深度学习之CNN深度卷积神经网络-VGG(进阶)

前言
本文主要CNN系列论文解读——VGG的简介、模型结构、参数计算、网络结构的代码实现等。
1.简介
VGGNet 是牛津大学计算机视觉组(Visual Geometry Group)和谷歌 DeepMind 一起研究出来的深度卷积神经网络,因而冠名为 VGG。VGG是一种被广泛使用的卷积神经网络结构,其在在2014年的 ImageNet 大规模视觉识别挑战(ILSVRC -2014)中获得了亚军,不是VGG不够强,而是对手太强,因为当年获得冠军的是GoogLeNet。
通常人们说的VGG是指VGG-16(13层卷积层+ 3层全连接层)。虽然其屈居亚军,但是由于其规律的设计、简洁可堆叠的卷积块,且在其他数据集上都有着很好的表现,从而被人们广泛使用,从这点上还是超过了GoogLenet。VGG和之前的AlexNet相比,深度更深,参数更多(1.38亿),效果和可移植性更好。
2.Abstract
Abstract
In this work we investigate the effect of the convolutional network depth on itsaccuracy in the large-scale image recognition setting. Ourmain contribution isa thorough evaluation of networks of increasing depth usingan architecture withvery small (3×3) convolution filters, which shows that a significant improvementon the prior-art configurations can be achieved by pushing the depth to 16–19weight layers. These findings were the basis of our ImageNet Challenge 2014submission, where our team secured the first and the second places in the localisa-tion and classification tracks respectively. We also show that our representationsgeneralise well to other datasets, where they achieve state-of-the-art results. Wehave made our two best-performing ConvNet models publicly available to facili-tate further research on the use of deep visual representations in computer vision.
翻译
在这项工作中,我们研究了卷积网络深度对其在大规模图像识别设置中的准确性的影响。我们的主要贡献是使用一个非常小的(3×3)卷积filter的架构对增加深度的网络进行了彻底的评估,这表明通过将深度提升到16 - 19个weight层,可以显著改善先前的配置。这些发现是我们提交ImageNet挑战赛2014的基础,我们的团队分别获得了本地化和分类的第一名和第二名。我们还展示了我们的成果可以很好地推广到其他数据集,在这些数据集上他们可以得到最优结果。我们已经公开了两个性能最好的卷积神经网络模型,以促进在计算机视觉中使用深度视觉表示的进一步研究。
3.网络结构
3.1 示意图
VGGNet以下6种不同结构,我们以通常所说的VGG-16(即下图D列)为例,展示其结构示意图

其中conv3-256表示:这是一个卷积层,卷积核尺寸为3(感受野尺寸),通道数为256。
VGG-16示意图

可见,整个网络有5个vgg-block块和5个maxpool层逐个相连,然后进入FC层,直到最后1000路softmax输出。
3.2 VGG特点
- vgg-block内的卷积层都是同结构的
- 池化层都得上一层的卷积层特征缩减一半
- 深度较深,参数量够大
- 较小的filter size/kernel size
1.vgg-block内的卷积层都是同结构的 意味着输入和输出的尺寸一样,且卷积层可以堆叠复用,其中的实现是通过统一的size为3×3的kernel size + stride1 + padding(same)实现。
2.maxpool层将前一层(vgg-block层)的特征缩减一半 使得尺寸缩减的很规整,从224-112-56-28-14-7。其中是通过pool size2 + stride2实现
3.深度较深,参数量够大 较深的网络层数使得训练得到的模型分类效果优秀,但是较大的参数对训练和模型保存提出了更大的资源要求。
4.较小的filter size/kernel size 这里全局的kernel size都为3×3,相比以前的网络模型来说,尺寸足够小。
3.3 layer设计
多种VGG网络设计都很统一,都有相同的224×224×3的input+5个maxpool层+3层fc全连接层,区别在于中间的Vgg-block块的设计不同。 下面我们以D列中的VGG-16为例展示具体的layer设计:block和block之间通过maxpool的stride=2,pool size=2进行减半池化;block内部,为了保持卷积层间的shape一致,kernel size统一尺寸为3×3。
第1层输入层: 输入为224×224×3 三通道的图像。
第2层vgg block层:输入为224×224×3,经过64个kernel size为3×3×3的filter,stride = 1,padding=same卷积后得到shape为224×224×64的block层(指由conv构成的vgg-block)。
第3层Max-pooling层: 输入为224×224×64,经过pool size=2,stride=2的减半池化后得到尺寸为112×112×64的池化层
第4层vgg block层: 输入尺寸为112×112×64,经128个3×3×64的filter卷积,得到112×112×128的block层。
