Python pandas对表格进行整行整列筛选、删除或修改,对特定值进行修改
Pandas库的使用
Pandas库:从入门到应用(二)–行列数据读写
Python数据处理工具 ——Pandas(数据的预处理)
Pandas库有两个数据类型: Series, DataFrame
- Series = 索引 + 一维数据
- DataFrame = 行列索引 + 二维数据
DataFrame类型
DataFrame类型介绍
- DataFrame类型由共用相同索引的一组列组成。
- DataFrame是一个表格型的数据类型,每列值类型可以不同。
- DataFrame既有行索引(index)、也有列索引(column)。
- DataFrame常用于表达二维数据,但可以表达多维数据。
筛选数据
如何利用pandas进行数据查询(筛选)
可以使用布尔索引来筛选数据。
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43],
"性别":['男','女','男','男'], "学历":['初中','本科','硕士','博士']})
print(df) #构建表格格式
# 筛选年龄大于30的数据
print(df[df['年龄'] > 30])
# 筛选出性别为女的数据
print(df[df['性别'] == '女'])
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
1 乙 23 女 本科
排序数据
.sort_index() 方法根据行索引进行排序,默认升序。
.sort_index(axis=0, ascending=True)
举例
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43], "性别":['男','女','男','男'],
"学历":['初中','本科','硕士','博士']})
print(df) #构建表格格式
# 升序排序
print(df.sort_index())
# 降序排序
print(df.sort_index(ascending=False))
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
3 丁 43 男 博士
2 丙 34 男 硕士
1 乙 23 女 本科
0 甲 12 男 初中
**.sort_values()**方法在指定轴上根据数值进行排序,默认升序。
DataFrame.sort_values(by, axis=0, ascending=True) # by: 列索引,默认axis=0可以不写
举例
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43],
"性别":['男','女','男','男'],"学历":['初中','本科','硕士','博士']})
print(df) #构建表格格式
# 按照年龄升序排序
print(df.sort_values('年龄'))
# 按照年龄降序排序
print(df.sort_values('年龄', ascending=False))
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
3 丁 43 男 博士
2 丙 34 男 硕士
1 乙 23 女 本科
0 甲 12 男 初中
删除特定的行或列drop()
【pandas】drop()函数详解
.drop() 能够删除DataFrame指定行或列索引
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
- labels:待删除的行名or列名;
- axis:删除时所参考的轴,0为行,1为列;
- index:待删除的行名
- columns:待删除的列名
- level:多级列表时使用,暂时不作说明
- inplace:布尔值,默认为False,这是返回的是一个copy;若为True,返回的是删除相应数据后的版本
- errors:一般用不到,这里不作解释
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43],
"性别":['男','女','男','男'], "学历":['初中','本科','硕士','博士']})
print(df) #构建表格格式
# 删除第二行
print(df.drop(1))
# 删除”性别“列
print(df.drop('性别', axis=1))
# 同时删除行数据和列数据
print(df.drop(index=[0,3], columns=['年龄','性别']))
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
0 甲 12 男 初中
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 学历
0 甲 12 初中
1 乙 23 本科
2 丙 34 硕士
3 丁 43 博士
姓名 学历
1 乙 本科
2 丙 硕士
python中删除表格中常用的方法是DataFrame.drop()函数,DataFrame.drop()常用的操作是删除一整行或者删除某一整列。对于删除某一列满足条件的所有行操作暂不支持;此时用 isin 效果理想。
python 筛选出或者删除某一列满足条件的所有行
python:按列条件筛选、删除DataFrame中满足列条件的行
新增列或行
Python Pandas多种添加行列数据方法总结
Pandas怎么增加一行列?Python如何用pandas给表格增加列
Pandas提供了多种添加列数据的方法,常见的方法有如下几种:
- df[‘new_column_name’] =Series/Array:在df末尾添加一列Series/Array数据,并且以new_column_name作为新建列的列名。
- df.insert(loc, column,value):在df的第loc列插入一列数据,并且以column作为新建列的列名,value为新建列的数据。
- df.join(df2):将df2中的数据(DataFrame/Series)按照预设的方式加入到df中,可以设定df2的源df(left/right)。
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43],
"性别":['男','女','男','男'],"学历":['初中','本科','硕士','博士']})
print(df, '\n') #构建表格格式
# 新增户籍列
df['户籍'] = pd.Series(['北京','上海','广州','深圳'])
