生成式深度学习(第二版)-译文-第五章-自回归模型
章节目标
- 了解自回归模型为何比较适合生成序列数据 (例如文本)
- 了解如何处理并tokenize文本数据
- 了解RNN(recurrent neural networks)的架构设计
- 利用Keras从零开始构建并训练 LSTM (long short-term memory network)
- 使用LSTM来生成新的文本
- 了解RNNs的其它变种,包括GRUs(Gated Recurrent Units) 以及 双向cells
- 理解图形数据如何被当做像素序列处理
- 学习PixelCNN的架构设计
- 使用Keras从零开始构建PixelCNN
- 使用PixelCNN来生成图像
迄今为止,我们已经探索了两类不同的包含隐变量的生成模型 — 变分自编码器 (VAEs) 以及 生成对抗网络(GANs)。在这两种情况下,我们都引入了一个新的变量,其分布易于采样,模型学会如何将该变量解码回原始的图像域。
现在,我们将注意力转向 自回归模型 — 它将生成式建模问题简化为序列处理过程。自回归模型以序列中前序值作为预测条件,而非依赖于一个隐藏随机变量。因此,它们尝试显示对数据生成分布进行建模,而非只是(如VAEs)寻找数据分布的一个近似。
在本章中,我们需要寻求两类不同的自回归模型: LSTM 以及 PixelCNN。我们将LSTM应用到文本数据,将PixelCNN应用到图像数据。我们将在第九章中涉及另外一种成功的自回归模型,Transformer。
引言
要理解LSTM的工作机理,我们先一起访问一个奇怪的监狱,其中囚徒们组成了一个文学社:
| 囚徒的文学社 |
|---|
| 爱德华·索普 不喜欢自己监狱长的工作。他整天忙于看管囚徒,无暇追求自己写短篇小说的爱好。他非常丧气,急需寻求某种方式来产出一些新内容。 |
| 一天,他偶获灵感,想到了一种方式,能够让自己在当前的工作模式下也能从事小说的写作 — 他想要让同监狱犯人一起帮他写作。他将这个新型社会命名为 Literary Society for Troublesome Miscreants, 或者叫LSTM (图5-1) 。该监狱属实奇怪,因为它仅仅只有一个大的隔间,却包含了256个囚徒。每个囚徒对于爱德华当前的故事该如何继续都有自己的想法。每一天,爱德华将他关于小说的最新的段落丢到隔间里,囚徒们的工作是根据新的段落和囚徒们前一天的想法来分别更新自己一对于故事当前状态的观点。 |
| 每个囚徒使用特定的思想过程来更新自己的观点,包括来自新增短路以及其他囚徒的观点的均衡信息。首先,他们决定前天的观点需要遗忘多少,以囊括新段落和其他囚徒的信息。他们也使用这些信息来形成新的想法,以决定从多大程度上将这些信息融合到昨天的旧想法中。这形成了囚徒今天的新观点。 |
| 但是,囚徒们都是隐秘的,并不总会告诉其他囚徒自己所有的观点。他们每人都会用最新的段落和其他囚徒的观点来决定自己披露多少观点。 |
| 当爱德华想要囚徒生成序列段落中的下一个词,所有囚徒将他们的观点告诉门卫,门卫聚合这些信息,并最终决定在小说的最后加入什么词。这个新词进一步反馈回监狱,整个过程持续知道全部故事完成。 |
| 为了训练囚徒和门卫,爱德华给了它们自己之前写的一系列词,并监控囚徒们选择的下一个词是否正确。基于准确率,他经常训练他们,慢慢的,他们逐渐学会了如何用爱德华独特的风格来撰写小说。 |
| 经过类似过程的多次迭代,爱德华发现系统已经可以生成相当真实的文本。爱德华满意的把生成的故事放入了他的新书,名为《爱德华·索普寓言》。 |

