【理论篇】是时候彻底弄懂BERT模型了(收藏)
引言
本文对BERT模型的理论进行了一个非常详尽的解释,相信看完本篇文章后,你对BERT模型的理解会上升一个层次。
本文是理论篇,下篇是实战篇。
BERT的基本思想
BERT如此成功的一个原因之一是它是基于上下文(context-based)的嵌入模型,不像其他流行的嵌入模型,比如word2vec,是上下文无关的(context-free)。
首先,让我们理解基于上下文和上下文无关的嵌入模型的区别。考虑下面两个句子:
Sentence A:He got bit by Python.
Sentence B:Python is my favorite programming language.
在句子A中,Python是蟒蛇的意思,而句子B中是一种编程语言。
如果我们得到上面两个句子中单词Python的嵌入向量,那么像word2vec这种嵌入模型就会为这两个句子中的Python赋予相同的嵌入。因为它是上下文无关的。
而BERT是基于上下文的模型,它可以根据上下文来生成单词的嵌入。因此它会给上面两个句子中的Python不同的嵌入向量。
那BERT是如何理解上下文的?
我们考虑句子A。首先BERT会将联系句子中每个单词与其他所有单词来理解每个单词的语境(contextual,或上行下文的)意思。所以为了理解单词Python的语境意思,BERT将单词Python与其他所有单词(包括自己)联系起来。
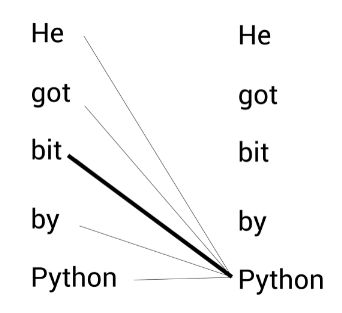
如上图所示,BERT能通过bit一词理解此句中的Python指的是蛇。这样,BERT根据上下文生成动态的嵌入表示。
BERT的原理
从BERT的全称,Bidirectional Encoder Representation from Transformer(来自Transformer的双向编码器表征),可以看出BERT是基于Transformer模型的,但是只是其中的编码器。
我们输入一个句子,Transformer的编码器会输出句子中每个单词的编码表示。那双向的代表什么意思?
由于Transformer编码器天然就是双向的,因为它的输入是完整的句子,也就是说指定某个单词,BERT已经读入了它两个方向上的所有单词。
我们举一个例子来理解BERT是如何从Transformer中得到双向编码表示的。
假设我们有一个句子A:He got bit by Python,现在我们把这个句子输入Transformer并得到了每个单词的上下文表示(嵌入表示)作为输出。
Transformer的编码器通过多头注意力机制理解每个单词的上下文,然后输出每个单词的嵌入向量。
如下图所示,我们输入一个句子到Transformer的编码器,它输出句子中每个单词的上下文表示。我们可以叠加 N N N个编码器。下图中 R He R_{\text{He}} RHe代表单词He的向量表示,每个单词向量表示的大小应当于每个编码器层的大小。
假设编码器层大小为768,那么单词的向量表示大小也就是768。
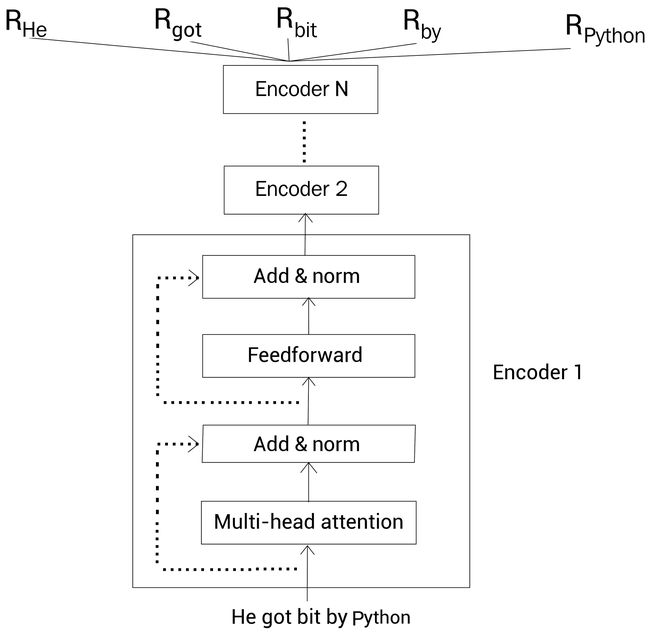
这样,通过BERT,给定一个句子,我们就得到了句子中每个单词的上下文嵌入向量表示。
BERT的配置
BERT的作者提出了两种标准的配置:
- BERT-base
- BERT-large
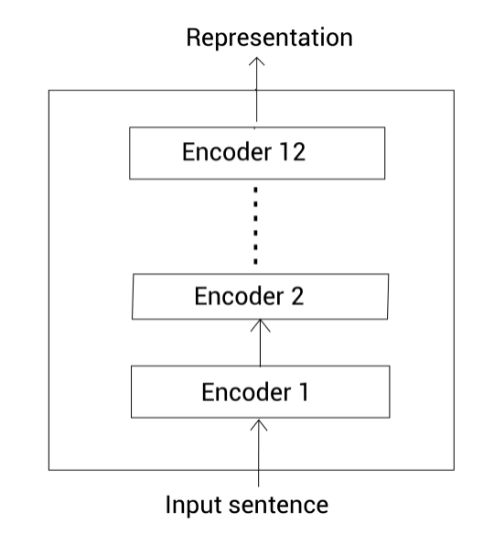
BERT-base
BERT-base包含12个编码器层。所有的编码器使用12个注意头。编码器中的全连接网络包含768个隐藏单元。因此,从该模型中得到的向量大小也就是768。
我们使用以下的记号:
- 编码器层数记为 L L L
- 注意力头数记为 A A A
- 隐藏单元数记为 H H H
因此BERT-base模型, L = 12 , A = 12 , H = 768 L=12,A=12,H=768 L=12,A=12,H=768。该模型的总参数大小为110M。BERT-base模型如下所示:
