Image Caption:图像字幕生成
前言
图像处理与自然语言处理的结合,给图像加字幕或者描述。应用前景非常广,比如早教,图像检索,盲人导航等。图像注释问题的通用解法非常接近于Encoder-Decoder结构,下面就几种方法作简单总结。
m-RNN
Mao这篇2015-paper,根据输入语句和图片,为图片生成字幕;以DeepRNN 处理语句,用CNN处理图片。基本思路:直接将图像表示和词向量以及隐向量作为多模判断的输入。

左侧是简单RNN结构,右侧是本文所提的m-RNN(多模式),输入是图片极其对应的语句描述。模型根据之前词和图像来评估下个词的概率分布,每一时间帧上,所有的权重都是共享的。
两层embedding,分别表示语法和语义含义,初始化方法采用随机初始化足矣,不用专用使用pre-trained的词向量。其中多模式模块有三个输入:词向量 w(t) w ( t ) ,隐状态 r(t) r ( t ) ,图像表示 I I 。隐状态
关于图像的表示,“For the image representation, here we use the activation of the 7th layer of AlexNet (Krizhevsky et al. (2012)) or 15th layer of VggNet (Simonyan & Zisserman (2014))”。
优化函数如下:
Deep Visual-Semantic
Li FeiFei的深度视觉语义2015-paper,听着很高大上,做起来也确实很高大上,复杂的很。跟上篇文章输入是一致的,在思路上略有不同,将图像和语言序列压缩到一个空间内。
面临的两个挑战: 1. 需要设计一个足够好的模型,既能够推理图像内容,又能够推理自然语言部分。2. 自然语句描述中涉及的实体在图中的位置是未知的。

前提假设:语句会频繁地引用图中特定但未知的位置。将词与图像中特定位置映射到通用空间内,学习embedding表达,使其在两种模式(图像和语言)下,语义相似的概念占据空间的相似位置。多模式:指的是,embedding空间既可以给图像用,有可以给序列用。
图像的表示:使用RCNN,来学习实体对应的局部 v=Wm[CNNθc(Ib)]+bm v = W m [ C N N θ c ( I b ) ] + b m ;序列的表示: BRNN来表示词
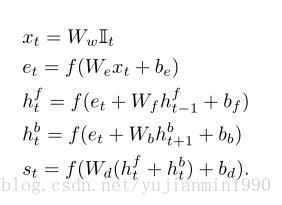
v v 和s s 如何保证在同一个空间内呢?是在学习目标上加以约束。图文的匹配度衡量: Skl S k l ,非常赞的方法。
这里,每个词 st s t 关联到 唯一的最匹配的图片区域。这一简化模型同样可以在最终的排序表现中起到非常好改进效果。假设 k=l k = l 表示对应的图片和语句对,最终的max-margin, structured losss如下:
这一目标收敛于当图片与语句对的关联具有最高分时,而非误匹配的对,by a margin。
使用MRF解码图对应的文本片段,这里也是整个方法复杂度变高的地方。我们将 vTist v i T s t 解释为 tth t t h 词描述任意某个图区域的的非标准化的log概率。
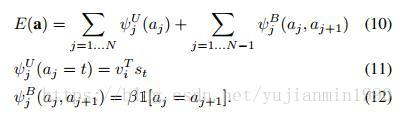
其中 β β 是控制长词短语映射的超参,当 β=0 β = 0 时,表示单个词之间的交互。输出是图像的一些局部区域带着描述片段词句。
整体结构示意图

Image Caption using Attention
在生成图像的某部分描述时,为了能够集中于图像某部分,K Xu于2015年引入Attention机制,命名为Visual Attention。分别定义了两种Attention机制:Stochastic Hard Attention 和 Deterministic Soft Attention,都可以压缩一张图片用以生成一段语言描述。
使用卷积网络CNN来提取图像特征作为解释变量,提取 L L 个解释向量,每一个都表示了图像的某一部分。a={a1,a2,...,aL},ai∈RD a = { a 1 , a 2 , . . . , a L } , a i ∈ R D ,为了能够描述更基础的图像特征,在底层卷积层上来抽取解释向量;用LSTM来作为解码器,生成描述语句。
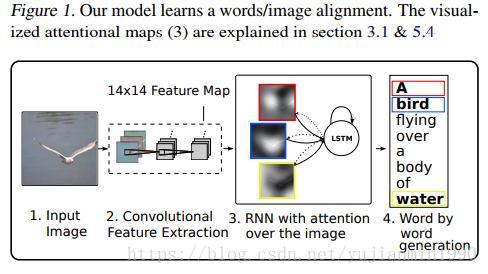
1)Stochastic Hard Attention
st,i=1 s t , i = 1 表示生成第 t t 个词时,第i i 部分图像被关注(一共 L L 部分)。将注意位置作为隐变量,可以将由解释变量ai a i 确定的上下文 z^t z ^ t 看作是随机变量【一方面,为随机选择关注部分图像作解释,一方面为采样寻优方法作约束】。
定义目标函数 Ls L s ,其下限值逼近于 logp(y|a) l o g p ( y | a )
上式指出基于MonteCarlo的采样方法来估计参数梯度是可行的,通过对 αi α i 决定的Multinoulli分布采样具体位置 st s t ,来估计参数导数,如下:
引入滑动平均来降低估计方差波动,对第 k k 个mini-batch,如下处理:
为进一步降低估计方差,引入熵 H[s] H [ s ] ,
最终的梯度如下:
λr和λe λ r 和 λ e 是两个超参,上述式子相当于强化学习,对注意集中的后续动作收益是目标句子的似然概率值,在采样注意策略下。
为什么称之为Hard Attention呢?是因为上下文 z^ z ^ 所用的解释向量是通过服从 αi α i 的分布采样得来的。
2)Deteriministic Soft Attention
若是不使用采样,而是直接使用所有的区域,就变成了soft attention,在Bahdanau的15年文章里就是类似的方法。
思考总结
1)基本方法大同小异:将图像和词表示在同一空间内是共同点。
2)应用的难度在于,实际环境更为复杂,即使有Attention机制也没有特别精确。
Reference
- 2015 - 《Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN)》
- 2015 - 《Deep Visual-Semantic Alignments for Generating Image Descriptions》
- 2015 - 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》