索普先生的故事以及他众包的寓言其实就是一项臭名昭著的序列数据(例如,文本)自回归技术的类比: long short-term memory network。
Long Short-Term Memory Network (LSTM)
一个LSTM是一种特定类型的循环神经网络(RNN)。RNNs包含一个循环层 (或者单元), 使得他们可以通过将某个时间点的输出作为另一时间点的输入来处理序列数据。
当RNNs 首次提出时,循环层非常简单,仅仅只包含了一个tanh操作子,以确保不同时间戳上传递的信息都会被放缩到 -1 和 1之间。但是,这个技术会遭受梯度消失问题,无法扩展到长序列数据。
LSTM 单元首次提出于Sepp Hochreiter和Jurgen Schmidhuber在1997年的一篇论文。在这篇论文中,作者描述了LSTMs如何摆脱普通RNNs会遭受的梯度消失问题,并且可以在数百个时间戳长度的序列上进行训练。自此以后,LSTM架构被采用并持续改进,其变种(如GRU,gated recurrent uinits,本章稍后会介绍)目前在Keras里也能提供。
LSTMs已经应用于诸多序列数据相关的问题,包括时间序列预测,情绪分析,音频分类。本章中,我们将使用LSTMs来解决文本生成的问题。
| 运行示例代码 |
|---|
| 本示例代码可以从Jupyter Notebook的如下路径找到:“notebooks/05_autoregressive/01_lstm/lstm.ipynb” |
Recipes数据集
我们将使用Kaggle上可获取的表层食谱数据集(Epicurious Recipes dataset)。这是一个超过2万食谱的集合,同时也有其他的元数据,如营养信息以及成分列表。
我们可以运行本书代码仓中Kaggle数据集下载器来下载数据集,如样例5-1所示。这将本地保存食谱和其它关联元数据到 /data 目录。
bash scripts/download_kaggle_data.sh hugodarwood epirecipes
例5-2 给出了数据如何加载及过滤,使得只有包含标题和详细描述的菜谱得以保留。菜谱文本串的一个样例如下 样例5-3所示。
with open('/app/data/epirecipes/full_format_recipes.json') as json_data:
recipe_data = json.load(json_data)
filtered_data = ['Recipe for ' + x['title'] + ' |' + ‘’.join(x[‘directions’])
for x in recipe_data
if 'title' in x
and x['title'] is not None
and 'directions' in x
and x['directions'] is not None
]
样例 5-3. Recipes数据集中的一条文本字符串
“Recipe for Ham Persillade with Mustard Potato Salad and Mashed Peas | Chop enough
parsley leaves to measure 1 tablespoon; reserve. Chop remaining leaves and stems
and simmer with broth and garlic in a small saucepan, covered, 5 minutes.
Meanwhile, sprinkle gelatin over water in a medium bowl and let soften 1 minute.
Strain broth through a fine-mesh sieve into bowl with gelatin and stir to dissolve.
Season with salt and pepper. Set bowl in an ice bath and cool to room temperature,
stirring. Toss ham with reserved parsley and divide among jars. Pour gelatin on top
and chill until set, at least 1 hour. Whisk together mayonnaise, mustard, vinegar,
1/4 teaspoon salt, and 1/4 teaspoon pepper in a large bowl. Stir in celery,
cornichons, and potatoes. Pulse peas with marjoram, oil, 1/2 teaspoon pepper, and
1/4 teaspoon salt in a food processor to a coarse mash. Layer peas, then potato
salad, over ham.”
在我们通过Keras构建LSTM之前,我们需要快速理解文本数据结构,并理解文本数据结构与本书中迄今为止见过的图像数据有何区别。
使用文本数据
文本和图像数据有一些关键的不同,这意味着很多方法尽管在图像数据上可以较好工作,但不能应用于文本数据。特别的:
-
文本数据: 包含离散的块(字符或者单词),而图像中的像素则是连续色度空间中的点。对于一个绿色像素,我们可以很轻易的让绿色像素更蓝,但是我们并不清楚,该怎样才能让一个单词 cat 更像单词 dog。这意味着,我们可以轻松的在图像数据上应用反向传播,因为我们可以计算损失函数相对单个像素的梯度来建立如何调节像素色彩的合适方向以最小化损失。而对于这些离散的文本数据,我们显然无法直接按照相同方式反向传播,所以我们需要找到一个围绕这一问题的方法。
-
文本数据有时间维度,而无空间维度,而图像数据有两个空间维度,而无时间维度。词语的顺序在文本数据中中非常重要,词语的翻转是无意义的,而图像通常可以翻转而不影响内容。进一步的,通常我们还需要捕捉词语间的长时序列依赖性: 例如,问题的答案,或者代词的上下文。对图像数据而言,所有的像素可被同时处理。
-
文本数据在个性单元 (单词 或者 字符) 对小的改变是非常敏感的。图像数据对单个像素单元的改变就没那么敏感 — 即使一些像素被改变,一个房子的图像仍然可以被识别为房子。但是,对于文本数据,改变少数单词会极大改变段落的意思,或者让段落无意义。这使得训练一个能生成一致文本你的模型更加困难,因为每一个单词都对整个段落的意义很重要。
-
文本数据有基于规则的语法结构,而图像数据则没有规则集合来指导像素如何赋值。例如,在任何语境下,我们写这么一段话 “The cat sat on the having” 都没有具体的语法意义。语义规则同样也极难建模,即使从语法上来讲,“I am in the beach” 没有任何错误,这句话也毫无意义。
| 基于文本的生成式深度学习前沿 |
|---|
| 直到最近,大部分复杂的生成式深度学习模型主要都聚焦在图像数据上,因为上文列的大部分挑战超过了当前最先进技术的应对范畴。然而,在最近五年中,基于文本的生成式深度学习发展迅速,这多亏了transformer模型架构的引入,正如第九章中我们将看到的。 |
记住上面几点,现在让我们一起看看需要采取哪些措施来使用文本数据训练LSTM网络。
Tokenization
第一步是清理并tokenize文本。Tokenization是将文本切分问个体单元(例如单词或字符)的过程。
你如何tokenize文本 去决议你希望自己的文本生成模型达到什么目标。使用单词或者字符 tokens各有利弊,你的选择将影响你在建模之前将如何清理文本,也将影响模型之输出。
如果你使用单词tokens:
-
所有文本都转换为小写,以此来保证句首的大写单词跟句中的相同单词保持相同的tokenized方式。但是,在一些情况下,这可能是我们不希望的。例如,一些名词,如名字或地址,可能从保持大写中受益,因为这样他们可以独立的tokenized。
-
文本 词典 (vocabulary,意指训练集中不同词的集合) 可能非常大,一些词可能仅仅只极少出现,甚至只出现一次。将出现极少的单词替换为 未知词 的token可能更为明智,而非将这些词也作为独立的tokens,以此来减少需要学习的神经网络权重数量。
-
单词是可以简化的,意思是他们可以简化到最简单的形式,以使得动词的不同时态也能一起tokenized。例如,browse,browsing,browses,以及browsed都会简化到brows。
-
对于标点符号,你要么tokenize,要么所需直接移除。
-
使用 tokenization 这个词的意思其实也在表明,模型永远预测不到训练字典之外的单词。
如果你使用字符tokens:
-
模型可能会产生训练字典之外的字符序列 — 这在某些情况下是我们想要的,但其他情况下并非如此。
-
大写字母可以被转换到小写形式,或者作为独立的tokens。
-
当使用字符tokenization时,字典通常更小。这对于模型训练速度是有益的,因为在最终的输出层只有更少的权重需要学习。
对于这个例子,我们将使用小写单词tokenization,不使用单词简化。我们也会将标点符合tokenize化,因为我们希望模型能够预测合适终结句子,何时需要逗号。
样例5-4之代码清理并tokenizes 文本。
def pad_punctuation(s):
s = re.sub(f"([{string.punctuation}])", r' \1 ', s)
s = re.sub(' +', ' ', s)
return s
# 标点符号补齐,将它们看做是独立的单词
text_data = [pad_punctuation(x) for x in filtered_data]
# 转换成Tensorflow dataset
text_ds = tf.data.Dataset.from_tensor_slices(text_data).batch(32).shuffle(1000)
# 创建一个Keras TextVectorization层来将文本转换为小写,给最流形的10000个单词一个对应的整数token,将序列修剪或者补齐至201 tokens长。
vectorize_layer = layers.TextVectorization(
standardize = 'lower',
max_tokens = 10000,
output_mode = "int",
output_sequence_length = 200 + 1,
)
# 将TextVectorization层应用于训练数据
vectorize_layer.adapt(text.ds)
# vocab 变量存储了单词tokens的列表
vocab = vectorize_layer.get_vocabulary()
一个菜谱tokenization之后的示例如下5-5所示。我们训练模型时采样的序列长度是训练过程的一个参数。在这个例子中,我们选择了序列长度200,因此我们补齐或者裁切到这个长度+1, 以允许我们创建目标变量 (在下一小节我们将介绍更多)。为了达到目标长度,向量的末尾以0填充。
| 停止Tokens |
|---|
| Token 0 通常被认为是停止 Token,标志着文本串到达了结尾。 |
# 样例 5-3 中菜谱 tokenized 之后的结果
[ 26 16 557 1 8 298 335 189 4 1054 494 27 332 228
235 262 5 594 11 133 22 311 2 332 45 262 4 671
4 70 8 171 4 81 6 9 65 80 3 121 3 59
12 2 299 3 88 650 20 39 6 9 29 21 4 67
529 11 164 2 320 171 102 9 374 13 643 306 25 21
8 650 4 42 5 931 2 63 8 24 4 33 2 114
21 6 178 181 1245 4 60 5 140 112 3 48 2 117
557 8 285 235 4 200 292 980 2 107 650 28 72 4
108 10 114 3 57 204 11 172 2 73 110 482 3 298
3 190 3 11 23 32 142 24 3 4 11 23 32 142
33 6 9 30 21 2 42 6 353 3 3224 3 4 150
2 437 494 8 1281 3 37 3 11 23 15 142 33 3
4 11 23 32 142 24 6 9 291 188 5 9 412 572
2 230 494 3 46 335 189 3 20 557 2 0 0 0
0 0 0 0 0]
样例5-6中,我们可以看到tokens列表的一个子集,映射到各自的标号。本层保留 token 0 以作补齐 (也即,0 作为停止token)。token 1 作为 未知单词 (不在前10000单词中的词,如 persillade)。 其他的词皆是以出现频率而赋予 token。词典中单词的数目也是训练过程的参数之一,囊括越多的单词,则越少会出现 未知 token,但是,模型需要变得更大,以容纳更大的词典尺寸。
# 样例 5-6 TextVectorization层之词典
0:
1: [UNK]
2: .
3: ,
4: and
5: to
6: in
7: the
8: with
9: a
训练集构建
给定该点之前的单词序列,我们的LSTM将被训练来预测序列中的下一个词。例如,我们可以把下面的tokens喂给模型: grilled chicken with boiled, 我们可以期望模型输出合适的下一个单词 (例如,potatoes, 而非bananas)。
我们可以简单的把整个sequence移动一个token,以此来构建目标变量。
数据集生成步骤可以通过如下样例5-7中的代码生成。
# 创建训练集
def prepare_inputs(text):
text = tf.expand_dims(text, -1)
tokenized_sentences = vectorize_layer(text)
x = tokenized_sentences[:,:, -1]
y = tokenized_sentences[:,1:]
return x, y
# 创建训练集: 包含食谱tokens (输入) 以及 同样的向量移动一个token (目标)
train_ds = text_ds.map(prepare_inputs)
LSTM架构
总体LSTM模型架构如下表5-1所示。模型的输入是整数token序列,输出是词典中10000个单词每个在序列的下一个位置出现的概率。要从细节上理解这是如何工作的,我们需要引入两个新的层类型,Embedding 层以及 LSTM。
| 层类型 | 输出形状 | 参数数目 |
|---|---|---|
| InputLayer | (None, None) | 0 |
| Embedding | (None, None,100) | 1,000,000 |
| LSTM | (None, None, 128) | 117,248 |
| Dense | (None, None, 10000) | 1,290,000 |
| 总的参数 | 2,407,248 |
|---|---|
| 训练参数 | 2,407,248 |
| 非训练参数 | 0 |
LSTM输入层
注意 Input 层不需要我们来特别提前指定序列长度,batch size 和 序列长度 都是灵活的 (因此,形状标注为 (None, None))。这是因为所有的下游层对将要通过的序列长度是不可知的。
嵌入层
一个 embedding 层本质上就是一个查找表,可以将每个整数token转换成一个长为 embedding_size的向量。如下图5-2所示。查找向量是作为权重通过模型学到的。因此,该层权重的数目等于字典的尺寸乘以嵌入向量的维度(例如,10000 x 100 = 1000000)。