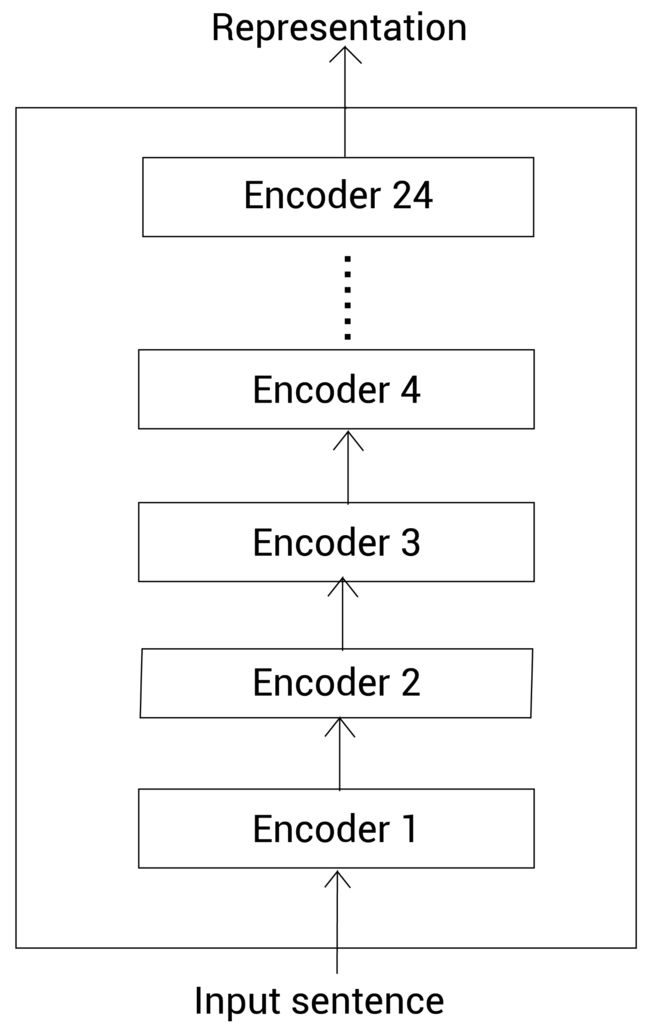
BERT-large
BERT-large包含24个编码器层。所有的编码器使用16个注意头。编码器中的全连接网络包含1024个隐藏单元。因此,从该模型中得到的向量大小也就是1024。
因此BERT-large模型, L = 24 , A = 16 , H = 1024 L=24,A=16,H=1024 L=24,A=16,H=1024。该模型的总参数大小为340M。BERT-large模型如下所示:
BERT的其他配置
除了两种标准的配置,我们也可以使用其他不同的配置。一些更小的配置如下:
- BERT-tiny, L = 2 , H = 128 L=2,H=128 L=2,H=128
- BERT-mini, L = 4 , H = 256 L=4,H=256 L=4,H=256
- BERT-small, L = 4 , H = 512 L=4,H=512 L=4,H=512
- BERT-medium, L = 8 , H = 512 L=8,H=512 L=8,H=512
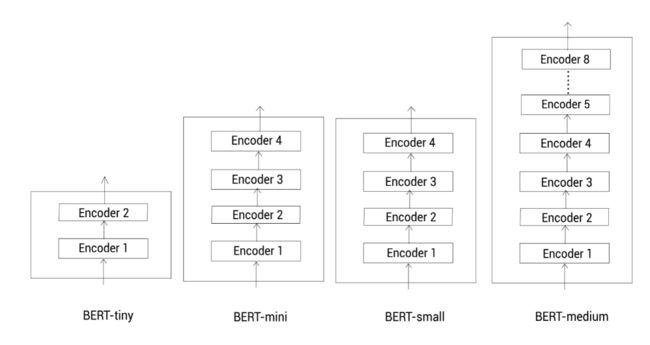
当计算资源有限时,我们可以使用这些更小的BERT模型。当然,标准的BERT模型能得到更准确的结果,同时也被广泛使用。
预训练BERT模型
本节我们会学习如何预训练BERT模型。预训练的意思是,假设我们有一个模型 m m m,首先我们为某种任务使用大规模的语料库训练模型 m m m。现在来了一个新任务,并有一个新模型,我们使用已经训练过的模型(预训练的模型) m m m的参数来初始化新的模型,而不是使用随机参数来初始化新模型。然后根据新任务调整(微调)新模型的参数。这是一种迁移学习。
BERT模型在大规模语料库中通过两个任务来预训练,分别叫屏蔽语言建模和下一句预测。
我们会探讨如何进行预训练的,但在此之前,先看下如何表示输入数据。
输入数据表示
在把数据喂给BERT之前,我们通过下面三个嵌入层将输入转换为嵌入向量:
- 标记嵌入(Token embedding)
- 片段嵌入(Segment embedding)
- 位置嵌入(Position embedding)
标记嵌入
首先,我们有一个标记嵌入层。还是以一个例子来理解。
考虑下面两个句子:
Sentence A: Paris is a beautiful city.
Sentence B: I love Paris.
首先我们对这两个句子分词,得到分词后的标记(单词),然后连到一起,本例中,我们没有进行小写转换:
tokens = [Paris, is, a, beautiful, city, I, love, Paris]
接下来,我们增加一个新的标记,叫作[CLS]标记,到第一个句子前面:
tokens = [ [CLS], Paris, is, a, beautiful, city, I, love, Paris]
然后我们增加一个新的标记,叫作[SEP]标记,到每个句子的结尾:
tokens = [ [CLS], Paris, is, a, beautiful, city, [SEP], I, love, Paris, [SEP]]
注意[CLS]标记只加在第一个句子前面,而[SEP]标记加到每个句子末尾。
[CLS]标记用于分类任务,而[SEP]标记用于表示每个句子的结尾。
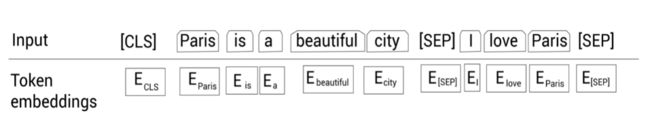
现在,在把所有的标记喂给BERT之前,我们使用一个叫作标记嵌入的嵌入层转换这些标记为嵌入向量。
这些嵌入向量的值会在训练过程中学习。如下图所示,我们有每个标记的嵌入,即, E [CLS] E_{\text{[CLS]}} E[CLS]表示标记[CLS]的嵌入, E Pairs E_{\text{Pairs}} EPairs表示标记Pairs的嵌入,等等:
片段嵌入
其次,我们有一个片段嵌入层。用于区分给定的两个句子。还是考虑上面介绍的例子:
Sentence A: Paris is a beautiful city.
