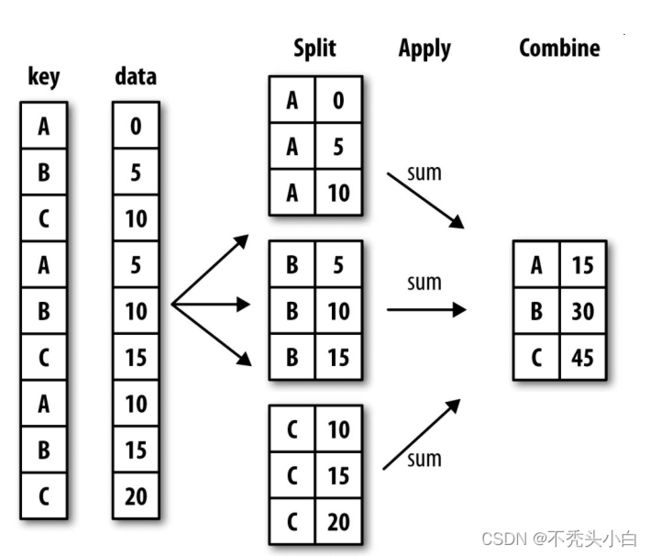
GroupBy机制
split-apply-combine(拆分-应用-合并)
import pandas as pd
import numpy as np
df=pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
|
key1 |
key2 |
data1 |
data2 |
| 0 |
a |
one |
1.067118 |
-0.237576 |
| 1 |
a |
two |
0.613814 |
1.059002 |
| 2 |
b |
one |
2.682089 |
0.865306 |
| 3 |
b |
two |
-0.331019 |
-1.627436 |
| 4 |
a |
one |
-0.599142 |
-0.615921 |
按照key1进行分组,并计算data1列的平均值:访问data1,并根据key1调用groupby
grouped=df['data1'].groupby(df['key1'])
grouped
变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df[‘key1’]的中间数据而已。该对象已经有了接下来对各分组执行运算所需的一切信息
grouped.mean()
key1
a 0.360597
b 1.175535
Name: data1, dtype: float64
means=df['data1'].groupby([df['key1'],df['key2']]).mean()
means
key1 key2
a one 0.233988
two 0.613814
b one 2.682089
two -0.331019
Name: data1, dtype: float64
means.unstack()
| key2 |
one |
two |
| key1 |
|
|
| a |
0.233988 |
0.613814 |
| b |
2.682089 |
-0.331019 |
分组键可以是任何长度适当的数组
states=np.array(['Ohio','California','California','Ohio','Ohio'])
years=np.array([2005,2005,2006,2005,2006])
df['data1'].groupby([states,years]).mean()
California 2005 0.613814
2006 2.682089
Ohio 2005 0.368050
2006 -0.599142
Name: data1, dtype: float64
通常,分组信息就位于相同的要处理DataFrame中。这里,你还可以将列名(可以
是字符串、数字或其他Python对象)用作分组键:
df.groupby('key1')
df.groupby(['key1','key2']).mean()
|
|
data1 |
data2 |
| key1 |
key2 |
|
|
| a |
one |
0.233988 |
-0.426748 |
| two |
0.613814 |
1.059002 |
| b |
one |
2.682089 |
0.865306 |
| two |
-0.331019 |
-1.627436 |
df.groupby(['key1','key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)
for name,group in df.groupby('key1'):
print(name)
print(group)
a
key1 key2 data1 data2
0 a one 1.067118 -0.237576
1 a two 0.613814 1.059002
4 a one -0.599142 -0.615921
b
key1 key2 data1 data2
2 b one 2.682089 0.865306
3 b two -0.331019 -1.627436
对于多重键的情况,元组的第一个元素将会由键值组成的元组
for (k1,k2),group in df.groupby(['key1','key2']):
print((k1,k2))
print(group)
('a', 'one')
key1 key2 data1 data2
0 a one 1.067118 -0.237576
4 a one -0.599142 -0.615921
('a', 'two')
key1 key2 data1 data2
1 a two 0.613814 1.059002
('b', 'one')
key1 key2 data1 data2
2 b one 2.682089 0.865306
('b', 'two')
key1 key2 data1 data2
3 b two -0.331019 -1.627436
你可以对这些数据片段做任何操作。将这些数据片段做成一个字典
pieces=dict(list(df.groupby('key1')))
pieces
{'a': key1 key2 data1 data2
0 a one 1.067118 -0.237576
1 a two 0.613814 1.059002
4 a one -0.599142 -0.615921,
'b': key1 key2 data1 data2
2 b one 2.682089 0.865306
3 b two -0.331019 -1.627436}
groupby默认是在axis=0上进行分组的,通过设置可以在其他任何轴上进行分组
df.dtypes
key1 object
key2 object
data1 float64
data2 float64
dtype: object
grouped=df.groupby(df.dtypes,axis=1)
grouped
for dtype,group in grouped:
print(dtype)
print(group)
float64
data1 data2
0 1.067118 -0.237576
1 0.613814 1.059002
2 2.682089 0.865306
3 -0.331019 -1.627436
4 -0.599142 -0.615921
object
key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
选取一列或列的子集
对于DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的
df.groupby('key1')['data1']
df.groupby('key1')[['data2']]
df['data1'].groupby(df['key1'])
df[['data2']].groupby(df['key1'])
对于大数据集,很可能只需要对部分列进行聚合
df.groupby(['key1','key2'])[['data2']].mean()
|
|
data2 |
| key1 |
key2 |
|
| a |
one |
-0.426748 |
| two |
1.059002 |
| b |
one |
0.865306 |
| two |
-1.627436 |
上述索引操作返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列名)
s_grouped=df.groupby(['key1','key2'])['data2']
s_grouped
s_grouped.mean()
key1 key2
a one -0.426748
two 1.059002
b one 0.865306
two -1.627436
Name: data2, dtype: float64
通过字典或Series进行分组
people=pd.DataFrame(np.random.randn(5,5),
columns=['a','b','c','d','e'],
index=['Joe','Steve','Wes','Jim','Travis'])
people.iloc[2:3,[1,2]]=np.nan
people
|
a |
b |
c |
d |
e |
| Joe |
1.064395 |
0.458101 |
-0.647722 |
0.913158 |
0.266544 |
| Steve |
0.464769 |
-0.152126 |
0.692518 |
0.800796 |
0.020842 |
| Wes |
0.534295 |
NaN |
NaN |
1.031494 |
1.019269 |
| Jim |
0.485397 |
0.930118 |
-0.124346 |
0.447506 |
0.761696 |
| Travis |
