GAP: Generalizable Approximate Graph Partitioning Framework(广义近似图划分框架)
Abstract
图划分是将一个图的节点划分为平衡的分区,同时最小化跨分区的边割的问题。由于它的组合性质,许多近似解被开发出来,包括多层次方法和谱聚类的变体。我们提出了GAP,一个可推广的近似划分框架, 这需要深入学习图划分的方法。我们定义了一个表示划分目标的可微损失函数,并利用反向传播优化网络参数。与按图重做优化的基线不同,GAP具有泛化能力,允许我们训练在推理时产生性能分区的模型,即使是在看不见的图上。此外,由于我们在学习图的表示的同时联合优化分区损失函数,GAP可以很容易地针对各种图结构进行调整。我们评估GAP在不同大小和结构的图上的性能,包括广泛使用的机器学习模型(例如ResNet、VGG和Inception-V3)、无标度图和随机图。我们证明GAP在达到竞争分割的同时比基线快100倍,并将其推广到看不见的图上。
1 Introduction
图划分是一个重要的优化问题,在计算机视觉、超大规模集成电路设计、生物学、社会网络、交通网络等领域有着广泛的应用。其目标是求图的平衡划分,同时最小化边割的数目。这个问题是NP完全问题,它被描述为一个离散优化问题,并且通常使用启发式和近似算法来获得解。一些值得注意的方法包括多级方法和谱划分方法[Karypis and Kumar,1998,Karypis et al.,1999,Karypis and Kumar,2000,Miettinen等人,2006,Andersen等人,2006,Chung,2007]。
在这项工作中,我们介绍了一种基于学习的方法,GAP,用于持续放松问题。我们定义了一个可微的损失函数,它的目标是将一个图划分成不相交的平衡分区,同时最小化这些分区的边割数。我们训练一个深度模型来优化这个损失函数。优化是在无监督的方式下完成的,不需要标记的数据集。
我们的方法GAP不假设图的结构(例如稀疏与稠密,或无标度)。相反,GAP在优化分割损失函数的同时,利用图嵌入技术学习并适应图结构。这种表示学习使得我们的方法是自适应的,而不需要为不同类型的图设计不同的策略。
我们基于学习的方法也具有泛化能力,这意味着我们可以在一组图上训练一个模型,然后在推理时使用它来处理大小不等的不可见图。特别地,我们证明了当GAP在较小的图(例如1k个节点)上训练时,它将所学知识转移到更大的图上(例如20k个节点)。这种泛化允许经过训练的间隙模型快速推断出大型不可见图上的分区,而基线方法必须为每个新的图重新进行整个优化。
综上所述,本文做出以下贡献:
(1) 我们提出了GAP,一个可推广的近似划分框架,它是一个无监督的学习方法来解决平衡图划分的经典问题。我们定义了一个可微的损失函数,它使用归一化割的连续松弛。然后我们训练一个深度模型,并应用反向传播来优化损耗。
(2)GAP模型可以在推理时对不可见图进行有效的划分。与现有的方法相比,泛化是一个优势,现有的方法必须对每个新的图重新进行整体优化。
(3)GAP利用了图嵌入技术[Kipf and Welling,2017,Hamilton et al.,2017]并学会了根据图的底层结构对图进行划分,从而能够在各种各样的图上生成高效的分区。
(4)为了鼓励可重复的研究,我们在补充材料中提供源代码,并且正在将框架开源。(Tips:代码已开源)
(5)我们发现GAP在实现竞争性分区的同时,在各种合成和真实世界的图上,GAP比性能最好的基线快100倍,最多有27000个节点。
2 Related Work
