算法中的数学知识总结
目录
- 数学知识补充
- 一、质数
-
- Ⅰ试除法判定质数
-
- 1、朴素做法 O ( n ) O(n) O(n):
- 2、优化 O ( n ) O(\sqrt n) O(n):
- Ⅱ分解质因数
- Ⅲ筛质数
-
- 1、朴素筛法 O ( n l o g n ) O(nlogn) O(nlogn)(将所有数的倍数筛掉):
- 2、埃氏筛 O ( l o g l o g n ) O(loglogn) O(loglogn)(将质数的倍数筛掉):
- 3、线性筛,也叫欧拉筛 O ( n ) O(n) O(n)(合数会被自己的最小质因子筛掉):
- 二、约数
-
- Ⅰ试除法求约数
- Ⅱ约数个数
- Ⅲ约数之和
- Ⅳ欧几里得算法
- 三、欧拉函数
-
- 筛法求欧拉函数
- 四、快速幂
-
- 快速幂求逆元
- 五、扩展欧几里得算法
- 六、高斯消元解线性方程组
- 七、组合数
-
- Ⅰ公式法(1<= b <= a <= 2000)
- Ⅱ 快速幂(1 <= b <= a <= 1 0 5 10^5 105)
- Ⅲ 卢卡斯定理(1 <= b <= a <= 1 0 18 10^{18} 1018)
- Ⅳ 高精度
- 卡特兰数
数学知识补充
算术基本定理:
任何一个大于1的正整数都能唯一分解为有限个质数的乘积,可写作:
N = p 1 c 1 p 2 c 2 … p k c k N = p_1^{c_1}p_2^{c_2} \dots p_k^{c_k} N=p1c1p2c2…pkck
其中,c都是正整数, p i p_i pi都是质数,且满足 p 1 < p 2 < ⋯ < p k p_1 < p_2 < \dots < p_k p1<p2<⋯<pk
费马小定理: 若 p 是质数,则对于任意整数 a ,有 a p ≡ a ( m o d p ) a^p \equiv a (mod\ p) ap≡a(mod p)。
欧拉定理: 若正整数 a ,n 互质,则 a ϕ ( n ) ≡ 1 ( m o d n ) a^{\phi(n)} \equiv 1 (mod \ n) aϕ(n)≡1(mod n),其中, ϕ ( n ) \phi(n) ϕ(n) 为欧拉函数。
裴蜀定理: 若 a,b 是整数,且 gcd(a,b)=d,那么对于任意的整数 x,y,ax+by 都一定是 d 的倍数,特别地,一定存在整数 x,y,使 ax+by = d 成立。
一、质数
定义: 在大于 1 的自然数中,除了 1 和它本身以外不再有其他因数的自然数。
Ⅰ试除法判定质数
1、朴素做法 O ( n ) O(n) O(n):
①如果 n 小于 2 ,则 n 不是质数。
②枚举从 2 到 n - 1 的所有数,判断是否能被 n 整除。
bool is_prim(int n)
{
if(n < 2) return false;
for(int i = 2;i < n;i++)
{
if(n % i == 0) return false;
}
return true;
}
2、优化 O ( n ) O(\sqrt n) O(n):
设 d 为待判定数 n 的一个因子,那么 n d \frac{n}{d} dn 也必定是 n 的一个因子。
例如: d = 3 , n d = 4 \rm d = 3,\frac{n}{d} = 4 d=3,dn=4,3 可以整除 12,4 也可以整除 12。
一个性质:成对的两个因子中,必只有一个小于等于 n \sqrt n n
证明如下:
若两个因子都大于 n \sqrt n n,即 d > n , n d > n d > \sqrt n,\frac{n}{d} > \sqrt n d>n,dn>n,则
d ∗ n d = n > n ∗ n = n d * \frac{n}{d} = n > \sqrt n * \sqrt n = n d∗dn=n>n∗n=n
得到 n > n n> n n>n,矛盾,所以两个因子必然只有一个小于等于 n \sqrt n n
因此在代码中,在 2~(n - 1) 中只要有一个为 n 的因子就能判定 n 是合数而不是质数,所以只需要从 2 枚举到 n \sqrt n n 即可( i ≤ n i \le \sqrt n i≤n)。
关于该处的写法:
① i < = s q r t ( n ) \rm i <= sqrt(n) i<=sqrt(n) : 因为 sqrt() 函数运行比较满,不推荐。
② i ∗ i < = n \rm i * i <= n i∗i<=n:int 的最大值为 2147483647( 2 31 − 1 2^{31 } - 1 231−1),i * i可能发生溢出,不推荐。
所以采用 i < = n / i \rm i <= n / i i<=n/i该写法。
bool is_prim(int n)
{
if(n < 2) return false;
for(int i = 2;i <= n / i;i++)
{
if(n % i == 0) return false;
}
return true;
}
Ⅱ分解质因数
枚举 2 到 n \sqrt n n 的数判断是否是 n 的因子。
为什么枚举所有数,不是要质因数吗?