-0.108946 |
2.500092 |
1.173428 |
0.467239 |
1.579619 |
假设已知列的分组关系,希望根据分组计算列的和
mapping={'a': 'red',
'b': 'red',
'c': 'blue',
'd': 'blue',
'e': 'red',
'f' : 'orange'}
将这个字典传给gruopby,来构造数组,但我们可以直接传递字典
by_column=people.groupby(mapping,axis=1)
by_column.sum()
|
blue |
red |
| Joe |
0.265436 |
1.789040 |
| Steve |
1.493315 |
0.333485 |
| Wes |
1.031494 |
1.553564 |
| Jim |
0.323159 |
2.177211 |
| Travis |
1.640667 |
3.970764 |
map_series=pd.Series(mapping)
map_series
a red
b red
c blue
d blue
e red
f orange
dtype: object
people.groupby(map_series,axis=1).count()
|
blue |
red |
| Joe |
2 |
3 |
| Steve |
2 |
3 |
| Wes |
1 |
2 |
| Jim |
2 |
3 |
| Travis |
2 |
3 |
通过函数进行分组
people.groupby(len).sum()
|
a |
b |
c |
d |
e |
| 3 |
2.084087 |
1.388219 |
-0.772069 |
2.392158 |
2.047509 |
| 5 |
0.464769 |
-0.152126 |
0.692518 |
0.800796 |
0.020842 |
| 6 |
-0.108946 |
2.500092 |
1.173428 |
0.467239 |
1.579619 |
将函数跟数组、列表、字典、Series混合使用也可以,因为任何东西在内部都会被转换成数组
key_list=['one','one','one','two','two']
people.groupby([len,key_list]).min()
|
|
a |
b |
c |
d |
e |
| 3 |
one |
0.534295 |
0.458101 |
-0.647722 |
0.913158 |
0.266544 |
| two |
0.485397 |
0.930118 |
-0.124346 |
0.447506 |
0.761696 |
| 5 |
one |
0.464769 |
-0.152126 |
0.692518 |
0.800796 |
0.020842 |
| 6 |
two |
-0.108946 |
2.500092 |
1.173428 |
0.467239 |
1.579619 |
根据索引级别分组
层次化索引数据集最方便的地方在于它能根据轴索引的一个级别进行聚合
columns=pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],
[1,3,5,1,3]],
names=['city','tenor'])
hier_df=pd.DataFrame(np.random.randn(4,5),columns=columns)
hier_df
| city |
US |
JP |
| tenor |
1 |
3 |
5 |
1 |
3 |
| 0 |
-2.712569 |
0.036956 |
-0.643195 |
0.770231 |
-1.886666 |
| 1 |
-0.841508 |
1.772366 |
0.550501 |
0.237302 |
0.968424 |
| 2 |
-1.221179 |
-0.434443 |
-0.475438 |
0.666095 |
-0.083710 |
| 3 |
-0.519055 |
2.062299 |
1.077549 |
-1.361656 |
-1.274750 |
要根据级别分组,使用level关键字传递级别序号或名字
hier_df.groupby(level='city',axis=1).count()
| city |
JP |
US |
| 0 |
2 |
3 |
| 1 |
2 |
3 |
| 2 |
2 |
3 |
| 3 |
2 |
3 |
数据聚合
聚合指的是任何能够从数组产生标量值的数据转换过程
| 函数名 |
说明 |
| count |
分组中非NA值的数量 |
| sum |
非NA值的和 |
| mean |
非NA值的平均值 |
| median |
非NA值的算数平均中位数 |
| std、var |
无偏(分母为n-1)标准差和方差 |
| min、max |
非NA值的最小值和最大值 |
| prod |
非NA值的积 |
| first、last |
第一个和最后一个非NA值 |
quantile计算Series或DataFrame列的样本分位数
df
|
key1 |
key2 |
data1 |
data2 |
| 0 |
a |
one |
1.067118 |
-0.237576 |
| 1 |
a |
two |
0.613814 |
1.059002 |
| 2 |
b |
one |
2.682089 |
0.865306 |
| 3 |
b |
two |
-0.331019 |
-1.627436 |
| 4 |
a |
one |
-0.599142 |
-0.615921 |
grouped=df.groupby(['key1','key2'])
grouped['data1'].quantile(0.9)
key1 key2
a one 0.900492
two 0.613814
b one 2.682089
two -0.331019
Name: data1, dtype: float64
如果要使用自己的聚合函数,只需将其传入aggregate或agg方法
def peak_to_peak(arr):
return arr.max()-arr.min()
grouped.agg(peak_to_peak)
|
|
data1 |
data2 |
| key1 |
key2 |
|
|
| a |
one |
1.66626 |
0.378344 |
| two |
0.00000 |
0.000000 |
| b |
one |
0.00000 |
0.000000 |
| two |
0.00000 |
0.000000 |
grouped.describe()
|
|
data1 |
data2 |
|
|
count |
mean |
std |
min |
25% |
50% |
75% |
max |
count |
mean |
std |
min |
25% |
50% |
75% |
max |
| key1 |
key2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| a |
one |
2.0 |
0.233988 |
1.178224 |
-0.599142 |
-0.182577 |
0.233988 |
0.650553 |
1.067118 |
2.0 |
-0.426748 |
0.26753 |
-0.615921 |
-0.521335 |
-0.426748 |
-0.332162 |
-0.237576 |
| two |
1.0 |
0.613814 |
NaN |
0.613814 |
0.613814 |
0.613814 |
0.613814 |
0.613814 |
1.0 |
1.059002 |
NaN |
1.059002 |
1.059002 |
1.059002 |
1.059002 |
1.059002 |
| b |
one |
1.0 |
2.682089 |
NaN |
2.682089 |
2.682089 |
2.682089 |
2.682089 |
2.682089 |
1.0 |
0.865306 |
NaN |
0.865306 |
0.865306 |
0.865306 |
0.865306 |
0.865306 |
| two |
1.0 |
-0.331019 |
NaN |
-0.331019 |
-0.331019 |
-0.331019 |
-0.331019 |
-0.331019 |
1.0 |
-1.627436 |
NaN |
-1.627436 |
-1.627436 |
-1.627436 |
-1.627436 |
-1.627436 |
面向列的多函数应用
tips=pd.read_csv("F:/项目学习/利用Pyhon进行数据分析(第二版)/利用Pyhon进行数据分析/pydata-book-2nd-edition/examples/tips.csv")
