了负责对方的快乐阳光下的山坡你素描的以后怎么抄袭我脑袋想的薛凯琪《找到天使了》在机器学习中,单一模型的性能可能会受到其局限性和数据的影响。为了解决这个问题,我们可以使用集成学习(EnsembleLearning)方法。集成学习通过结合多个基模型的预测结果,来提高整体模型的准确性和稳健性。Stacki
- Stacking算法:集成学习的终极武器
civilpy
算法集成学习机器学习
Stacking算法:集成学习的终极武器在机器学习的竞技场中,集成学习方法以其卓越的性能而闻名。其中,Stacking(堆叠泛化)作为一种高级集成技术,更是被誉为“集成学习的终极武器”。本文将带你深入了解Stacking算法的原理和实现,并提供一些实战技巧和最佳实践。1.Stacking算法原理探秘Stacking算法的核心思想是训练多个不同的基模型,并将它们的预测结果作为新模型的输入特征,以此来
- 集成学习(上):Bagging集成方法
万事可爱^
机器学习修仙之旅#监督学习集成学习机器学习人工智能Bagging随机森林
一、什么是集成学习?在机器学习的世界里,没有哪个模型是完美无缺的。就像古希腊神话中的"盲人摸象",单个模型往往只能捕捉到数据特征的某个侧面。但当我们把多个模型的智慧集合起来,就能像拼图一样还原出完整的真相,接下来我们就来介绍一种“拼图”算法——集成学习。集成学习是一种机器学习技术,它通过组合多个模型(通常称为“弱学习器”或“基础模型”)的预测结果,构建出更强、更准确的学习算法。这种方法的主要思想是
- 【集成学习】:Stacking原理以及Python代码实现
Geeksongs
机器学习python机器学习深度学习人工智能算法
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好。今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理。并在博文的后面附有相关代码实现。总体来说,stacking集成算法主要是一种基于“标签”的学习,有以下的特点:用法:模型利用交叉验证,对训练集进行预测,从而实现二次学习优点:可以结合不同的模型缺点:增加了时间开销,容
- windows使用ssh-copy-id命令的解决方案
爱编程的喵喵
Windows实用技巧windowssshssh-copy-id解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了windows使用ssh-copy-
- Yolo系列之Yolo的基本理解
是十一月末
YOLOpython开发语言yolo
YOLO的基本理解目录YOLO的基本理解1YOLO1.1概念1.2算法2单、多阶段对比2.1FLOPs和FPS2.2one-stage单阶段2.3two-stage两阶段1YOLO1.1概念YOLO(YouOnlyLookOnce)是一种基于深度学习的目标检测算法,由JosephRedmon等人于2016年提出。它的核心思想是将目标检测问题转化为一个回归问题,通过一个神经网络直接预测目标的类别和位
- PyTorch基础知识讲解(一)完整训练流程示例
苏雨流丰
机器学习pytorch人工智能python机器学习深度学习
文章目录Tutorial1.数据处理2.网络模型定义3.损失函数、模型优化、模型训练、模型评价4.模型保存、模型加载、模型推理Tutorial大多数机器学习工作流程涉及处理数据、创建模型、优化模型参数和保存训练好的模型。本教程向你介绍一个用PyTorch实现的完整的ML工作流程,并提供链接来了解这些概念中的每一个。我们将使用FashionMNIST数据集来训练一个神经网络,预测输入图像是否属于以下
- 机器学习中的贝叶斯网络:如何构建高效的风险预测模型
AI天才研究院
DeepSeekR1&大数据AI人工智能大模型自然语言处理人工智能语言模型编程实践开发语言架构设计
作者:禅与计算机程序设计艺术文章目录机器学习中的贝叶斯网络:如何构建高效的风险预测模型1.背景介绍2.基本概念术语说明2.1马尔科夫随机场(MarkovRandomField)2.2条件随机场(ConditionalRandomField,CRF)2.3变量elimination算法2.4贝叶斯网络3.核心算法原理和具体操作步骤以及数学公式讲解3.1原理介绍1.贝叶斯网络基础2.贝叶斯网络构建风险
- 大语言模型学习路线:从入门到实战
大模型官方资料
语言模型学习人工智能产品经理自然语言处理搜索引擎