①当枚举到 i 时,2 到 i - 1 的所有 n 的质因子都会除 n 。
所以当枚举到 i 时,2 到 i - 1 中没有 n 的质因子。
②且当 n % i == 0条件成立时,说明 n 是 i 的倍数,此时 2 到 i - 1 中也没有 i 的质因子,根据质数的定义,i 必定是质数。
void divide(int a)
{
for(int i = 2;i <= a / i;i++)
{
if(a % i == 0)
{
int s = 0;
while(a % i == 0)
{
s++;
a /= i;
}
cout<<i<<" "<<s<<endl;
}
}
//最后如果n还是>1,说明这就是大于sqrt(n)的唯一质因子,输出即可。
cout<<endl;
}
Ⅲ筛质数
1、朴素筛法 O ( n l o g n ) O(nlogn) O(nlogn)(将所有数的倍数筛掉):
void get_prime(int n)
{
for(int i = 2;i <= n;i++)
{
if(!st[i]) //如果为质数
{
prime[cnt++] = i;
}
//将每一个数的倍数筛掉
for(int j = i + i;j <= n;j += i)
{
st[j] = true;
}
}
}
2、埃氏筛 O ( l o g l o g n ) O(loglogn) O(loglogn)(将质数的倍数筛掉):
void get_prime(int n)
{
for(int i = 2;i <= n;i++)
{
if(st[i]) continue;//st判断是否被筛掉
prime[cnt++] = i;
for(int j = i + i;j <= n;j += i)
{
st[j] = true;
}
}
}
3、线性筛,也叫欧拉筛 O ( n ) O(n) O(n)(合数会被自己的最小质因子筛掉):
p j p_j pj:表示下标为 j 的质数
①当 i % p j p_j pj == 0:
pj是i的质因子,pj也是pj*i的质因子,同时是最小质因子
②当 i % p j p_j pj != 0:
由于 p j p_j pj 是从小到大枚举的质数且 i % p j p_j pj ==0的话说明 p j p_j pj是 i 的最小质因子,可现在不是,说明 p j p_j pj 一定小于 i 的最小质因子, p j p_j pj 是 p j ∗ i p_j * i pj∗i 的最小质因子
总结:无论哪种情况, p j p_j pj 都是 p j ∗ i p_j*i pj∗i 的最小质因子,即: p j ∗ i p_j*i pj∗i (合数)一定会被它的最小质因子筛掉。
void get_prime(int n)
{
for(int i = 2;i <= n;i++)
{
if(!st[i])
{
prime[cnt++] = i;
}
for(int j = 0;prime[j] <= n / i;j++)//枚举所有质数
{
st[prime[j] * i] = true;//筛掉该质数对应的合数
if(i % prime[j] == 0) break;
}
}
}
二、约数
Ⅰ试除法求约数
从 1 枚举到 n \sqrt n n ,判断 i 是否能整除 n ,对于大于 n \sqrt n n 的约数,可以通过 n d \frac{n}{d} dn 计算得出。
vector<int> get_divisors(int n)
{
vector<int> res;
for(int i = 1;i <= n / i;i++)
{
if(n % i == 0)
{
res.push_back(i);
if(i != n / i) res.push_back(n / i);
}
}
sort(res.begin(),res.end());
return res;
}
Ⅱ约数个数
公式: ( c 1 + 1 ) ( c 2 + 1 ) … ( c k + 1 ) (c_1 + 1)(c_2 + 1)\dots(c_k + 1) (c1+1)(c2+1)…(ck+1)
求 N 的约数个数:
由算术基本定理得: N = p 1 c 1 p 2 c 2 … p k c k N = p_1^{c_1}p_2^{c_2} \dots p_k^{c_k} N=p1c1p2c2…pkck