我们将每个整数token嵌入到连续的向量,因为它使得模型可以学到每个单词的表示,该表示可以通过反向传播更新。我们当然也可以仅仅只对每个输入做独热编码,但使用嵌入层更常用,因为它使得嵌入层本身可训练,因此让模型具备更强的灵活性来决定该如何对每个token进行嵌入以提升性能。
因此,输入层传递了一个形状为[batch_size, seq_length] 的整数序列张量到嵌入层,嵌入层输出 形状为 [batch_size, seq_length, embedding_size]。该输出进一步传递给 LSTM 层(图5-3)。

LSTM层
要理解 LSTM 层,我们需要首先看看一个通用的循环层(recurrent layer)如何工作的。
一个循环层具有特定的性质: 它可以处理序列输入数据 x 1 , . . . , x n x_1, ... , x_n x1,...,xn。它包含了一个单元(cell),随着序列 x t x_t xt可以持续更新隐层状态 h t h_t ht。
隐层状态是一个向量,其长度等于cell中units个数 — 这可以被理解为cell对序列的当前理解。在时间步 t,cell 使用了隐状态的前序值 h t − 1 h_{t-1} ht−1 ,连同当前时间步的数据 x t x_t xt 来产生一个更新的隐状态向量 h t h_t ht。这一循环过程一直持续,知道序列的结尾。一旦序列结束,循环层输出最终cell的隐状态 h n h_n hn,该状态传递给忘了的下一层。这一过程如下图5-4所示。

