rocky 系统 ---- Kubernetes(k8s)安装以及搭建详解
一、前期准备
三台兼容的 Linux 主机
| 机器类型 | 操作系统 | IP | 节点类型 |
|---|---|---|---|
| VMware虚拟机 | rocky 9.0 | 192.168.45.132/24 | k8s-master |
| VMware虚拟机 | rocky 9.0 | 192.168.45.133/24 | k8s-node1 |
| VMware虚拟机 | rocky 9.0 | 192.168.45.134/24 | k8s-node2 |
| 修改主机名 |
# 在192.168.45.132执行
hostnamectl set-hostname k8s-master && bash
# 在192.168.45.133执行
hostnamectl set-hostname k8s-node1 && bash
# 在192.168.45.134执行
hostnamectl set-hostname k8s-node2 && bash
时间同步(全部机器操作)
yum install chrony -y
systemctl start chronyd
systemctl enable chronyd
chronyc sources
允许 iptables 检查桥接流量(可略过)
cat <手动加载所有的配置文件
$ sudo sysctl --system
所需端口
master节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API 服务器 | 所有组件 |
| TCP | 入站 | 2379-2380 | etcd | 服务器客户端 API |
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 |
| TCP | 入站 | 10251 | kube-scheduler | kube-scheduler 自身 |
| TCP | 入站 | 10252 | kube-controller-manager | kube-controller-manager 自身 |
node节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 |
| TCP | 入站 | 30000-32767 | NodePort 服务 | 所有组件 |
二、安装 runtime
为了在 Pod 中运行容器,Kubernetes 使用 容器运行时(Container Runtime)。
默认情况下,Kubernetes 使用 容器运行时接口(Container Runtime Interface,CRI) 来与你所选择的容器运行时交互。
如果你不指定运行时,则 kubeadm 会自动尝试检测到系统上已经安装的运行时, 方法是扫描一组众所周知的 Unix 域套接字。 下面的表格列举了一些容器运行时及其对应的套接字路径:
| 运行时 | 域套接字 |
|---|---|
| Docker | /var/run/dockershim.sock |
| containerd | /run/containerd/containerd.sock |
| CRI-O | /var/run/crio/crio.sock |
如果同时检测到 Docker 和 containerd,则优先选择 Docker。 这是必然的,因为 Docker 18.09 附带了 containerd 并且两者都是可以检测到的, 即使你仅安装了 Docker。 如果检测到其他两个或多个运行时,kubeadm 输出错误信息并退出。
kubelet 通过内置的 dockershim CRI 实现与 Docker 集成。
装完docker后会仅有containerd
containerd简介
containerd是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性。containerd可以在宿主机中管理完整的容器生命周期,包括容器镜像的传输和存储、容器的执行和管理、存储和网络等。
Docker vs containerd
containerd是从Docker中分离出来的一个项目,可以作为一个底层容器运行时,现在它成了Kubernete容器运行时更好的选择。
K8S为什么要放弃使用Docker作为容器运行时,而使用containerd呢?
如果你使用Docker作为K8S容器运行时的话,kubelet需要先要通过 dockershim 去调用Docker,再通过Docker去调用containerd。
如果你使用containerd作为K8S容器运行时的话,由于containerd内置了 CRI (Container Runtime Interface:容器运行时接口)插件,kubelet可以直接调用containerd。
所有机器安装docker步骤如下
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
sudo yum install -y docker-ce
# 启动
sudo systemctl start docker
# 开机自启
sudo systemctl enable docker
# 查看版本号
sudo docker --version
# 查看版本具体信息
sudo docker version