设 d 为 N 的约数: d = p 1 β 1 p 2 β 2 … p k β k d = p_1^{\beta_1}p_2^{\beta_2} \dots p_k^{\beta_k} d=p1β1p2β2…pkβk
对于 β 1 \beta_1 β1 有 0 ≤ β 1 ≤ c 1 0 \le \beta_1 \le c_1 0≤β1≤c1,根据算术基本定理, β 1 , c 1 \beta_1,c_1 β1,c1 都为正整数,则 β 1 \beta_1 β1 有 ( c 1 + 1 ) (c_1 + 1) (c1+1) 中不同的选法,对 β 2 \beta_2 β2~ β k \beta_k βk 同上。
根据组合,则约数个数为 ( c 1 + 1 ) ( c 2 + 1 ) … ( c k + 1 ) (c_1 + 1)(c_2 + 1)\dots(c_k + 1) (c1+1)(c2+1)…(ck+1)
#include Ⅲ约数之和
公式: ( p 1 0 + p 1 1 + ⋯ + p 1 c 1 ) … ( p k 0 + p k 1 + ⋯ + p k c k ) (p_1^0 + p_1^1 + \dots +p_1^{c_1}) \dots (p_k^0 + p_k^1 + \dots +p_k^{c_k}) (p10+p11+⋯+p1c1)…(pk0+pk1+⋯+pkck)
#include Ⅳ欧几里得算法
gcd(a,b): 求 a 和 b 的最大公约数
证明 gcd(a,b) = gcd(b,a mod b):
①从左往右:
设 d = gcd(a,b)
因为对应左边 d | a,d | b,所以 d | (ax + by) (d 能整除 a 的若干倍 + b 的若干倍)
a mod b = a - ⌊ a b ⌋ \rm \lfloor\frac{a}{b} \rfloor ⌊ba⌋ * b
令 c = ⌊ a b ⌋ \rm \lfloor\frac{a}{b} \rfloor ⌊ba⌋(c 为常数)
所以 a mod b = a - c * b
所以 对应右边 d | b,d | (a - c * b)
②从右往左:
设 d = gcd(b,a mod b)
因为 d | b,d | (a - c * b)
所以 d | [(a - c * b) + c * b] = d | a,对应右边
证毕!
int gcd(int a,int b)
{
return !b ? a : gcd(b,a % b);
}
三、欧拉函数
定义: 1 ~ N 中与 N 互质的数的个数被称为欧拉函数,记为 ϕ ( N ) \phi(N) ϕ(N),若在算术基本定理中, N = p 1 c 1 p 2 c 2 … p k c k N = p_1^{c_1}p_2^{c_2} \dots p_k^{c_k} N=p1c1p2c2…pkck,则:
ϕ ( N ) = N ∗ ( 1 − 1 p 1 ) ∗ ( 1 − 1 p 2 ) … ( 1 − 1 p m ) \phi(N) = N * (1 - \frac{1}{p_1}) * (1 - \frac{1}{p_2}) \dots (1 - \frac{1}{p_m}) ϕ(N)=N∗(1−p11)∗(1−p21)…(1−pm1)
规定 ϕ ( 1 ) = 1 \phi(1) = 1 ϕ(1)=1
推导:为了求 1 - N 中和 N 互质的数的个数
①从 1 ~ N 中去掉 p 1 , p 2 , … , p k p_1,p_2,\dots ,p_k p1,p2,…,pk 的所有倍数
N − N p 1 − N p 2 − ⋯ − N p k N - \frac{N}{p_1} - \frac{N}{p_2} - \dots - \frac{N}{p_k} N−p1N−p2N−⋯−pkN
②若一个数既是 p 1 p_1 p1的倍数,又是 p 2 p_2 p2 的倍数,根据①,则该数被去掉了两次,加上所有 p i ∗ p j p_i * p_j pi∗pj 的倍数
