【论文精读】HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
- 前言
- Abstract
- 1 Introduction
- 2 Related Works
- 3 HuggingGPT
-
- 3.1 Task Planning
-
- Specification-based Instruction
- Demonstration-based Parsing
- 3.2 Model Selection
-
- In-context Task-model Assignment
- 3.3 Task Execution
-
- Resource Dependency
- 3.4 Response Generation
- 4 Experiments
-
- 4.1 Settings
- 4.2 Qualitative Results
- 4.3 Quantitative Evaluation
- 5 Limitations
- 6 Conclusion
- 阅读总结
前言
又是一篇利用LLM进行规划的工作,中稿于NeurIPS 2023,它充分结合了专家模型解决特定任务的能力和LLMs的理解推理能力,工作新颖但效果一般,可以说提供了一种新的利用LLM解决通用任务的范式,在思想上值得借鉴。
| Paper | https://arxiv.org/pdf/2303.17580.pdf |
|---|---|
| Code | https://github.com/microsoft/JARVIS |
| From | NeurIPS 2023 |
Abstract
解决具有不同领域和模态的复杂人工智能任务是迈向通用人工智能的关键,虽然现在有大量可以用的AI模型面向不同领域和模态,但是它们不能解决复杂的AI任务。LLM在自然语言任务上有出色的表现,因此作者主张LLMs充当控制者来管理当前现有的AI模型,用于处理AI任务,自然语言则成为实现该目标的通用接口。作者提出HuggingGPT,一个利用LLMs来连接机器学习社区(如Hugging Face)中各种AI模型来解决AI任务的框架。具体来说,当收到请求时,作者利用ChatGPT进行任务规划,根据Hugging Face中模型的功能描述来选择模型,执行每个子任务,并根据结果进行响应。HuggingGPT可以处理大量不同领域和模态复杂的任务,并且取得了可观的结果。
1 Introduction
LLMs如ChatGPT由于其出色的自然语言任务的处理能力受到来自工业界和学术界的广泛关注,同时LLMs的强大能力也推动了许多新兴的研究课题。尽管如此,现有的LLM技术依然有很多不足,并且有如下问题亟待解决:
- 输入模态单一,只能输入文本。
- 现实中很多复杂任务都是由多个子任务组成,需要多个模型的调度和协作。
- 很多情况下其性能不如专家模型。
本文作者指出,为了解决复杂的AI任务,LLMs应该和外部模型进行协作从而利用它们的能力。因此,核心问题在于如何选取合适的中间件来连接LLM和AI模型。作者注意到,每个AI模型可以通过自然语言来描述其功能,因此,他们引入了一个概念:语言是连接LLMs和AI模型的通用接口,换句话说,通过将这些模型的描述放入prompt中,LLMs可以像一个大脑一样管理、规划、调度和协作这些AI模型。但是这又出现另一个问题,解决大量AI任务需要收集大量高质量模型的描述,这需要庞大的prompt工程。因此作者将目光看向了机器学习社区如Hugging Face,如果将LLMs和具有高质量的AI模型社区连接起来,那么可能帮助解决复杂的AI任务。
因此,本文提出HuggingGPT,将LLMs和ML社区联系起来,它可以处理不同模态的输入并自主解决许多复杂的AI任务。具体来说,对于Hugging Face中的每个AI模型,作者使用库中对应的模型描述与prompt融合到一起与ChatGPT相连。之后,LLMs充当大脑来确定用户问题的答案。整个过程如下图所示:
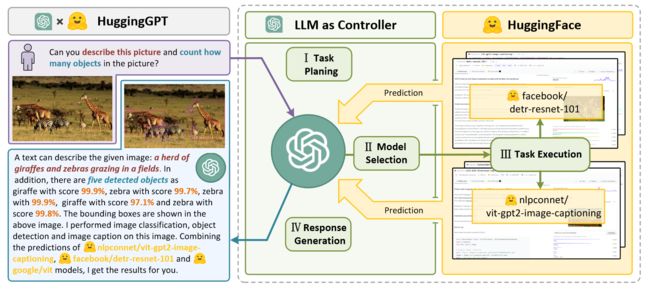
整个过程可以分为四个步骤:
- 任务计划。
- 模型选择。