大语言模型学习路线:从入门到实战在人工智能领域,大语言模型(LargeLanguageModels,LLMs)正迅速成为一个热点话题。本学习路线旨在为有基本Python编程和深度学习基础的学习者提供一个清晰、系统的大模型学习指南,帮助你在这一领域快速成长。本学习路线更新至2024年02月,后期部分内容或工具可能需要更新。适应人群已掌握Python基础具备基本的深度学习知识学习步骤本路线将通过四个核
- 深度学习与目标检测系列(六) 本文约(4.5万字) | 全面解读复现ResNet | Pytorch |
小酒馆燃着灯
深度学习目标检测pytorch人工智能ResNet残差连接残差网络
文章目录解读Abstract—摘要翻译精读主要内容Introduction—介绍翻译精读背景RelatedWork—相关工作ResidualRepresentations—残差表达翻译精读主要内容ShortcutConnections—短路连接翻译精读主要内容DeepResidualLearning—深度残差学习ResidualLearning—残差学习翻译精读ResNet目的以前方法本文改进本质
- 深度学习与目标检测系列(三) 本文约(4万字) | 全面解读复现AlexNet | Pytorch |
小酒馆燃着灯
深度学习目标检测pytorchAlexNet人工智能
文章目录解读Abstract-摘要翻译精读主要内容1.Introduction—前言翻译精读主要内容:本文主要贡献:2.TheDataset-数据集翻译精读主要内容:ImageNet简介:图像处理方法:3.TheArchitecture—网络结构3.1ReLUNonlinearity—非线性激活函数ReLU翻译精读传统方法及不足本文改进方法本文的改进结果3.2TrainingonMultipleG
- Pytorch使用手册-DCGAN 指南(专题十四)
AI专题精讲
Pytorch入门到精通pytorch人工智能python
1.Introduction本教程将通过一个示例介绍DCGANs(深度卷积生成对抗网络)。我们将训练一个生成对抗网络(GAN),在给它展示大量真实名人照片后,它能够生成新的“名人”图片。这里的大部分代码来源于PyTorch官方示例中的DCGAN实现,而本文档将对该实现进行详细解释,并阐明这种模型的运行机制及其背后的原因。无需担心,你不需要事先了解GAN的知识,但初次接触的读者可能需要花一些时间来理
- 使用 Milvus 进行向量数据库管理与实践
qahaj
milvus数据库python
技术背景介绍在当今的AI与机器学习应用中,处理和管理大量的嵌入向量是一个常见的需求。Milvus是一个开源向量数据库,专门用于存储、索引和管理深度神经网络以及其他机器学习模型生成的大规模嵌入向量。它的高性能和易用性使其成为处理向量数据的理想选择。核心原理解析Milvus的核心功能体现在其强大的向量索引和搜索能力。它支持多种索引算法,包括IVF、HNSW等,使其能够高效地进行大规模向量的相似性搜索操
- Dom
周华华
JavaScripthtml
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q
- 【Spark九十六】RDD API之combineByKey
bit1129
spark
1. combineByKey函数的运行机制
RDD提供了很多针对元素类型为(K,V)的API,这些API封装在PairRDDFunctions类中,通过Scala隐式转换使用。这些API实现上是借助于combineByKey实现的。combineByKey函数本身也是RDD开放给Spark开发人员使用的API之一
首先看一下combineByKey的方法说明:
- msyql设置密码报错:ERROR 1372 (HY000): 解决方法详解
daizj
mysql设置密码
MySql给用户设置权限同时指定访问密码时,会提示如下错误:
ERROR 1372 (HY000): Password hash should be a 41-digit hexadecimal number;
问题原因:你输入的密码是明文。不允许这么输入。
解决办法:用select password('你想输入的密码');查询出你的密码对应的字符串,
然后
- 路漫漫其修远兮 吾将上下而求索
周凡杨
学习 思索
王国维在他的《人间词话》中曾经概括了为学的三种境界古今之成大事业、大学问者,罔不经过三种之境界。“昨夜西风凋碧树。独上高楼,望尽天涯路。”此第一境界也。“衣带渐宽终不悔,为伊消得人憔悴。”此第二境界也。“众里寻他千百度,蓦然回首,那人却在灯火阑珊处。”此第三境界也。学习技术,这也是你必须经历的三种境界。第一层境界是说,学习的路是漫漫的,你必须做好充分的思想准备,如果半途而废还不如不要开始。这里,注
