论文笔记:S2SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
论文笔记:S2SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
目录
- 论文笔记:S2SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers
- 导语
- 摘要
- 1 简介
- 2 提出的方法
-
- 2.1 问题定义
- 2.2 Question-Schema Interaction Graph
-
- 注入句法
- 解耦约束
- 3 实验
-
- 3.1 实验设置
- 3.2 实现细节
- 3.3 Baseline模型
- 3.4 结果分析
-
- 整体性能表现
- Ablation Study
- 3.5 定性分析
- 3.6 关于Parser
- 4 相关工作
- 5 总结
导语
- 会议:ACL 2022 Findings
- 地址:https://arxiv.org/abs/2203.06958
摘要
Text-to-SQL任务是Semantic Parsing任务中的一个重要分支。目前最先进的基于图编码器的模型已经被很好的应用于该任务,但是它们并没有对问题的句法进行很好的建模。本文提出了S2SQL,向Text-to-SQL中基于Question-Schema的图编码器的parser中注入句法信息,有效地利用了Text-to-SQL的问题的语法依赖信息,提高了性能。我们还利用解耦约束引入不同的关系边缘嵌入,进一步提高了网络的性能。在Spider上的实验和在稳健性设置的数据集Spider-Syn上的实验表明,在使用预训练模型时,本文提出的方法优于所有现有方法,在Spider排行榜上的性能排名第一。
1 简介
关系型数据库无处不在,存储了大量的结构化信息。与数据库的交互通常需要编写结构化代码(如SQL)的专业知识,这对于不精通查询语言的用户来说并不友好。Text-to-SQL旨在将自然语言问题自动转换为可执行SQL语句。
最近,一个大规模的、多表的、真实的Text-to-SQL的基准数据集Spider发布了。Spider上最有效、最流行的编码器架构是question-schema interaction graph。基于此,许多最先进的模型已得到进一步发展。它将自然语言问题和结构化数据库schema信息联合建模,并利用一些预定义的关系来挖掘它们之间的交互关系。然而,我们发现当前基于图的模型有两个主要的限制。

句法建模 句法和语义联合建模是自然语言处理的核心问题。在深度学习范式中,对于以句法为中心特征的任务,如Text-to-SQL任务,应该更好地理解句法的作用。例如,图1显示了基线模型可以学习question和schema之间的 date,id 和 transcript之间的正确链接,但是没有识别出id也应该包含在SELECT子句中。另一方面,在依存句法树的帮助下,date和id彼此接近,因此应该同时出现在SELECT子句中。然而,几乎所有可用的方法都将语言问题视为一个序列,而在基于神经网络的Text-to-SQL模型中忽略了句法信息。
混乱的边嵌入 Question-Schema interaction graph预先定义了一系列的边,并将它们建模为可学习的嵌入。这些嵌入在本质上应该是不同的,因为它们中的每一个代表了不同类型的关系,有不同的含义。以往的研究已经证明了可学习嵌入算法容易被纠缠,且不能满足多样性目标。
