大数据最佳实践-hive on spark
目录
-
- Hive on Spark与SparkSQL
- Spark 内存配置
- spark动态分配
- Hive
Hive on Spark与SparkSQL
Hive是Hadoop中的标准SQL引擎,也是最古老的引擎之一。Hive on Spark为我们立即提供了Hive和Spark的所有巨大优势。它最初是作为数据仓库(DW)工具构建的,现在它具有轻松交换执行引擎的功能,因此更具吸引力。简而言之,使用Hive on Spark,您的查询将由Hive优化器优化,最后执行Spark作业。与默认MR相比,其他所有Hive功能仍保持完整,但具有更快,更优化的执行引擎。Hive已经存在了很长时间,并且得到了更好的社区支持。从Cloudera开始,Hive on Spark可以从CDH 5.7开始进行生产。Hive具有比SparkSQL更好的SQL支持,并具有使用HiveServer2进行身份验证的更好的安全性功能。以下图片显示Hive如何在内部将Spark作为执行引擎工作?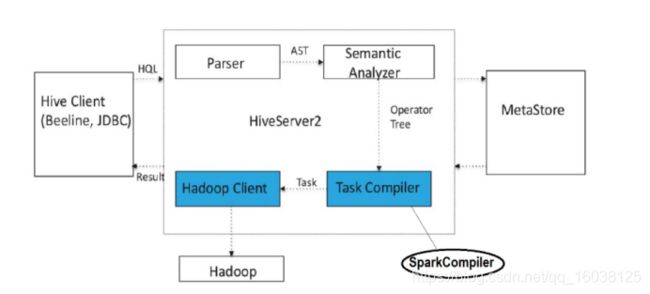
SparkSQL是更新的SQL-on-Hadoop工具。它与Hive集成,并且默认情况下使用Hive Metastore来管理其元数据。它有自己的称为Catalyst的查询优化器,该优化器通过优化查询然后生成字节码来运行作业来构造运算符树。与Hive不同,这里没有切换执行引擎的选择。SparkSQL集成并与其他Spark库(例如Spark流,Spark核心等)无缝集成,例如可以将Java代码与SQL混合并与RDD一起玩,创建DataFrames等。现在有了这个库,Spark用户可以有选择地使用SQL构造在编写Spark管道时。下图概述了sparkSQL体系结构。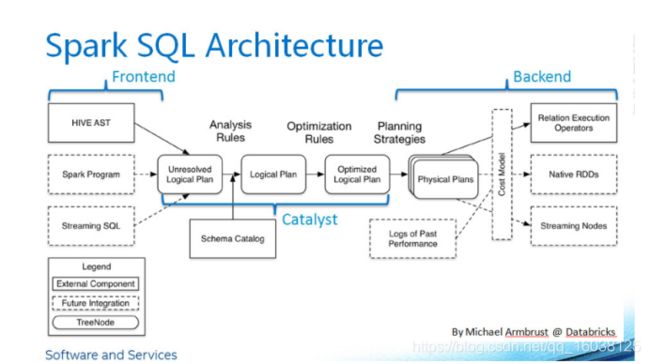
SparkSQL和Hive均可与Tableau,Datameer等BI工具连接。CDH5不支持sparkSQL节俭服务器,因此,如果您打算将Tableau等BI工具连接到CDH 5,则由您自己决定。执行引擎,这两种解决方案完全依赖于内存,当内存用完时,数据会溅到磁盘上,这与MR一样严重。还有一点要注意;Spark对经常访问的数据集有效,只有在这种情况下,您才能释放Spark的全部功能,因为框架可以在内存中缓存RDD。SparkSQL不能替代Hive,反之亦然。在我看来,SparkSQL对Spark开发人员和API更加友好,因为它使在Spark中进行编程更加容易。
Spark 内存配置
yarn.nodemanager.resource.memory-mb = 100 GB
yarn.nodemanager.resource.cpu-vcores = 28 < 机器核心数
yarn.scheduler.maximum-allocation-mb>(spark.yarn.executor.memoryOverhead+spark.executor.memory )
spark.executor.cores =4、5或6
spark.executor.num= 28/4 可以整除
spark.executor.memory=100/28/4=14G
对于单个执行程序,请使用64 GB作为上限。
运行内存过多的执行程序通常会导致过多的垃圾回收延迟。对于单个执行程序,请使用64 GB作为上限。
HDFS客户端难以处理许多并发线程。每个执行程序最多可以完成五个任务,以实现完整的写入吞吐量,因此请使每个执行程序的内核数保持在该数量以下。
运行微小的执行程序(例如,具有单个内核和仅足够的内存来运行单个任务)可以抵消在单个JVM中运行多个任务的好处。例如,广播变量必须在每个执行器上复制一次,因此许多小型执行器会产生更多的数据副本。
更多的执行程序内存可实现更多查询的map join 优化,但由于垃圾回收,可能导致开销增加。
在某些情况下,HDFS客户端不能很好地处理并发写入器,因此,如果执行者具有过多的内核,则可能会出现竞争状态
spark.yarn.executor.memoryOverhead=executorMemory * 0.10 (5-10%)
spark.driver = 12%* yarn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.memory-mb大于50 GB时为12 GB
yarn.nodemanager.resource.memory-mb在12 GB到50 GB之间时为4 GB
yarn.nodemanager.resource.memory-mb在1GB和12GB之间时为1GB
yarn.nodemanager.resource.memory-mb小于1 GB时为256 MB
spark.driver.memory = 10.5gb
spark.yarn.driver.memoryOverhead = 1.5gb
spark.executor.instances =
测试环境
主机数量40*spark.executor.cores
生产环境
spark动态分配
根据工作负载动态扩展分配给您的应用程序的群集资源。启用动态分配后,Spark应用程序积压了待处理的任务,它可以请求执行者。当应用程序变得空闲时,其执行程序将被释放,并可以被其他应用程序获取。
spark.dynamicAllocation.enabled=true
初始执行程序的数量越大
Init num-executors=max(spark.executor.instances,spark.dynamicAllocation.initialExecutors
)
启用Spark动态资源分配后,所有资源均分配给第一个可用的提交作业,从而导致后续应用程序排队。要允许应用程序并行获取资源,请将资源分配给池并在这些池中运行应用程序,并使在池中运行的应用程序被抢占。请参阅动态资源池。
Spark Streaming 配置
spark.dynamicAllocation.executorIdleTimeout 执行程序在被删除之前必须处于空闲状态的时间长度。
默认: 60 s。
spark.dynamicAllocation.enabled 是否启用动态分配。
默认: 真正。