图划分:图划分是一个重要的组合优化问题,已经得到了详尽的研究。最广泛使用的图划分算法通过对输入图执行操作来生成分区,直到收敛为止[Andersen等人,2006,Chung,2007]。另一方面,多级划分方法首先通过折叠节点和边来减小图的大小,然后在较小的图上进行划分,最后扩展图以恢复对原始图的划分[Karypis and Kumar,2000,Karypis et al.,1999,Karypis and Kumar,1998,Miettinen et al.,2006]。这些算法可以提供高质量的分区【Miettinen等人,2006年】。
另一种方法是使用模拟退火。[vanden Bout and Miller,1990]提出了平均场退火,它将模拟退火与Hopfield神经网络相结合。[Kawamoto et al.,2018]研究了一种不同的图划分公式,其中图是由统计模型生成的,任务是推断生成模型的预先指定的组标签。他们为这一版本的问题开发了一个最小图神经网络结构的平均场理论。
这一系列的研究将图划分描述为一个离散优化问题,而我们的GAP框架是第一个用于连续松弛问题的深度学习方法之一。此外,GAP将一般化为看不见的图,动态地生成分区,而不必对每个图重新进行优化。
聚类:给定一组点,聚类的目标是识别相似点的组。对具有不同目标的聚类问题,如自平衡k均值和平衡最小割集进行了详尽的研究[Liu等人,2017,Chen等人,2017,Chang等人,2014]。最有效的聚类技术之一是谱聚类,它首先在图的特征空间中生成节点嵌入,然后将k均值聚类应用于这些向量[Shi and Malik,2000,Ng et al.,2002,Von Luxburg,2007]。
然而,将聚类推广到看不见的节点和图是非常重要的。为了解决泛化问题,SpectralNet[Shaham et al.,2018]是光谱聚类的一种深度学习方法,它为看不见的数据点生成光谱嵌入。其他用于聚类的深度学习方法尝试以适合于通过k均值或高斯混合模型进行聚类的方式对输入进行编码【Yang等人,2017年,Xie等人,2016年,Zheng等人,2016年,Dilokthanakul等人,2016年】。
图聚类和图划分虽然相关,但它们是不同的问题,因为图聚类试图最大化簇的局部性,而图划分则在保持分区之间平衡的同时保持局部性。我们的方法还将划分问题视为具有可微损失的端到端学习问题,而上述方法生成嵌入,然后使用不可微技术(如k-means)进行聚类。
设备布置:图划分的实际意义通过张量流计算图的设备布置任务来证明,其中的目标是通过为设备分配操作来最小化执行时间。[Mirhoseini et al.,2017]提出了一种强化学习方法来优化张量流图的设备布局。他们使用seq2seq策略将操作分配给设备。然后将生成的配售的执行时间作为奖励信号来优化策略。[Mirhoseini et al.,2018]中提出了一个设备布局的层次模型,其中图形划分和布局是联合学习的。虽然这项工作也使用神经网络来学习分区,但是他们的目标是优化结果分区的运行时,迫使他们使用策略梯度来优化其不可微的损失函数。
3 Problem Definition and Background
设G=(V,E)是一个图,其中V={vi}和E={E(vi,vj)| vi∈V,vj∈V}是图中的节点集和边集。设n为节点数。图G可分为g个不相交集S1,S2,...,S g,其中集合中的节点的并集为V(k=1t S k=V),每个节点只属于一个集合(k=1s k=∅),只需去掉连接这些集合的边。
最小割集:为了形成不相交集而从G中删除的边的总数称为割。给定集S k,S̄k,则割(S k,S̄k)正式定义为:
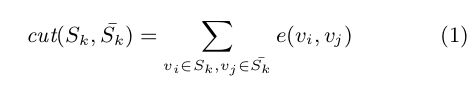
该公式可推广到多个不相交集s1,s2。sg,其中S̄k是除sk外所有集的并集。
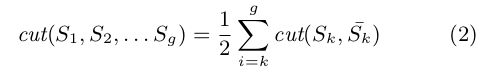