Docker镜像源设置
# 修改文件 /etc/docker/daemon.json,没有这个文件就创建
# 添加以下内容后,重启docker服务:
cat > /etc/docker/daemon.json <三、安装 kubeadm、kubelet 和 kubectl
你需要在所有机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
kubectl:用来与集群通信的命令行工具。
kubeadm 不能帮你安装或者管理 kubelet 或 kubectl,所以你需要 确保它们与通过 kubeadm 安装的控制平面的版本相匹配。 如果不这样做,则存在发生版本偏差的风险,可能会导致一些预料之外的错误和问题。
1)配置hosts 3台都要执行
cat <<EOF>> /etc/hosts
192.168.45.134 k8s-node1
192.168.45.133 k8s-node2
192.168.45.132 k8s-master
EOF
# 查看
cat /etc/hosts
2)关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
3)关闭swap
kubelet 在 1.8 版本以后强制要求 swap 必须关闭。要不然kubelet 无法正常启动
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
4)将 SELinux 设置为 disabled模式(相当于将其禁用)
# 临时关闭
sudo setenforce 0
# 永久禁用
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
5)配置yum源,这里配置阿里云的源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
EOF
6)开始安装kubeadm,kubelet和kubectl
sudo yum install -y kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
查了下资料, k8s已经弃用了docker了,如果yum直接安装 kubelet kubeadm kubect的话 是V1.24版本 V1.24版本就会出现错误,安装的时候需要指定一下1.23版本
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
sudo systemctl enable --now kubelet
# 查看状态
systemctl status kubelet
查看状态会发现

重新安装(或第一次安装)k8s,未经过kubeadm init 或者 kubeadm join后,kubelet会不断重启,这个是正常现象,执行init或join后问题会自动解决,对此官网有如下描述,也就是此时不用理会kubelet.service。
先查看k8s版本
kubectl version
yum info kubeadm

7)使用 kubeadm 创建集群(master节点)
初始化,–kubernetes-version版本就是上面查询出来的,可以不写,默认会自动获取版本,–image-repository:默认是官网k8s.gcr.io,但是很慢,这里换成了阿里云的;–apiserver-advertise-address=192.168.0.113:这里的ip为master节点ip,记得更换。
kubeadm init \
--apiserver-advertise-address=192.168.45.132 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
# –image-repository string: 这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
# –kubernetes-version string: 指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(v1.22.1)来跳过网络请求。
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
以下是各种报错处理
报错一: CPUs 1 is less than the required 2
处理方式:CPU 最小需要2c 添加CPU
报错二:
这个报错原因是因为安装kubeadm,kubelet和kubectl时,没有指定版本,安装的是最新版,需要重新卸载,安装;
命令如下
yum remove kubelet kubeadm kubectl
yum -y install kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6

报错三:
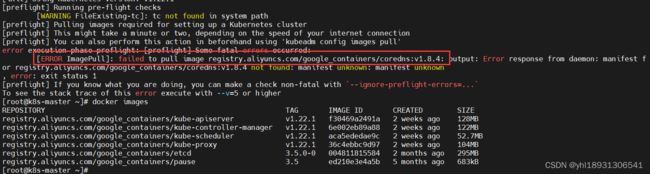
registry.aliyuncs.com/google_containers/coredns:v1.8.4 not found 【解决】
由于安装的是Kubernetes
v1.22.1版本,在初始化的时候报错信息中提示需要registry.aliyuncs.com/google_containers/coredns:v1.8.4版本的coredns镜像,手动拉取registry.aliyuncs.com/google_containers/coredns:v1.8.4版本的镜像时发现没有,所以就只能拉取一个默认版本的阿里云coredns镜像,拉取下来之后自己再手动修改一下镜像的tag信息为v1.8.4版本。
命令如下#手动拉取默认版本的coredns镜像
docker pull registry.aliyuncs.com/google_containers/coredns
#查看拉取下来的coredns镜像
docker images
将拉取的默认版本的coredns镜像tag信息修改为v1.8.4版本
docker tag registry.aliyuncs.com/google_containers/coredns:latest registry.aliyuncs.com/google_containers/coredns:v1.8.4
查看
docker images
registry.aliyuncs.com/google_containers/coredns v1.8.4 a4ca41631cc7 10 months ago 46.8MB