print(df)
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历 户籍
0 甲 12 男 初中 北京
1 乙 23 女 本科 上海
2 丙 34 男 硕士 广州
3 丁 43 男 博士 深圳
Pandas提供了多种添加行数据的方法,常见的方法有如下几种:
- df.loc[len(df)] = Series/Array:在df的最后一行添加一条Series/Array数据。
- df.append(Series/Dict/DF):在df的最后一行添加一条Series/Dict/DF数据。
- df.loc[n] = Series/Array:在df的第n行添加一条Series/Array数据(注意:n不能大于len(df))。
- df[pd.RangeIndex(start=1, stop=n)] = DataFrame:在df的最后一行添加一个DataFrame,并且这个DataFrame的数量必须与原始的df的列数相同。
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43],
"性别":['男','女','男','男'],"学历":['初中','本科','硕士','博士']})
print(df, '\n') #构建表格格式
# 新增行
df = df.append(pd.Series(['戊','45','女','博士'], index=['姓名', '年龄', '性别', '学历']), ignore_index=True)
print(df)
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
4 戊 45 女 博士
新增一行部分列数据
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43],
"性别":['男','女','男','男'],"学历":['初中','本科','硕士','博士']})
print(df, '\n') #构建表格格式
# 新增行
df = df.append(pd.Series(['戊','博士'], index=['姓名', '学历']), ignore_index=True)
print(df)
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
姓名 年龄 性别 学历
0 甲 12.0 男 初中
1 乙 23.0 女 本科
2 丙 34.0 男 硕士
3 丁 43.0 男 博士
4 戊 NaN NaN 博士
数据类型转换及描述统计
Python数据处理工具 ——Pandas(数据的预处理)
# 查看数据的行列数
print('数据集的行列数:\n',sec_cars.shape)
# 查看数据集每个变量的数据类型
print('各变量的数据类型:\n',sec_cars.dtypes)
# 数据的描述性统计
print('各变量的数据的描述性分析(基本的统计量(如最小值、均值、中位数、最大值等)):\n',sec_cars.describe())

数据的基本统计分析
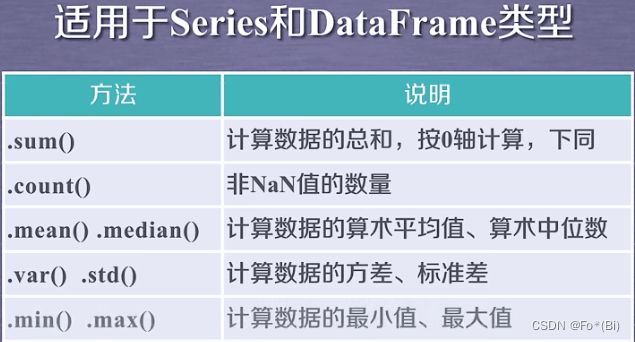
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43], "性别":['男','女','男','男'],
"学历":['初中','本科','硕士','博士']})
print(df) #构建表格格式
# 计算年龄的和
print('和:', df['年龄'].sum())
# 计算非空值的个数
print('非空值的个数:', df['年龄'].count())
# 计算年龄的算术平均值/平均数。均值也就是平均数,有时也称为算术平均数
print('平均数:', df['年龄'].mean())
# 计算年龄的中位数
print('中位数:', df['年龄'].median())
# 计算年龄的标准差
print('标准差:', df['年龄'].std())
# 计算年龄的方差
print('方差:', df['年龄'].var())
# 计算年龄的最小值
print('最小值:', df['年龄'].min())
# 计算年龄的最小值
print('最大值:', df['年龄'].max())
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
和: 112
非空值的个数: 4
平均数: 28.0
中位数: 28.5
标准差: 13.4412301024373
方差: 180.66666666666666
最小值: 12
最大值: 43
数据的累计统计分析
累计统计分析函数能对序列中的前1—n个数进行累计运算,可减少for循环的使用,使得数据的运算变得更加灵活。

cumsum是matlab中一个函数,通常用于计算一个数组各行的累加值
cumsum()函数的使用
import pandas as pd
df = pd.DataFrame(data={"姓名":['甲','乙','丙','丁'],"年龄":[12,23,34,43], "性别":['男','女','男','男'],
"学历":['初中','本科','硕士','博士']})
print(df) #构建表格格式
# 计算年龄的累加
print('累加:\n', df['年龄'].cumsum())
结果:
姓名 年龄 性别 学历
0 甲 12 男 初中
1 乙 23 女 本科
2 丙 34 男 硕士
3 丁 43 男 博士
累加:
0 12
1 35
2 69
3 112
Name: 年龄, dtype: int64
cumsum
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]))
print(df) #构建表格格式
# 参数axis=0指的是按行累加,即本行=本行+上一行
b = df.cumsum(axis=0)
print(b)
# 参数axis=1指的是按列相加,即本列=本列+上一列
c = df.cumsum(axis=1)
print(c)
结果:
0 1 2
0 1 2 3
1 4 5 6
2 7 8 9
0 1 2
0 1 2 3
1 5 7 9
2 12 15 18
0 1 2
0 1 3 6
1 4 9 15
2 7 15 24
cumprod
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]))
print(df) #构建表格格式
# 参数axis=0指的是按行累积,即本行=本行*上一行
b = df.cumprod(axis=0)