spark.dynamicAllocation.initialExecutors 启用动态分配时,Spark应用程序的执行程序的初始数量。如果spark.executor.instances (或其等效的命令行参数, --num-执行者)设置为更高的数字,而是使用该数字。
默认: 1个。
spark.dynamicAllocation.minExecutors 执行者数量的下限。
默认: 0。
spark.dynamicAllocation.maxExecutors 执行者数量的上限。
默认: 整数MAX_VALUE。
spark.dynamicAllocation.schedulerBacklogTimeout 在请求新的执行程序之前,必须积压待处理任务的时间长度。
默认: 1个 s。
sparkstream和动态分配
从CDH 5.5开始,默认情况下启用动态分配,这意味着在空闲时将删除执行程序。动态分配与Spark Streaming操作冲突。
在Spark Streaming中,数据是成批进入的,只要有可用数据,执行程序就会运行。如果执行程序空闲超时小于批处理持续时间,则会不断添加和删除执行程序。但是,如果执行程序空闲超时大于批处理持续时间,则永远不会删除执行程序。因此,Cloudera建议您通过设置禁用动态分配 spark.dynamicAllocation.enabled 到 错误的 运行流应用程序时。
在非托管CDH部署中优化YARN模式
在不受Cloudera Manager管理的CDH部署中,每次运行时,Spark都会将Spark程序集JAR文件复制到HDFS 火花提交。您可以通过执行以下任一操作来避免这种复制:
spark.yarn.jar=local:/usr/lib/spark/lib/spark-assembly.jar
hdfs dfs -mkdir -p /user/spark/share/lib
Hdfs dfs -put SPARK_HOME/assembly/lib/spark-assembly_*.jar /user/spark/share/lib/spark-assembly.jar
spark.yarn.jar=hdfs://namenode:8020/user/spark/share/lib/spark-assembly.jar
Hive
为了充分利用可用的执行程序,您必须同时(并行)运行足够的任务。在大多数情况下,Hive会自动为您确定并行性,但是您可能会在并发调整方面有所控制。在输入端,映射任务的数量等于输入格式生成的分割的数量。对于Hive on Spark,输入格式为CombineHiveInputFormat,可以根据需要对基础输入格式生成的拆分进行分组。您可以在舞台边界处更好地控制并行性。调整 hive.exec.reducers.bytes.per.reducer以控制每个reducer处理多少数据,Hive根据可用的执行程序,执行程序内存设置,为属性设置的值和其他因素确定最佳分区数。实验表明,对于指定的值,Spark不如MapReduce敏感hive.exec.reducers.bytes.per.reducer,只要生成足够多的任务以使所有可用执行者都忙。为了获得最佳性能,请为该属性选择一个值,以便Hive生成足够的任务以完全使用所有可用的执行程序
hive.auto.convert.join.noconditionaltask.size=更大的值
基于统计信息的普通联接转换为 map join的阈值
数据大小由两个统计数据描述:
totalSize—磁盘上数据的大概大小
rawDataSize—内存中数据的大概大小
Hive在MapReduce上的用途 totalSize。当两者均可用时,Hive on Spark使用rawDataSize。由于压缩和序列化,两者之间的差异很大totalSize 和 rawDataSize对于同一数据集可能会发生
hive.stats.collect.rawdatasize=true
hive.stats.fetch.column.stats = true
hive.optimize.index.filter = true
hive.optimize.reducededuplication.min.reducer = 4
hive.optimize.reducededuplication = true
hive.merge.mapfiles = true
hive.merge.mapredfiles = false
hive.merge.smallfiles.avgsize = 16000000
hive.merge.size.per.task =
256000000 hive.merge.sparkfiles = true
hive.auto.convert.join = true
hive.auto.convert.join.noconditionaltask = true
hive.auto.convert.join.noconditionaltask.size = 20M(对于Spark,可能需要增加, 200M)
hive.optimize.bucketmapjoin.sortedmerge = false
hive.map.aggr.hash.percentmemory = 0.5
hive.map.aggr = true
hive.optimize.sort.dynamic.partition = false
hive.stats.autogather = true
hive.stats .fetch.column.stats = true
hive.compute.query.using.stats = true
hive.limit.pushdown.memory.usage = 0.4(MR和Spark)
hive.optimize.index.filter = true
hive.exec.reducers.bytes.per.reducer = 67108864
hive .smbjoin.cache.rows = 10000
hive.fetch.task.conversion =更多
hive.fetch.task.conversion.threshold = 1073741824
hive.optimize.ppd = true