tips.head()
|
total_bill |
tip |
smoker |
day |
time |
size |
| 0 |
16.99 |
1.01 |
No |
Sun |
Dinner |
2 |
| 1 |
10.34 |
1.66 |
No |
Sun |
Dinner |
3 |
| 2 |
21.01 |
3.50 |
No |
Sun |
Dinner |
3 |
| 3 |
23.68 |
3.31 |
No |
Sun |
Dinner |
2 |
| 4 |
24.59 |
3.61 |
No |
Sun |
Dinner |
4 |
tips['tip_pct']=tips['tip']/tips['total_bill']
tips.head()
|
total_bill |
tip |
smoker |
day |
time |
size |
tip_pct |
| 0 |
16.99 |
1.01 |
No |
Sun |
Dinner |
2 |
0.059447 |
| 1 |
10.34 |
1.66 |
No |
Sun |
Dinner |
3 |
0.160542 |
| 2 |
21.01 |
3.50 |
No |
Sun |
Dinner |
3 |
0.166587 |
| 3 |
23.68 |
3.31 |
No |
Sun |
Dinner |
2 |
0.139780 |
| 4 |
24.59 |
3.61 |
No |
Sun |
Dinner |
4 |
0.146808 |
grouped=tips.groupby(['day','smoker'])
grouped_pct=grouped['tip_pct']
grouped_pct.agg('mean')
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
如果传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名
grouped_pct.agg(['mean','std',peak_to_peak])
|
|
mean |
std |
peak_to_peak |
| day |
smoker |
|
|
|
| Fri |
No |
0.151650 |
0.028123 |
0.067349 |
| Yes |
0.174783 |
0.051293 |
0.159925 |
| Sat |
No |
0.158048 |
0.039767 |
0.235193 |
| Yes |
0.147906 |
0.061375 |
0.290095 |
| Sun |
No |
0.160113 |
0.042347 |
0.193226 |
| Yes |
0.187250 |
0.154134 |
0.644685 |
| Thur |
No |
0.160298 |
0.038774 |
0.193350 |
| Yes |
0.163863 |
0.039389 |
0.151240 |
如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作DataFrame的列名
grouped_pct.agg([('foo','mean'),('bar',np.std)])
|
|
foo |
bar |
| day |
smoker |
|
|
| Fri |
No |
0.151650 |
0.028123 |
| Yes |
0.174783 |
0.051293 |
| Sat |
No |
0.158048 |
0.039767 |
| Yes |
0.147906 |
0.061375 |
| Sun |
No |
0.160113 |
0.042347 |
| Yes |
0.187250 |
0.154134 |
| Thur |
No |
0.160298 |
0.038774 |
| Yes |
0.163863 |
0.039389 |
可以定义一组应用于全部列的一组函数,或不同列应用于不同的函数。
functions=['count','mean','max']
result=grouped[['tip_pct','total_bill']].agg(functions)
result
|
|
tip_pct |
total_bill |
|
|
count |
mean |
max |
count |
mean |
max |
| day |
smoker |
|
|
|
|
|
|
| Fri |
No |
4 |
0.151650 |
0.187735 |
4 |
18.420000 |
22.75 |
| Yes |
15 |
0.174783 |
0.263480 |
15 |
16.813333 |
40.17 |
| Sat |
No |
45 |
0.158048 |
0.291990 |
45 |
19.661778 |
48.33 |
| Yes |
42 |
0.147906 |
0.325733 |
42 |
21.276667 |
50.81 |
| Sun |
No |
57 |
0.160113 |
0.252672 |
57 |
20.506667 |
48.17 |
| Yes |
19 |
0.187250 |
0.710345 |
19 |
24.120000 |
45.35 |
| Thur |
No |
45 |
0.160298 |
0.266312 |
45 |
17.113111 |
41.19 |
| Yes |
17 |
0.163863 |
0.241255 |
17 |
19.190588 |
43.11 |
result['tip_pct']
|
|
count |
mean |
max |
| day |
smoker |
|
|
|
| Fri |
No |
4 |
0.151650 |
0.187735 |
| Yes |
15 |
0.174783 |
0.263480 |
| Sat |
No |
45 |
0.158048 |
0.291990 |
| Yes |
42 |
0.147906 |
0.325733 |
| Sun |
No |
57 |
0.160113 |
0.252672 |
| Yes |
19 |
0.187250 |
0.710345 |
| Thur |
No |
45 |
0.160298 |
0.266312 |
| Yes |
17 |
0.163863 |
0.241255 |
ftuples = [('Durchschnitt', 'mean'),('Abweichung', np.var)]
grouped[['tip_pct', 'total_bill']].agg(ftuples)
|
|
tip_pct |
total_bill |
|
|
Durchschnitt |
Abweichung |
Durchschnitt |
Abweichung |
| day |
smoker |
|
|
|
|
| Fri |
No |
0.151650 |
0.000791 |
18.420000 |
25.596333 |
| Yes |
0.174783 |
0.002631 |
16.813333 |
82.562438 |
| Sat |
No |
0.158048 |
0.001581 |
19.661778 |
79.908965 |
| Yes |
0.147906 |
0.003767 |
21.276667 |
101.387535 |
| Sun |
No |
0.160113 |
0.001793 |
20.506667 |
66.099980 |
| Yes |
0.187250 |
0.023757 |
24.120000 |
109.046044 |
| Thur |
No |
0.160298 |
0.001503 |
17.113111 |
59.625081 |
| Yes |
0.163863 |
0.001551 |
19.190588 |
69.808518 |
对一个列或不同的列应用不同的函数,具体的办法是向agg传入一个从列名映射到函数的字典
grouped.agg({'tip':np.max,'size':'sum'})
|
|
tip |
size |
| day |
smoker |
|
|
| Fri |
No |
3.50 |
9 |
| Yes |
4.73 |
31 |
| Sat |
No |
9.00 |
115 |
| Yes |
10.00 |
104 |
| Sun |
No |
6.00 |
167 |
| Yes |
6.50 |
49 |
| Thur |
No |
6.70 |
112 |
| Yes |
5.00 |
40 |
只有将多个函数应用到至少一列时,DataFrame才会有层次化
grouped.agg({'tip_pct':['min','max','mean','std'],'size':'sum'})