第5层Max-pooling层:输入为112×112×128,经pool size = 2,stride = 2减半池化后得到尺寸为56×56×128的池化层。
第6层vgg block层: 输入尺寸为56×56×128,经256个3×3×128的filter卷积,得到56×56×256的block层。
第7层Max-pooling层: 输入为56×56×256,经pool size = 2,stride = 2减半池化后得到尺寸为28×28×256的池化层。
第8层vgg block层:输入尺寸为28×28×256,经512个3×3×256的filter卷积,得到28×28×512的block层。
第9层Max-pooling层: 输入为28×28×512,经pool size = 2,stride = 2减半池化后得到尺寸为14×14×512的池化层。
第10层vgg block层: 输入尺寸为14×14×512,经512个3×3×512的filter卷积,得到14×14×512的block层。
第11层Max-pooling层: 输入为14×14×512,经pool size = 2,stride = 2减半池化后得到尺寸为7×7×512的池化层。该层后面还隐藏了flatten操作,通过展平得到7×7×512=25088个参数后与之后的全连接层相连。
第12~14层Dense层: 第12~14层神经元个数分别为4096,4096,1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类。
3.4 参数计算


4.论文解读
1.介绍
随着Krizhevsky等人在2012年发表的AlexNet,卷积神经网络在CV领域取得了巨大成功,越来越多的人在其原始架构上进行改进,譬如ILSVRC-2013上效果最好的作品中即选用了较小的感受野尺寸(kernel size较小)和较小的步幅stride;还有2014年的在整个图像上和多尺度下密集训练的网络...而本论文重点讨论了卷积神经网络架构的另一个重要方面:深度。为了使深度更深,作者将架构的其他参数进行了调整,譬如所有卷积层中filter size尺寸都设为很小的3×3,而将卷积层数量加大,使深度更深,事实证明是可行的。
VGG的架构不仅实现了ILSVRC分类和定位任务的最佳精度,而且还适用于其他图像识别数据集,即使仅作为前置部分(特征提取)也可以实现出色的性能。
2. 卷积神经网络配置
2.1 结构
在模型训练期间,作者所做的唯一预处理就是将输入的224×224×3通道的像素值,减去平均RGB值,然后进行训练,接着,图像输入进入堆叠的卷积层(vgg-block块)。使用了最小尺寸的fliter size 3×3,这个尺寸也是能捕捉上下左右和中间方位的最小尺寸。block块之间的卷积层stride固定为1且padding为1使得卷积层之间保持相同的尺寸。maxpooling层的特点是stride = 2,pool size尺寸2×2。 网络中全连接层的配置相同,都会通过ReLU进行修正。
VGG的网络结构中(除一个特例外)都不包含AlexNet中提及的LRN(局部响应正则化),因为作者发现其并不能提高性能,反而会带来内存消耗和计算时间的增加。
2.2 配置
所有的VGG结构都遵从2.1里的结构设计,只是其中block内部的卷积层不同。表1中介绍了从A~E六中网络结构的设计和配置,表2中则分别列出了他们的参数总量。卷积层的通道数从64开始,经池化后逐渐加倍至128,256,直到516。论文中提到,尽管VGG很深,但是相比一些较浅的卷积网络,其参数量并不算很大,因为那些较浅的网络使用了大尺寸的感受野(filter size很大),卷积层的shape较大等。如(Sermanet et al., 2014)参数量达到1.44亿。
2.3 讨论
这一小结提到,为什么这里使用了filter size为3×3叠加卷积层的block?而不是直接用单层的7×7的卷积层? 首先,3个卷积层叠加,带来了3次relu的非线性校正,比使用一个relu的单层layer更具有识别力;第二,降低了参数量,7×7×C×C 比3×3×C×C的参数量大81%。 作者提到了,使用诸如2014年的Network in Network中的1×1卷积,不改变shape只改变通道数,也可以增加非线性。还提到2014年的GoogLeNet,作者表明:虽然架构不同,不过两者有共同点:1.深度足够深;2.都使用了较小尺寸的filter size用来减少参数量,故其模型效果很好。
3.(图像)分类架构
这一节主要介绍模型训练,测试的细节工作。
3.1 训练
训练和之前的AlexNet整体类似,使用小批量梯度下降,参数方面:batch设为256,动量设为0.9,除最后一层外的全连接层也都使用了丢弃率0.5的dropout。learning rate最初设为0.01,权重衰减系数为5×10^-4。对于权重层采用了随机初始化,初始化为均值0,方差0.01的正态分布。 训练的图像数据方面,为了增加数据集,和AlexNet一样,这里也采用了随机水平翻转和随机RGB色差进行数据扩增。对经过重新缩放的图片随机排序并进行随机剪裁得到固定尺寸大小为224×224的训练图像。
具体方式如下: 这里定义S为经过isotropically-rescaled(宽高等比例缩放)后的图片的最小边长度。原则上,缩放后的图像中只有S>=224的部分才可以被用来做随机剪裁,进行训练。论文中,将S称为training scale。
图片缩放和随机裁剪 举个例子,这里设training scale S = 224。有三幅经缩放后的图片:A,B,C。尺寸长×宽分别为:A 200×400,B 224×600 C 600×900 则A的最小边200<224,不可以进行裁剪;B、C可以(且对B的任何裁剪范围,都只能在宽600所在的边上移动)
在论文实现中,采用了两种方式来设定S:
- 固定尺度fix scale
- 多尺度multi scale
1.固定尺度fix scale 训练中评估了两种scale:S = 256和S = 384
2.多尺度multi scale 训练中设置了[Smin, Smax]的浮动尺度,范围设为[256,512]。作者认为,对于即使同一类别的物体,其在不同图片上的大小也不尽相同,所以浮动尺度会更好,更接近真实情况。