为了更细节的解释这点,让我们结构这一过程,使得我们可以看到一个单一序列是如何喂到层里(图5-5)。

Cell 权重
我们需要记住很重要的一点是,在这个框图中,所有的cell共享相同的权重(实际上,它们就是相同的cell)。这个框图本质上与图5-4并无区别,只是用另外一种方式画出了循环层的机制。
这里,我们通过把cell复制到各个时间步表示循环过程,并展示出当数据流经cell时 隐层状态 是如何持续更新的。我们可以清楚看到,之前的隐层状态如何与当前的序列数据点(当前的词向量嵌入)混合,来产生下一个隐状态。该层的输出是当输入序列中的每一个单词都经过处理之后cell的最终隐状态。
警告
cell的输出被称作 隐状态 是一个不幸的命名公约 — 事实上它并不是隐的,你也不必如此考虑它。实际上,最后的隐状态是该层的总输出,在本章中,我们只需要利用这一事实: 在每一个单一的时间步,我们都可以获取隐状态。
LSTM Cell
既然我们已经知道了一个通用的循环层是如何工作的,让我们进一步看看LSTM cell内部。
给定前序隐状态 h t − 1 h_{t-1} ht−1 和当前的词嵌入 x t x_t xt,LSTM cell的职责是输出一个新的隐状态 h t h_t ht。简要回顾一下, h t h_t ht 的长度等于 LSTM 的 units 数目。这是一个当你定义层时设定的参数,与序列的长度并无关系。
警告
确保你没有混淆两个术语 cell 以及 unit。LSTM 层中只有一个cell,它是由包含的 units 数目所定义。就像我们之前讲的故事中囚徒所处的监狱空间一样。我们通常把循环层画作一系列摊开的 cells,因为这种绘制方式有助于我们直观的看到隐层状态如何随着时间步来更新。
一个 LSTM cell 包含一个 cell 状态 C t C_t Ct,它可以看做cell关于序列当前状态的内部置信度。这和cell在最后的时间步最终输出的隐状态 h t h_t ht 是不同的。cell 状态和隐状态长度(cell中units个数)相同。
让我们进一步看看单一cell,以及隐状态是如何更新的(图5-6)。

隐状态之更新一共分为6步:
- 前序时间步之隐状态, h t − 1 h_{t-1} ht−1 以及当前的词嵌入, x t x_t xt,这两者拼接起来,并传递给 forget 门。forget 门简单来说就是一个密集链接层,权重矩阵为 W f W_f Wf,偏置为 b f b_f bf,以及一个sigmoid 激活函数。结果向量, f t f_t ft 长度与cell中的units数目相同,其值为 0 到 1之间,可以决定之前的Cell状态 C t − 1 C_{t-1} Ct−1 ,有多少需要保留。
- 拼接向量也将进一步传给一个 input 门,该门与 forget 门类似,也是一个密集连接层,权重矩阵为 W i W_i Wi,偏置为 b i b_i bi,以及一个sigmoid 激活函数。该门的输出, i t i_t it, 长度与cell中的units数目相同,其值为 0 到 1之间,可以决定多少新的信息要加入到之前的Cell状态 C t − 1 C_{t-1} Ct−1 。
- 拼接向量也将进一步传给一个 dense 层,权重矩阵为 W C W_C WC,偏置为 b C b_C bC,以及一个 tanh 激活函数,该层的输出, C ˉ t \bar{C}_t Cˉt,包含了 cell 想要保留的新信息。其长度与cell中的units数目相同,其值为 -1 到 1之间。
- f t f_t ft 和 C t − 1 C_{t-1} Ct−1 进行逐元素乘法,并与 i t i_t it和 C ˉ t \bar{C}_t Cˉt的逐元素乘法结果相加。这表示前序cell状态的遗忘部分 加上 新的相关信息,以产生更新的Cell 状态 C t C_t Ct。
- 拼接向量进一步传给一个 output门:一个密集连接层,权重矩阵为 W o W_o Wo,偏置为 b o b_o bo,以及一个sigmoid 激活函数。该门的输出, o t o_t ot, 长度与cell中的units数目相同,其值为 0 到 1之间,可以决定多少更新后的Cell状态 C t C_t Ct,需要从cell中输出 。
- o t o_t ot 与经过tanh处理的更新后的Cell状态 C t C_t Ct逐元素相乘,以此来产生新的隐状态 h t h_t ht。
Keras LSTM 层
所有的复杂性都被KERAS的LSTM层类型封装起来了,所以你不用担心如何自己实现它。
译者注: 上述的讲解过于简洁,关于RNN和LSTM的区别和联系对大部分读者而言可能没那么容易理解,可以进一步参考这篇博客。

LSTM训练
构建,编译及训练LSTM的代码如下示例5-8所示。
# 构建,编译及训练LSTM
# Input层不需要我们预先指定指定序列长度(它是灵活的),所以我们可以用None占位
inputs = layers.Input(shape=(None,),dtype="int32")
# Embedding层需要两个参数: 词典尺寸 (10000 tokens),以及嵌入向量维度(100)
x = layers.Embedding(10000,100)(inputs)
# LSTM层需要我们指定隐向量的维度(128)。我们仍然选择返回隐状态的完整序列,而不仅仅只是最后一个时间步的隐状态
x = layers.LSTM(128, return_sequences=True)(x)
# Dense Layer将每步的隐状态转换为下一个token的概率
outputs = layers.Dense(10000, activation = 'softmax')(x)
# 给定一个tokens序列,整个模型预测下一个 token
lstm = models.Model(inputs, outputs)
loss_fn = losses.SparseCategoricalCrossentropy()
# 模型用 SparseCategoricalCrossentropy 损失编译 --- 这与 categorical cross-entropy 一致,但是这个当 labels是整数 而非 独热编码向量时使用
lstm.compile("adam", loss_fn)
# 模型拟合到训练数据集
lstm.fit(train_ds, epochs=25)
如下图5-7. 我们可以看到LSTM训练的开始几个 epochs — 注意 example output是如何随着损失度量下降 而变得越来越具备可理解性。图5-8展示了cross-entropy loss metric 随着训练过程下降。