Sentence B: I love Paris.
在对上面两个句子分词之后,我们得到了:
tokens = [ [CLS], Paris, is, a, beautiful, city, [SEP], I, love, Paris, [SEP]]
然后,除了[SEP]标记,我们还要给模型某种标志来区分两个句子。因此,我们将输入的标记喂给片段嵌入层。
片段嵌入层只返回两种嵌入, E A E_A EA或 E B E_B EB,作为输出。即如果输入标记属于句子 A A A,那么该标记会映射到嵌入 E A E_A EA;反之属于句子 B B B的话,则映射到嵌入 E B E_B EB。
如下图所示:

那如果我们只有一个句子时,片段嵌入是如何工作的呢?很简单,假设我们只有一个句子*Paris is a beautiful city*,那么所有的标记只会映射到同一个嵌入 E A E_A EA:

位置嵌入
接下来,我们有一个位置嵌入层。我们知道Transformer为了得到句子中单词的顺序信息,使用了位置编码。
我们也知道BERT本质上就是Transformer的编码器,所以我们需要提供句子中标记的位置信息,然后才能输入到BERT。位置嵌入层就是干这个工作的。

如图所示, E 0 E_0 E0表示标记[CLS]的位置嵌入, E 1 E_1 E1表示标记Paris的位置嵌入,以此类推。
最终的表示
现在我们看一下最终的输入表示是怎样的。如下图所示,首先我们将给定的输入序列分词为标记列表,然后喂给标记嵌入层,片段嵌入层和位置嵌入层,得到对应的嵌入表示。然后,累加所有的嵌入表示作为BERT的输入表示。
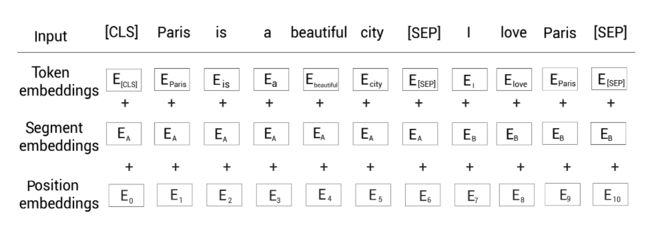
比如标记[CLS]的输入表示为标记嵌入 E CLS E_{\text{CLS}} ECLS+片段嵌入 E A E_A EA+位置嵌入 E 0 E_0 E0。
下面我们来看一下BERT使用的叫作WordPiece的分词器。
WordPiece分词器
WordPiece分词器基于子词(subword)分词模式。还是以一个例子来理解该分词器是如何工作的。考虑下面的句子:
"Let us start pretraining the model."
现在,如果我们使用WordPiece分词器来分词,我们会得到如下所示的标记:
tokens = [let, us, start, pre, ##train, ##ing, the, model]
我们可以观察到,在使用WordPiece分词器对句子进行分词时,单词pretraining被拆分为以下子词——pre、##train、##ing。
这是什么意思?
当使用WordPiece分词器分词,首先我们检测单词在词表(vocabulary)中是否存在,若存在,则作为标记;否则,我们将该单词拆分为一些子词,然后我们检查这些子词是否存在于词表。
如果某个子词存在于词表,那么将它作为一个标记;否则继续拆分子词,然后检查更小的子词是否存在于词表中。
这样,我们不断地拆分子词,并用词表检查子词,直到碰到单个字符为止。这种做法可以有效地处理未登录词(out-of-vocabulary,OOV)。
BERT的词表有30K个标记,如果某个单词属于这30K个标记中一个,那我们将该单词视为一个标记;否则,我们拆分单词为子词,然后检查子词是否属于这30K个标记之一。
在我们的例子中,单词pretraining不在BERT的词表中。一次你,我们将它拆分为子词pre,##train和##ing。前面的#表示这个单词为一个子词,并且它前面有其他单词。现在我们检查子词##train和##ing是否出现在词表中。因为它们正好在词表中,所以我们不需要继续拆分。
通过使用一个WordPiece分词器,我们得到了下面的标记:
tokens = [let, us, start, pre, ##train, ##ing, the, model]
接着增加[CLS]到句子的开始和[SEP]到句子的结尾:
tokens = [ [CLS], let, us, start, pre, ##train, ##ing, the model, [SEP] ]
更详细的关于WordPiece分词器如何工作的讨论留到本文的结尾处。
现在我们学习如何预训练BERT模型。
预训练策略
BERT模型的预训练基于两个任务:
- 屏蔽语言建模
- 下一句预测
在深入屏蔽语言建模之间,我们先来理解一下语言建模任务的原理。
语言建模
在语言建模任务中,我们训练模型给定一系列单词来预测下一个单词。可以把语言建模分为两类:
- 自回归语言建模
- 自编码语言建模
自回归语言建模
我们还可以将自回归语言建模归类为:
- 前向(左到右)预测
- 反向(右到左)预测
老规矩,通过实例来理解。考虑文本Paris is a beautiful city. I love Paris。假设我们移除了单词city然后替换为空白符__:
Paris is a beautiful __. I love Paris
现在,我们的模型需要预测空白符实际的单词。如果使用前向预测,那么我们的模型以从左到右的顺序阅读序列中的单词,直到空白符:
Paris is a beautiful __.