- 任务执行。
- 生成回复。
受益于这种设计,HuggingGPT可以根据请求自动生成计划,使用外部模型,汇聚多模态感知能力和专家模型的能力从而解决复杂的AI任务。其中任务规划的设计起到非常重要的作用。总的来说,本文的贡献如下:
- 利用专家模型和LLMs的优势,为设计通用AI解决方案提供了新的途径。
- 集成Hugging Face中大量的任务特定模型,HuggingGPT可以处理多模态和领域的AI任务。
- 作者指出HuggingGPT中任务规划的重要性,并制定一些实验评估LLM的规划能力。
- 在多模态具有挑战性的任务上证明了HugingGPT解决复杂问题上的巨大潜能。
2 Related Works
LLMs受益于其庞大的语料库和密集的计算,在零样本和小样本任务甚至数学计算、常识推理等复杂任务上表现出令人印象深刻的能力。为了将LLMs的能力扩展到文本之外的任务,现有的工作可以分为两个分支:
- 设计统一的多模态语言模型解决各种人工智能任务。
- 研究LLM使用工具或模型的整合。
与这些方法不同,HuggingGPT向着更通用的AI能力迈进:
- HuggingGPT使用LLM作为接口,有效将LLM的语言理解能力和其它模型的专业能力结合起来。
- HuggingGPT不限于视觉感知人物,可以解决任何模态任何领域的任务。
- 提供更开放的模型选择方法,可以持续便捷集成各种AI模型。
3 HuggingGPT
HuggingGPT的工作流程包括四个阶段:任务规划,模型选择,任务执行和响应生成。如下图所示:

整个过程HuggingGPT自动部署,从而协调和执行专家模型以实现目标。下表展示了详细的prompt设计。

3.1 Task Planning
一般来说,现实场景中很多用户请求包含复杂的意图,因此,作者将任务规划作为HuggingGPT的第一步,旨在利用LLM分析用户的请求并分解为结构化任务的集合。此外,作者还要求LLM确定这些分解任务的依赖和执行顺序,以建立其连接。HuggingGPT进行了prompt的设计,包括基于规范的指令和基于演示的解析。
Specification-based Instruction
为了更好表示用户请求,作者期望LLM能够遵循一些规范来解析任务。因此作者提供了任务的模板,指导LLM依据规范进行任务解析,如表1中task、id、dep和args,用于表示任务的信息、标识符、依赖项和参数。
Demonstration-based Parsing
为了更好理解任务规划的意图和标准,HuggingGPT在prompt中加入了多个演示,每个演示都由用户请求和相应的输出组成,输出任务的预期解析序列。此外,为了支持更全面的用户请求,作者通过附加指令将聊天日志合并到prompt中。
3.2 Model Selection
任务计划好后,下一步需要对任务匹配最合适的模型。 作者使用模型描述作为连接模型的语言接口。具体来说,作者从ML社区中获取模型的描述,然后根据上下文任务分配模型选取适合该任务的模型。
In-context Task-model Assignment
任务分配模型作为单选任务,备选的模型在给定的文本中以选项形式出现。HuggingGPT理论上会选择最合适的模型,但是由于token长度限制,无法包含所有相关的模型信息,因此会进行过滤操作,然后对选中的模型根据下载量进行排序得到Top-k模型。该策略可以大大减少prompt中的token使用,有效选出合适的模型。
3.3 Task Execution
获取模型后下一步就是执行任务。这一步中,HuggingGPT会自动将任务的参数输入到模型中,运行模型得到推理结果,然后发送回LLM。由于先决任务的输出是动态生成的,HuggingGPT需要在任务启动前动态指定任务的依赖资源。因此建立资源依赖性任务之间的连接具有挑战性。
Resource Dependency
为了解决资源依赖问题,作者使用了特殊的符号task_id是先决任务的标识。在任务执行阶段,HuggingGPT动态引入该资源,这样的方式可以使HuggingGPT高效处理资源依赖关系。
此外,如果任务没有依赖,那么将并行执行这些任务,提高推理的效率。为了进一步加速和计算稳定性,作者还提供了混合推理端点来部署这些模型。