规范化割:最小化割的图的最优划分(方程式2)是一个研究得很好的问题,并且有有效的多项式算法来解决它[Papadimitriou和Steiglitz,1982]。然而,最小割准则倾向于度较小的切割节点,导致集/分区不平衡。为了避免这种偏差,[Shi and Malik,2000,Zhang and Rohe,2018]研究了基于图电导的归一化切割(Ncut),其中切割成本计算为所有节点的总边缘连接的一部分。
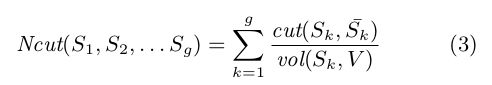
其中vol(sk,V)=vi∈sk,vj∈vee(vi,vj),即图G中节点属于sk的总度。
最小化归一化割的一种方法是基于图的拉普拉斯特征向量[Shi and Malik,2000,Zhang and Rohe,2018]。先前的研究表明,在广泛的社会和信息网络中,图电导最小的集群通常很小[Leskovec,2009,Zhang和Rohe,2018]。正则化谱聚类是[Zhang and Rohe,2018]提出的解决这一问题的方法。
然而,在本文中,我们提出GAP作为一种无监督学习方法,它具有一个可微的损失函数,可以训练它来寻找具有最小规范化割的平衡分区。我们证明了GAP使泛化成为不可见图。
4 Generalizable Approximate Partitioning
现在我们介绍可归纳的近似划分框架(GAP)。如图1所示,GAP有两个主要组成部分:用于生成每个节点的划分概率的图表示学习(模型)和标准化切割目标的可微公式(损失函数)。GAP使我们能够训练一个神经网络来优化一个先前无法区分的目标,通过生成具有最小边缘切割的平衡分割。在讨论模型之前,我们首先给出了损失函数。
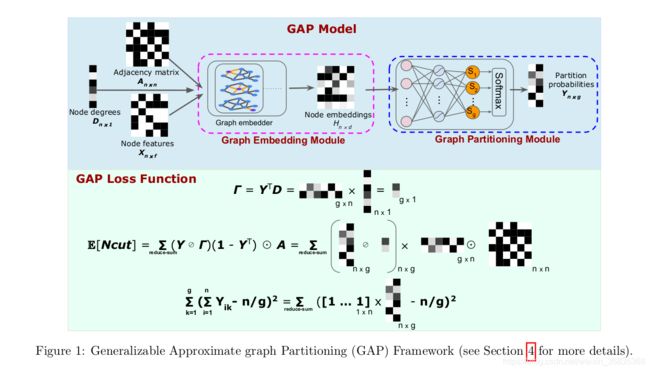
4.1 GAP Loss Function
我们假设我们的模型返回![]() ,Yik表示节点v i∈v属于分区sk的概率。我们提出了一个基于Y的损失函数X来计算方程3中的归一化割,并评估分区的平衡性。在后面的4.2小节中,我们将讨论生成Y的模型。
,Yik表示节点v i∈v属于分区sk的概率。我们提出了一个基于Y的损失函数X来计算方程3中的归一化割,并评估分区的平衡性。在后面的4.2小节中,我们将讨论生成Y的模型。
规范化割:正如我们在第3节中讨论的,![]() 是边数
是边数![]() ,其中
,其中![]() 。设Yik是节点vi属于分区Sk的概率。节点Vj不属于分区sk的概率为1−Yjk。因此,E[cut(S k,S̄k)]可由式4表示,其中N(v i)是与v i相邻的节点集(图1中的直观说明)。
。设Yik是节点vi属于分区Sk的概率。节点Vj不属于分区sk的概率为1−Yjk。因此,E[cut(S k,S̄k)]可由式4表示,其中N(v i)是与v i相邻的节点集(图1中的直观说明)。
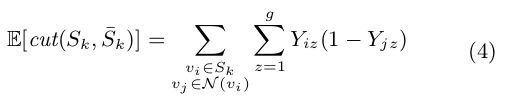
由于给定节点的相邻节点集可以从图a的邻接矩阵中检索出来,因此我们可以将方程4重写如下:

与邻接矩阵![]() 的逐元素乘积确保只考虑相邻节点。此外,
的逐元素乘积确保只考虑相邻节点。此外,![]() 的结果是n×n矩阵,
的结果是n×n矩阵,![]() 是其所有元素的和。
是其所有元素的和。
由式3可知,![]() 是属于Sk的所有节点的阶数之和。设D是大小为n的列向量,其中Di是节点v i∈V的次数。给定Y,我们可以计算
是属于Sk的所有节点的阶数之和。设D是大小为n的列向量,其中Di是节点v i∈V的次数。给定Y,我们可以计算![]() 如下:
如下:

式中,Γ是![]() 中的向量,g是划分的数目。利用式5和式6中的
中的向量,g是划分的数目。利用式5和式6中的![]() ,我们可以计算方程式3中的预期归一化切割,如下所示:
,我们可以计算方程式3中的预期归一化切割,如下所示:

![]() 是元素除法,