如果我们使用反向预测,那么我们的模型以从右到左的顺序阅读序列中的单词,直到空白符:
__. I love Paris
因此,自回归模型天然就是单向的,意味着它们只会以一个方向阅读输入序列。
自编码语言建模
自编码语言建模任务同时利用了前向(左到右)和反向(右到左)预测的优势。即,它们在预测时同时读入两个方向的序列。因此,我们可以说自编码语言模型天生就是双向的。
为了预测空白符,自编码语言模型同时从两个方向阅读序列,如下所示:
Paris is a beautiful __. I love Paris
因此双向的模型能获得更好的结果。
屏蔽语言建模
BERT是一个自编码语言模型,即预测时同时从两个方向阅读序列。在一个屏蔽语言建模任务中,对于给定的输入序列,我们随机屏蔽15%的单词,然后训练模型去预测这些屏蔽的单词。为了做到这一点,我们的模型以两个方向读入序列然后尝试预测屏蔽的单词。
举个例子。我们考虑上面见到的句子:Paris is a beautiful city', and 'I love Paris。首先,我们将句子分词,得到一些标记:
tokens = [Paris, is, a beautiful, city, I, love, Paris]
接着还是增加[CLS]标记到第一个句子的开头,增加[SEP]标记到每个句子的结尾:
tokens = [ [CLS], Paris, is, a beautiful, city, [SEP], I, love, Paris, [SEP] ]
接下来,我们在上面的标记列表中随机地屏蔽15%的标记(单词)。假设我们屏蔽单词city,然后用[MASK]标记替换这个单词,结果为:
tokens = [ [CLS], Paris, is, a beautiful, [MASK], [SEP], I, love, Paris, [SEP] ]
现在训练我们的BERT模型去预测被屏蔽的标记。
这里有一个小问题。 以这种方式屏蔽标记会在预训练和微调之间产生差异。即,我们训练BERT通过预测[MASK]标记。训练完之后,我们可以为下游任务微调预训练的BERT模型,比如情感分析任务。但在微调期间,我们的输入不会有任何的[MASK]标记。因此,它会导致 BERT 的预训练方式与微调方式不匹配。
为了解决这个问题,我们应用80-10-10%规则。我们知道我们会随机地屏蔽句子中15%的标记。现在,对于这些15%的标记,我们做下面的事情:
-
80%的概率,我们用
[MASK]标记替换该标记。因此,80%的情况下,输入会变成如下:tokens = [ [CLS], Paris, is, a beautiful, [MASK], [SEP], I, love, Paris, [SEP] ] -
10%的概率,我们用一个随机标记(单词)替换该标记。所以,10%的情况下,输入变为:
tokens = [ [CLS], Paris, is, a beautiful, love, [SEP], I, love, Paris, [SEP] ] -
剩下10%的概率,我们不做任何替换。因此,此时输入不变:
tokens = [ [CLS], Paris, is, a beautiful, city, [SEP], I, love, Paris, [SEP] ]
在分词和屏蔽之后,我们分别将这些输入标记喂给标记嵌入、片段嵌入和位置嵌入层,然后得到输入嵌入。
然后,我们将输入嵌入喂给BERT。如下所示,BERT接收输入然后返回每个标记的嵌入表示作为输出。 R [CLS] R_{\text{[CLS]}} R[CLS]代表输入标记[CLS]的嵌入表示, R Paris R_{\text{Paris}} RParis代表标记Paris的嵌入表示,以此类推。
在本例中,我们使用BERT-base,即有12个编码器层,12个注意力头和768个隐藏单元。

我们得到了每个标记的嵌入表示 R R R。现在, 我们如何用这些表示预测屏蔽的标记?
为了预测屏蔽的标记,我们将BERT返回的屏蔽的单词表示 R [MASK] R_{\text{[MASK]}} R[MASK]喂给一个带有softmax激活函数的前馈神经网络。然后该网络输出词表中每个单词属于该屏蔽的单词的概率。如下图所示。这里输入嵌入层没有画出来以减小版面:
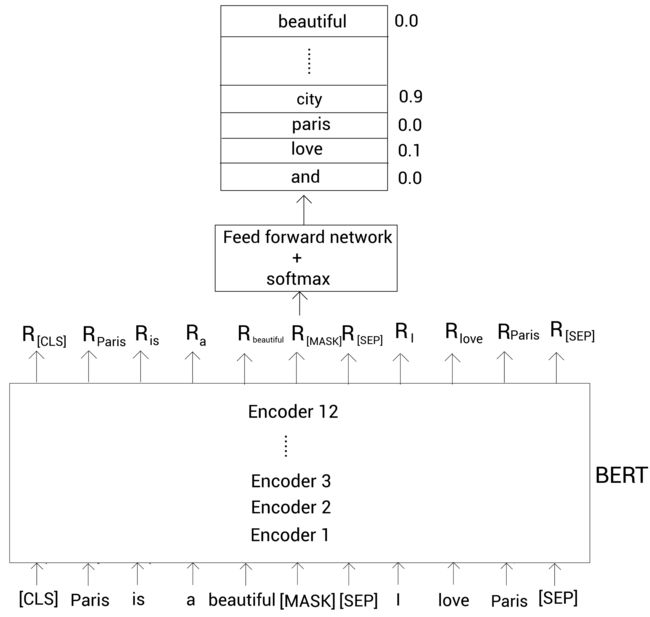
从上图可以看到,单词city属于屏蔽单词的概率最高。因此,我们的模型会预测屏蔽单词为city。
注意在初始的迭代中,我们的模型不会输出正确的概率,因为前馈网络和BERT编码器层的参数还没有被优化。然而,通过一系列的迭代之后,我们更新了前馈网络和BERT编码器层的参数,然后学到了优化的参数。
屏蔽语言建模也被称为完形填空(cloze)任务。我们已经知道了如何使用屏蔽语言建模任务训练BERT模型。而屏蔽输入标记时,我们也可以使用一个有点不同的方法,叫作全词屏蔽(whole word masking,WWM)。
全词屏蔽
同样,我们以实例来理解全词屏蔽是如何工作的。考虑句子Let us start pretraining the model。记住BERT使用WordPiece分词器,所以,在使用该分词器之后,我们得到下面的标记:
tokens = [let, us, start, pre, ##train, ##ing, the, model]
然后增加[CLS]和[SEP]标记:
tokens = [[CLS], let, us, start, pre, ##train, ##ing, the, model, [SEP]]
接着随机屏蔽15%的单词。假设屏蔽后的结果为:
tokens = [[CLS], [MASK], us, start, pre, [MASK], ##ing, the, model, [SEP]]
从上面可知,我们屏蔽了单词let和##train。其中##train是单词pretraining的一个子词。在全词屏蔽模型中,如果子词被屏蔽了,然后我们屏蔽与该子词对应单词的所有子词。因此,我们的标记变成了下面的样子:
tokens = [[CLS], [MASK], us, start, [MASK], [MASK], [MASK], the, model, [SEP]]
注意我们也需要保持我们的屏蔽概率为15%。所以,当屏蔽子词对应的所有单词后,如果超过了15%的屏蔽率,我们可以取消屏蔽其他单词。如下所示,我们取消屏蔽单词let来控制屏蔽率:
tokens = [[CLS], let, us, start, [MASK], [MASK], [MASK], the, model, [SEP]]
这样,我们使用全词屏蔽来屏蔽标记。
在下小节中,我们会训练BERT另一个有趣的任务。
下一句预测
下一句预测(next sentence prediction,NSP)是另一个用于训练BERT模型的任务。NSP是二分类任务,在此任务中,我们输入两个句子两个BERT,然后BERT需要判断第二个句子是否为第一个句子的下一句。
考虑下面两个句子:
Sentence A: She cooked pasta.