- Hadoop(二)对话单的操作
朱辉辉33
hadoop
Debug:
1、
A = LOAD '/user/hue/task.txt' USING PigStorage(' ')
AS (col1,col2,col3);
DUMP A;
//输出结果前几行示例:
(>ggsnPDPRecord(21),,)
(-->recordType(0),,)
(-->networkInitiation(1),,)
- web报表工具FineReport常用函数的用法总结(日期和时间函数)
老A不折腾
finereport报表工具web开发
web报表工具FineReport常用函数的用法总结(日期和时间函数)
说明:凡函数中以日期作为参数因子的,其中日期的形式都必须是yy/mm/dd。而且必须用英文环境下双引号(" ")引用。
DATE
DATE(year,month,day):返回一个表示某一特定日期的系列数。
Year:代表年,可为一到四位数。
Month:代表月份。
- c++ 宏定义中的##操作符
墙头上一根草
C++
#与##在宏定义中的--宏展开 #include <stdio.h> #define f(a,b) a##b #define g(a) #a #define h(a) g(a) int main() { &nbs
- 分析Spring源代码之,DI的实现
aijuans
springDI现源代码
(转)
分析Spring源代码之,DI的实现
2012/1/3 by tony
接着上次的讲,以下这个sample
[java]
view plain
copy
print
- for循环的进化
alxw4616
JavaScript
// for循环的进化
// 菜鸟
for (var i = 0; i < Things.length ; i++) {
// Things[i]
}
// 老鸟
for (var i = 0, len = Things.length; i < len; i++) {
// Things[i]
}
// 大师
for (var i = Things.le
- 网络编程Socket和ServerSocket简单的使用
百合不是茶
网络编程基础IP地址端口
网络编程;TCP/IP协议
网络:实现计算机之间的信息共享,数据资源的交换
协议:数据交换需要遵守的一种协议,按照约定的数据格式等写出去
端口:用于计算机之间的通信
每运行一个程序,系统会分配一个编号给该程序,作为和外界交换数据的唯一标识
0~65535
查看被使用的
- JDK1.5 生产消费者
bijian1013
javathread生产消费者java多线程
ArrayBlockingQueue:
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部 是在队列中存在时间最长的元素。队列的尾部 是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列检索操作则是从队列头部开始获得元素。
ArrayBlockingQueue的常用方法:
- JAVA版身份证获取性别、出生日期及年龄
bijian1013
java性别出生日期年龄
工作中需要根据身份证获取性别、出生日期及年龄,且要还要支持15位长度的身份证号码,网上搜索了一下,经过测试好像多少存在点问题,干脆自已写一个。
CertificateNo.java
package com.bijian.study;
import java.util.Calendar;
import
- 【Java范型六】范型与枚举
bit1129
java
首先,枚举类型的定义不能带有类型参数,所以,不能把枚举类型定义为范型枚举类,例如下面的枚举类定义是有编译错的
public enum EnumGenerics<T> { //编译错,提示枚举不能带有范型参数
OK, ERROR;
public <T> T get(T type) {
return null;
- 【Nginx五】Nginx常用日志格式含义
bit1129
nginx
1. log_format
1.1 log_format指令用于指定日志的格式,格式:
log_format name(格式名称) type(格式样式)
1.2 如下是一个常用的Nginx日志格式:
log_format main '[$time_local]|$request_time|$status|$body_bytes
- Lua 语言 15 分钟快速入门
ronin47
lua 基础
-
-
单行注释
-
-
[[
[多行注释]
-
-
]]
-
-
-
-
-
-
-
-
-
-
-
1.