|
|
tip_pct |
size |
|
|
min |
max |
mean |
std |
sum |
| day |
smoker |
|
|
|
|
|
| Fri |
No |
0.120385 |
0.187735 |
0.151650 |
0.028123 |
9 |
| Yes |
0.103555 |
0.263480 |
0.174783 |
0.051293 |
31 |
| Sat |
No |
0.056797 |
0.291990 |
0.158048 |
0.039767 |
115 |
| Yes |
0.035638 |
0.325733 |
0.147906 |
0.061375 |
104 |
| Sun |
No |
0.059447 |
0.252672 |
0.160113 |
0.042347 |
167 |
| Yes |
0.065660 |
0.710345 |
0.187250 |
0.154134 |
49 |
| Thur |
No |
0.072961 |
0.266312 |
0.160298 |
0.038774 |
112 |
| Yes |
0.090014 |
0.241255 |
0.163863 |
0.039389 |
40 |
以没有行索引的形式返回依聚合数据
所有示例中的聚合数据都有唯一的分组键组成的索引(可能是层次化)。可以向groupby传入as_index=False禁用该功能
tips.info()
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 smoker 244 non-null object
3 day 244 non-null object
4 time 244 non-null object
5 size 244 non-null int64
6 tip_pct 244 non-null float64
dtypes: float64(3), int64(1), object(3)
memory usage: 13.5+ KB
num_col=tips.select_dtypes(include=['int64','float64'])
num_col
|
total_bill |
tip |
size |
tip_pct |
| 0 |
16.99 |
1.01 |
2 |
0.059447 |
| 1 |
10.34 |
1.66 |
3 |
0.160542 |
| 2 |
21.01 |
3.50 |
3 |
0.166587 |
| 3 |
23.68 |
3.31 |
2 |
0.139780 |
| 4 |
24.59 |
3.61 |
4 |
0.146808 |
| ... |
... |
... |
... |
... |
| 239 |
29.03 |
5.92 |
3 |
0.203927 |
| 240 |
27.18 |
2.00 |
2 |
0.073584 |
| 241 |
22.67 |
2.00 |
2 |
0.088222 |
| 242 |
17.82 |
1.75 |
2 |
0.098204 |
| 243 |
18.78 |
3.00 |
2 |
0.159744 |
244 rows × 4 columns
tips
|
total_bill |
tip |
smoker |
day |
time |
size |
tip_pct |
| 0 |
16.99 |
1.01 |
No |
Sun |
Dinner |
2 |
0.059447 |
| 1 |
10.34 |
1.66 |
No |
Sun |
Dinner |
3 |
0.160542 |
| 2 |
21.01 |
3.50 |
No |
Sun |
Dinner |
3 |
0.166587 |
| 3 |
23.68 |
3.31 |
No |
Sun |
Dinner |
2 |
0.139780 |
| 4 |
24.59 |
3.61 |
No |
Sun |
Dinner |
4 |
0.146808 |
| ... |
... |
... |
... |
... |
... |
... |
... |
| 239 |
29.03 |
5.92 |
No |
Sat |
Dinner |
3 |
0.203927 |
| 240 |
27.18 |
2.00 |
Yes |
Sat |
Dinner |
2 |
0.073584 |
| 241 |
22.67 |
2.00 |
Yes |
Sat |
Dinner |
2 |
0.088222 |
| 242 |
17.82 |
1.75 |
No |
Sat |
Dinner |
2 |
0.098204 |
| 243 |
18.78 |
3.00 |
No |
Thur |
Dinner |
2 |
0.159744 |
244 rows × 7 columns
tips_1=tips.drop('time',axis=1)
tips_1.groupby(['day','smoker']).mean()
|
|
total_bill |
tip |
size |
tip_pct |
| day |
smoker |
|
|
|
|
| Fri |
No |
18.420000 |
2.812500 |
2.250000 |
0.151650 |
| Yes |
16.813333 |
2.714000 |
2.066667 |
0.174783 |
| Sat |
No |
19.661778 |
3.102889 |
2.555556 |
0.158048 |
| Yes |
21.276667 |
2.875476 |
2.476190 |
0.147906 |
| Sun |
No |
20.506667 |
3.167895 |
2.929825 |
0.160113 |
| Yes |
24.120000 |
3.516842 |
2.578947 |
0.187250 |
| Thur |
No |
17.113111 |
2.673778 |
2.488889 |
0.160298 |
| Yes |
19.190588 |
3.030000 |
2.352941 |
0.163863 |
tips_1.groupby(['day','smoker'],as_index=False).mean()
|
day |
smoker |
total_bill |
tip |
size |
tip_pct |
| 0 |
Fri |
No |
18.420000 |
2.812500 |
2.250000 |
0.151650 |
| 1 |
Fri |
Yes |
16.813333 |
2.714000 |
2.066667 |
0.174783 |
| 2 |
Sat |
No |
19.661778 |
3.102889 |
2.555556 |
0.158048 |
| 3 |
Sat |
Yes |
21.276667 |
2.875476 |
2.476190 |
0.147906 |
| 4 |
Sun |
No |
20.506667 |
3.167895 |
2.929825 |
0.160113 |
| 5 |
Sun |
Yes |
24.120000 |
3.516842 |
2.578947 |
0.187250 |
| 6 |
Thur |
No |
17.113111 |
2.673778 |
2.488889 |
0.160298 |
| 7 |
Thur |
Yes |
19.190588 |
3.030000 |
2.352941 |
0.163863 |
apply:一般性的“拆分-应用-合并”
def top(df,n=5,column='tip_pct'):
return df.sort_values(by=column)[-n:]
top(tips,n=6)
|
total_bill |
tip |
smoker |
day |
time |
size |
tip_pct |
| 109 |
14.31 |
4.00 |
Yes |
Sat |
Dinner |
2 |
0.279525 |
| 183 |
23.17 |
6.50 |
Yes |
Sun |
Dinner |
4 |
0.280535 |
| 232 |
11.61 |
3.39 |
No |
Sat |
Dinner |
2 |
0.291990 |
| 67 |
3.07 |
1.00 |
Yes |
Sat |
Dinner |
1 |
0.325733 |
| 178 |
9.60 |
4.00 |
Yes |
Sun |
Dinner |
2 |
0.416667 |
| 172 |
7.25 |
5.15 |
Yes |
Sun |
Dinner |
2 |
0.710345 |
tips.groupby('smoker').apply(top)
|
|
total_bill |
tip |
smoker |
day |
time |
