干货分享!让你通俗理解扩散模型
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达还有谁没有看过diffusion的工作,席卷AI圈的diffusion到底是什么?本文作者用尽量通俗的描述向大家解释 diffusion 的来龙去脉。
实验室最近人人都在做扩散,从连续到离散,从 CV 到 NLP,基本上都被 diffusion 洗了一遍。但是观察发现,里面的数学基础并不是模型应用的必须。其实大部分的研究者都不需要理解扩散模型的数学本质,更需要的是对扩散模型的原理的经验化理解,从而应用到 research 里面去。笔者做 VAE 和 diffussion 也有一段时间了,就在这里通俗地解释一下 diffusion 的来龙去脉。
01
Variational AutoEncoder (VAE)

要讲扩散模型,不得不提 VAE。VAE 和 GAN 一样,都是从隐变量生成目标数据。它们假设隐变量服从某种常见的概率分布(比如正态分布),然后希望训练一个模型,这个模型将原来的概率分布映射到训练集的概率分布,也就是分布的变换。注意,VAE 和 GAN 的本质都是概率分布的映射。大致思路如下图所示:

图片来源:https://zhuanlan.zhihu.com/p/34998569
换句话说,大致意思就是先用某种分布随机生成一组隐变量,然后这个隐变量会经过一个生成器生成一组目标数据。VAE 和 GAN 都希望这组数据的分布和目标分布尽量接近。
是不是听上去很 work?但是这种方法本质上是难以 work 的,因为“尽量接近”并没有一个确定的关于 XXX 和 X^\hat{X}\hat{X} 的相似度的评判标准。换句话说,这种方法的难度就在于,必须去猜测“它们的分布相等吗”这个问题,而缺少真正 interpretable 的价值判断。有聪明的同学会问,KL 散度不就够了吗?不行,因为 KL 散度是针对两个已知的概率分布求相似度的,而和 XXX 的概率分布目前都是未知。
GAN 的做法就是直接把这个度量标准也学过来就行,相当生猛。但是这样做的问题在于依然不 interpretable,非常不优雅。VAE 的做法就优雅很多了,我们先来看 VAE 是怎么做的,理解了 VAE 以后再去理解 Diffussion 就很自然了。
到底什么是生成模型?
我们看回生成模型到底是个啥。我们拿到一批 sample(称为), 想要用学到它的分布, 这样就能同时学到没被 sample 到的数据了, 用这个分布就能随意采样, 然后获得 生成结果。但是这个分布九曲回肠, 根本不可能直接获得。所以绕个弯, 整一个隐变量, 这东西可以生成。不妨假设满足正态分布, 那就可以先从正态分布里面随便取一个, 然后用和的关系算出。这里不得不用一下数学公式, 因为后面一直要用到(其实也很简单, 学过概率学基础一下就看得懂) :
换句话说, 就是不直接求, 而是造一个别的变量(好听的名字叫“隐变量"),获得这个隐变量和我要搞的的关系, 也能搞到。注意, 上式中,称为后验分布,称为先验分布。
VAE 的核心
VAE 的核心就是, 我们不仅假设 是正态分布, 而且假设每个 也是正态分布。 什么意思呢? 因为是一组采样,其实可以表示成, 而我们想要针对每个获得一个专属于它和的一个正态分布。换句话说, 有个sample, 就有个正态分布。其实也很好理解, 每一个采样点当然都需要一个相对的分布, 因为没有任何两个采样点是完全一致的。
那现在就要想方设法获得这个正态分布了。怎么搞? 学!拟合!但是要注意, 这里的拟合与不同, 本质上是在学习和的关系, 而非学习比较与的标准。
OK, 现在问一个小学二年级就知道的问题, 已知是正态分布, 学什么才能确定这个正态分布? 没错, 均值和方差。怎么学? 有数据啊!不是你自己假设的吗,是已知的啊, 那你就用这俩去学个均值和方差。
好, 现在我们已经学到了这个正态分布。那就好说了, 直接从里面采样一个, 学 一个 generator,就能获得了。那接下来只需要最小化方差就行。来看看下面的图, 仔细理解一下:

