大数据技术平台
文章目录
概要
雾霾天气预测过程是一个较为复杂的过程,首先必须要准备一个平台来对气象数据作相应的处理,包括:数据存储、数据处理、数据分析和预测结果的展示。
想要做好雾霾天气的预测,需要做一些准备工作,首先解决气象数据的获取,然后存储气象因素这样的大数据,之后利用数据分析技术和方法实施雾霾天气的预测。对于气象数据的获取,可以通过气象部门的地面传感器等工具进行采集,也可以通过卫星等采集卫星云图等数据;或者到专门数据交易平台进行交易,也可以利用爬虫算法实现气象数据的获取,数据获取手段较多,根据自己的实际情况来获取研究数据。采集到的天气数据必须要进行存储,对于这样的大数据如何进行存储,通过什么样的方式进行存储,可以有效地提高大数据存储速度和管理效率,以及对大数据进行安全操作;当数据存储不存在问题时,如何对数据进行处理和分析,得到未来一天或者几天的天气到底是不是雾霾天气的预测,这就需要大数据处理和分析的平台来帮助处理和分析气象数据。目前,市场上存在的大数据处理和分析平台非常多,有开源的、商业的等不同形式的平台。当然,谈到大数据处理和分析平台不得不去了解Hadoop。
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海数据的处理能力。几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等都支持Hadoop。另外,阿里云也提供了一个商业的大数据存储和处理平台,功能丰富,界面好,易于对大数据进行相关的操作。
1.1、大数据定义
大数据定义
定义:大数据主要解决,海量数据的采集、存储、分析计算问题。
特点:Volume(大量) Velocity(高速) Variety(多样) Value(低价值密度)
1.2、Hadoop简介
- Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
- Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
- Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
- Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
- 几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
1.3 hadoop版本