现在,我们已经编译并训练了LSTM,我们可以开始通过以下过程用它来生成长文本:
- 给网络喂已有单词序列,并让它来预测下一个单词。
- 把预测的单词加入已有序列,并重复。
网络会输出一组对应每个单词的概率,从这个概率分布中我们可以进行采样。因此,我们可以让文本的生成过程随机而非固定。进一步的,我们可以引入一个温度参数 (temperature) 到采样过程,以此参数标识我们希望该过程有几分固定。
| 温度参数 |
|---|
| 温度接近0,意味着让采样过程更确定 (也即,具有最高概率的单词有极大概率被选中),而温度接近1意味着每个单词按照模型输出的概率来采样。 |
这一过程如样例5-9代码所示,其构建了一个callback函数,可以用于在每次训练epoch的末尾来生成文本。
# 样例5-9 The TextGenerator callback function
class TextGenerator(callbacks.Callback):
def __init__(self, index_to_word, top_k = 10):
self.index_to_word = index_to_word
# 构建一个反向字典映射: 从单词到token
self.word_to_index = {
word: index for index, word in enumerate(index_to_word)
}
# 本函数用 temperature 放缩因子更新概率
def sample_from(self, probs, temperature):
probs = probs ** (1 / temperature)
probs = probs / np.sum(probs)
return np.random.choice(lens(probs), p = probs), probs
def generate(self, start_prompt, max_tokens, temperature):
# start_prompt是一组词串,用来给模型作为输入开启文本生成过程,例如 recipe for
start_tokens = [
self.word_to_index.get(x, 1) for x in start_prompt.split()
]
sample_tokens = None
info = []
# 单词先转换为一个tokens的列表
while len(start_tokens) < max_tokens and sample_tokens != 0:
x = np.array([start_tokens])
# 模型输出每个单词可能为序列下一个词的概率
y = self.model.predict(x)
# 概率传递给sampler以输出下一个单词,参数为 temperature
sample_tokens, probs = self.sample_from(y[0][-1], temperature)
info.append({'prompt': start_prompt, 'word_probs': probs})
# 我们将新单词加入prompt文本,以用于生成过程的下次迭代
start_tokens.append(sample_token)
start_prompt = start_prompt + ' ' + self.index_to_word[sample_token]
print(f'\ngenerated text:\n{start_prompt}\n')
return info
def on_epoch_end(self, epoch, logs=None):
self.generate("recipe for", max_tokens = 100, temperature = 1.0)
让我们具体看看两个不同的temperature值 (图5-9)。

以上两个段落中有一些事情需要注意。首先,两个在风格上都跟原始的菜谱训练集比较像。它们都以一个菜谱名开头,包含语法正确的表述。差别在于,使用 temperature = 1.0 来生成的文本更加冒险,因此不如 temperature=0.2 那样准确。使用 temperature = 1.0 会产生更大的发散性,因为模型才能从有更大离散度的概率分布中采样得到。
为了展示这一点,图5-10展示了对于两个不同temperature值,不同prompts的具有最高概率的头五个tokens。

对于一系列的上下文,模型都有能力生成下一个最可能词的合适分布。例如,即使模型从来未被告知如何对语言进行名词,动词,数字的划分,它却显然具备将单词划分到这些类别的能力,并可以以语法正确的方式来使用这些词。
进一步的,取决于前序标题之不同,模型可以选择合适的动词来开启菜谱指令。对于烤的蔬菜,它选择了 preheat,prepare,heat,put,或者 combine 作为最可能的,而对于冰激凌,它选择了 in,combine,stir,whisk,mix。这表明,模型具备一些上下文理解能力,可以根据成分表推断出菜谱之间的差异。
同时,也请注意,temperature = 0.2 示例对应的概率在首选项上是多么过分强调。这也是小的temperature对应更低的发散性的原因。
尽管我们的基础 LSTM 模型比较善于生成真实感文本,很显然它仍然比较难把握其某些生成单词的语义。它介绍了一些不可能在一起工作的成分 (例如,酸日本土豆,美洲山核桃面包屑,雪糕)!在一些情况下啊,这可能是理想的 — 例如,如果我们希望 LSTM 生成一些有趣的、独一无二类型的单词 — 但是在其他情况下,我们需要模型深入理解 什么样的单词可以聚合到一起,并对于前序文本介绍的思想有更长久的记忆。
在下一章节中,我们会探索一些方式,用以提升基础LSTM网络。在第九章中,我们将一起看一种新的自回归模型, Transformer,这将会把语言模型提升到新的层次。
RNN 拓展
前面章节的模型是一个简单的示例,教会我们如何训练 一个 LSTM 模型来生成给定风格的文本。在这一章节中,我们将进一步探索这个思想的几个拓展。
RNN 堆叠
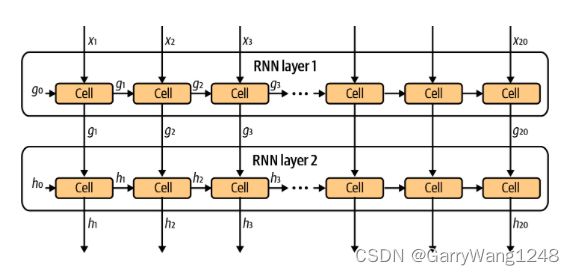
我们使用的网络仅仅包含单一的LSTM层,但是实际上,我们也可以训练堆叠LSTM层,使得我们可以从文本学习更深层次的特征。
为了实现这一点,我们简单在第一个LSTM层之后引入另一个LSTM层。第二个LSTM层可以使用第一个LSTM层的隐状态作为输入数据。这个过程如图5-11所示,总体结构如表5-2所示。
| 层类型 | 输出形状 | 参数数目 |
|---|---|---|
| InputLayer | (None, None) | 0 |
| Embedding | (None, None,100) | 1,000,000 |
| LSTM | (None, None, 128) | 117,248 |
| LSTM | (None, None, 128) | 131,584 |
| Dense | (None, None, 10000) | 1,290,000 |
| 总的参数 | 2,538,832 |
|---|---|
| 训练参数 | 2,538,832 |
| 非训练参数 | 0 |
构建堆叠LSTM的样例代码如下样例5-10所示。
# 样例5-10: 构建堆叠 LSTM
text_in = layers.Input(shape = (None,))
# 可能是原作者的一个笔误 非 embedding 而是 x
x = layers.Embedding(total_words, embedding_size)(text_in)
x = layers.LSTM(n_units, return_sequences = True)(x)
x = layers.LSTM(n_units, return_sequences = True)(x)
probabilities = layers.Dense(total_words, activation = 'softmax')(x)
model = models.Model(text_in, probabilities)
门控循环单元 (Gated Recurrent Units,GRU)
另一种常用的RNN层是 GRU,其与LSTM单元的核心不同列举如下:
- forget 和 input 门被替代为 reset 及 update门。
- 没有 cell 状态 或 output门,只有一个隐状态从cell输出。
隐状态使用四步迭代,如图5-12所示。