变量 & 控制流
-
-
-
-
-
-
-
-
-
-
num
=
23
-
-
数字都是双精度
str
=
'aspythonstring'
- java-35.求一个矩阵中最大的二维矩阵 ( 元素和最大 )
bylijinnan
java
the idea is from:
http://blog.csdn.net/zhanxinhang/article/details/6731134
public class MaxSubMatrix {
/**see http://blog.csdn.net/zhanxinhang/article/details/6731134
* Q35
求一个矩阵中最大的二维
- mongoDB文档型数据库特点
开窍的石头
mongoDB文档型数据库特点
MongoDD: 文档型数据库存储的是Bson文档-->json的二进制
特点:内部是执行引擎是js解释器,把文档转成Bson结构,在查询时转换成js对象。
mongoDB传统型数据库对比
传统类型数据库:结构化数据,定好了表结构后每一个内容符合表结构的。也就是说每一行每一列的数据都是一样的
文档型数据库:不用定好数据结构,
- [毕业季节]欢迎广大毕业生加入JAVA程序员的行列
comsci
java
一年一度的毕业季来临了。。。。。。。。
正在投简历的学弟学妹们。。。如果觉得学校推荐的单位和公司不适合自己的兴趣和专业,可以考虑来我们软件行业,做一名职业程序员。。。
软件行业的开发工具中,对初学者最友好的就是JAVA语言了,网络上不仅仅有大量的
- PHP操作Excel – PHPExcel 基本用法详解
cuiyadll
PHPExcel
导出excel属性设置//Include classrequire_once('Classes/PHPExcel.php');require_once('Classes/PHPExcel/Writer/Excel2007.php');$objPHPExcel = new PHPExcel();//Set properties 设置文件属性$objPHPExcel->getProperties
- IBM Webshpere MQ Client User Issue (MCAUSER)
darrenzhu
IBMjmsuserMQMCAUSER
IBM MQ JMS Client去连接远端MQ Server的时候,需要提供User和Password吗?
答案是根据情况而定,取决于所定义的Channel里面的属性Message channel agent user identifier (MCAUSER)的设置。
http://stackoverflow.com/questions/20209429/how-mca-user-i
- 网线的接法
dcj3sjt126com
一、PC连HUB (直连线)A端:(标准568B):白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。 B端:(标准568B):白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。 二、PC连PC (交叉线)A端:(568A): 白绿,绿,白橙,蓝,白蓝,橙,白棕,棕; B端:(标准568B):白橙,橙,白绿,蓝,白蓝,绿,白棕,棕。 三、HUB连HUB&nb
- Vimium插件让键盘党像操作Vim一样操作Chrome
dcj3sjt126com
chromevim
什么是键盘党?