+ N p 1 p j + N p 1 p 3 + ⋯ + +\frac{N}{p_1p_j} + \frac{N}{p_1p_3}+\dots+ +p1pjN+p1p3N+⋯+
③若一个数既是 p 1 p_1 p1的倍数,又是 p 2 p_2 p2 的倍数,也是 p 3 p_3 p3 的倍数,
根据①,该数被去掉了三次,根据②,该数被加上了三次,我们应该让这个数去掉一次,减去 p i ∗ p j ∗ p k p_i * p_j * p_k pi∗pj∗pk 的倍数
− N p 1 p 2 p 3 − N p 1 p 2 p 4 − ⋯ − -\frac{N}{p_1p_2p_3} - \frac{N}{p_1p_2p_4} - \dots - −p1p2p3N−p1p2p4N−⋯−
④会发现相关规律,并将欧拉函数 ϕ ( N ) = N ∗ ( 1 − 1 p 1 ) ∗ ( 1 − 1 p 2 ) … ( 1 − 1 p m ) \phi(N) = N * (1 - \frac{1}{p_1}) * (1 - \frac{1}{p_2}) \dots (1 - \frac{1}{p_m}) ϕ(N)=N∗(1−p11)∗(1−p21)…(1−pm1) 展开即可得到此式。
int phi(int n)
{
int res = n;
for(int i = 2;i <= n / i;i++)
{
if(n % i == 0)
{
res = res / i * (i - 1);
while(n % i == 0) n /= i;
}
}
if(n > 1) res = res / n * (n - 1);
return res;
}
筛法求欧拉函数
①若一个数是质数,设此数为 p ,则根据欧拉函数与质数定义,1 ~ p 中与 p 互质的数的个数为 p - 1,即 ϕ ( p ) = p − 1 \phi(p) = p - 1 ϕ(p)=p−1。
②当 i % p j p_j pj == 0 时,求 ϕ ( p j ∗ i ) \phi(p_j * i) ϕ(pj∗i):
当 i % p j p_j pj == 0 时, p j p_j pj 为 i 的最小质因子, p j p_j pj 为 p j ∗ i p_j * i pj∗i 的最小质因子。
根据欧拉函数定义得:
ϕ ( i ) = i ∗ ( 1 − 1 p 1 ) ∗ ( 1 − 1 p 2 ) … ( 1 − 1 p m ) \phi(i) = i* (1 - \frac{1}{p_1}) * (1 - \frac{1}{p_2}) \dots (1 - \frac{1}{p_m}) ϕ(i)=i∗(1−p11)∗(1−p21)…(1−pm1)
则
ϕ ( p j ∗ i ) = p j ∗ i ∗ ( 1 − 1 p 1 ) ∗ ( 1 − 1 p 2 ) … ( 1 − 1 p m ) = p j ∗ ϕ ( i ) \begin{align} \phi(p_j * i) &= p_j * i * (1 - \frac{1}{p_1}) * (1 - \frac{1}{p_2}) \dots (1 - \frac{1}{p_m})\\ &=p_j * \phi(i) \end{align} ϕ(pj∗i)=pj∗i∗(1−p11)∗(1−p21)…(1−pm1)=pj∗ϕ(i)
③当 i % p j ≠ p_j \ne pj= 0 时,求 ϕ ( p j ∗ i ) \phi(p_j * i) ϕ(pj∗i):
p j p_j pj 不是 i 的质因子:
ϕ ( i ) = i ∗ ( 1 − 1 p 1 ) ∗ ( 1 − 1 p 2 ) … ( 1 − 1 p m ) \phi(i) = i* (1 - \frac{1}{p_1}) * (1 - \frac{1}{p_2}) \dots (1 - \frac{1}{p_m}) ϕ(i)=i∗(1−p11)∗(1−p21)…(1−pm1)
其中,不包含 1 − 1 p j 1 - \frac{1}{p_j} 1−pj1。
但是 p j p_j pj 是 i ∗ p j i * p_j i∗pj 的质因子:
ϕ ( p j ∗ i ) = p j ∗ i ∗ ( 1 − 1 p 1 ) ∗ ( 1 − 1 p 2 ) … ( 1 − 1 p m ) ∗ ( 1 − 1 p j ) = p j ∗ ϕ ( i ) ∗ ( 1 − 1 p j ) = ϕ ( i ) ∗ ( p j − 1 ) \begin{align} \phi(p_j * i) &= p_j * i * (1 - \frac{1}{p_1}) * (1 - \frac{1}{p_2}) \dots (1 - \frac{1}{p_m})*(1-\frac{1}{p_j})\\ &=p_j * \phi(i) * (1 - \frac{1}{p_j})\\ &=\phi(i) * (p_j - 1) \end{align} ϕ(pj∗i)=pj∗i∗(1−p11)∗(1−p21)…(1−pm1)∗(1−pj1)=pj∗ϕ(i)∗(1−pj1)=ϕ(i)∗(pj−1)
void get_eular()
{
eular[1] = 1;
for(int i = 2;i <= n;i++)
{
if(!st[i])
{
primes[cnt ++] = i;
eular[i] = i - 1;
}
for(int j = 0;primes[j] <= n / i;j++)
{
int t = primes[j] * i;
st[primes[j] * i] = true;
if(i % primes[j] == 0)
{
eular[t] = eular[i] * primes[j];
break;
}
eular[t] = eular[i] * (primes[j] - 1);
}
}
}
四、快速幂
为了在 O ( l o g k ) O(logk) O(logk) 的时间复杂度中,求 a k m o d p a^k mod \ p akmod p。
将 a 分解,将 k 用二进制表示:
k = 2 x 1 + 2 x 2 + ⋯ + 2 x t k = 2^{x_1} + 2^{x_2} + \dots + 2^{x_t} k=2x1+2x2+⋯+2xt
则
a k = a 2 x 1 + 2 x 2 + ⋯ + 2 x t = a 2 x 1 ∗ a 2 x 2 ∗ ⋯ ∗ a 2 x t \begin{align} a^k &= a^{2^{x_1} + 2^{x_2} + \dots + 2^{x_t}}\\ &=a^{2^{x_1}} * a^{2^{x_2}} * \dots * a^{2^{x_t}} \end{align} ak=a2x1+2x2+⋯+2xt=a2x1∗a2x2∗⋯∗a2xt
对于每个因子如何递推得到:
a 2 0 ∗ a 2 0 = a 2 1 a 2 1 ∗ a 2 1 = a 2 2 ⋮ a 2 l o g k − 1 ∗ a 2 l o g k − 1 = a 2 l o g k \begin{align} &a^{2^{0}} * a^{2^{0}} = a^{2^{1}}\\ &a^{2^{1}} * a^{2^{1}} = a^{2^{2}}\\ &\vdots \\ &a^{2^{logk - 1}} * a^{2^{logk - 1}} = a^{2^{logk}} \end{align} a20∗a20=a21a21∗a21=a22⋮a2logk−1∗a2logk−1=a2logk
LL qmi(LL a,LL b,LL p)
{
LL res = 1 % p;
while(b)
{
if(b & 1) res = res * a % p;
a = a * a % p;
b >>= 1;
}
return res;
}
快速幂求逆元
乘法逆元: a b ≡ a ∗ x ( m o d p ) \frac{a}{b} \equiv a * x (mod \ p) ba≡a∗x(mod p)
可以理解为: b ∗ x ≡ 1 ( m o d p ) b * x \equiv 1 (mod \ p) b∗x≡1(mod p),若 b 为 p 的倍数,则 b ∗ x ≡ 0 ( m o d p ) b * x \equiv 0 (mod \ p) b∗x≡0(mod p) ,即不存在逆元。
由费马小定理得:
b p − 1 ≡ 1 ( m o d p ) b ∗ b p − 2 ≡ 1 ( m o d p ) \begin{align} b^{p-1} &\equiv 1 (mod \ p)\\ b*b^{p - 2} &\equiv 1 (mod\ p) \end{align} bp−1b∗bp−2≡1(mod p)≡1(mod p)
则 b p − 2 b^{p - 2} bp−2 即 b ( m o d p ) b (mod \ p) b(mod p) 的乘法逆元。
#include 五、扩展欧几里得算法
利用裴蜀定理求 x,y:
①当 b = 0 时:gcd(a,0) = a。
a x + b y = a x + 0 ∗ y = a ax + by = ax + 0 * y = a ax+by=ax+0∗y=a
显然,x = 1,y = 0 是其中的一组解。
②当 b ≠ \ne = 0 时:令 d = gcd(b,a mod b)。
为了方便计算,将 x,y对调,即 d = exgcd(b,a mod b,y,x)
d = b y + ( a m o d b ) x = b y + ( a − ⌊ a b ⌋ b ) x = a x + b ( y − ⌊ a b ⌋ x ) \begin{align} d &= by + (a mod \ b)x\\ &= by + (a - \lfloor \frac{a}{b} \rfloor b)x\\ &= ax + b(y -\lfloor \frac{a}{b} \rfloor x)\\ \end{align} d=by+(amod b)x=by+(a−⌊ba⌋b)x=ax+b(y−⌊ba⌋x)
将 a,b的系数对应,发现 x 不变,y 发生了改变。
int gcd(int a,int b,int &x,int &y)
{
if(!b)
{
x = 1,y = 0;
return a;
}
int d = gcd(b,a % b,y,x);
y -= (a / b) * x;
return d;
}
六、高斯消元解线性方程组
枚举每一列 c
①找到当前列的绝对值最大的一行。
②将该行换到最上面。
③将该行的第一个数变成 1(该行的所有数除以该行第一个数,从后往前求)。
④将当前列 c 该行下面所有行消成 0。
⑤将主元上面的数消成 0。
#include 七、组合数
Ⅰ公式法(1<= b <= a <= 2000)
C a b = C a − 1 b + C a − 1 b − 1 C_a^b = C_{a-1}^b + C_{a-1}^{b-1} Cab=Ca−1b+Ca−1b−1
#include Ⅱ 快速幂(1 <= b <= a <= 1 0 5 10^5 105)
C a b = a ! ( a − b ) ! b ! C_a^b = \frac{a!}{(a - b)! b!} Cab=(a−b)!b!a!
①预处理 i 的阶乘 fact[i] (mod 1e9 + 7)
②预处理 i 的阶乘的逆元 infact[i] (mod 1e9 + 7)
③ C a b = f a c t [ a ] ∗ i n f a c t [ a − b ] ∗ i n f a c t [ b ] C_a^b = fact[a] * infact[a - b] * infact[b] Cab=fact[a]∗infact[a−b]∗infact[b]
#include Ⅲ 卢卡斯定理(1 <= b <= a <= 1 0 18 10^{18} 1018)
C a b = C a m o d p b m o d p C a / p b / p ( m o d p ) C_a^b = C_{a\ mod\ p}^{b\ mod\ p} C_{a/p}^{b/p} (mod \ p) Cab=Ca mod pb mod pCa/pb/p(mod p)
C a b = a ! ( a − b ) ! b ! = ( a − b + 1 ) … a b ! C_a^b = \frac{a!}{(a - b)!b!} = \frac{(a - b +1) \dots a}{b!} Cab=(a−b)!b!a!=b!(a−b+1)…a
#include Ⅳ 高精度
C a b = a ! ( a − b ) ! b ! C_a^b = \frac{a!}{(a - b)!b!} Cab=(a−b)!b!a!