- 前一个时间步的隐状态为 h t − 1 h_{t-1} ht−1,当前的词嵌入为 x t x_t xt,这两者拼接起来,用于构建 reset 门。该门是一个dense层,权重矩阵是 W r W_r Wr, 以及一个 sigmoid 激活函数。结果向量 r t r_t rt 其长度与cell的单元个数相等,存储0-1之间的值以决定前一个隐状态 h t − 1 h_{t-1} ht−1有多少部分需要进一步参与cell新的置信度计算。
- reset 门应用于隐状态 h t − 1 h_{t-1} ht−1,并与当前的词嵌入 x t x_t xt。向量喂给一个dense层,该层权重为 W W W, 激活函数为 tanh,来产生一个向量 h ~ t \tilde{h}_t h~t,存储cell的新置信度。其长度与cell中的单元个数相等,存储z的值在-1和1之间。
- 前一个时间步的隐状态为 h t − 1 h_{t-1} ht−1,当前的词嵌入为 x t x_t xt,这两者拼接起来,也应用于构建 update 门。该门是一个dense层,权重矩阵是 W z W_z Wz, 以及一个 sigmoid 激活函数。结果向量 z t z_t zt 其长度与cell的单元个数相等,存储0-1之间的值,以决定新的置信度 h ~ t \tilde{h}_t h~t在大多程度上混合入当前的隐状态 h t − 1 h_{t-1} ht−1。
- 新的置信度 h ~ t \tilde{h}_t h~t,当前的隐状态 h t − 1 h_{t-1} ht−1,按照update门决定的权重 z t z_t zt 进行混合,以产生更新的隐状态 h t h_{t} ht,该状态为cell之输出。
双向Cells
对于预测问题来说,整个的text在推理时对模型均可见,没有任何理由只在前向过程处理处理序列 — 在后向过程中同样可以处理。一个双向层利用这一点来存储两组隐状态: 一组是跟之前一样在前向过程中对序列进行处理的结果。另一个是序列后向处理时生成的。通过这种方式,该层可以学习某个时间步之前和之后的信息。
在Keras中,这是通过对循环层的封装来实现的,如下样例 5-11所示。
# 构建双向GRU层
layer = layers.Bidirectional(layers.GRU(100))
| 隐状态 |
|---|
| 结果层之隐状态是一组长度两倍于封装单元(前向和后向隐状态的连接)units数的向量。因此,在这个例子中,层的隐状态数目是200。 |
截至目前,我们仅仅只在文本数据上应用了自回归模型 (LSTMs) 。在下一章节中,我们将一起看看如何应用自回归模型来生成图像。
PixelCNN
2016年,van den Oord等引入了一个模型,可以通过逐像素的方式来生成图像,它主要基于前序像素来预测下一个像素的likelihood。该模型被称为 PixelCNN, 它可训练用于自回归生成图像。
在 PixelCNN中,我们需要引入两个新的概念 — masked convolutional layers 以及 residual blocks。
| 运行本示例代码 |
|---|
| 本示例代码可以从本书附带代码库的以下目录找到 “notebooks/05_autoregressive/02_pixelcnn/pixelcnn.ipynb”, 代码实现修改自Keras官网上由 AMDoreau实现的杰出 PixelCNN tutorial |
Masked Convolutional Layers
在第二章中,我们已经看到,卷积层可以利用一系列滤波器来抽取图像特征。在特定像素位置,该层的输出是滤波器权重和前层以该像素为中心的小方形区域之乘积的加权和。该方法可以检测边缘和纹理,在更深的层上,也可以检测形状和高层次特征。
尽管卷积层在特征检测上非常有用,他们不能直接以自回归的方式应用,因为在像素并非有序的。它们依赖于一个事实: 所有的像素都同等处理 — 没有哪个像素被视为图像的开头或者结尾。这与上一小节中我们看到的文本数据是相反的,在文本中,tokens是有清晰的顺序的,所以象LSTMs这样的循环模型才可以得到应用。
为了让我们用自回归的方式来应用卷积层,我们必须首先在像素上标定一个顺序,以此来确保滤波器只能看到当前像素之前的那些像素。我们可以通过将卷积层应用于当前图像根据前序像素来预测下一像素来实现一次生成图像的一个像素。
首先,我们需要选择像素的顺序 — 一个明智的建议是按照从左上到右下的顺序来给像素排序,首先在行上移动,然后在列上移动。
然后,我们对卷积滤波器进行掩膜操作,使得该层在每个像素的输出只受限于该像素之前的像素。这是通过使用一个0和1组成的掩膜与滤波器权重相乘实现的,使得目标像素之后的所有值均为0。
实际上,PixelCNN有两种实现方式,如下图5-13所示。
- 类型A,中心像素的值也加以掩膜;
- 类型B,中心像素的值不加掩膜。