仔细理解的时候有没有发现一个问题? 为什么在文章最开头, 我们强调了没法直接比较和的分布, 而在这里, 我们认为可以直接比较这俩? 注意, 这里的 是专属于 (针对于) 的隐变量, 那么和 本身就有对应关系,因此右边的蓝色方框内的“生成器”, 是一一对应的生成。
另外,大家可以看到,均值和方差的计算本质上都是 encoder。也就是说,VAE 其实利用了两个 encoder 去分别学习均值和方差。
VAE 的 Variational 到底是个啥
这里还有一个非常重要的问题 (对于初学者而言可能会比较困难, 需要反复思考) : 由于我们通过最小化来训练右边的生成器, 最终模型会逐渐使得和趋于一致。但是注 意, 因为是重新随机采样过的, 而不是直接通过均值和方差 encoder 学出来的, 这个生成器的输入是有噪声的。但是仔细思考一下, 这个噪声的大小其实就用方差来度量。为了使得分布的学习尽量接近, 我们希望噪声越小越好, 所以我们会尽量使得方差趋于 0。
但是方差不能为 0 , 因为我们还想要给模型一些训练难度。如果方差为 0 , 模型永远只需要学习高斯分布的均值, 这样就丟失了随机性, VAE 就变成 AE 了...... 这就是为什么 VAE 要在 AE 前面加一个 Variational:我们希望方差能够持续存在, 从而带来噪声! 那如何解决这个问题呢? 其实保证有方差就行, 但是 VAE 给出了一个优雅的答案: 不仅需要保证有方差, 还要让所有趋于标准正态分布!为什么要这么做呢? 这里又需要一个小小的数学推导:
这条式子大家想必都看得懂, 看不懂也没事......关键是结论: 如果所有都趋于, 那么我们可以保证也趋于, 从而实现先验的假设, 这样就形成了一个闭环! 太优雅了! 那怎么让所有趋于呢? 加 loss 呗, 具体的 loss 推导这里就不做深入了, 用到了很多数学知识, 又要被公式淹没了。到此为止, 我们可以把 VAE 进一步画成:
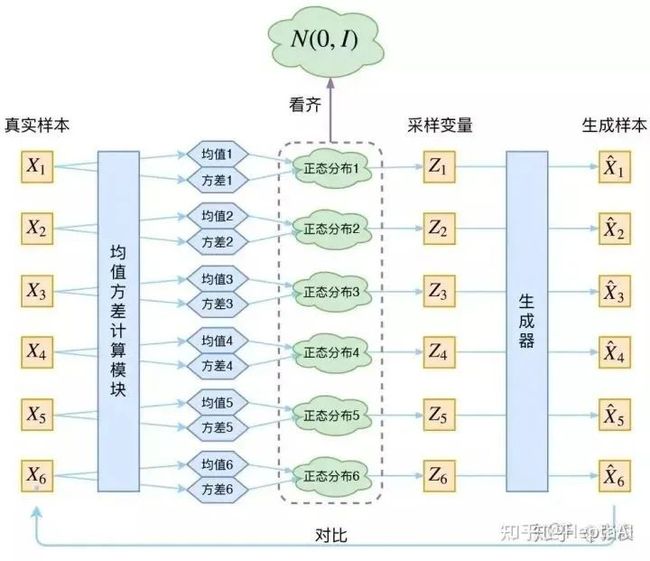
VAE 的本质
现在我们来回顾一下 VAE 到底做了啥。VAE 在 AE 的基础上对均值的 encoder 添加高斯噪声(正态分布的随机采样),使得 decoder(就是右边那个生成器)有噪声鲁棒性;为了防止噪声消失,将所有趋近于标准正态分布,将 encoder 的均值尽量降为 0,而将方差尽量保持住。这样一来,当 decoder 训练的不好的时候,整个体系就可以降低噪声;当 decoder 逐渐拟合的时候,就会增加噪声。
本质上,是不是和 GAN 很像?!要我命名,我也可以叫 VAE 是生成对抗 encoder(手动滑稽
02
Diffusion Model(扩散模型,DM)

好了,到此为止,你已经理解了扩散模型的所有基础。现在我们来站在 VAE 的基础上讲讲扩散模型。目前的教程实在是太数学了,其实可以用更加通俗的语言讲清楚。从本质上说,Diffusion 就是 VAE 的升级版。
VAE 有一个做了好几年的核心问题。大家思考一下, 上面的 VAE 中, 变分后验 是怎么获得的? 是学出来的! 用当 loss, 去学这个。学这个变分后验就有五花八门的方法了, 除了上面说的拟合法, 还有用纯数学来做的, 甚至有用 BERT 这种 PLM 来做的。但是无论如何都逃不出这个 VAE 的框架:必须想办法设计一个生成器, 使得变分后验分布尽量真实。这种方法的问题在于, 这个变分后验 的表达能力与计算代价是不可兼得的。 换句话说, 简单的变分后验表达并不丰富(例如数学公式法), 而复杂的变分后验计算过于复杂(例如 PLM 法)。
现在回过头来看看 GAN 做了啥。前面也提到过,GAN 其实就是简单粗暴,没有任何 encoder,直接训练生成器,唯一的难度在于判别器(就是下图这个“它们的分布相等吗”的东西)不好做。

好了,聪明的你也已经知道我要说什么了。Diffusion 本质就是借鉴了 GAN 这种训练目标单一的思路和 VAE 这种不需要判别器的隐变量变分的思路,糅合一下,发现还真 work 了……下面让我们来看看到底是怎么糅合的。为什么我们糅合甚至还没传统方法好,大佬糅合揉出个 diffusion?
Diffusion 的核心
知道你们都懒得划上去,我再放一下 VAE 的图。