size |
tip_pct |
| smoker |
|
|
|
|
|
|
|
|
| No |
88 |
24.71 |
5.85 |
No |
Thur |
Lunch |
2 |
0.236746 |
| 185 |
20.69 |
5.00 |
No |
Sun |
Dinner |
5 |
0.241663 |
| 51 |
10.29 |
2.60 |
No |
Sun |
Dinner |
2 |
0.252672 |
| 149 |
7.51 |
2.00 |
No |
Thur |
Lunch |
2 |
0.266312 |
| 232 |
11.61 |
3.39 |
No |
Sat |
Dinner |
2 |
0.291990 |
| Yes |
109 |
14.31 |
4.00 |
Yes |
Sat |
Dinner |
2 |
0.279525 |
| 183 |
23.17 |
6.50 |
Yes |
Sun |
Dinner |
4 |
0.280535 |
| 67 |
3.07 |
1.00 |
Yes |
Sat |
Dinner |
1 |
0.325733 |
| 178 |
9.60 |
4.00 |
Yes |
Sun |
Dinner |
2 |
0.416667 |
| 172 |
7.25 |
5.15 |
Yes |
Sun |
Dinner |
2 |
0.710345 |
tips.groupby(['smoker','day']).apply(top,n=1,column='total_bill')
|
|
|
total_bill |
tip |
smoker |
day |
time |
size |
tip_pct |
| smoker |
day |
|
|
|
|
|
|
|
|
| No |
Fri |
94 |
22.75 |
3.25 |
No |
Fri |
Dinner |
2 |
0.142857 |
| Sat |
212 |
48.33 |
9.00 |
No |
Sat |
Dinner |
4 |
0.186220 |
| Sun |
156 |
48.17 |
5.00 |
No |
Sun |
Dinner |
6 |
0.103799 |
| Thur |
142 |
41.19 |
5.00 |
No |
Thur |
Lunch |
5 |
0.121389 |
| Yes |
Fri |
95 |
40.17 |
4.73 |
Yes |
Fri |
Dinner |
4 |
0.117750 |
| Sat |
170 |
50.81 |
10.00 |
Yes |
Sat |
Dinner |
3 |
0.196812 |
| Sun |
182 |
45.35 |
3.50 |
Yes |
Sun |
Dinner |
3 |
0.077178 |
| Thur |
197 |
43.11 |
5.00 |
Yes |
Thur |
Lunch |
4 |
0.115982 |
result=tips.groupby('smoker')['tip_pct'].describe()
result
|
count |
mean |
std |
min |
25% |
50% |
75% |
max |
| smoker |
|
|
|
|
|
|
|
|
| No |
151.0 |
0.159328 |
0.039910 |
0.056797 |
0.136906 |
0.155625 |
0.185014 |
0.291990 |
| Yes |
93.0 |
0.163196 |
0.085119 |
0.035638 |
0.106771 |
0.153846 |
0.195059 |
0.710345 |
result.unstack('smoker')
smoker
count No 151.000000
Yes 93.000000
mean No 0.159328
Yes 0.163196
std No 0.039910
Yes 0.085119
min No 0.056797
Yes 0.035638
25% No 0.136906
Yes 0.106771
50% No 0.155625
Yes 0.153846
75% No 0.185014
Yes 0.195059
max No 0.291990
Yes 0.710345
dtype: float64
在groupby中调用describe之类的函数,实际上是应用了下面两条代码的快捷方式:
f=lambda x:x.describe()
grouped.apply(f)
禁止分组键
分组键会跟原始对象的索引共同构成结果对象中的层次
化索引。将group_keys=False传入groupby即可禁止该效果
tips.groupby('smoker',group_keys=False).apply(top)
|
total_bill |
tip |
smoker |
day |
time |
size |
tip_pct |
| 88 |
24.71 |
5.85 |
No |
Thur |
Lunch |
2 |
0.236746 |
| 185 |
20.69 |
5.00 |
No |
Sun |
Dinner |
5 |
0.241663 |
| 51 |
10.29 |
2.60 |
No |
Sun |
Dinner |
2 |
0.252672 |
| 149 |
7.51 |
2.00 |
No |
Thur |
Lunch |
2 |
0.266312 |
| 232 |
11.61 |
3.39 |
No |
Sat |
Dinner |
2 |
0.291990 |
| 109 |
14.31 |
4.00 |
Yes |
Sat |
Dinner |
2 |
0.279525 |
| 183 |
23.17 |
6.50 |
Yes |
Sun |
Dinner |
4 |
0.280535 |
| 67 |
3.07 |
1.00 |
Yes |
Sat |
Dinner |
1 |
0.325733 |
| 178 |
9.60 |
4.00 |
Yes |
Sun |
Dinner |
2 |
0.416667 |
| 172 |
7.25 |
5.15 |
Yes |
Sun |
Dinner |
2 |
0.710345 |
分位数和桶分析
frame = pd.DataFrame({'data1': np.random.randn(1000),
'data2': np.random.randn(1000)})
quartiles = pd.cut(frame.data1, 4)
quartiles[:10]
0 (-0.0596, 1.69]
1 (-3.565, -1.809]
2 (-1.809, -0.0596]
3 (-0.0596, 1.69]
4 (-0.0596, 1.69]
5 (-0.0596, 1.69]
6 (-1.809, -0.0596]
7 (-1.809, -0.0596]
8 (-1.809, -0.0596]
9 (-1.809, -0.0596]
Name: data1, dtype: category
Categories (4, interval[float64, right]): [(-3.565, -1.809] < (-1.809, -0.0596] < (-0.0596, 1.69] < (1.69, 3.439]]
def get_stats(group):
return {'min':group.min(),'max':group.max(),'count':group.count(),'mean':group.mean()}
grouped=frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()
|
min |
max |
count |
mean |
| data1 |
|
|
|
|
| (-3.565, -1.809] |
-2.240036 |
2.383580 |
40.0 |
-0.147557 |
| (-1.809, -0.0596] |
-2.455718 |
3.207027 |
452.0 |
-0.016250 |
| (-0.0596, 1.69] |
-2.989626 |
3.232200 |
459.0 |
0.048823 |
| (1.69, 3.439] |
-1.774519 |
2.201069 |
49.0 |
0.054332 |
这些都是长度相等的桶。要根据样本分位数得到大小相等的桶,使用qcut。传入labels=False可只获得分位数的编号
grouping = pd.qcut(frame.data1, 10, labels=False)
grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()
|
min |
max |
count |
mean |
| data1 |
|
|