3.4 Response Generation
任务执行完毕,HuggingGPT需要生成最终响应。如表一所示,HuggingGPT会将之前所有阶段的信息整合为简短的摘要,包括计划的任务列表、选取的模型以及模型的推理结果。
最重要的还是推理结果,会以结构化格式出现。HuggingGPT允许LLM接收这些结构化的推理结果作为输入,以自然语言形式生成响应。
4 Experiments
4.1 Settings
实验部分,作者采用了gpt-3.5-turbo,text-davinci-003,gpt-4等模型作为LLMs,通过调用OpenAI的接口实现。
4.2 Qualitative Results
图一和图二都对HuggingGPT进行了演示。图一的用户请求包含描述图像和对象计数两个子任务,为了完成这两个子任务,HuggingGPT规划了三个任务:图像分类,图像描述和对象检测,最后集成模型推理的结果生成响应。图二展示了更详细的示例,具体可以认真过一遍这张图片。更多演示见附录A3。
4.3 Quantitative Evaluation
HuggingGPT中,任务规划是整个工作流中最重要的步骤,它直接决定了接下来的pipeline。因此,作者认为任务规划的质量也会影响LLM在某些部分的能力(如推理和决策)。为了更好地对任务规划进行评估,作者将任务分为三个不同的类别并制定不同的指标。

- 单一任务。当任务名称和预测标签完全相等时,计划是正确的。
- 时序任务。表示用户的请求可以分解为多个子任务的序列。
- 图任务。用户请求可以分解为有向无环图。
数据集为作者收集到的由GPT-4生成以及标注者标注的请求。包括一些复杂的请求,涵盖上面三种任务。GPT-4标注数据集评估结果如下:
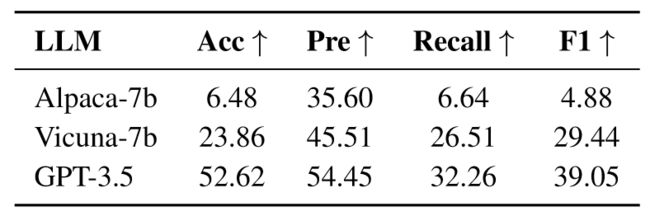

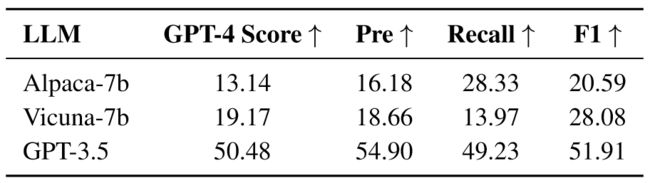
可以看到GPT3.5表现出突出的规划能力,远远优于其它两个模型。在专家标注的46个请求上进行实验的结果如下:
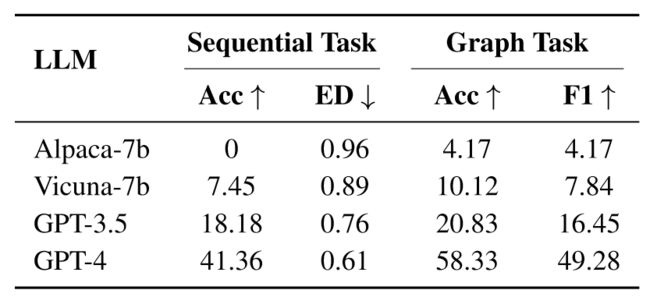
结果和上面的结论一致,越强大的LLM在任务规划上表现更出色,并且可以发现,GPT-4标注的请求与人类相比有很大的差距。
5 Limitations
尽管HuggingGPT展示了解决AI任务的新范式,但是仍有局限性以及需要提升的地方:
- 规划严重依赖LLM的性能。
- HuggingGPT需要多次与LLM进行交互,效率不高。
- Token长度限制导致无法满足需求。
- LLM具有不稳定性,因为输出不可控。
6 Conclusion
本文提出了一个名为HuggingGPT的系统来解决人工智能任务,以语言作为连接LLM和AI模型的接口,并且利用Hugging Face等社区的模型自动解决用户的不同请求。通过利用LLM在理解和推理上的优势,HuggingGPT可以将用户的意图分解为多个子任务,然后根据不同的任务调用专家模型进行执行得到响应。HuggingGPT 在解决具有挑战性的人工智能任务方面展示了巨大的潜力,从而为实现通用人工智能铺平了新的途径。
阅读总结
利用LLMs执行任务规划的工作在随着LLMs性能的不断提升呈现爆发式增长,包括利用LLMs解决复杂推理任务,利用LLMs作为agent在Minecraft进行探索规划,利用LLMs使用工具等等,这些工作都是借助了LLM出色的理解和推理能力,通过自然语言作为中间媒介,以人的思维方式来解决各种问题。本文的工作非常新颖,在当前LLM在模态和领域任务上存在短板的情况下,HuggingGPT既利用了LLMs出的理解和规划能力,又利用了专家模型的解决特定任务的能力。但是这个工作还有个明显的短板,因为LLMs本身就有很强的处理NLP任务的能力,如果遇到NLP相关的任务,直接用LLMs解决反而比专家模型效果来的要好。此外,随着多模态LLMs的飞速发展,其解决不同场景和模态任务的能力将很快赶超专家模型,传统的专家模型终将被淘汰。因此,HuggingGPT只是当前这个短暂时代的产物,可能不到一年,这样的工作就又被淘汰了。