print(b)
# 参数axis=1指的是按列累积,即本列=本列*上一列
c = df.cumprod(axis=1)
print(c)
结果:
0 1 2
0 1 2 3
1 4 5 6
2 7 8 9
0 1 2
0 1 2 3
1 4 10 18
2 28 80 162
0 1 2
0 1 2 6
1 4 20 120
2 7 56 504
cummax、cummin
返回一个DataFrame或Series轴上的累积最大值、最小值。
cummax(axis=None, skipna=True, *args, **kwargs)
若要在操作中包含NA值,请使用skipna=False
import pandas as pd
df = pd.DataFrame({"A":[5, 3, 0, 4],
"B":[1, 2, 4, 3],
"C":[4, 1, 8, 2],
"D":[5, 4, 2, 10]})
print(df, '\n') #构建表格格式
# 参数axis=0,给出行的最大值
b = df.cummax(axis = 0)
print(b)
# 参数axis=1,给出列的最大值
c = df.cummax(axis = 1)
print(c, '\n')
# 参数axis=0,给出行的最小值
d = df.cummin(axis=0)
print(d)
# 参数axis=1,给出列的最小值
e = df.cummin(axis=1)
print(e)
结果:
A B C D
0 5 1 4 5
1 3 2 1 4
2 0 4 8 2
3 4 3 2 10
A B C D
0 5 1 4 5
1 5 2 4 5
2 5 4 8 5
3 5 4 8 10
A B C D
0 5 5 5 5
1 3 3 3 4
2 0 4 8 8
3 4 4 4 10
A B C D
0 5 1 4 5
1 3 1 1 4
2 0 1 1 2
3 0 1 1 2
A B C D
0 5 1 1 1
1 3 2 1 1
2 0 0 0 0
3 4 3 2 2
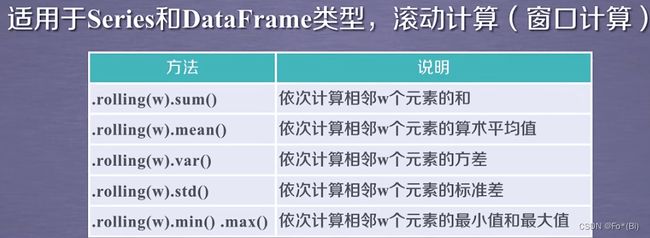
Python3:pandas中的移动窗口函数rolling的用法
rolling().sum()
首先我们设置的窗口window=5,也就是5个数取一个和。index 0,1 ,2,3为NaN,是因为它们前面都不够5个数。等到index4 的时候,它的值是怎么算的呢,index4 = index0+index1+index2+index3+index4
import pandas as pd
df = pd.DataFrame({"A":[5, 3, 0, 4],
"B":[1, 2, 4, 3],
"C":[4, 1, 8, 2],
"D":[5, 4, 2, 10]})
print(df, '\n') #构建表格格式
b = df.rolling(2).sum()
print(b)
结果:
A B C D
0 5 1 4 5
1 3 2 1 4
2 0 4 8 2
3 4 3 2 10
A B C D
0 NaN NaN NaN NaN
1 8.0 3.0 5.0 9.0
2 3.0 6.0 9.0 6.0
3 4.0 7.0 10.0 12.0
设置的窗口window=2,也就是2个数取一个和。index1 = index0+index1
数据的相关分析

import pandas as pd
df = pd.DataFrame({"A":[5, 3, 0, 4],
"B":[1, 2, 4, 3],
"C":[4, 1, 8, 2],
"D":[5, 4, 2, 10]})
print(df, '\n') #构建表格格式
b = df.cov()
print('协方差矩阵:\n', b)
结果:
A B C D
0 5 1 4 5
1 3 2 1 4
2 0 4 8 2
3 4 3 2 10
协方差矩阵:
A B C D
A 4.666667 -2.333333 -4.666667 4.666667
B -2.333333 1.666667 2.166667 -0.500000
C -4.666667 2.166667 9.583333 -6.250000
D 4.666667 -0.500000 -6.250000 11.583333
相关系数
corr()函数的用法
其中corr()函数的参数为空时,默认使用的参数为pearson.
- pearson:相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
- spearman:非线性的,非正太分析的数据的相关系数
- kendall:用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正太分布的数据
import pandas as pd
df = pd.DataFrame({"A":[5, 3, 0, 4],
"B":[1, 2, 4, 3],
"C":[4, 1, 8, 2],
"D":[5, 4, 2, 10]})
print(df, '\n') #构建表格格式
print('pearson相关系数矩阵:\n', df.corr(method='pearson'))
print('spearman相关系数矩阵:\n', df.corr(method='spearman'))
print('kendall相关系数矩阵:\n', df.corr(method='kendall'))
结果:
A B C D
0 5 1 4 5
1 3 2 1 4
2 0 4 8 2
3 4 3 2 10
pearson相关系数矩阵:
A B C D
A 1.000000 -0.836660 -0.697823 0.634726
B -0.836660 1.000000 0.542137 -0.113796
C -0.697823 0.542137 1.000000 -0.593205
D 0.634726 -0.113796 -0.593205 1.000000
spearman相关系数矩阵:
A B C D
A 1.0 -0.8 -0.2 0.8
B -0.8 1.0 0.4 -0.4
C -0.2 0.4 1.0 -0.4
D 0.8 -0.4 -0.4 1.0
kendall相关系数矩阵:
A B C D
A 1.000000 -0.666667 0.000000 0.666667
B -0.666667 1.000000 0.333333 -0.333333
C 0.000000 0.333333 1.000000 -0.333333
D 0.666667 -0.333333 -0.333333 1.000000