MCAN论文笔记——Deep Modular Co-Attention Networks for Visual Question Answering
MCAN
MCAN论文笔记,仅记录个人阅读感受,如有问题和侵权行为,欢迎指出
Deep Modular Co-Attention Networks for Visual Question Answering, CVPR 2019
Tutorial (rohit497.github.io)
本文受到Transformer启发,运用了两种attention unit:
- 模型内部交互的self-attention(例如word-to-word or region_to_region),记为SA
- 模型之间交互的guided-attention(例如word-to-region),记为GA
组合使用SA和GA,我们就能获得可以深度级联的不同的MCA模块。使用这种方式构造出来的网络能够很好的学习到Co-Attention的特征,同时,实验发现,利用self-attention对image region进行建模,可以很好的提高object counting的效果,这在传统的VQA任务中是比较难以实现的。
Modular Co-Attention Layer
与Transformer类似,MCA中的两个部分:SA和GA如图所示:

其计算过程与Transformer中的Multi-head Attention计算一般无二,不再过多赘述:
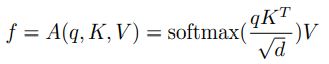

Modular Composition for VQA
基于上述提出的SA和GA attention单元,该模型将其进行组合,形成了三种modular co-attention layer(MCA layer),这些模块均可以进行上述提出的深度级联,即一个MCA layer的输出可以作为下一个MCA layer的输入。
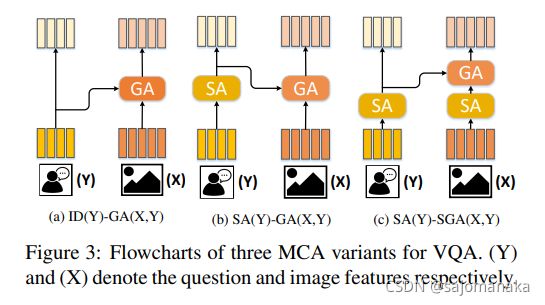
可以观察到其中© SA(Y)-SGA(X, Y) 的结构就和我们常见的Transformer非常类似
该论文指出,除了上面三种MCA的组织方式,还可以尝试别的组合方式,但由于篇幅限制,就没有给出实验比较。如GA(X, Y)-GA(Y, X) & SGA(X, Y)-SGA(Y, X)
Modular Co-Attention Networks
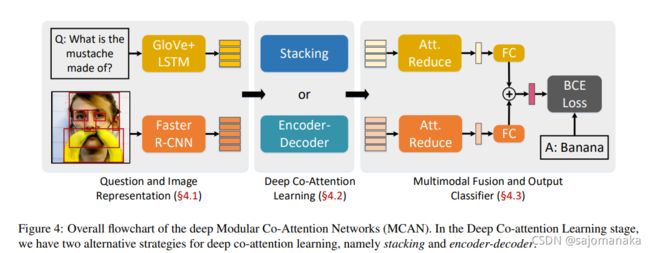
总体结构如图所示,分为三个部分
- Question and Image Representation
- Deep Co-Attention Learning
- Multimodal Fusion and Output Classifier
Question and Image Representations
与之前的很多的任务类似(例如Bottom-up and Top-down),该模型的图像特征采用利用Faster R-CNN提取的对象特征,问题表示采用GloVe的Embedding和LSTM 进行encoding。不再赘述
Deep Co-Attention Learning
假设有L层MCA layer ,对于每一层MCA layer,有:
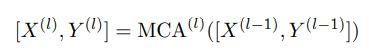
其中 X ( 0 ) = X a n d Y ( 0 ) = Y X^{(0)}=X \; and \; Y^{(0)}=Y X(0)=XandY(0)=Y 作为初始化参数
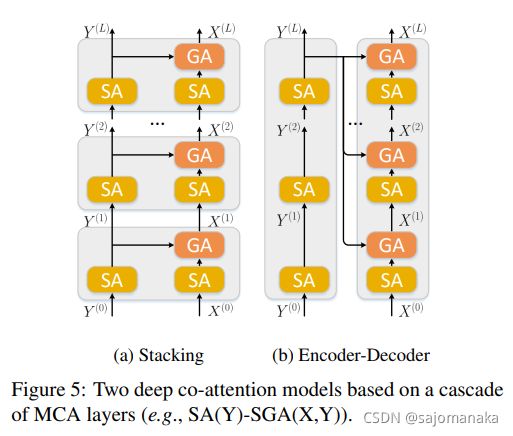
以SA(Y)-SGA(X, Y) layer 为例,其中有两种组织layer的方式,分别为:Stacking和Encoder-Decoder,如下图所示:
Multimodal Fusion and Output Classifier
经过Deep Co-Attention Learning,模型得到:
![]()
![]()
分别对于图像和语言都获得了丰富的语义信息,在将二者进行fusion之前,要添加一个attention reduction model。这个模块需要一个两层的MLP:(FC(d)-ReLU-Dropout(0.1)-FC(1)),然后通过此计算出一个注意力分数 α \alpha α,有点类似于一个self-attention?表示如下:
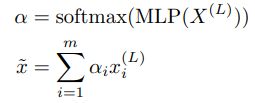
对于x,y都进行如上述操作,然后进行fusion:
![]()
最后通过一个sigmoid函数计算各个类别得分,以BCELoss为Loss function
Experiments
对于不同模块的实验:
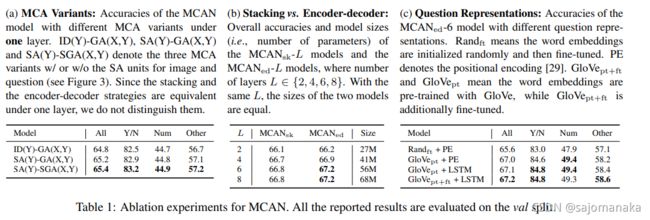
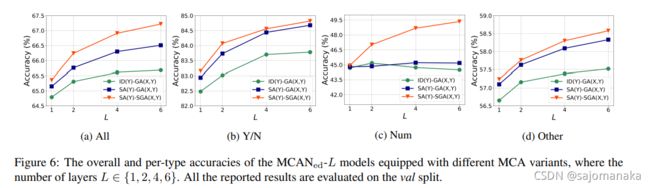
层数对结果的影响:
attention影响:
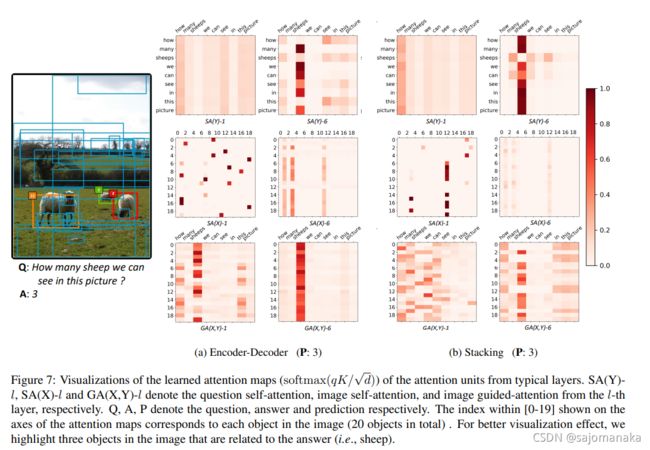
attention 可视化例子:

参考资料:
用于视觉问答的深度模块化共同注意网络 《Deep Modular Co-Attention Networks for Visual Question Answering》_xiashilin的博客-CSDN博客
[1906.10770] Deep Modular Co-Attention Networks for Visual Question Answering (arxiv.org)