是元素除法,![]() 的结果是一个n×n矩阵,其中
的结果是一个n×n矩阵,其中![]() 是它所有元素的和。
是它所有元素的和。
平衡割:到目前为止,我们已经展示了如何计算给定矩阵Y(属于分区的节点概率)的图的期望规范化割。在这里,我们展示了给定的Y,我们也可以评估这些分区的平衡程度。
给定图| V |=n中的节点数和分区数g,要获得平衡分区,每个分区的节点数应为![]() 。Y中列的和给出了每个分区中的期望节点数,因为Yik表示节点v i∈v属于分区Sk的概率。因此,对于平衡分区,我们将以下错误最小化:
。Y中列的和给出了每个分区中的期望节点数,因为Yik表示节点v i∈v属于分区Sk的概率。因此,对于平衡分区,我们将以下错误最小化:

结合期望的归一化切割(方程式7)和平衡分割误差(方程式8),我们得到以下损失函数:
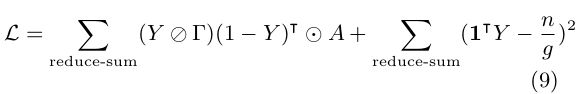
接下来,我们讨论了在等式9中寻找图划分Y以最小化损失的间隙神经模型。
4.2 The GAP Model
GAP模型接受一个图定义,生成利用局部图结构的节点嵌入,并将每个嵌入投影到logit中,该逻辑图定义了一个概率分布,以最小化期望的标准化切割(等式9)。
图嵌入模块:图嵌入模块的目的是利用图的结构和节点特征来学习节点嵌入。最近,使用图卷积网络[Kipf and Welling,2017](GCN)、GraphSAGE[Hamilton et al.,2017]、neural graph Machines[Bui et al.,2017]、graph Attention networks[Veličković等人]等方法将图神经网络应用于节点嵌入和分类任务方面取得了一些进展。,2018年]和其他变体。在这项工作中,我们利用GCN和GraphSAGE学习各种图的图形表示,这有助于泛化。
GCN:[Kipf and Welling,2017]表明未经训练的具有随机权重的GCN可以作为一个强大的图节点特征抽取器。在我们的实现中,我们使用了加权矩阵![]() 的3层GCN,使用了[Glorot和Bengio,2010]中描述的Xavier初始化。
的3层GCN,使用了[Glorot和Bengio,2010]中描述的Xavier初始化。

其中,![]() 是具有附加自连接的无向图G的邻接矩阵。I n是单位矩阵,
是具有附加自连接的无向图G的邻接矩阵。I n是单位矩阵,![]()
![]() 。输入特征矩阵X依赖于图。在张量流计算图中,每种操作类型(如MatMul、Conv2d、Sum等)都是一个特征。
。输入特征矩阵X依赖于图。在张量流计算图中,每种操作类型(如MatMul、Conv2d、Sum等)都是一个特征。
GraphSAGE:[Hamilton et al.,2017]开发了一种基于节点输入特征生成高维图节点表示的节点嵌入技术。该技术的核心是采样和聚合,在给定一个节点v i的情况下,我们从N(v i)中抽取一组v i的邻居,并聚合它们的表示(使用最大池),以生成v i的采样邻居的嵌入。这种邻域表示与v i本身的表示相结合,以生成v i的新表示。多次迭代这个过程会导致消息在节点之间传递,以增加跳数。
我们对GraphSAGE的实现基于[Hamilton et al.,2017]中的算法1。对于通过步骤k的每个消息,我们对每个节点v i∈v执行以下操作:
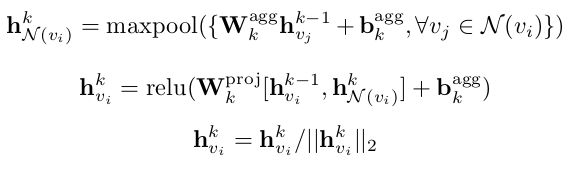
其中agg和proj分别表示聚合矩阵和投影矩阵。
图划分模块:我们的GAP框架中的第二个模块负责对图进行划分,接受节点嵌入,并生成每个节点属于分区s1、s2、…、sg的概率(图1中的Y)。该模块是一个完全连接的层,然后是softmax,经过训练,使方程9最小化。