Hadoop1.x组成: MapReduce(计算+资源调度) + HDFS (数据存储) + Common (辅助工具)
Hadoop2.x组成 :MapReduce (计算) + Yarn (资源调度) + HDFS (数据存储) + Common (辅助工具)
Hadoop3.x在组成上没有变化。 在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。在Hadoop2.x时代,增 加了Yarn。Yarn只负责 .资源的调度,MapReduce只负责运算。
1.4Hadoop的特性
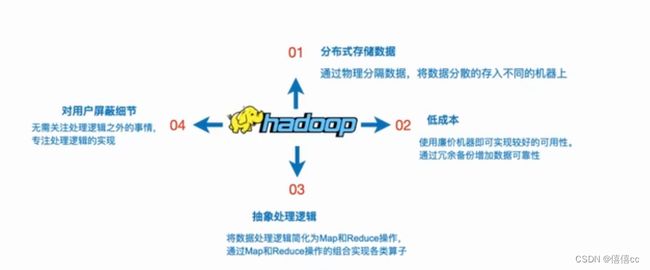
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是一种可靠、高校、可伸缩的方式进行处理的,它具有以下几个方面的特征:
①高可靠性:采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
②高效性:作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。
③高可扩展性:Hadoop的设计
目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
④高容错性:采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
⑤成本低:Hadoop 采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC搭建Hadoop运行环境。
⑥运行在Linux平台上:Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
⑦支持多种编程语言:Hadoop上的应用程序也可以使用其他语言编写,如C++。
1.5Hadoop的应用现状
- 国外:Facebook等
- 国内:百度、淘宝、网易、华为、中国移动等,其中,淘宝的Hadoop集群比较大
- Hadoop在企业中的应用架构
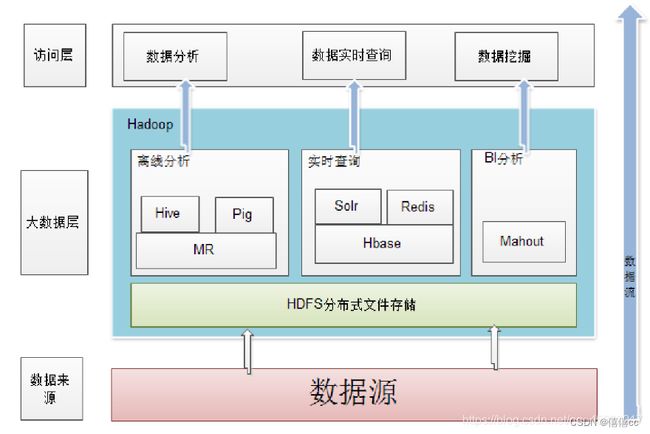
二.大数据生态圈
1.数据存在面临的瓶颈与挑战
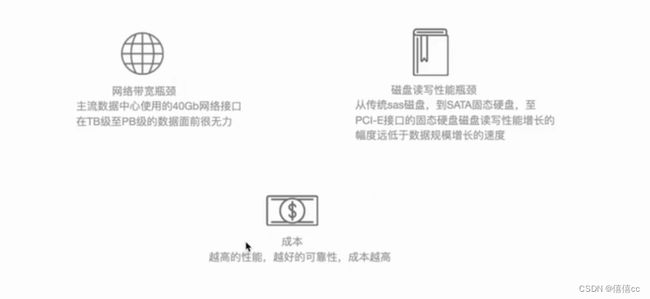
Hadoop有狭义和广义之说
(1)狭义的Hadoop就是指Hadoop框架本身而已,有三个重要组成部分
HDFS (Hadoop 分布式文件系统,存储)