|
|
| 0 |
-2.240036 |
2.617873 |
100.0 |
-0.036513 |
| 1 |
-2.162690 |
3.207027 |
100.0 |
0.038019 |
| 2 |
-2.312058 |
1.901076 |
100.0 |
-0.052351 |
| 3 |
-2.297201 |
2.963489 |
100.0 |
-0.033958 |
| 4 |
-2.455718 |
3.178088 |
100.0 |
-0.083398 |
| 5 |
-2.989626 |
2.336623 |
100.0 |
0.110641 |
| 6 |
-2.269297 |
3.232200 |
100.0 |
0.074222 |
| 7 |
-2.115640 |
2.599014 |
100.0 |
0.070273 |
| 8 |
-2.387508 |
2.364138 |
100.0 |
-0.062957 |
| 9 |
-1.774519 |
2.333942 |
100.0 |
0.094271 |
示例:用特定于分组的值填充缺失值
对于缺失数据的清理工作,有时你会用dropna将其替换掉,而有时则可能会希望用
一个固定值或由数据集本身所衍生出来的值去填充NA值。这时就得使用fillna这个
工具
s = pd.Series(np.random.randn(6))
s
0 1.264682
1 0.495235
2 -0.016187
3 1.781491
4 -0.231563
5 -0.393924
dtype: float64
s[::2] = np.nan
s
0 NaN
1 0.495235
2 NaN
3 1.781491
4 NaN
5 -0.393924
dtype: float64
s.fillna(s.mean())
0 0.627601
1 0.495235
2 0.627601
3 1.781491
4 0.627601
5 -0.393924
dtype: float64
假设你需要对不同的分组填充不同的值。一种方法是将数据分组,并使用apply和一个能够对各数据块调用fillna的函数即可。
states = ['Ohio', 'New York', 'Vermont', 'Florida',
'Oregon', 'Nevada', 'California', 'Idaho']
group_key = ['East'] * 4 + ['West'] * 4
data = pd.Series(np.random.randn(8), index=states)
data
Ohio 1.045855
New York 1.075995
Vermont 0.425475
Florida 0.086684
Oregon -1.262191
Nevada -0.209671
California 0.120289
Idaho -0.564744
dtype: float64
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
data
Ohio 1.045855
New York 1.075995
Vermont NaN
Florida 0.086684
Oregon -1.262191
Nevada NaN
California 0.120289
Idaho NaN
dtype: float64
data.groupby(group_key).mean()
East 0.736178
West -0.570951
dtype: float64
我们可以用分组平均值去填充NA值
fill_mean=lambda g:g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
East Ohio 1.045855
New York 1.075995
Vermont 0.736178
Florida 0.086684
West Oregon -1.262191
Nevada -0.570951
California 0.120289
Idaho -0.570951
dtype: float64
也可以在代码中定义各组的填充值
fill_values={'East':0.5,'West':-1}
fill_func=lambda g:g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
East Ohio 1.045855
New York 1.075995
Vermont 0.500000
Florida 0.086684
West Oregon -1.262191
Nevada -1.000000
California 0.120289
Idaho -1.000000
dtype: float64
示例:随机采样和排列
假设你想要从一个大数据集中随机抽取(进行替换或不替换)样本以进行蒙特卡罗
模拟(Monte Carlo simulation)或其他分析工作。“抽取”的方式有很多,这里使用的方法是对Series使用sample方法
suits=['H','S','C','D']
card_val=(list(range(1,11))+[10]*3)*4
base_names=['A']+list(range(2,11))+['J','K','Q']
cards=[]
for suit in['H','S','C','D']:
cards.extend(str(num)+suit for num in base_names)
deck=pd.Series(card_val,index=cards)
deck
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
KH 10
QH 10
AS 1
2S 2
3S 3
4S 4
5S 5
6S 6
7S 7
8S 8
9S 9
10S 10
JS 10
KS 10
QS 10
AC 1
2C 2
3C 3
4C 4
5C 5
6C 6
7C 7
8C 8
9C 9
10C 10
JC 10
KC 10
QC 10
AD 1
2D 2
3D 3
4D 4
5D 5
6D 6
7D 7
8D 8
9D 9
10D 10
JD 10
KD 10
QD 10
dtype: int64
def draw(deck,n=5):
return deck.sample(n)
draw(deck)
10H 10
9H 9
6H 6
JC 10
QH 10
dtype: int64
想要从每种花色中随机抽取两张牌。由于花色是牌名的最后一个字符,所以
我们可以据此进行分组,并使用apply
get_suit=lambda card:card[-1]
deck.groupby(get_suit).apply(draw,n=2)
C 7C 7
KC 10
D 4D 4
AD 1
H 3H 3
8H 8
S KS 10
JS 10
dtype: int64
deck.groupby(get_suit,group_keys=False).apply(draw,n=2)
5C 5
4C 4
6D 6
4D 4
2H 2
5H 5
8S 8
3S 3
dtype: int64
示例:分组加权平均数和相关系数
df = pd.DataFrame({'category': ['a', 'a', 'a', 'a','b', 'b', 'b', 'b'],
'data': np.random.randn(8),
'weights': np.random.rand(8)})
df
|
category |
data |
weights |
| 0 |
a |
-1.022846 |
0.702148 |
| 1 |
a |
0.405966 |
0.095783 |
| 2 |
a |
0.282171 |
0.439928 |
| 3 |
a |
0.541287 |
0.866943 |
| 4 |
b |
0.695519 |
0.363663 |
| 5 |
b |
-0.419917 |
0.270279 |
| 6 |
b |
-0.077227 |
0.565714 |
| 7 |
b |
1.600511 |
0.636178 |
grouped=df.groupby('category')
get_wavg=lambda g:np.average(g['data'],weights=g['weights'])
grouped.apply(get_wavg)
category
a -0.040814
b 0.606788
dtype: float64
Yahoo!Finance的数据集,其中含有几只股票和标准普尔500指数(符号SPX)的收盘价
close_px=pd.read_csv('F:/项目学习/利用Pyhon进行数据分析(第二版)/利用Pyhon进行数据分析/pydata-book-2nd-edition/examples/stock_px_2.csv',parse_dates=True,index_col=0)