3.2 测试
略
3.3 实施细节
GPU并行训练:模型是用贾扬清2013年开源的的Caffe框架进行的(C++编写),但做了部分修改以实现多GPU训练。针对一个batch,将其分割为多个gpu batch,并且进行并行处理,梯度计算在 GPU 之间是同步的,所以结果和在一个 GPU 上训练的结果完全一样。
训练设备及耗时:在4块并行的NVIDIA Titan Black上训练大约需要2~3周
4.分类实验
4.1 single scale
这里的single scale指的是测试时所用的scale固定。这里把训练scale和测试的scale分别用S和Q表示。当S为固定值时,令Q = S固定;当S为[Smin,Smax]浮动时,Q固定为 = 0.5[Smin + Smax]。 测试发现LRN局部响应归一化并没有带来精度提升,故在A-LRN之后的B~E类VGG网络中,都没有使用。
通过表格间各个网络的对比发现如下结论:
- 总体来说卷积网络越深,损失越小,效果越好。
- C优于B,表明多增加的非线性relu有效
- D优于C,表明了卷积层filter对于捕捉空间特征有帮助。
- E深度达到19层后达到了损失的最低点,但是对于其他更大型的数据集来说,可能更深的模型效果更好。
- B和同类型filter size为5×5的网络进行了对比,发现其top-1错误率比B高7%,表明小尺寸filter效果更好。
- 在训练中,采用浮动尺度效果更好,因为这有助于学习分类目标在不同尺寸下的特征。
4.2 multi scale
和single scale相对,这里multi scale表示测试时的scale不固定。 这里当训练时的S固定时,Q取{S - 32, S, S+32}中的每个值,进行测试过后取平均结果。 当S为[Smin,Smax]浮动时,Q取{Smin, 0.5(Smin+Smax), Smax},测试后取平均。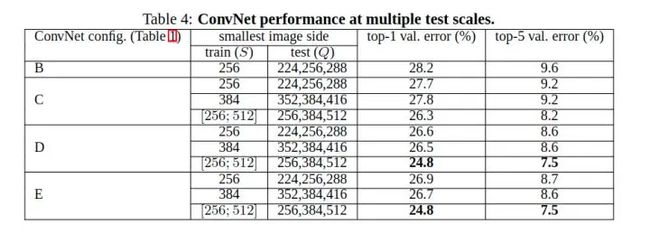
结论:
- 同single scale一样,模型越深,效果越好;
- 同深度下,浮动scale效果好于固定scale。
5.总结
作者表示:我们评估了非常深的卷积网络(多达19权重层)的大规模图像分类。 研究表明,表征深度有利于分类的准确性,并且可以通过使用传统的 ConvNet 架构在 ImageNet 挑战数据集上的最先进的性能
5.代码实现
这里使用tensorflow2.0实现网络结构,而不是完整的训练。
import tensorflow as tf
print(tf.__version__)
for gpu in tf.config.experimental.list_physical_devices('GPU'):
tf.config.experimental.set_memory_growth(gpu, True)
def vgg_block(num_convs, num_channels):
blk = tf.keras.models.Sequential()
for _ in range(num_convs):
# strides默认 = (1, 1)
blk.add(tf.keras.layers.Conv2D(num_channels,kernel_size=3,
padding='same',activation='relu'))
blk.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
return blk
def vgg(conv_arch):
net = tf.keras.models.Sequential()
for (num_convs, num_channels) in conv_arch:
net.add(vgg_block(num_convs,num_channels))
net.add(tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(4096,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(4096,activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1000,activation='softmax')]))
return net
conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))
net = vgg(conv_arch)
X = tf.random.uniform((1,224,224,3))
for blk in net.layers:
X = blk(X)
print(blk.name, 'output shape:\t', X.shape)
输出:
sequential_1 output shape: (1, 112, 112, 64)
sequential_2 output shape: (1, 56, 56, 128)
sequential_3 output shape: (1, 28, 28, 256)
sequential_4 output shape: (1, 14, 14, 512)
sequential_5 output shape: (1, 7, 7, 512)
sequential_6 output shape: (1, 1000)
在《动手学深度学习》-tf2.0版一书中,有完整的训练代码。不过由于ImageNet规模较大,故数据集使用的是Fashion-MNIST,完整训练可参考:使用重复元素的网络(VGG)
6.总结
VGGNet通过在传统卷积神经网络模型(AlexNet)上的拓展,发现除了较为复杂的模型结构的设计(如GoogLeNet和Network in Network)外,深度对于提高模型准确率很重要,VGG和之前的AlexNet相比,深度更深,参数更多(1.38亿),效果和可移植性更好,且模型设计的简洁而规律,从而被广泛使用。 还有一些特点总结如下:
- 小尺寸的filter(3×3)不仅使参数更少,效果也并不弱于大尺寸filter如5×5
- 数据增强和图像裁剪如multi scale等方式有助于提高网络准确率
- AlexNet中的局部响应归一化作用不大