在本文中,我们提出了S2SQL,注入句法的Question-Schema interaction graph的Text-to-SQL解析器。S2SQL将来自句法依存树的句法标签建模为额外的边嵌入。我们相信,如果输入的结构可以可靠地获得,并且是任务的中心特征,那么明确利用该结构的模型就会受益。在本文中,我们调查和证明了适当地将句法信息引入到Text-to-SQL中可以进一步提高性能,我们对提出的模型表现很好提供了一个详细的分析。在此基础上,我们提出了一个解耦约束来鼓励模型学习不同的关系嵌入集,从而进一步提高了网络的性能。我们在具有挑战性的Text-to-SQL基准数据集Spider和Spider-Syn上评估了我们提出的模型,并证明当使用不同的预模型进行增强时,S2SQL的性能一致优于其他基于图的模型。简言之,我们工作的贡献有三方面:
- 我们研究了句法在Text-to-SQL任务中的重要性,并提出了一种新颖的、强大的跨领域的Text-to-SQL编码器,即S2SQL。
- 为了包含不同的边嵌入学习,引入解耦约束,进一步提高了算法的性能。
- 实验结果表明,在具有挑战性的Spider和Spider-Syn数据上,我们的方法优于现有的所有模型。
2 提出的方法
2.1 问题定义
给定一个自然语言问句 Q = { q i } i = 1 ∣ Q ∣ Q=\{q_i\}^{|Q|}_{i=1} Q={qi}i=1∣Q∣和一个数据库的schema S = { C , T } S=\{C,T\} S={C,T},其中 C = { c 1 t 1 , c 2 t 1 , ⋯ , c 1 t 2 , c 2 t 2 , ⋯ } \mathcal{C}=\left\{c_{1}^{t_{1}}, c_{2}^{t_{1}}, \cdots, c_{1}^{t_{2}}, c_{2}^{t_{2}}, \cdots\right\} C={c1t1,c2t1,⋯,c1t2,c2t2,⋯}表示这个数据库中所有的column, T = { t i } i = 1 ∣ T ∣ T=\{t_i\}^{|T|}_{i=1} T={ti}i=1∣T∣表示所有的table。Text-to-SQL的目标就是在给定以上输入的情况下得到对应的SQL语句 y y y。文本到sql的实际方法采用了编码器解码器体系结构。本文的重点是对编码器部分的改进。有关解码器的详细说明,请参阅论文笔记:RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers。
2.2 Question-Schema Interaction Graph
输入的Question和Schema可以被一同视为一个图 G = { V , E } G=\{V,E\} G={V,E},其中 V = Q ∪ T ∪ C V=Q\cup T\cup C V=Q∪T∪C,最初的节点嵌入矩阵 X ∈ R ∣ V ∣ Q ∣ + ∣ T ∣ + ∣ C ∣ ∣ × d \mathbf{X} \in \mathbb{R}^{|V| \mathcal{Q}|+| \mathcal{T}|+| \mathcal{C}|| \times d} X∈R∣V∣Q∣+∣T∣+∣C∣∣×d的初始值(即每个节点的初始embedding)是将输入整理成如下序列形式 [ C L S ] q 1 q 2 ⋯ q ∣ Q ∣ [ S E P ] t 10 t 1 c 10 t 1 c 1 t 1 c 20 t 1 c 2 t 1 ⋯ t 20 t 2 c 10 t 2 c 1 t 2 c 20 t 2 c 2 t 2 ⋯ [ S E P ] [\mathrm{CLS}] q_{1} q_{2} \cdots q_{|Q|}[\mathrm{SEP}] t_{10} t_{1} c_{10}^{t_{1}} c_{1}^{t_{1}} c_{20}^{t_{1}} c_{2}^{t_{1}} \cdots t_{20} t_{2} c_{10}^{t_{2}} c_{1}^{t_{2}} c_{20}^{t_{2}} c_{2}^{t_{2}} \cdots[\mathrm{SEP}] [CLS]q1q2⋯q∣Q∣[SEP]t10t1c10t1c1t1c20t1c2t1⋯t20t2c10t2c1t2c20t2c2t2⋯[SEP]. (之后输入到BERT或其他预训练模型中得到)。其中, t i 0 t_{i0} ti0和 c j 0 t i c_{j0}^{t_i} cj0ti表示这个table或column的type信息,被放在每个table或column输入项之前。他们之间的连边 R = { R } i = 1 , j = 1 ∣ X ∣ , ∣ X ∣ \mathcal{R}=\{R\}_{i=1, j=1}^{|X|,|X|} R={R}i=1,j=1∣X∣,∣X∣表示所有输入节点中任意两个节点之间已知的关系。
RGAT(relational graph attention transformers)模型对整个图进行建模,并得到输出表示为:
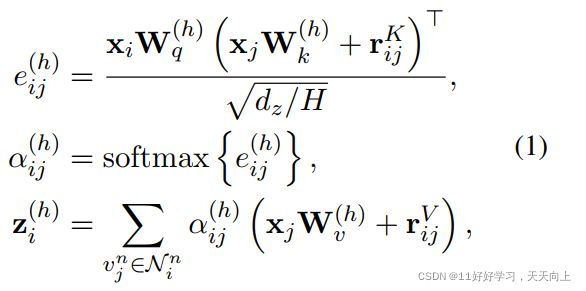
其中, W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv是可以通过训练学习。 N i n N_i^n Nin代表节点 v i n v_i^n vin的receptive field。
注入句法
之前的工作主要是在编码器中使用schema与question之间以及schema内部的连接,忽略了问题的结构。我们提出了一种将句法依赖信息集成到图中的有效方法。一个简单的想法是将所有句法依存类型直接视为新边类型。然而,依存句法解析器将返回55种不同的依存句法类型。如此大量的边类型会显著增加S2SQL中关系嵌入参数量,导致过拟合。为解决这个问题,我们将依赖类型引入三个抽象关系:Forward、Backward和NONE。另外,为了保证边嵌入的简单性,我们只考虑一阶关系。通过多层transformer的叠加,该模型无需刻意构造就能隐式捕获多阶关系。具体来说,我们计算在问题中的任意两个token v i v_i vi和 v j v_j vj之间的距离 D ( v i , v j ) D(v_i,v_j) D(vi,vj)。如果 v i v_i vi和 v j v_j vj具有上述依存关系类型,则该距离设置为 v i v_i vi和 v j v_j vj之间的一阶距离,否则为0。基于这个一阶距离D,我们通过前面定义的三种抽象类型之一,对token v i v_i vi和 v j v_j vj之间的句法关系 R i j R_{ij} Rij问题进行建模。
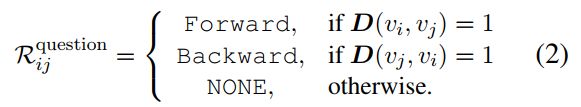
总的来说,如图2所示,S2SQL在图G中建模了三种结构:
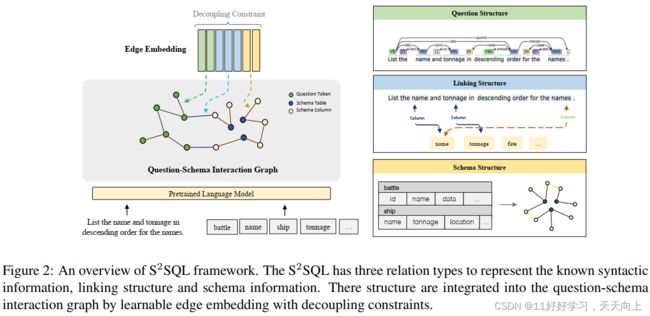
- 问题结构 R q u e s t i o n R^{question} Rquestion:表示两个问句token之间的语法依存关系;
- 连接结构 R l i n k i n g R^{linking} Rlinking:将相关实体与相应的schema中的列或表对齐的关系;
- schema结构 R s c h e m a R^{schema} Rschema:schema内部的关系,如主键-外键关系。
解耦约束
R中有k条已知边,每条边都表示为一个关系嵌入。直观地说,这些边缘嵌入 r = [ r 1 ; r 2 ; : : : ; R k ] r = [r_1;r_2;:::;R_k] r=[r1;r2;:::;Rk]应该是多样化的,因为它们有不同的语义含义。为了避免优化过程中存在耦合嵌入边r的潜在风险,我们引入了正交性条件:

这里1代表元素全部为1的矩阵,I代表单位矩阵。F即矩阵的Frobenius 范数。(注:这个操作可以直接在Pytorch中通过torch.norm(matrix)实现。)
3 实验
3.1 实验设置
数据集和评价指标 本文在Spider和Spider-Syn数据集上进行实验。Spider是一个大规模的、复杂的、跨域的Text-to-SQL的基准测试。Spider-Syn源自Spider,通过手动选择反映现实世界问题意译的同义词来替换与模式相关的单词。对于评估,我们遵循官方评估报告准确的匹配准确性(Exact Match,即EM)。
3.2 实现细节
我们利用PyTorch来实现我们提出的模型。在预处理过程中,问题、列名和表名的输入将使用Standford Nature Language Processing工具箱进行标记化和语义化。为了与基线进行比较,我们使用相同的一组超参数来配置它,例如,堆叠8个自我注意层,将dropout设置为0.1。位置前馈网络的内层尺寸为1024。在解码器内部,我们使用大小为128的规则嵌入,大小为64的节点类型嵌入,以及在LSTM内部的隐藏层size为512,dropout为0.21。

3.3 Baseline模型
我们在Spider和Spider-Syn上进行了实验,并将我们的方法与几个基线进行了比较。
- RYANSQL:一种基于sketch的slot filling方法,它被提出来为其对应的位置合成每个SELECT语句。
- RATSQL:是一个关系感知的模式编码模型,其中的question-schema interaction graph由n-gram模式构建的。
- ShadowGNN:使用与领域无关的表示在抽象和语义级别处理模式。
- BRIDGE:表示一个token序列中的问题和模式,其中将某个问题中提到的value所属的column跟在后面。
- LGESQL:使用Line graph增强的Text-to-SQL模型,无需构造meta path就可以挖掘底层的关系特性。Spider排行榜之前的SOTA。
3.4 结果分析
整体性能表现
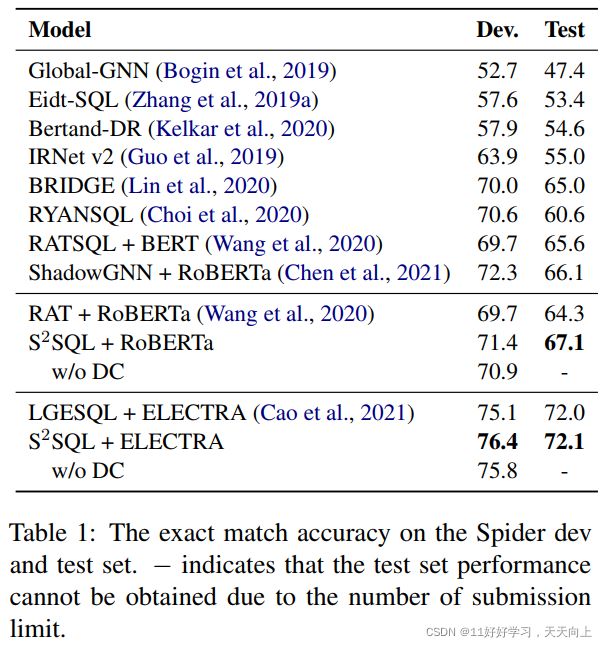
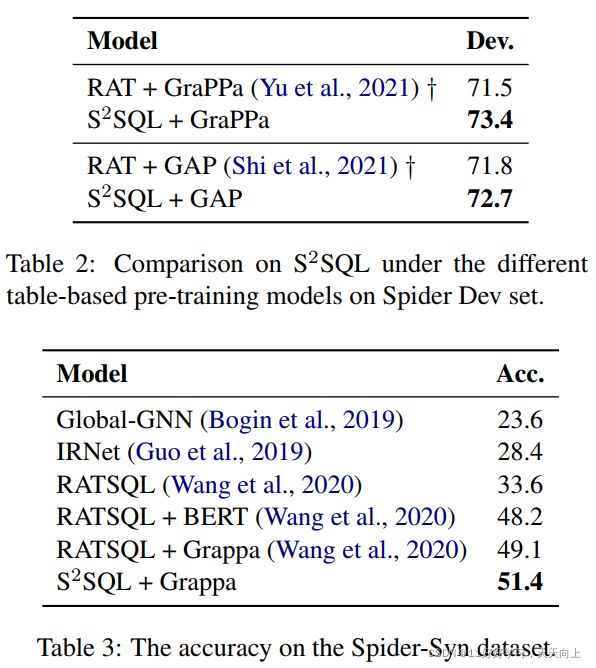