初始的掩膜卷积层 (也即,直接应用于输入图像的掩膜卷积层) 不能使用中心像素,因为该像素恰恰是我们想要网络来预测的像素!无论如何,其他后续层中,我们可以使用中心像素,因为这个只是原始输入图像前序像素的信息聚合结果。
在Keras中,MaskedConvLayer的实现方式如下样例 5-12所示:
# 样例5-12 Keras中 MaskedConvLayer的实现
class MaskedConvLayer(layers.Layer):
def __init__(self, mask_type, **kwargs):
super(MaskedConvLayer, self).__init__()
self.mask_type = mask_type
# MaskedConvLayer基于正常的Conv2D层
self.conv = layers.Conv2D(**kwargs)
def build(self, input_shape):
self.conv.build(input_shape)
kernel_shape = self.conv.kernel.get_shape()
#Mask初始化为全0
self.mask = np.zeros(shape = kernel_shape)
# 前序行的像素掩膜为1
self.mask[: kernel_shape[0] // 2, ...] = 1.0
# 同一行前序列的像素掩膜为1
self.mask[kernel_shape[0] // 2, : kernel_shape[1], ...] = 1.0
# 如果掩膜类型为B,则中心像素掩膜为1
if self.mask_type == "B":
self.mask[kernel_shape[0] // 2, kernel_shape[1] // 2, ...] = 1.0
def call(self, inputs):
# 掩膜与滤波器权重相乘
self.conv.kernel.assign(self.conv.kernel * self.mask)
return self.conv(inputs)
注意,这个简化的例子假定图像为灰度(也即,只有一个通道)。如果我们有彩色图像,我们将有三个彩色通道,则我们也可以有三个颜色通道,我们亦可设定一个顺序,例如,红色通道优先蓝色通道,蓝色通道优先绿色通道。
残差模块
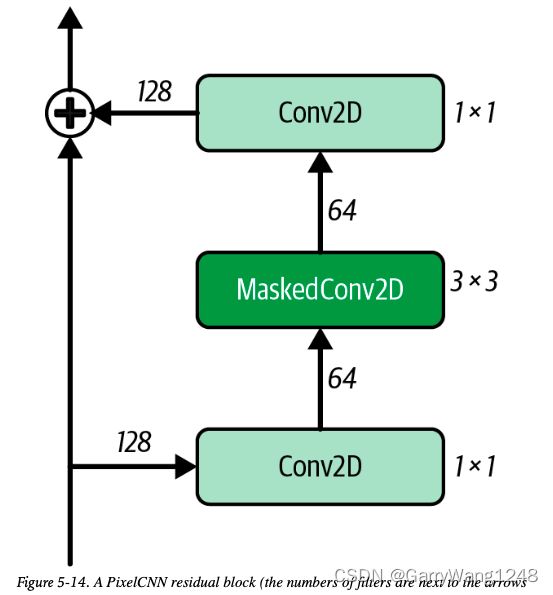
现在,我们看到了如何来对卷积层施加掩膜,我们也可以开始构建自己的 PixelCNN。我们将要用的核心模块是残差模块。
一个残差block是一组层的集合,其block的输出在传递给网络其余部分之前首先加到输入上。换句话说,输入有一个到输出的快速路由,而无需经过一系列中间层 — 这被称为 跳跃连接 (skip connection)。跳跃连接背后的合理性在于,如果最优的变换恰好是保持输入不变,则它可以通过将所有中间层权重简单置0达到。没有跳跃连接的情况下,网络需要找到一个中间层的 identity mapping ,这显然难的多。
我们PixelCNN中的残差block框图如下图5-14所示。
我们可以按照样例5-13所示代码构建 ResidualBlock:
# 样例 5-13: A Residual Block
class ResidualBlock(layers.Layer):
def __init__(self, filters, **kwargs):
super(ResidualBlock, self).__init__(**kwargs)
# 初始的Conv2D层将通道数减半
self.conv1 = layers.Conv2D(
filters = filters // 2, kernel_size = 1, activation = "relu"
)
# kernel size为3的类型B MaskedConv2D 层,只使用5个像素之信息 --- 三个像素在
# 焦点像素之上一行,一个在其左,另一个是焦点像素自己
self.pixel_conv = MaskedConv2D(
mask_type = "B",
filters = filters // 2,
kernel_size = 3,
activation = "relu",
padding = "same",
)
# 最后一个Conv2D层加倍通道数,以匹配输入形状
self.conv2 = layers.Conv2D{
filters = filters, kernel_size = 1, activation = "relu"
}
def call(self, inputs):
x = self.conv1(inputs)
x = self.pixel_conv(x)
x = self.conv2(x)
# 卷积层的输出加到input上去 --- 这是一个跳跃连接
return layers.add([inputs, x])
PixelCNN 训练
在样例5-14中,我们把整个PixelCNNwang放到一起,与原始paper的结构比较接近。在原始的论文里,输出层是一个带softmax激活的 256 滤波器 Conv2D层。换句话说,网络尝试通过预测正确的像素值来重新创造输入,有一点像 自编码器。差别在于, PixelCNN 是受限的,使得前序 pixels 的信息不能流动以影响每个像素的预测,这主要是由于网络的设计方式决定的,使用了MaskedConv2D。
这种方法的一个挑战是,网络没法理解一个像素值(如200) 和另一个像素值(如201)很接近。它必须独立的学习每个像素的输出值,这也就意味着即使对最简单的数据集来说,训练都是很慢的。因此,在我们的视线中,我们简化输入,使得每个像素只能取到四个值中间的一个。通过这种方式,我们可以使用一个4滤波器 Conv2D输出,而非256。
# 样例5-14. PixelCNN 架构
# 模型的输入是灰度图像 16x16x1,输入放缩到 0 到 1之间。
inputs = layers.Input(shape(16,16,1))
# 第一个类型A的MaskedConv2D层,kernel 尺寸为7, 使用了24个像素的信息,焦点像素之上3行以及其左边3个
x = MaskedConv2D(mask_type = "A",
filters = 128,
kernel_size = 7,
activation = "relu",
padding = "same")(inputs)
# 五个ResidualBlock 层序列堆叠
for _ in range(5):
x = ResidualBlock(filters=128)(x)
# 两个类型B,kernel_size=1的MaskedConv2D层作为Dense层,跨越每个像素所有通道
for _ in range(2):
x = MaskedConv2D(mask_type = "B",
filters = 128,
kernel_size = 1,
strides = 1
activation = "relu",
padding = "valid",)(x)
# 最后的Conv2D层降低通道数到4 --- 本例中像素层级数
out = layers.Conv2D(filters=4, kernel_size = 1, strides = 1, activation = "softmax", padding = "valid")(x)
# 构建模型来接受一个图像,并输出一幅同样尺寸的图像
pixel_cnn = models.Model(inputs, out)
adam = optimizers.Adam(learning_rate=0.0005)
pixel_cnn.compile(optimizer=adam, loss = "sparse_categorical_crossentropy")
# 拟合模型 --- input_data 放到到 [0,1], output_data 放缩到 [0,3] (整数)
pixel_cnn.fit(input_data,output_data,batch_size=128,epochs=150)
PixelCNN分析
我们可以在Fashion-MNIST数据集(第三章曾介绍过)上训练 PixelCNN。为了生成新图像,我们需要在给定前序像素基础上,让模型来预测下一个像素,每次预测一个像素。这一过程相比变分自编码器来说非常缓慢!对于一个32x32的灰度图像而言,我们需要使用模型序列推理1024次,而在VAE中,我们仅需要做一次推理。这是如PixelCNN这类自回归模型最大的缺点 — 因为采样过程的序列特性,它们采样起来太慢。
基于这种原因,我们使用16x16的图像,而非32x32,以加速新图像的生成。生成callback类如下例5-15所示。
# 使用PixelCNN生成新的图像
class ImageGenerator(callbacks.Callback):
def __init__(self, num_img):
self.num_img = num_img
def sample_from(self, probs, temperature):
probs = probs ** (1 / temperature)
probs = probs / np.sum(probs)
return np.random.choice(len(probs),p=probs)
def generate(self, temperature):
# 从一批空图像开始
generated_images = np.zeros(shape(self.num_img,)+(pixel_cnn.inputshape)[1:])
batch, rows, cols, channels = generated_image.shape
for row in range(rows):
for col in range(cols):
for channel in range(channels):
# 当前图像rows,cols,channels循环,预测下一个像素值
probs = self.model.predict(generated_images)[:, row, col, :]
# 从预测的分布中采样一个像素值 (在我们的例子中,[0,3]中的一阶)
generated_images[:, row, col, channel] = [self.sample_from(x, temperature) for x in probs]
# 将像素阶转换到 [0,1]范围,并覆盖当前图像像素值,下一次循环准备
generated_images[:, row, col, channel] / = 4
return generated_images
def on_epoch_end(self, epoch, logs = None):
generated_images = self.generate(temperature = 1.0)
display(generated_images, save_to = "./output/generated_img_%03d.png" % (epoch) s)
img_generator_callback = ImageGenerator(num_img=10)
在图5-15中,我们可以看到多个原始训练集中的图像,以及PixelCNN生成的图像。