close_px.head()
|
AAPL |
MSFT |
XOM |
SPX |
| 2003-01-02 |
7.40 |
21.11 |
29.22 |
909.03 |
| 2003-01-03 |
7.45 |
21.14 |
29.24 |
908.59 |
| 2003-01-06 |
7.45 |
21.52 |
29.96 |
929.01 |
| 2003-01-07 |
7.43 |
21.93 |
28.95 |
922.93 |
| 2003-01-08 |
7.28 |
21.31 |
28.83 |
909.93 |
close_px.info()
DatetimeIndex: 2214 entries, 2003-01-02 to 2011-10-14
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AAPL 2214 non-null float64
1 MSFT 2214 non-null float64
2 XOM 2214 non-null float64
3 SPX 2214 non-null float64
dtypes: float64(4)
memory usage: 86.5 KB
close_px[-4:]
|
AAPL |
MSFT |
XOM |
SPX |
| 2011-10-11 |
400.29 |
27.00 |
76.27 |
1195.54 |
| 2011-10-12 |
402.19 |
26.96 |
77.16 |
1207.25 |
| 2011-10-13 |
408.43 |
27.18 |
76.37 |
1203.66 |
| 2011-10-14 |
422.00 |
27.27 |
78.11 |
1224.58 |
spx_corr=lambda x:x.corrwith(x['SPX'])
rets=close_px.pct_change().dropna()
rets
|
AAPL |
MSFT |
XOM |
SPX |
| 2003-01-03 |
0.006757 |
0.001421 |
0.000684 |
-0.000484 |
| 2003-01-06 |
0.000000 |
0.017975 |
0.024624 |
0.022474 |
| 2003-01-07 |
-0.002685 |
0.019052 |
-0.033712 |
-0.006545 |
| 2003-01-08 |
-0.020188 |
-0.028272 |
-0.004145 |
-0.014086 |
| 2003-01-09 |
0.008242 |
0.029094 |
0.021159 |
0.019386 |
| ... |
... |
... |
... |
... |
| 2011-10-10 |
0.051406 |
0.026286 |
0.036977 |
0.034125 |
| 2011-10-11 |
0.029526 |
0.002227 |
-0.000131 |
0.000544 |
| 2011-10-12 |
0.004747 |
-0.001481 |
0.011669 |
0.009795 |
| 2011-10-13 |
0.015515 |
0.008160 |
-0.010238 |
-0.002974 |
| 2011-10-14 |
0.033225 |
0.003311 |
0.022784 |
0.017380 |
2213 rows × 4 columns
get_year=lambda x:x.year
by_year=rets.groupby(get_year)
by_year.apply(spx_corr)
|
AAPL |
MSFT |
XOM |
SPX |
| 2003 |
0.541124 |
0.745174 |
0.661265 |
1.0 |
| 2004 |
0.374283 |
0.588531 |
0.557742 |
1.0 |
| 2005 |
0.467540 |
0.562374 |
0.631010 |
1.0 |
| 2006 |
0.428267 |
0.406126 |
0.518514 |
1.0 |
| 2007 |
0.508118 |
0.658770 |
0.786264 |
1.0 |
| 2008 |
0.681434 |
0.804626 |
0.828303 |
1.0 |
| 2009 |
0.707103 |
0.654902 |
0.797921 |
1.0 |
| 2010 |
0.710105 |
0.730118 |
0.839057 |
1.0 |
| 2011 |
0.691931 |
0.800996 |
0.859975 |
1.0 |
计算列与列之间的相关系数
by_year.apply(lambda g:g['AAPL'].corr(g['MSFT']))
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64
示例:组级别的线性回归
import statsmodels.api as sm
def regress(data,yvar,xvars):
Y=data[yvar]
X=data[xvars]
X['intercept']=1
result=sm.OLS(Y,X).fit()
return result.params
by_year.apply(regress,'AAPL',['SPX'])
|
SPX |
intercept |
| 2003 |
1.195406 |
0.000710 |
| 2004 |
1.363463 |
0.004201 |
| 2005 |
1.766415 |
0.003246 |
| 2006 |
1.645496 |
0.000080 |
| 2007 |
1.198761 |
0.003438 |
| 2008 |
0.968016 |
-0.001110 |
| 2009 |
0.879103 |
0.002954 |
| 2010 |
1.052608 |
0.001261 |
| 2011 |
0.806605 |
0.001514 |
透视表和交叉表
透视表
tips_1.pivot_table(index=['day','smoker'])
|
|
size |
tip |
tip_pct |
total_bill |
| day |
smoker |
|
|
|
|
| Fri |
No |
2.250000 |
2.812500 |
0.151650 |
18.420000 |
| Yes |
2.066667 |
2.714000 |
0.174783 |
16.813333 |
| Sat |
No |
2.555556 |
3.102889 |
0.158048 |
19.661778 |
| Yes |
2.476190 |
2.875476 |
0.147906 |
21.276667 |
| Sun |
No |
2.929825 |
3.167895 |
0.160113 |
20.506667 |
| Yes |
2.578947 |
3.516842 |
0.187250 |
24.120000 |
| Thur |
No |
2.488889 |
2.673778 |
0.160298 |
17.113111 |
| Yes |
2.352941 |
3.030000 |
0.163863 |
19.190588 |
tips.pivot_table(['tip_pct','size'],index=['time','day'],columns='smoker')
|
|
size |
tip_pct |
|
smoker |
No |
Yes |
No |
Yes |
| time |
day |
|
|
|
|
| Dinner |
Fri |
2.000000 |
2.222222 |
0.139622 |
0.165347 |
| Sat |
2.555556 |
2.476190 |
0.158048 |
0.147906 |
| Sun |
2.929825 |
2.578947 |
0.160113 |
0.187250 |
| Thur |
2.000000 |
NaN |
0.159744 |
NaN |
| Lunch |
Fri |
3.000000 |
1.833333 |
0.187735 |
0.188937 |
| Thur |
2.500000 |
2.352941 |
0.160311 |
0.163863 |
传入margins=True添加分项小计。这将会添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计
tips.pivot_table(['tip_pct','size'],index=['time','day'],columns='smoker',margins=True)
|
|