Sentence B: It was delicious.
这两个句子中, B B B就是 A A A的下一句,所以我们标记这对句子为isNext。
然后看另外两个句子:
Sentence A: Turn the radio on.
Sentence B: She bought a new hat.
显然 B B B不是 A A A的下一句,所以我们标记这个句子对为notNext。
在NSP任务中,我们模型的目标是预测句子对属于isNext还是notNext。
那么NSP任务有什么用?通过运行NSP任务,我们的模型可以理解两个句子之间的关系,这会有利于很多下游任务,像问答和文本生成。
那么如何获取NSP任务的数据集?我们可以从任何单语语料库中生成数据集。假设我们有一些文档。对于isNext类别,我们从某篇文档中抽取任意相连的句子,然后将它们标记为isNext;对于notNext类别,我们从一篇文档中取一个句子,然后另一个句子随机的从所有文档中取,标记为notNext。同时我们需要保证数据集中50%的句子对属于isNext,剩下50%的句子对属于notNext。
假设我们这样得到如下所示的数据集:

我们以上面数据集中第一个句子对为例。首先,我们进行分词,得到:
tokens = [She, cooked, pasta, It, was, delicious]
接下来,增加[CLS]和SEP标记:
tokens = [[CLS], She, cooked, pasta, [SEP], It, was, delicious, [SEP]]
然后我们把这个输入标记喂给标记嵌入、片段嵌入和位置嵌入层,得到输入嵌入。
接着把输入嵌入喂给BERT获得每个标记的嵌入表示。如下图所示, R [CLS] R_{\text{[CLS]}} R[CLS]代表标记[CLS]的嵌入表示。

为了进行分类,我们简单地将[CLS]标记的嵌入表示喂给一个带有softmax函数的全连接网络,该网络会返回我们输入的句子对属于isNext和notNext的概率。
因为[CLS]标记保存了所有标记的聚合表示。也就得到了整个输入的信息。所以我们可以直接拿该标记对应的嵌入表示来进行预测。如下图所示:

上面我们可以看到,最终的全连接网络输出isNext的概率较高。
预训练过程
原始论文中的BERT是通过Toronto BookCorpus和维基百科数据集预训练的。我们已经知道了BERT通过屏蔽语言建模和NSP任务进行预训练。那么我们如何为这两个任务准备数据集呢?
首先,我们从语料库中采样两个句子(或文本片段)。假设我们采样了句子 A A A和 B B B,这两个句子的所有分词后的标记总数应该小于等于512。在采样两个句子(或文本片段)时u,50%的情况下,我们采样点句子 B B B为句子 A A A的下一句;另外50%的情况下,我们采样的句子 B B B不是句子 A A A的下一句。
假设我们采样了下面两个句子:
Sentence A: We enjoyed the game
Sentence B: Turn the radio on
我们现在应该已经很熟悉了,首先通过WordPiece分词器分词,然后增加[CLS]和[SEP]标记:
tokens = [[CLS], we, enjoyed, the, game, [SEP], turn, the radio, on, [SEP]]
接下来,我们根据80-10-10%规则随机屏蔽15%的标记。假设我们屏蔽了标记game:
tokens = [[CLS], we, enjoyed, the, [MASK], [SEP], turn, the radio, on, [SEP]]
现在,我们将这些标记输入给BERT,然后训练BERT去预测屏蔽的标记,同时预测句子 B B B是否为句子 A A A的下一句。也就是说,我们同时训练屏蔽语言建模和NSP任务。
BERT以256个序列的批大小训练1,000,000步。我们使用Adam优化器,参数为 l r = 1 e − 4 , β 1 = 0.9 , β 2 = 0.999 lr=1e-4,\beta_1=0.9,\beta_2=0.999 lr=1e−4,β1=0.9,β2=0.999,然后热身(warm-up)步数设为10,000。
什么是热身步?