我们还注意到,对于特别大的图,可以从较大的图中对随机抽样的小批量节点进行优化。此外,可以阻止从分割模块到嵌入模块的梯度流,从而导致无监督的节点嵌入。
5 Experiments
我们实验的主要目标是(a)评估GAP框架对hMETIS的性能[Karypis and Kumar,2000],一个广泛使用的使用多级划分的划分器,以及(b)评估GAP在不可见图上的泛化性,并提供关于列车图和测试图之间的结构相似性如何影响的见解泛化性能。源代码是为可复制性而提供的,并且正在被开源。
5.1 Setup
我们对真实图和合成图进行了实验。具体来说,我们使用了五个广泛使用的张量流图。我们还生成随机图和无标度图作为合成数据集,以显示GAP对不同结构图的有效性。
Real Datasets
* ResNet[He et al.,2016]是一个具有残余连接的深卷积网络,可避免梯度消失。带有50层的ResNet_v1_50的TensorFlow实现包含20586个操作。
* Inception-v3【Szegedy等人,2017年】由多个区块组成,每个区块由若干个卷积层和汇集层组成。这个模型的张量流图包含27114个操作。
* lexNet【Krizhevsky等人,2012年】由5个卷积层组成,其中一些是max pooling层,3个完全连接的层和一个最终的softmax。该模型的张量流图有798次运算。
*MNIST conv有3个卷积层用于MNIST分类任务。该模型的张量流图包含414个运算。
*VGG[Simonyan和Zisserman,2014]包含16个卷积层。VGG的张量流图包含1325个操作。
Synthetic Datasets(合成数据集)
* 随机:使用Erdös–Rényi模型随机生成大小为10 3和10 4节点的网络[Erdos and Rényi,1960],其中任意两个节点之间具有边的概率为0.1。
*无标度:使用NetworkX随机生成大小为103和104的无标度网络【Hagberg等人,2008】(无标度网络是一种度分布遵循幂律的网络【Bollobás等人,2003年】)。

Baseline基线:由于图划分是NP完全的,所以通常使用启发式和近似算法来导出解。虽然已经有大量关于特定图结构/应用的图划分的工作[Gonzalez et al.,2012,Hada et al.,2018],hMETIS[Karypis and Kumar,2000,Karypis et al。,1999]是一个通用框架,适用于各种各样的图形,并被证明在不同的领域提供高质量的分区(例如VLSI、道路网络[Miettinen等人,2006年,Xu和Tan,2012年]。与hMETIS类似,GAP是一个通用的框架,它对图结构没有任何假设。在我们的实验中,我们将GAP与嗯,我们设置hMETIS参数以返回边缘切割最小的平衡分区。
Performance Measures性能度量:正如我们在第3节中讨论的,图划分的目标是具有最小边割的平衡分区。我们通过检查1)Edge cut:切割与总边数的比率,以及2)平衡性:是1减去每个分区中节点数的MSE,然后平衡分区(n/g)来评估结果分区的性能。
5.2 Performance
在这组实验中,我们发现GAP的性能优于hMETIS。因为hMETIS不会泛化为看不见的图,并且一次只优化一个图,所以我们还约束GAP一次优化一个图,以便进行公平比较。我们在5.3节讨论了GAP的泛化能力。
表1显示了GAP对hMETIS在实张量流图上的3分区问题的性能。这两种技术生成非常平衡的分区,GAP在VGG图的边缘切割上的性能优于hMETIS。
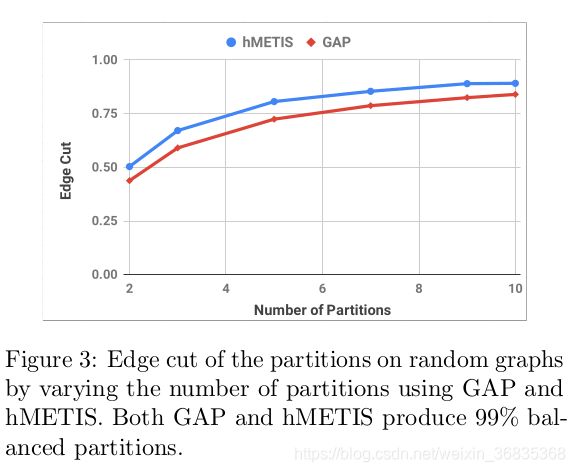