前面也已经提到,VAE 的最大问题是这个变分后验。在 VAE 中,我们先定义了右边蓝色的生成器,再学一个变分后验来适配这个生成器。能不能反一下,先定义一个变分后验再学一个生成器呢?
如果你仔细看了上面的 VAE 部分,我相信你已经有思路了。VAE 的生成器,是将标准高斯映射到数据样本(自己定义的)。VAE 的后验分布,是将数据样本映射到标准高斯(学出来的)。那反过来,我想要设计一种方法 A,使得 A 用一种简单的“变分后验”将数据样本映射到标准高斯(自己定义的),并且使得 A 的生成器,将标准高斯映射到数据样本(学出来的)。注意,因为生成器的搜索空间大于变分后验,VAE 的效率远不及 A 方法:因为 A 方法是学一个生成器(搜索空间大),所以可以直接模仿这个“变分后验”的每一小步!
好,现在我告诉你,这个 A 方法就是扩散模型(Diffusion Model)的核心思路:定义一个类似于“变分后验”的从数据样本到高斯分布的映射,然后学一个生成器,这个生成器模仿我们定义的这个映射的每一小步。
Diffusion Model 的 Diffusion 到底是个啥
接触 diffusion 的你肯定知道马尔可夫链!这东西不仅 diffusion 里面有,各种怪异的算法里面也都出现了。为什么用它?因为它的一个关键性质:平稳性。一个概率分布如果随时间变化,那么在马尔可夫链的作用下,它一定会趋于某种平稳分布(例如高斯分布)。只要终止时间足够长,概率分布就会趋近于这个平稳分布。
这个逐渐逼近的过程被作者称为前向过程(forward process)。注意,这个过程的本质还是加噪声! 试想一下为什么……其实和 VAE 非常相似,都是在随机采样!马尔可夫链每一步的转移概率,本质上都是在加噪声。这就是扩散模型中“扩散”的由来:噪声在马尔可夫链演化的过程中,逐渐进入 diffusion 体系。随着时间的推移,加入的噪声(加入的溶质)越来越少,而体系中的噪声(这个时刻前的所有溶质)逐渐在 diffussion 体系中扩散,直至均匀。看看下面的图,你应该就恍然大悟了:

现在想想,为什么要用马尔可夫链。我们把问题详细地重述一下:为什么我们创造一个稳定分布为高斯分布的马尔可夫链,对于生成器模仿我们定义的某个映射的每一小步有帮助呢?这里你肯定想不出来,不然你也能发明 diffusion model ——答案是,基于马尔可夫链的前向过程,其每一个 epoch 的逆过程都可以近似为高斯分布。
懵了吧,我也懵了。真正的推导发了好几篇 paper,都是些数学巨佬的工作,不得不感叹基础科学的力量……相关工作主要用的是 SDE(随机微分方程),我们在这里不做深入,但是需要理解大致的思路,如下图所示。
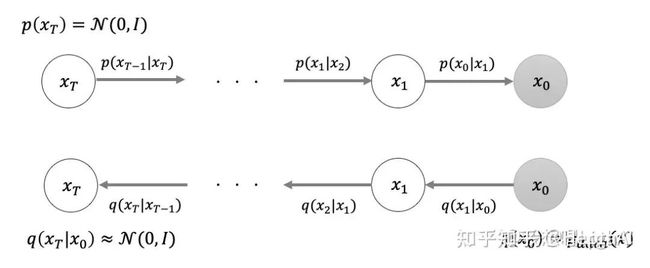
图源:https://www.zhihu.com/question/536012286/answer/2533146567
下面的是前向过程,上面的是反向过程。前向过程通过马尔可夫链的转移概率不断加入噪音,从右边的采样数据到左边的标准高斯;反向过程通过 SDE 来“抄袭”对应正向过程的那一个 epoch 的行为(其实每一步都不过是一个高斯分布),从而逐渐学习到对抗噪声的能力。高斯分布是一种很简单的分布,运算量小,这一点是 diffusion 快的最重要原因。
Diffusion 的本质
现在回头看看 diffusion 到底做了个啥工作。我们着重看一下下图的 VAE 和 diffussion 的区别:

图源:https://zhuanlan.zhihu.com/p/525106459
可以很清晰的认识到,VAE 本质是一个基于梯度的 encoder-decoder 架构,encoder 用来学高斯分布的均值和方差,decoder 用变分后验来学习生成能力,而将标准高斯映射到数据样本是自己定义的。而扩散模型本质是一个 SDE/Markov 架构,虽然也借鉴了神经网络的前向传播/反向传播概念,但是并不基于可微的梯度,属于数学层面上的创新。两者都定义了高斯分布作为隐变量,但是 VAE 将作为先验条件(变分先验),而 diffusion 将作为类似于变分后验的马尔可夫链的平稳分布。
想要更深入的理解?
文章的定位本身就是让读者读懂 diffusion 而非对 diffusion 框架本身进行数学创新,是应用向而非结构向的,大佬们如果希望看到更深入的分析可以追更和评论区催更~
03
参考资料

https://zhuanlan.zhihu.com/p/34998569
https://www.zhihu.com/question/536012286/answer/2533146567
https://zhuanlan.zhihu.com/p/525106459
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~