报错4:
这个报错:
[kubelet-check] It seems like the kubelet isn’t running or healthy.
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz’ failed with error: Get “http://localhost:10248/healthz”: dial tcp [::1]:10248: connect: connection refused.
说明:
docker 和 kubelet 服务中的 cgroup 驱动不一致,
有两种方法 方式一:驱动向 docker 看齐 方式二:驱动为向kubelet 看齐
如果docker 不方便重启则统一向 kubelet看齐,并重启对应的服务即可
解决方式
docker 配置文件
这里采取的是方式二,docker 默认驱动为 cgroupfs ,只需要添加vim /etc/docker/daemon.json
“exec-opts”: [
“native.cgroupdriver=systemd”
],
添加完的配置文件如下:
more /etc/docker/daemon.json
{
“exec-opts”: [
“native.cgroupdriver=systemd”
],
“registry-mirrors”: [“http://hub-mirror.c.163.com”]
}kublete 配置文件
grep 截取一下,可以看得出来kubelet默认 cgoup 驱动为systemd
cat /var/lib/kubelet/config.yaml |grep group
cgroupDriver: systemd重启docker
systemctl restart docker
刷新-初始化kubeadm
kubeadm reset

这一步无需操作,请注意,只是作者标注命令:
docker 删除所有镜像命令:
docker rmi $(docker images -qa)
再执行下面初始化命令
kubeadm init \
--apiserver-advertise-address=192.168.45.132 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16

根据上图提示,要使非 root 用户可以运行 kubectl,请运行以下命令, 它们也是 kubeadm init 输出的一部分:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#或者,如果你是 root 用户,则可以运行,这里我使用root用户,但是生产环境一般不会用root用户的:
#临时生效(退出当前窗口重连环境变量失效)
export KUBECONFIG=/etc/kubernetes/admin.conf
#永久生效(推荐)
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
**如果不加入环境变量,会出现如下报错:

**
8)安装Pod网络插件(CNI:Container Network Interface)(master)
你必须部署一个基于 Pod 网络插件的 容器网络接口 (CNI),以便你的 Pod 可以相互通信。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果上面安装失败,则下载百度里的,离线安装
链接:https://pan.baidu.com/s/1w83UWxMmVo1U_A_rj-K7TA
提取码:8888
kubectl apply -f kube-flannel.yml
docker images
查看集群信息
kubectl get nodes

9)Node节点加入集群
如果没有令牌,可以通过在控制平面节点上运行以下命令来获取令牌:
kubeadm token list
默认情况下,令牌会在24小时后过期。如果要在当前令牌过期后将节点加入集群, 则可以通过在控制平面节点上运行以下命令来创建新令牌:
kubeadm token create
# 再查看
kubeadm token list
![]()
如果你没有 --discovery-token-ca-cert-hash 的值,则可以通过在控制平面节点上执行以下命令链来获取它:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
如果执行kubeadm init时没有记录下加入集群的命令,可以通过以下命令重新创建(推荐)一般不用上面的分别获取token和ca-cert-hash方式,执行以下命令一气呵成:
kubeadm token create --print-join-command
kubeadm join 192.168.45.132:6443 --token pwf4a4.dh7x99bn35bs1ut3 \
--discovery-token-ca-cert-hash sha256:28159b5c726af4405f643b2c9e3576c651c68a314eb34a16b0c4669b3b8551ca
![]()
以下命令在node节点执行
两台node都执行
kubeadm join 192.168.45.132:6443 --token pwf4a4.dh7x99bn35bs1ut3 \
--discovery-token-ca-cert-hash sha256:28159b5c726af4405f643b2c9e3576c651c68a314eb34a16b0c4669b3b8551ca
报错:这里可能会报错 localhost:10248拒绝访问,这个处理方式如上,docker配置文件修改一下就好了
解决查看:kubeadm 创建集群报错4处理方法 如上
查看集群信息
如果在node节点查看信息报错如下
kubectl get nodes
报错:
![]()
【解决】
重置节点信息
kubeadm reset
需要将master节点的 /etc/kubernetes/admin.conf复制到node节点的相同位置
scp -r $HOME/.kube 192.168.45.133:
scp -r $HOME/.kube 192.168.45.134:
执行下面的代码加入环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
修改docker的cgroup driver,修改或创建/etc/docker/daemon.json,加入下述内容:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
重新加载
systemctl daemon-reload
systemctl restart docker
docker info | grep Cgroup