在训练的初始阶段,我们可以设置一个很大的学习率,但是我们应该在后面的迭代中设置一个较小的学习率。因为在初始的迭代时,我们远没有收敛,所以设置较大的学习率带来更大的步长是可以的,但在后面的迭代中,我们已经快要收敛了,如果学习率(导致步长)较大可能会错过收敛位置(极小值)。在初始迭代期设置较大的学习率而在之后的迭代期减少学习率的做法被称为学习率scheduling。
热身步就是用于学习率scheduling的。假设我们的学习率是1e-4,然后热身步为10000个迭代。意味着我们在初始的10000个迭代中,将学习率从0增大到1e-4。在10000个迭代后,我们线性地减少学习率因为我们接近收敛位置了。
我们同样对所有的网络层使用0.1的dropout比率。BERT使用的激活函数叫作GELU(Gaussian Error Linear Unit)。
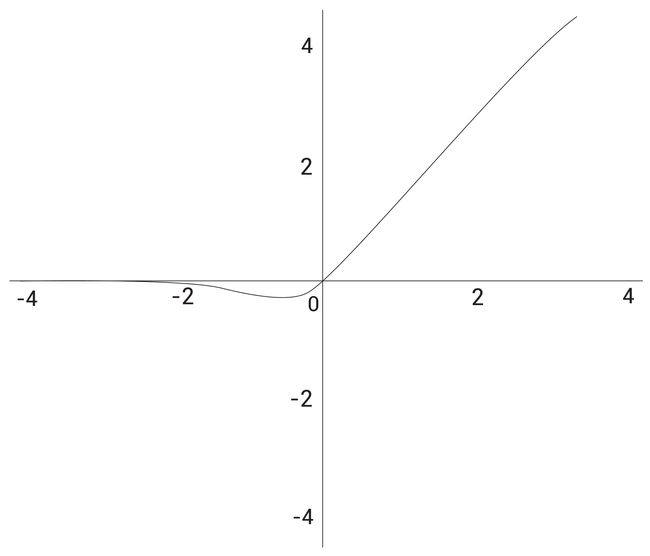
GELU函数为:
GELU ( x ) = x Φ ( x ) \text{GELU}(x) = x \Phi(x) GELU(x)=xΦ(x)
这里 Φ ( x ) \Phi(x) Φ(x)是标准的高斯累积分布函数(Gaussian cumulative distribution function),
GELU的近似计算数学公式为:
GELU ( x ) = 0.5 x ( 1 + t a n h [ 2 / π ( x + 0.044715 x 3 ) ] ) \text{GELU}(x) = 0.5x(1 + tanh[\sqrt{2/π}(x + 0.044715x^3)]) GELU(x)=0.5x(1+tanh[2/π(x+0.044715x3)])
它的函数图像如下:
这样,我们可以使用屏蔽语言建模和NSP任务预训练BERT模型。下面我们学习有趣的子词Tokenization算法。
子词Tokenization算法
子词Tokenization(可以理解为分词)在很多SOTA NLP模型上得到广泛的使用,包括BERT和GPT-3。它能很有效的处理未登陆词。
本节我们会探讨子词Tokenization的工作细节。在深入之前,我们先看一下单词级的Tokenization。
假设我们有一个训练数据集。我们从这个训练数据集中构建一个词表。为了构建该词表,我们将数据集中的文本拆分成单词,然后把唯一的单词加入到词表。通常,词表包含很多单词(标记),为了举例的简单,假设我们的词表只包含下面的单词:
vocabulary = [game, the, I, played, walked, enjoy]
现在我们有了词表,然后我们基于该词表来对输入进行分词。考虑输入句子I played the game。在英文中,我们只要通过空格就得得到句子中所有的单词。所以我们有[I, play, the, game]。现在,我们检查是否所有的单词都在词表中。恰好这些单词都在词表中,从给定句子中得到的最终标记就为:
tokens = [I, played, the, game]
接着我们考虑另一个句子:I enjoyed the game。首先还是根据空格分词,得到 [I, enjoyed, the, game]。接着,检查是否所有的单词出现在词表中。我们可以看到,除了单词enjoyed,其他的单词都在词表中,因此我把enjoyed替换为未知标记
tokens = [ I, , the, game]
我们也可以看到,尽管我们词表中有单词enjoy,但是由于没有完全一样的单词enjoyed,它就变成未知词了。可能是因为我们的词表太小了,然而哪怕有一个超大的词表,先不说这样的词表会带来内存和性能方面的压力,仍然有可能无法处理没有出现过的词(词表中也没有出现过)。
那么是否有更好的方式来解决这个问题呢?
这时就需要子词Tokenization技术了。我们以上面的例子来看子词Tokenization的工作原理,我们的词表包含下面的单词:
vocabulary = [game, the, I, played, walked, enjoy]
在子词Tokenization中,我们将单词拆分为更小的子词。假设我们拆分单词played为子词[play, ed];拆分单词walked为子词[walk, ed]。在拆分子词后,我们将这些子词加到词表中。由于词表中不包含重复单词,所以我们的词表变成了:
vocabulary = [game, the, I, play, walk, ed, enjoy]