size |
tip_pct |
|
smoker |
No |
Yes |
All |
No |
Yes |
All |
| time |
day |
|
|
|
|
|
|
| Dinner |
Fri |
2.000000 |
2.222222 |
2.166667 |
0.139622 |
0.165347 |
0.158916 |
| Sat |
2.555556 |
2.476190 |
2.517241 |
0.158048 |
0.147906 |
0.153152 |
| Sun |
2.929825 |
2.578947 |
2.842105 |
0.160113 |
0.187250 |
0.166897 |
| Thur |
2.000000 |
NaN |
2.000000 |
0.159744 |
NaN |
0.159744 |
| Lunch |
Fri |
3.000000 |
1.833333 |
2.000000 |
0.187735 |
0.188937 |
0.188765 |
| Thur |
2.500000 |
2.352941 |
2.459016 |
0.160311 |
0.163863 |
0.161301 |
| All |
|
2.668874 |
2.408602 |
2.569672 |
0.159328 |
0.163196 |
0.160803 |
All值为平均数:不单独考虑烟民与非烟民(All列),不单独考虑行分组两个
级别中的任何单项(All行)
要使用其他的聚合函数,将其传给aggfunc即可。例如,使用count或len可以得到有关分组大小的交叉表(计数或频率)
tips.pivot_table('tip_pct', index=['time', 'smoker'],columns='day',aggfunc=len, margins=True)
|
day |
Fri |
Sat |
Sun |
Thur |
All |
| time |
smoker |
|
|
|
|
|
| Dinner |
No |
3.0 |
45.0 |
57.0 |
1.0 |
106 |
| Yes |
9.0 |
42.0 |
19.0 |
NaN |
70 |
| Lunch |
No |
1.0 |
NaN |
NaN |
44.0 |
45 |
| Yes |
6.0 |
NaN |
NaN |
17.0 |
23 |
| All |
|
19.0 |
87.0 |
76.0 |
62.0 |
244 |
tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'],columns='day', aggfunc='mean', fill_value=0)
|
|
day |
Fri |
Sat |
Sun |
Thur |
| time |
size |
smoker |
|
|
|
|
| Dinner |
1 |
No |
0.000000 |
0.137931 |
0.000000 |
0.000000 |
| Yes |
0.000000 |
0.325733 |
0.000000 |
0.000000 |
| 2 |
No |
0.139622 |
0.162705 |
0.168859 |
0.159744 |
| Yes |
0.171297 |
0.148668 |
0.207893 |
0.000000 |
| 3 |
No |
0.000000 |
0.154661 |
0.152663 |
0.000000 |
| Yes |
0.000000 |
0.144995 |
0.152660 |
0.000000 |
| 4 |
No |
0.000000 |
0.150096 |
0.148143 |
0.000000 |
| Yes |
0.117750 |
0.124515 |
0.193370 |
0.000000 |
| 5 |
No |
0.000000 |
0.000000 |
0.206928 |
0.000000 |
| Yes |
0.000000 |
0.106572 |
0.065660 |
0.000000 |
| 6 |
No |
0.000000 |
0.000000 |
0.103799 |
0.000000 |
| Lunch |
1 |
No |
0.000000 |
0.000000 |
0.000000 |
0.181728 |
| Yes |
0.223776 |
0.000000 |
0.000000 |
0.000000 |
| 2 |
No |
0.000000 |
0.000000 |
0.000000 |
0.166005 |
| Yes |
0.181969 |
0.000000 |
0.000000 |
0.158843 |
| 3 |
No |
0.187735 |
0.000000 |
0.000000 |
0.084246 |
| Yes |
0.000000 |
0.000000 |
0.000000 |
0.204952 |
| 4 |
No |
0.000000 |
0.000000 |
0.000000 |
0.138919 |
| Yes |
0.000000 |
0.000000 |
0.000000 |
0.155410 |
| 5 |
No |
0.000000 |
0.000000 |
0.000000 |
0.121389 |
| 6 |
No |
0.000000 |
0.000000 |
0.000000 |
0.173706 |
pivot_table参数说明
| 函数名 |
说明 |
| values |
待聚合的列的名称。默认聚合所有数值列 |
| index |
用于分组的列名或其他分组键,出现在结果透视表的行 |
| columns |
用于分组的列名或其他分组键,出现在结果透视表的列 |
| aggfunc |
聚合函数或函数列表,默认mean。可以是任何对groupby有效的函数 |
| fill_value |
用于替换表中的缺失值 |
| dropna |
如果为True,不添加条目都为NA的列 |
| margins |
添加行/列小计和总计,默认为False |
交叉表:crosstab
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表。
data=pd.DataFrame({'Sample':np.arange(1,11),
'Nationality':['USA','Japan','USA','Japan','Japan','Japan','USA','USA','Japan','USA'],
'Handedness':['Right-handed',' Left-handed','Right-handed','Right-handed',' Left-handed','Right-handed','Right-handed','Left-handed','Right-handed','Right-handed']
})
data
|
Sample |
Nationality |
Handedness |
| 0 |
1 |
USA |
Right-handed |
| 1 |
2 |
Japan |
Left-handed |
| 2 |
3 |
USA |
Right-handed |
| 3 |
4 |
Japan |
Right-handed |
| 4 |
5 |
Japan |
Left-handed |
| 5 |
6 |
Japan |
Right-handed |
| 6 |
7 |
USA |
Right-handed |
| 7 |
8 |
USA |
Left-handed |
| 8 |
9 |
Japan |
Right-handed |
| 9 |
10 |
USA |
Right-handed |
pd.crosstab(data.Nationality, data.Handedness, margins=True)
| Handedness |
Left-handed |
Left-handed |
Right-handed |
All |
| Nationality |
|
|
|
|
| Japan |
2 |
0 |
3 |
5 |
| USA |
0 |
1 |
4 |
5 |
| All |
2 |
1 |
7 |
10 |
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)
|
smoker |
No |
Yes |
All |
| time |
day |
|
|
|
| Dinner |
Fri |
3 |
9 |
12 |
| Sat |
45 |
42 |
87 |
| Sun |
57 |
19 |
76 |
| Thur |
1 |
0 |
1 |
| Lunch |
Fri |
1 |
6 |
7 |
| Thur |
44 |
17 |
61 |
| All |
|
151 |
93 |
244 |