图3显示了当分区数从2到10时GAP对hmeti的性能。这些图代表了5个随机图的平均值。GAP和hMETIS都能产生99%的平衡分区。然而,GAP也能够找到比hMETIS更低的边缘切割分区。通过检查我们的数据集的度直方图(图2a到2d),我们发现虽然hMETIS启发式算法在稀疏张量流图上工作得相当好,但是GAP在稠密图上的性能优于hMETIS。
5.3 Generalization
在本节中,我们将展示GAP在真实数据集和合成数据集上的有效推广。据我们所知,我们是第一个提出一种图划分的学习方法,它可以推广到不可见的图。
5.3.1 Generalization on real graphs
在这组实验中,我们用单个张量流图VGG训练GAP,并在MNIST-conv上进行验证。在推理时,我们在看不见的张量流图AlexNet、ResNet、andrence time上测试训练的模型Inception-v3。
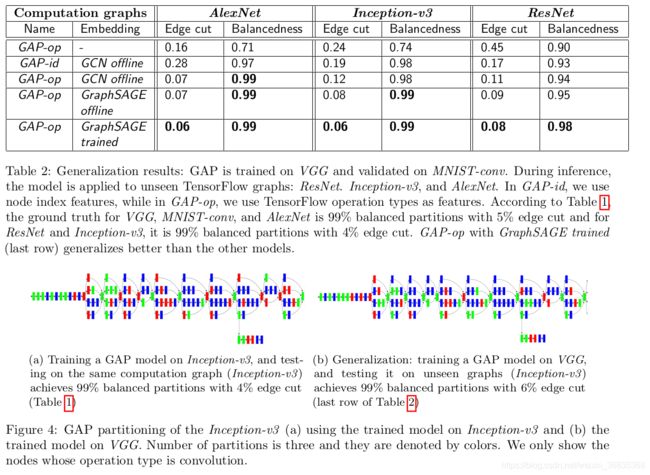
表2给出了我们的实验结果,并说明了节点特征和图嵌入在泛化中的重要性。在GAP-id中,我们使用节点的索引作为其特征,而在GAP-op中,操作类型(如TensorFlow中的Add、Conv2d和L2loss)作为节点特征。我们将所有功能编码为一个热点。在第4.2节之后,我们利用图卷积网络[Kipf and Welling,2017](GCN)和Graph SAGE[Hamilton等人,2017]来捕捉图形之间的相似性。在GCN离线和fline的GraphSAGE中,我们不训练图嵌入模块(图1)中没有来自分割模块的梯度流,而在GraphSAGE训练中,两个模块是联合训练的。表2显示,经过GraphSAGE训练(最后一行)的GAP-op获得了最佳的性能,并且比其他模型更好地进行了泛化。注意,这个模型是在一个图上训练的,VGG只有1325个节点,在AlexNet、ResNet和Inception-v3上分别用798、20586和27114个节点进行测试。
图4显示了Inception-v3的间隙划分,使用了一个在同一个图(4a)上训练的模型和一个在VGG(4b)上训练的模型。注意,分区用颜色表示,我们只显示操作类型为卷积的节点。在场景(4a)中,我们在Inception-v3上训练和测试GAP,我们实现了99%的平衡分区和4%的边缘切割(表1)。GAP在VGG上训练并在看不见的图(Inception-v3)上进行测试,它实现了99%的平衡分区和6%的边缘切割(表2的最后一行)。图4a和4b中的分区分配非常相似(75%),这证明了GAP的泛化。
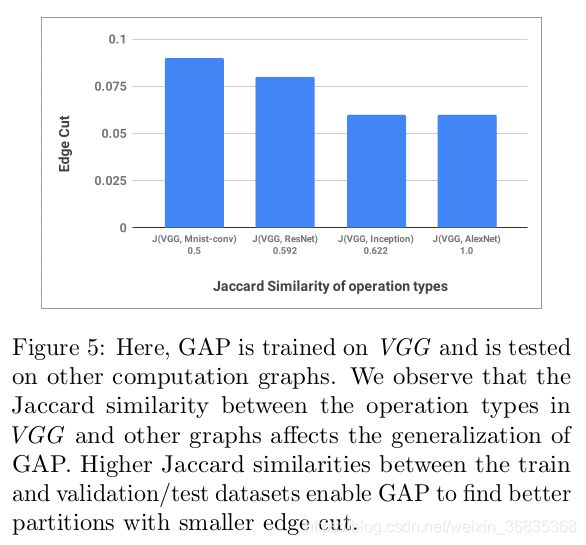
我们还观察到VGG和其他用于推理和验证的计算图中节点特征(操作类型)的相似性与间隙划分的边缘切割分数相关(图5)。例如,让A和B分别是VGG和ResNet中的操作类型集,Jaccard相似性为![]() )。图5显示,随着图形与VGG的Jaccard相似性的增加,边缘切割减少。换句话说,在训练图和测试图中出现相似的节点类型有助于我们的模型的泛化。
)。图5显示,随着图形与VGG的Jaccard相似性的增加,边缘切割减少。换句话说,在训练图和测试图中出现相似的节点类型有助于我们的模型的泛化。
模型体系结构与Hyper-p参数:这里,我们描述了性能最好的模型的细节(对应于表2的最后一行)。特征(TensorFlow操作类型)的数量为1518。GraphSAGE有5层512个单元的共享池,图形分区模块是一个由64个单元组成的3层密集网络,最后有一个softmax层。我们使用ReLU作为激活函数,所有权重都是使用Xavier初始化初始化的[Glorot和Bengio,2010]。我们使用Adam优化器,学习率为7.5e-5。

5.3.2 Generalization on synthetic graphs