让我们考虑之前看到的句子:I enjoyed the game。同样我们先根据空格将句子拆分单词,我们有[ I, enjoyed, the, game]。接着我们检测是否所有的单词都在词表中。我们可以看到除了单词enjoyed,其他所有单词都在词表中。此时,我们不会将该单词替换为未知词,而是将它继续拆分为子词:[enjoy, ed]。然后我们继续检查这些子词是否出现在词表中,刚好都出现在词表中。所以我们得到了下面的标记:
tokens = [ I, enjoy, ##ed, the, game]
我们可以看到ed前面有两个#。这代表##ed是一个子词,而且它前面有另一个单词。我们不会为单词拆分后的第一个子词增加##符号,这就是为什么子词enjoy前面没有#。这样子词Tokenization处理了未知词,也就是没有出现在词表中的单词。
现在问题是,我们知道我们将单词played和walked拆分成子词,然后增加它们的子词到词表中。但是为什么我们只拆分这些单词呢?为什么不是词表中的其他单词?我们如何决定哪些单词要拆分,哪些不要?这就是子词Tokenization算法起作用的地方。
我们接下来学习几个常见的子词Tokenization算法:
- 字节对编码(Byte pair encoding,BPE)
- 字节级字节对编码(Byte-level byte pair encoding,BBPE)
- WordPiece
字节对编码
我们仍然通过一个例子来理解BPE是如何工作的。假设我们有一个数据集。首先,我们从该数据集中抽取每个单词同时统计它们出现的次数。假设我们抽取的结果为: (cost, 2), (best, 2), (menu, 1), (men, 1),* and *(camel, 1)。
现在,我们将这些单词拆分成字符变成一个字符序列。下面的表格显示这些字符序列以及它们对应的单词次数:
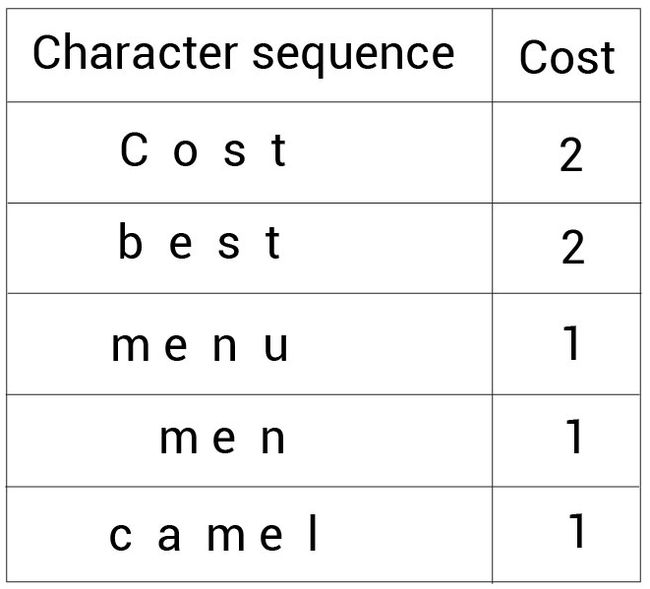
接下来,我们先定义词表大小。假设我们定义的词表大小为14。意味着我们会创建一个包含14个标记的词表。现在,我们就一起来看一下如何使用BPE创建词表。
首先,我们将字符序列中所有字符不重复地添加到词表中,如下所示:
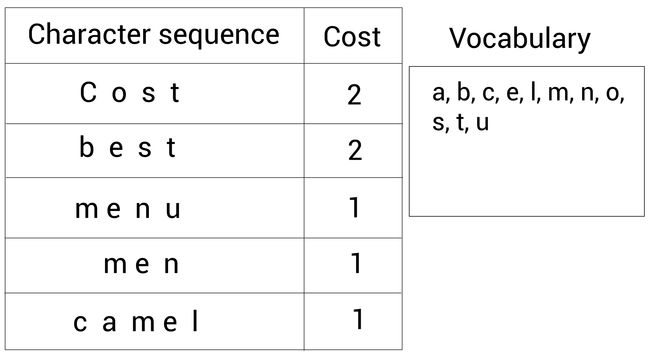
很容易计算我们现在的词表(右边的Vocabulary)大小为 11 11 11。下面看看如何增加新标记到词表中。
首先,我们找出出现次数最多的相邻的字符对。然后我们合并这个字符对并加入到词表中。我们不断重复该步骤知道达到词表大小。让我们来看下具体细节。
看下面的字符序列,我们能观察到出现最多的字符对是s和t,因为s和t相邻地出现了 4 4 4次:

所以,我们合并这两个字符s和t成st,并将st加入到词表:

接着,我们重复这一步骤。我们继续寻找出现最多的相邻字符对。我们又发现了现在最频繁的字符对是m和e,它们出现了 3 3 3次:
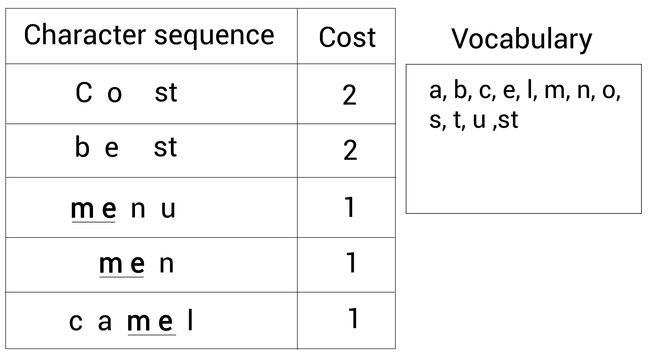
所以我们合并字符m和e为me并加入词表:

再一次,我们继续检查出现最多的字符对。我们此时发现最常见的字符对是me和n,它们一起出现了 2 2 2次:
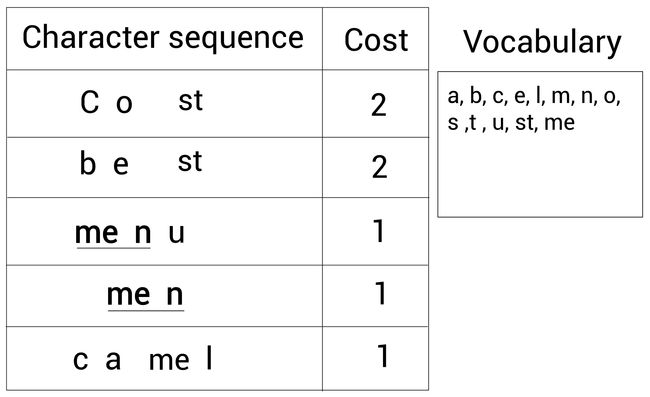
所以,我们继续合并me和n为men,然后加入词表:
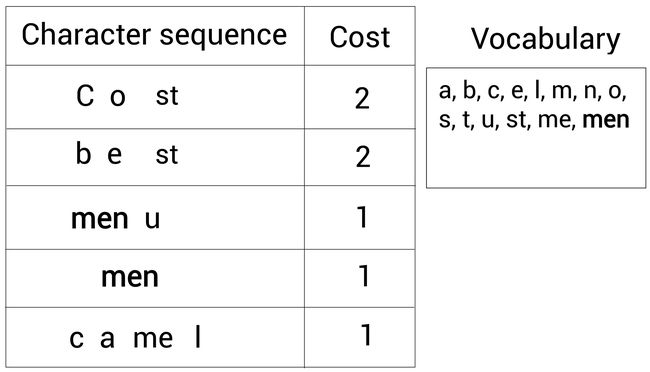
这样,我们不断重复直到词表大小达到预定义的值。从上图可以看出,我们的词表大小已经有 14 14 14了。
因此,在本例中,我们创建了大小为 14 14 14的词表,这样BPE算法就停止了。
我们就得到了包含 14 14 14个标记的词表:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me,men}
BPE算法的步骤总结如下:
- 从给定的数据集中抽取单词以及相应的频次
- 定义词表大小
- 将单词拆分为字符序列
- 将所有字符序列中的字符不重复地添加到词表中
- 选择并合并频次最高的相邻字符对
- 重复步骤5直到满足词表大小
我们已经知道了如何使用BPE创建词表。那如何使用这个词表呢?我们使用该词表来对输入序列进行分词。我们下面通过一些例子来理解词表的使用。
使用BPE分词
我们上小节创建的词表如下:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me,men}
现在,我们来看如何使用这个词表。假设我们的输入文本只包含一个单词:mean。
那么我们先检查这个单词是否出现在词表中,显然没有。所以我们将该单词拆分为两个子词[me, an]。接着,我们检查这些子词是否出现在词表中。发现只有me出现在词表中,an则没有。