MapReduce (分布式离线计算框架,计算)
Yarn (分布式离线框架,资源协调)
 (2)广义的Hadoop指的是一个生态系统/生态圈,包含Hadoop框架之后的很多大数据技术栈
(2)广义的Hadoop指的是一个生态系统/生态圈,包含Hadoop框架之后的很多大数据技术栈
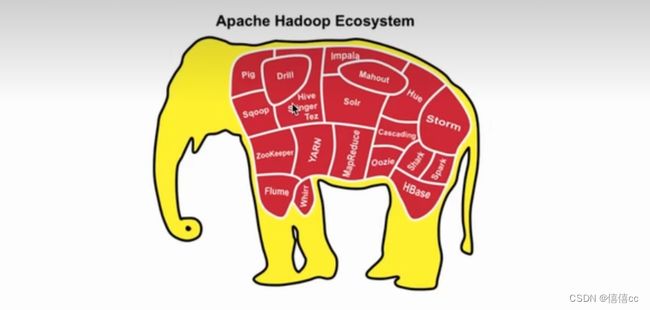
为什么说Hadoop处于大数据领域的“王者”地位,已经成为大数据的代名词?
- Hadoop是大数据领域第一个真正意义上的框架
- 我们说,大数据技术解决海量数据存储和海量数据计算,Hadoop中有 HDFS 完成存储,MapReduce0完成计算。从计算的角度说虽然后面出现了其他的计算引擎,但是它们都参考了MapReduce;至于存储,一直都有使用HDFS,HDFS的地位始终无法撼动
- Hadoop是一个大圈子,囊括性很强
2.Hadoop项目结构
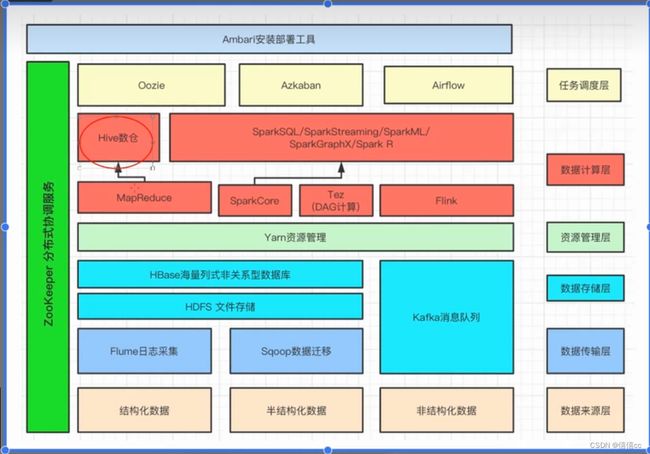
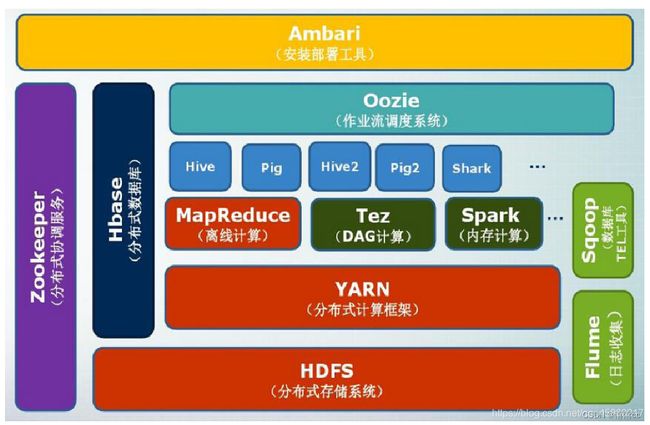
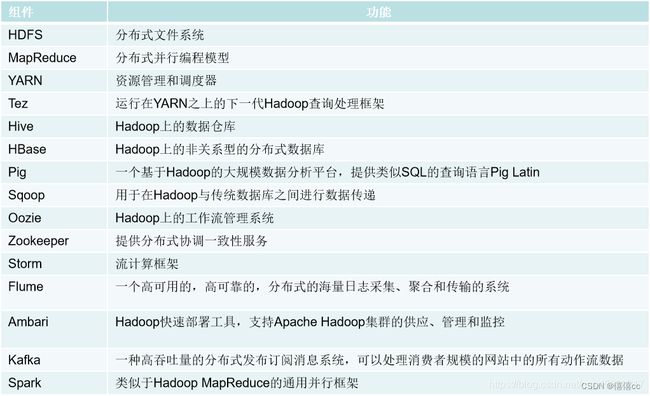
3.阿里云大数据平台
概述:
是阿里云提供的一站式的数据分析和应用平台。工程师十几年相关经验的积累,阿里云把这些经验统一汇总,通过服务的方式供我们使用。用户可以根据不同的应用场景去使用数加不同的数据服务,使用这些服务时不需要自己搭建底层的数据集群(数据架构)
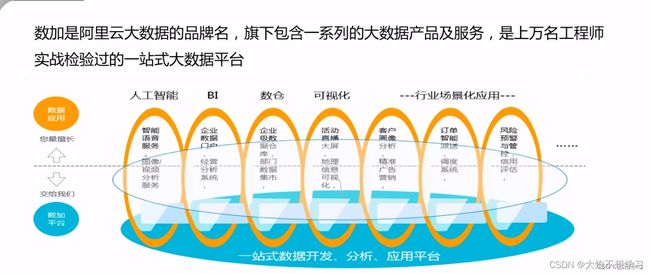
“数加”是阿里云大数据的核心能力
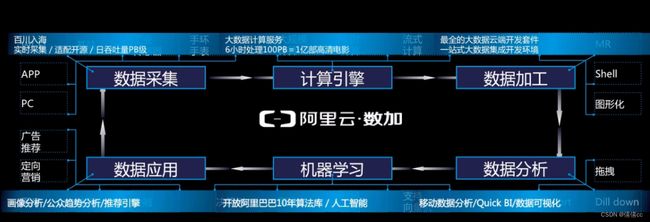
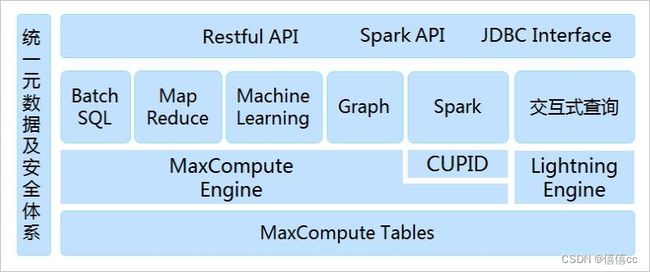
1 MaxCompute
1.1 简介
MaxCompute大数据计算服务,原名为ODPS(Open Data Processing Service),为阿里云的数据仓库解决方案,提供大数据量(百TB、PB、EB)的结构化数据的存储和计算服务。
1.2 分布式
MaxCompute为实现超大数据量的存储以及计算性能,它底层采用分布式存储以及分布式计算引擎。
1.3 计算模型
MaxCompute支持SQL、MapReduce、UDF(Java/Python)、Graph、基于DAG的处理、交互式、内存计算、机器学习等计算类型及MPI迭代类算法。
什么是MaxCompute?