我们首先将S2SQL与Spider上的其他最先进的模型进行比较。如表1所示,我们可以看到S2SQL优于所有现有模型。值得注意的是,S2SQL + RoBERTa在隐藏测试集中的准确率为67.1%,比强基线RAT + RoBERTa高2.8%。同样的,SOTA模型LGESQL + ELECTRA在隐藏测试集上的准确率为72.0%,在开发集上的准确率为75.1%,而S2SQL + ELECTRA可以达到72.1%的测试精度和76.4%的开发精度。表2显示了RAT和S2SQL开发集上基于Table的前训练模型的结果。我们可以看到,当使用不同的训练前模型(包括RoBERTa (Liu et al., 2019)、GraPPa (Yu et al., 2021)和GAP (Shi et al., 2021)增强时,S2SQL的表现始终优于RAT。此外,如表3所示,S2SQL展示了Spider-Syn数据集上的提升。
Ablation Study
表1的最后一行显示,移除解耦约束会导致开发集性能下降0.5%。这说明解耦关系嵌入有助于提高性能。为了检验解耦约束的影响,我们将任意两个关系嵌入之间的余弦相似度可视化。如图3所示,我们观察到解耦约束消除了纠缠现象(颜色较深),并产生了更多样化的嵌入集。
3.5 定性分析

在表4中,我们将S2SQL模型生成的SQL查询与基线模型LGESQL创建的SQL查询进行了比较。我们注意到,S2SQL比基准系统执行得更好,特别是在问题理解依赖于语法结构的情况下。例如,在第一种情况下,order 和name有NMOD关系,baseline模型预测出错,在第一个示例中,name和 tonnage可以链接正确,但baseline未能捕获name和order的结构,导致生成错误,而S2SQL预测结果正确。
3.6 关于Parser
在我们的实验中,我们使用SpaCy工具作为句法分析器。需要强调的是,SpaCy句法分析的质量对S2SQL的性能影响很小。给出了以下三个主要原因。
- SpaCy是当前的SOTA解析器工具(OntoNotes 5.0语料库上的准确率为95%以上),在各种介绍语法的论文中得到了广泛的应用,这证明了它的可靠性。
- Spider中的问题并不复杂,可以很好地处理。
- 尽管语法分析器错误可能会给S2SQL带来干扰,但我们提出的归纳句法注入方法(而不是独立句法注入)可以减轻句法类型错误的影响。
4 相关工作
有许多工作在改进编码器和解码器方面开展以及基于表格的预训练。此外,Wang等(2021a)提出了一种基于元学习的训练目标,以提高泛化能力。Scholak等人(2021)提出了PICARD,一种约束T5自回归解码器的方法。在编码器相关的工作中,Guo等人(2019)引入了模式链接模块,旨在识别问题中提到的列和表。Lin等人(2020)利用数据库内容来增强模式表示。Bogin等人(2019)使用GNN来推导模式结构的表示。然后,Chen等人(2021)提出了ShadowGNN算法,该算法利用注意力抽象问题和图式的表征。此外,Hui等人(2021a)提出了一个动态图框架,可以为上下文相关的设置建模上下文信息。最近的研究方法(Wang et al., 2020;Cao等人,2021)通过Relation-aware-transformers实现了最佳性能。与这些研究不同的是,我们研究了句法结构在编码阶段的影响。
5 总结
本文提出了一种语法增强的问题模式图编码器(S2SQL),它可以有效地对文本到sql的语法信息进行建模,并引入解耦约束来诱导不同的关系嵌入。该模型在广泛使用的基准测试——Spider和Spider syn上取得了最新的性能。