kubectl get nodes

安装flannel网络插件,采用离线安装,kube-flanel.yml文件上面有
kubectl apply -f kube-flannel.yml
将node节点加入到集群中
kubeadm token create --print-join-command
--v=5:显示详细信息
kubeadm join 192.168.45.132:6443 --token cgmxso.bfgou00m72tnbpz4 --discovery-token-ca-cert-hash sha256:b4792b0f3b54c8b8b71a4a484129b4e2acfe5014c37b1b18dbebbc0c8f69fc15 --v=5
另一个node节点同上操作
报错:STATUS一直为NotReady
首先使用如下命令来看一下kube-system的 pod 状态
kubectl get pod -n kube-system
kubectl get pod -n kube-system -o wide
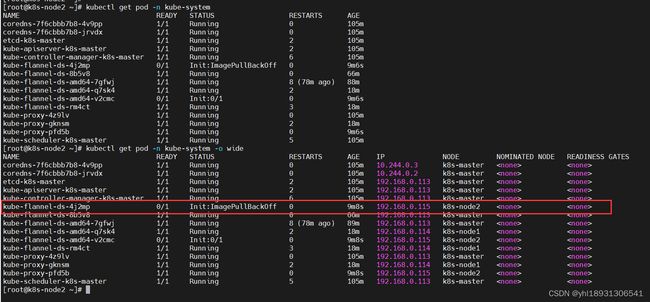
如上,可以看到 pod kube-flannel 的状态是ImagePullBackoff,意思是镜像拉取失败了,所以我们需要手动去拉取这个镜像。这里可以看到某些 pod 运行了两个副本是因为我有两个节点存在了。
也可以通过kubectl describe pod -n kube-system <服务名>来查看某个服务的详细情况,如果 pod 存在问题的话,你在使用该命令后在输出内容的最下面看到一个[Event]条目,如下:
kubectl describe pod kube-flannel-ds-4j2mp -n kube-system

处理:手动拉取镜像
docker pull quay.io/coreos/flannel:v0.14.0
修改完了之后过几分钟 k8s 会自动重试,等一下就可以发现不仅flannel正常了,其他的 pod 状态也都变成了Running,这时再看 node 状态就可以发现问题解决了:

四、清理
如果你在集群中使用了一次性服务器进行测试,则可以关闭这些服务器,而无需进一步清理。你可以使用 kubectl config
delete-cluster 删除对集群的本地引用。
1)先将节点设置为维护模式(k8s-node1是节点名称)
kubectl drain k8s-node1 --delete-local-data --force --ignore-daemonsets
2)在删除节点之前,请重置 kubeadm 安装的状态:
kubeadm reset
3)重置过程不会重置或清除 iptables 规则或 IPVS 表。如果你希望重置 iptables,则必须手动进行:
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
4)如果要重置 IPVS 表,则必须运行以下命令:
ipvsadm -C
5)现在删除节点:
kubectl delete node k8s-node1
五、搭建K8S Dashboard
1)下载dashboard文件:
curl -o kubernetes-dashboard.yaml https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended/kubernetes-dashboard.yaml
如果地址不可用可以使用下面的地址下载
链接:https://pan.baidu.com/s/197hmZAK4LLxSrViQFC-iEg
提取码:8888
安装
kubectl apply -f kubernetes-dashboard.yaml
验证,查看服务被分配到哪个节点上:
kubectl get pods -n kube-system -o wide