大数据计算服务MaxCompute(原名ODPS)是一种快速、完全托管的EB级数据仓库解决方案。
随着数据收集手段不断丰富,行业数据大量积累,数据规模已增长到了传统软件行业无法承载的海量数据(TB、PB、EB)级别。MaxCompute致力于批量结构化数据的存储和计算,提供海量数据仓库的解决方案及分析建模服务。
由于单台服务器的处理能力有限,海量数据的分析需要分布式的计算模型。分布式的计算模型对数据分析人员要求较高且不易维护。数据分析人员不仅需要了解业务需求,同时还需要熟悉底层分布式计算模型。MaxCompute为您提供完善的数据导入方案以及多种经典的分布式计算模型,您可以不必关心分布式计算和维护细节,便可轻松完成大数据分析。
目前,MaxCompute服务已覆盖全球16个国家和地区,客户遍及金融、互联网、生物医疗、能源、交通、传媒等行业,为全球用户提供海量数据存储和计算服务。MaxCompute的多个客户案例荣获“2017大数据优秀产品和应用解决方案案例”奖。此外,MaxCompute、DataWorks以及AnalyticDB代表阿里云入选了Forrester Wave™ Q4 2018云数据仓库报告。
说明 MaxCompute已经在阿里巴巴集团内部得到大规模应用,例如大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。
DataWorks和MaxCompute关系紧密,DataWorks为MaxCompute提供一站式的数据同步、业务流程设计、数据开发、管理和运维功能,详情请参见什么是DataWorks。
1.MaxCompute SQL
- (TB级别)实时性要求不高的场合
- 结果化查询语言
2.MaxComputeMapReduce
- 编程模型
- 并行计算
3.图计算Graph
- 图处理计算框架
- 基于graph框架开发高效的机器学习或者数据挖掘算法
产品优势
- 大规模计算存储
MaxCompute适用于100GB以上规模的存储及计算需求,最大可达EB级别。
- 多种计算模型
MaxCompute支持SQL、MapReduce、UDF(Java/Python)、Graph、基于DAG的处理、交互式、内存计算、机器学习等计算类型及MPI迭代类算法。简化了企业大数据平台的应用架构。
- 强数据安全
MaxCompute已稳定支撑阿里全部数据仓库业务9年以上,提供多层沙箱防护、细粒度权限管理及监控。
MaxCompute通过了独立
的第三方审计师针对阿里云对AICPA可信服务标准中关于安全性、可用性和机密性原则符合性描述的审计。审计报告请参见SOC 3报告。
- 低成本
与企业自建专有云相比,MaxCompute的计算存储更高效,可以降低30%~50%的采购成本。
- 免运维
基于MaxCompute的Serverless无服务器的设计思路,用户只需关心作业和数据,而无需关心底层分布式架构及运维。
- 极致弹性扩展
MaxCompute提供按量付费模式下的作业级别的资源管理。用户无需受困于资源扩展难题,系统会自动扩展计算、存储、网络等资源,最大程度地节省成本。
MaxCompute以数据为中心,内建多种计算模型和服务接口,满足广泛的数据分析需求。一切服务“开通”即用,更好地赋能数据业务。