键盘党是指尽可能将所有电脑操作用键盘来完成,而不去动鼠标的人。鼠标应该说是新手们的最爱,很直观,指哪点哪,很听话!不过常常使用电脑的人,如果一直使用鼠标的话,手会发酸,因为操作鼠标的时候,手臂不是在一个自然的状态,臂肌会处于绷紧状态。而使用键盘则双手是放松状态,只有手指在动。而且尽量少的从鼠标移动到键盘来回操作,也省不少事。
在chrome里安装 vimium 插件
- MongoDB查询(2)——数组查询[六]
eksliang
mongodbMongoDB查询数组
MongoDB查询数组
转载请出自出处:http://eksliang.iteye.com/blog/2177292 一、概述
MongoDB查询数组与查询标量值是一样的,例如,有一个水果列表,如下所示:
> db.food.find()
{ "_id" : "001", "fruits" : [ "苹
- cordova读写文件(1)
gundumw100
JavaScriptCordova
使用cordova可以很方便的在手机sdcard中读写文件。
首先需要安装cordova插件:file
命令为:
cordova plugin add org.apache.cordova.file
然后就可以读写文件了,这里我先是写入一个文件,具体的JS代码为:
var datas=null;//datas need write
var directory=&
- HTML5 FormData 进行文件jquery ajax 上传 到又拍云
ileson
jqueryAjaxhtml5FormData
html5 新东西:FormData 可以提交二进制数据。
页面test.html
<!DOCTYPE>
<html>
<head>
<title> formdata file jquery ajax upload</title>
</head>
<body>
<
- swift appearanceWhenContainedIn:(version1.2 xcode6.4)
啸笑天
version
swift1.2中没有oc中对应的方法:
+ (instancetype)appearanceWhenContainedIn:(Class <UIAppearanceContainer>)ContainerClass, ... NS_REQUIRES_NIL_TERMINATION;
解决方法:
在swift项目中新建oc类如下:
#import &
- java实现SMTP邮件服务器
macroli
java编程
电子邮件传递可以由多种协议来实现。目前,在Internet 网上最流行的三种电子邮件协议是SMTP、POP3 和 IMAP,下面分别简单介绍。
◆ SMTP 协议
简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)是一个运行在TCP/IP之上的协议,用它发送和接收电子邮件。SMTP 服务器在默认端口25上监听。SMTP客户使用一组简单的、基于文本的
- mongodb group by having where 查询sql
qiaolevip
每天进步一点点学习永无止境mongo纵观千象
SELECT cust_id,
SUM(price) as total
FROM orders
WHERE status = 'A'
GROUP BY cust_id
HAVING total > 250
db.orders.aggregate( [
{ $match: { status: 'A' } },
{
$group: {
- Struts2 Pojo(六)
Luob.
POJOstrust2
注意:附件中有完整案例
1.采用POJO对象的方法进行赋值和传值
2.web配置
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee&q
- struts2步骤
wuai
struts
1、添加jar包
2、在web.xml中配置过滤器
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.st

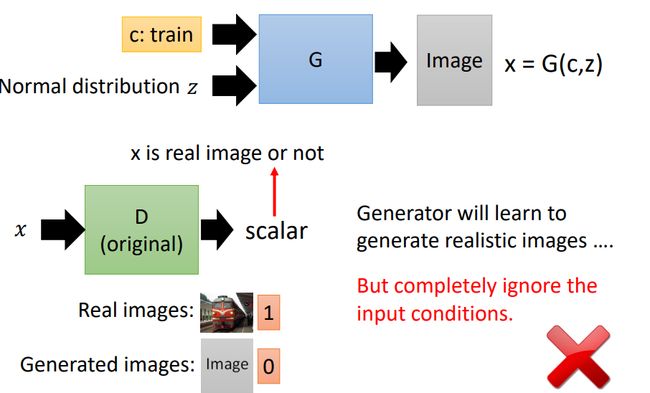
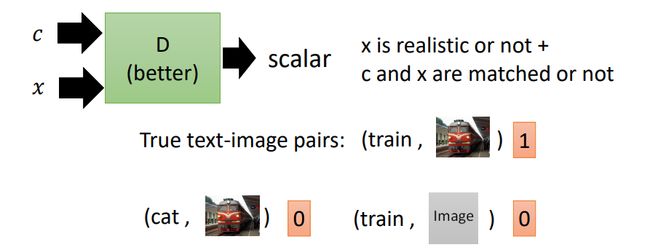
 (条件+图片)。
(条件+图片)。 。
。