我们进一步研究了随机图和无标度图上GAP的推广。注意,我们在同一类型的图上训练和测试GAP,但是节点的数量可能会有所不同。例如,我们在1k节点的随机图上训练GAP,并在1k和10k节点的随机图上进行测试。同样,我们在1k节点的scalefree图上训练GAP,并在1k和10k节点的无标度图上进行测试。
图6a、6b和6c显示了无标度图上GAP相对于hMETIS的边缘切割、平衡性和执行时间(每个点是5个实验的平均值)。在GAP-Scalefree-1中,我们只使用一个无标度图来训练GAP,而GAP-Scalefree10是在10个无标度图上训练的。然后,我们在5张1k和10k节点的无标度图上测试了GAP-Scalefree-1和GAP-Scalefree-10模型,并给出了平均结果。图6a显示了GAP-Scalefree-1和GAP-Scalefree-10用比hMETIS更低的边缘切割来划分1k和10k节点的不可见图。尽管GAP-Scalefree-1的平衡性低于hMETIS,但是通过增加训练集中的图的数量(GAP-Scalefree-10),平衡性得到了改善,如图6b所示,而其边缘切割仍然更小(6a)。此外,GAP-Scalefree-10比hMETIS(6c)运行得稍快,其分区与hMETIS(6b)的分区一样平衡,但具有较低的边缘切割(6a)。
图7a、7b和7c显示了随机图上GAP相对于hmeti的边缘切割、平衡性和执行时间。每个点是5个实验的平均值。在GAP-Random-1中,我们只在一个随机图上训练GAP,而在GAP-Random-10中,我们训练10个随机图。然后,我们在5个1k和10k节点的不可见随机图上测试了GAP-random-1和GAP-random-10模型,并给出了平均结果。GAP在1k和10k节点的不可见随机图上泛化时的性能与hMETIS的性能几乎相同,而图7c显示在推断过程中,GAP比hMETIS的运行时快10到100倍。
模型结构和超参数:与计算图中节点特征是操作类型不同,合成图中的节点没有特征。此外,我们还必须训练一个模型,它可以推广到不同大小的图。例如,我们在具有1k个节点的随机图上训练一个模型,并在具有10k个节点的随机图上测试它。为此,我们将PCA应用于无特征图的邻接矩阵,并检索1000大小的嵌入作为节点特征。我们使用ReLU作为我们的激活函数,所有的权重都是通过Xavier初始化初始化的。我们还使用Adam优化器。下面是每个模型的其余超参数。
GAP-Scalefree-1:用一个无标度图训练模型。GraphSAGE有5层512个单元,图划分模块采用softmax的三层128单元密集网络。学习率为2.5e-6。
GAP-Scalefree-10:用10个无标度图训练。GraphSAGE有4层128个单元,图划分模块是一层64个单元的密集网络,采用softmax。学习率为7.5e-6。
GAP-Random-1:只使用随机图训练。GraphSAGE有5层128个单元的共享池,图划分模块是一个由64个单元组成的2层密集网络,带有softmax。学习率为7.5e-4。
GAP-Random-10:用10个随机图训练。GraphSAGE有2层256个单元的共享池,图划分模块是一个由128个单元组成的3层密集网络,带有softmax。学习率为7.5e-6。
6 Conclusion
针对图划分问题,我们提出了一个深度学习框架GAP,其目标是将图中的节点分配到平衡的分区中,同时最小化跨分区的边割。我们的GAP框架支持泛化:我们可以训练在推理时产生性能分区的模型,即使是在看不见的图上。与现有的基线相比,这种泛化是一个优势,现有的基线会为每个新的图形重新进行优化。我们对广泛使用的机器学习模型(ResNet、VGG和Inception-v3)、无标度图和随机图的结果表明,GAP在达到竞争划分的同时,比基线快100倍,并将其推广到看不见的图。