因此,我们继续拆分子词an,所以现在子词包含[me, a, n]。现在我们检查字符a和n是否出现在词表中。答案为是,因此我们最终得到的标记如下:
tokens = [me,a,n]
下面我们考虑另一个单词star。首先我们发现该单词不在词表中。所以我们拆分为子词[st, ar]。现在检查子词是否在词表中。我们可以看到子词st在词表中,而ar不在。因此我们继续拆分子词ar,所以现在子词包括[st, a, r]。现在我们检查字符a和r是否在词表中。显然a在而r
不在。因为我r只是一个字符,所以我们无法继续拆分,因此只能将它替换为
tokens = [st,a,]
我们知道BPE可以很好的处理稀有词,但是现在我们有一个r没有出现在词表中。如果我们用一个较大的语料库创建词表,我们的词表肯定会包含所有的字符。
下面来看最后一个例子:men。我们检查该单词是否在词表中,幸运地是它就在词表中。因为得到的标记为:
tokens = [men]
这样,我们就使用BPE对输入序列进行分词。下面我们来理解另一个分词方法。
字节级字节对编码
这个名字可能有点奇怪,因为我们上面介绍的算法虽然叫“字节”对编码,但实际上还是字符级别的。所以就有了字节级的字节对编码存在的意义。
BBPE与BPE类似,我们使用一个例子来理解BBPE。
假设我们的输入文本仅包含一个单词best。我们知道在BPE中,我们可以将该单词拆分为字符序列,就可以得到:
Character sequence: b e s t
然而在BBPE中,我们不是将单词转换为字符序列,而是转换为字节序列。我们该单词转换为如下的字节序列:
Byte sequence: 62 65 73 74
这样,每个Unicode字符都转换成一个字节。单个字符可以包含1到4个字节。
我们再看一个例子。假设输入是一个中文词汇:你好。现在,我们将它转换为字节级序列,得到:
Byte sequence: e4 bd a0 e5 a5 bd
通过这种方式,我们先将文本转换为字节级序列,然后应用BPE算法根据字节级符号对构建词表就可以了。
但是使用字节级BPE而不是字符级BPE的目的是什么?好吧,字节级BPE对于多语言情况下非常有用。它能非常有效地处理未登录词,同时处理多语言词表也非常出色。
WordPiece
WordPiece类似BPE,只有一个细微的差别。我们知道BPE,给定一个数据集,首先抽取单词和频次。其次拆分单词为字符序列。接着合并高频字符对直到达到词表大小。
WordPiece做的也是同样的事情,但有一个区别在于我们并不是基于频次合并字符对。而是根据似然(概率)合并字符对。所以我们合并在给定训练集上训练的语言模型中具有最高概率的字符对。
我们还是通过一个例子理解这一点吧。
考虑我们再BPE中的例子:
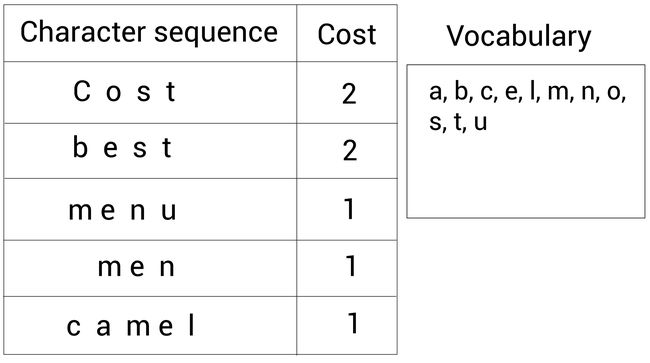
我们知道在BPE中,合并的是最高频次的字符对。在BPE中,我们会合并s和t,因为它们一起出现的频次最高。但是现在,在WordPiece中,我们会根据似然来合并单词。
首先,我们检查语言模型(通过给定数据集训练的语言模型)输出的每个字符对出现的概率。然后我们选取概率最高的那一对。字符对s和t出现的概率可以计算为:
p ( s t ) p ( s ) p ( t ) \frac{p(st)}{p(s)p(t)} p(s)p(t)p(st)
如果它们的概率是最高的,那么我们就合并它们并加入到词表中。这样,我们就计算了每个字符对出现的概率并合并概率最高的那一对到词表中。
WordPiece算法的步骤可以总结如下:
- 从给定的数据集抽取单词和对应你的频次
- 定义词表大小
- 拆分词表为字符序列
- 将所有字符序列中的字符不重复地添加到词表中
- 基于给定的数据集(训练集)构建语言模型
- 合并语言模型输出概率最大的字符对,并加入到词表中
- 重复第6步直到满足词表大小
在构建词表后,我们就可以用它来分词了。假设我们根据WordPiece构建的词表如下:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me}
现在假设我们输入文本只包含一个单词:stem。该单词没有出现在词表中。所以我们拆分为子词[st, ##em],接下来我们检查是否这些子词出现在词表中。我们发现子词st在词表中,而em不在。
因此,我们继续拆分子词em,现在我们得到的子词为:[st, ##e, ##m]。现在我们继续检查是否字符e和m出现在词表中。因为它们都在词表中,所以我们最终得到的标记为:
tokens = [st, ##e, ##m]
这样我们就使用WordPiece子词Tokenization算法创建了一个词表,并用该词表进行分词。
参考
Getting Started with Google BERT