从上图可知,服务被分配到了k8s-node1,对外端口为nodePort:31080,配置文件里的。
谷歌浏览器访问不了,原因是部署UI的镜像中默认自带的证书是一个不可信任的证书,则先用火狐访问:https://nodeIp:nodePort
https://192.168.45.133:31080
获取token测试
kubectl get secret -n kube-system|grep kubernetes-dashboard-token
# 根据自己情况输入命令
kubectl describe secret kubernetes-dashboard-token-cnsx4 -n kube-system

选中token码,复制到令牌上,点击登陆
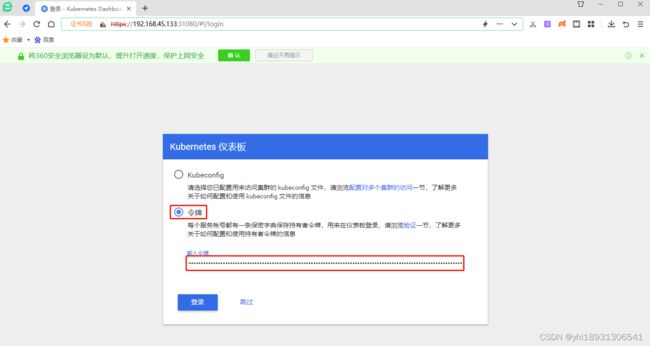
解决谷歌浏览器不能访问的问题,通过生成新的证书永久解决
# 创建一个用于自签证书的目录
mkdir kubernetes-dashboard-key && cd kubernetes-dashboard-key
# 生成证书请求的key
openssl genrsa -out dashboard.key 2048
# 192.168.45.132为master节点的IP地址
openssl req -new -out dashboard.csr -key dashboard.key -subj '/CN=192.168.45.132'
# 生成自签证书
openssl x509 -req -in dashboard.csr -signkey dashboard.key -out dashboard.crt
# 删除原有证书
kubectl delete secret kubernetes-dashboard-certs -n kube-system
# 创建新证书的secret
kubectl create secret generic kubernetes-dashboard-certs --from-file=dashboard.key --from-file=dashboard.crt -n kube-system
# 查找正在运行的pod
kubectl get pod -n kube-system
# 删除pod,让k8s自动拉起一个新的pod,相对于重启
kubectl delete pod kubernetes-dashboard-7b4f79c84d-ndc65 -n kube-system
# 再次查看,会自动生成一个pod。
kubectl get pod -n kube-system
kubectl get pods -n kube-system -o wide
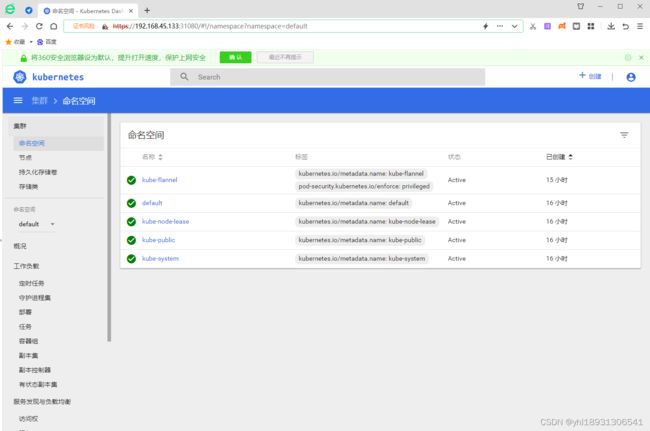
服务调度到了node2上了,使用Google访问: https://192.168.45.134:31080

输入token登录
如果刚刚生成的 token 忘记了,需要重新申请,使用下面命令:
kubectl get secret -n kube-system|grep kubernetes-dashboard-token
# 根据自己情况输入命令
kubectl describe secret kubernetes-dashboard-token-cnsx4 -n kube-system
完成。
以上就是k8s 集群安装流程。