该模型在重新创造原始图像的整体形状和风格时表现很好。令人相当惊喜的一个点在于,我们可以把图像看做一系列的tokens (像素值),并使用自回归模型(如PixelCNN)来生成真实感样例。
如之前提到,自回归模型的一大缺陷是采样巨慢,这也是为什么在本书中我们只给了一个简单展示的原因。然而,我们将在第十章中看到更复杂的自回归模型也可以应用于图像以生成SOTA结果。在这些例子中,慢的生成速度是获取优质输出的必要代价。
自从原始论文发表以后,PixelCNN的架构和训练过程上提出了各种各样的改进。下一章节介绍了其中的一个改变 — 使用混合分布 — 并展示了如何使用TensorFlow内置函数 利用这一改进来训练 PixelCNN。
混合分布
对于我们之前的样例 ,我们把PixelCNN的输出降低到4个像素层级,以此确保网络无需学习一个256独立像素值的分布,这将减慢训练过程。然而,距离理想情况还远着 — 对于彩色图像,我们不希望画布局限于有限的颜色。
为客服这一问题,我们可以让网络的输出是一个混合分布,而非256个像素值上softmax,这一思想最早由 Salimans 等提出来。混合分布是由两个或更多其他密度分布的简单混合。例如,我们可以有一个由5个logistic分布组成的混合分布,每个logistic分布都有独立参数。混合分布要求离散类别分布以表示选取混何种每个分布的概率。一个例子如图5-16所示。

要从混合分布中采样,我们首先从类别分布中采样,以选取特定的子分布,然后从该子分布中按照惯常的方式采样。通过这种方式,我们可以使用相对较少的参数创造复杂的分布。例如,图5-16的混合分布只需要8个参数 — 两个作为类目分布,以及三个正态分布对应的均值和方差参数。这是与255个参数对比的,它定义了整个像素范围的类目分布。
为方便起见,TensorFlow概率库提供了一个函数使得我们可以用一行代码来构建带混合分布输出的PixelCNN。样例5-16展示了如何使用这个函数来构建PixelCNN。
| 运行本示例代码 |
|---|
| 本示例代码可以通过Jupyter Notebook在本书附带代码库的下列路径打开: “notebooks/05_autoregressive/03_pixelcnn_md/pixelcnn_md.ipynb” |
#样例 5-16 使用TensorFlow函数构建PixelCNN
import tensorflow_probability as tfp
# 将PixelCNN定义为一个分布 --- 也即,输出层是一个由5个logistic分布组成的混合分布
dist = tfp.distributions.PixelCNN(
image_shape = (32, 32, 1),
num_resnet = 1,
num_hierachies = 2,
num_filters = 32,
num_logistic_mix = 5,
dropout_p = .3,
)
# 输入是 32x32x1 的灰度图像
image_input = layers.Input(shape=(32,32,1))
log_prob = dist.log_prob(image_input)
# Model接收 灰度图像作为输入,基于PixelCNN计算的混合分布输出图像的log-likelyhood
model = models.Model(inputs = image_input, outputs = log_prob)
# 损失函数是一个batch的输入图像内计算的 负的平均log-Likelihood
model.add_loss(-tf.reduce_mean(log_prob))
模型的训练方式如过往类似,但这次接受[0,255]范围内的像素值作为输入。输出可以使用Sample 函数从分布中生成,如下样例5-17所示。
dist.sample(10).numpy()
生成的样例图像如下图5-17所示。和我们之前例子的差别在于,所有的像素值范围都利用了。

本章小结
在本章中,我们已经看到自回归模型,如RNN,可以被用于模拟特定写作风格生成文本序列。另外,我们也看到了PixelCNN如何按照逐个像素序列的方式生成图像。
我们探索了两个不同循环层 — LSTM 以及 GRU — 并且看到这些cells是如何堆叠或者 双向来构成复杂的网络结构。我们利用Keras构建了一个LSTM来生成真实感菜单,并且看到了如何操纵采样过程中的温度参数来增加或减少输出的随机性。
我们也看到了使用PixelCNN时,图像是如何以自回归的方式生成。我们利用Keras从零开始构建了一个PixelCNN,涉及了 掩码卷积层 和 残差blocks 来允许信息在网络中流通使得只有前序像素可以用于当前像素的生成。最后,我们讨论了TensorFlow概率库如何提供了独立的,实现了混合分布作为输出层的PixelCNN函数,这允许我们进一步改进学习过程。
在下一章中,我们将探索另一种生成式建模家族,它显式建模了数据生成分布 — normalizing flow models.