1~n中 p 的倍数的个数为 ⌊ n p ⌋ \lfloor \frac{n}{p} \rfloor ⌊pn⌋,例:1~8中 2 的倍数的个数为 ⌊ 8 2 ⌋ = 4 \lfloor \frac{8}{2} \rfloor = 4 ⌊28⌋=4
因为 n ! = n ∗ ( n − 1 ) … 2 ∗ 1 n! = n*(n - 1) \dots 2 *1 n!=n∗(n−1)…2∗1
所以 n! 中 p 的倍数的个数等于 1~n 中 p 的倍数的个数
因此 n! 中包含 p 的个数 = ⌊ n p ⌋ + ⌊ n p 2 ⌋ + ⌊ n p 3 ⌋ + … \lfloor \frac{n}{p} \rfloor + \lfloor \frac{n}{p^2} \rfloor + \lfloor \frac{n}{p^3} \rfloor + \dots ⌊pn⌋+⌊p2n⌋+⌊p3n⌋+…
① (线性筛)因为 a >= b,a > a - b,所以只需预处理 a 中所有的质因数(a! 中所有的质因数相当于 a 中的所有质因数)
②利用上述性质将 C a b C_a^b Cab 分解质因数,
即: C a b C_a^b Cab 中 p 的个数为:a! 中 p 的个数 - b! 中 p 的个数 - (a - b)! 中 p 的个数。
③根据算术基本定理得到 C a b C_a^b Cab,其中乘法使用高精度。
#include 卡特兰数
以满足条件的01序列为例:
将该题转化为网格图,以 n = 6为例,规定:0 表示向右走,1表示向上走。
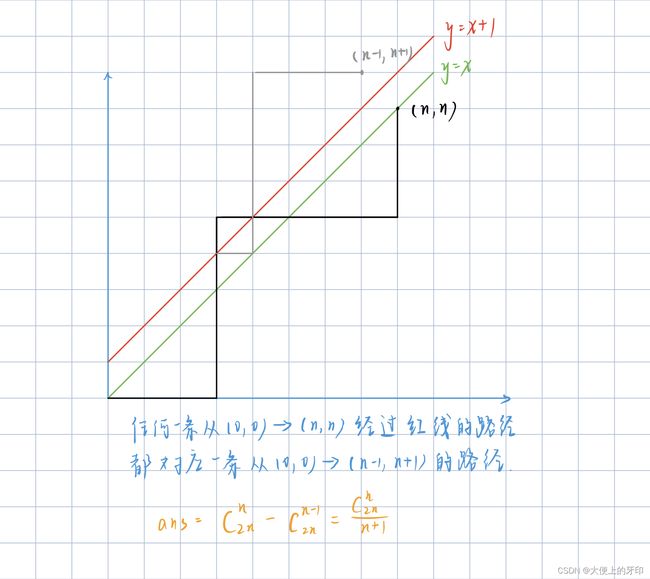
图片来源,借用一下QAQ
①将 n 个 0 和 n 个 1 组合成排列长度为 2n 的序列,对应网格图中不同的路径。
总路径个数为 C 12 6 C_{12}^6 C126,即 12 个数中选 0 的方案数。
②对于任意前缀 0 的个数不少于 1 的个数,可转化为网格图中不经过红线的路径个数,从而转化为:
所有路径个数( C 12 6 C_{12}^6 C126) - 经过红线的路径个数
③对于任意一条经过红线的路径,其终点是固定的(6,6),以经过红线点为起始点,将其关于红线对称后,其终点依然固定(5,7),则经过红线的路径个数可转化为从(0,0)到(5,7)的个数( C 12 5 C_{12}^5 C125)
答案为: C 2 n n − C 2 n n − 1 ( C 12 6 − C 12 5 ) C_{2n}^n - C_{2n}^{n-1}(C_{12}^6 - C_{12}^{5}) C2nn−C2nn−1(C126−C125)
化简:
C 2 n n − C 2 n n − 1 = ( 2 n ) ! n ! n ! − ( 2 n ) ! ( n + 1 ) ! ( n − 1 ) ! = ( 2 n ) ! ( n + 1 ) − ( 2 n ) ! n ( n + 1 ) ! n ! = ( 2 n ) ! ( n + 1 ) ! n ! = 1 n + 1 ( 2 n ) ! n ! n ! = 1 n + 1 C 2 n n ( 卡特兰数 ) \begin{align} &C_{2n}^n - C_{2n}^{n-1}\\ =&\frac{(2n)!}{n!n!} - \frac{(2n)!}{(n + 1)!(n - 1)!}\\ =&\frac{(2n)!(n + 1) - (2n)!n}{(n + 1)!n!}\\ =&\frac{(2n)!}{(n + 1)!n!} \\ =&\frac{1}{n + 1} \frac{(2n)!}{n!n!}\\ =&\frac{1}{n + 1}C_{2n}^n(卡特兰数) \end{align} =====C2nn−C2nn−1n!n!(2n)!−(n+1)!(n−1)!(2n)!(n+1)!n!(2n)!(n+1)−(2n)!n(n+1)!n!(2n)!n+11n!n!(2n)!n+11C2nn(卡特兰数)
#include