Spark Streaming流式数据处理
目录
- 一、Spark Streaming 简介
- 二、简单的例子
- 三、Spark Streaming相关核心类
-
- 3.1 StreamingContext
- 3.2 离散流 Discretized Streams(DStreams)
- 3.3 Input DStreams 与 Receivers(接收器)
-
- 3.3.1 基础数据源
-
- a.Socket(TCP Socket)
- b.File Streams(文件流)
- c.RDDs 队列
- 3.3.2 高级数据源
-
- a.Flume 数据源
- b.Kafka 数据源
- 3.3.3 Streams based on Custom Receivers
- 四、DStream API*
- 五、Spark Streaming优化
一、Spark Streaming 简介
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从Kafka, Kinesis, or TCP sockets等许多来源摄入,并且可以使用与像高级别功能表达复杂的算法来处理map,reduce,join和window。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。还可以在数据流上应用Spark的MLlib 机器学习和 GraphX 图形处理算法。

在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批处理,然后由Spark引擎进行处理,以生成批处理的最终结果流。
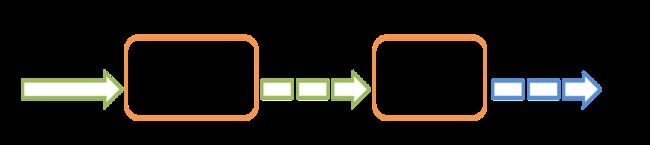
Spark Streaming提供了称为离散化流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka和Kinesis等来源的输入数据流来创建DStream,也可以通过对其他DStream应用高级操作来创建DStream。在内部,DStream表示为RDD序列 。
二、简单的例子
- 新建一份maven工程,导入依赖:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark_version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark_version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark_version}</version>
</dependency>
- 基于Spark Streaming的wordcount
package cn.wsj.mysparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NcWordCount {
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getName)
.setMaster("local[4]")
//创建StreamingContext对象与集群进行交互,Seconds(5)表示批处理间隔
val ssc: StreamingContext = new StreamingContext(conf, Seconds(5))
//创建一个将连接到主机名xxx端口xxxx的DStream,例如localhost:9999
val line: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.237.160", 1234)
//计算每批数据中的每个单词并打印
line.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_).print()
//启动Spark Streaming
ssc.start()
//等待计算终止
ssc.awaitTermination()
}
}
- 这里监听了一个外部的端口,可以再linux虚拟机上进行如下操作:
# 安装网络工具netcat
ymu -y install nc
# 打开一个socket ,这里我开启的是1234端口
nc -lk 1234
在spark程序启动后,可以观察到时间戳的变化,此时来到socket端口,不断回车输入字母
e.g.
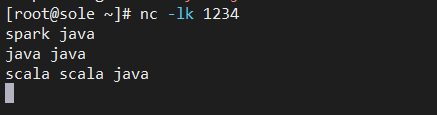
在spark客户端可以看到如下变化,每段时间都会显示每个单词的词频统计结果:
"C:\Program Files\Java\jdk1.8.0_231\bin\java.exe"
-------------------------------------------
Time: 1617191345000 ms
-------------------------------------------
-------------------------------------------
Time: 1617191350000 ms
-------------------------------------------
(spark,1)
(java,1)
-------------------------------------------
Time: 1617191355000 ms
-------------------------------------------
(java,2)
-------------------------------------------
Time: 1617191360000 ms
-------------------------------------------
(scala,2)
(java,1)
Process finished with exit code -1
三、Spark Streaming相关核心类
3.1 StreamingContext
要初始化Spark Streaming程序,必须创建一个StreamingContext对象,该对象是所有Spark Streaming功能的主要入口点。
- 通过SparkConf创建
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(this.getClass.getName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
- 通过SparkContext创建,通常是使用已有的 SparkContext 来创建
StreamingContext
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1))
定义context后,必须执行以下操作:
1.通过创建输入DStream定义输入源;
2.通过将转换和输出操作应用于DStream来定义流计算;
3.开始接收数据并使用进行处理streamingContext.start();
4.等待使用停止处理(手动或由于任何错误)streamingContext.awaitTermination();
5.可以使用手动停止处理streamingContext.stop()。
创建 StreamingContext需要注意下面几个问题:
1.一个 JVM 只能有一个 SparkContext 启动。意味着应用程序中不应该出现
两个 SparkContext;
2.一个 JVM 同时只能有一个 StreamingContext 启动。但一个 SparkContext可以创建多个 StreamingContext,只要上一个 StreamingContext 先用 stop(false)停止,再创建下一个即可;默认调用stop()方法时,会同时停止内部的SparkContext
3.StreamingContext 停止后不能再启动。也就是说调用 stop()后不能再 start();
4…StreamingContext 启动之后,就不能再往其中添加任何计算逻辑了。也就是说执行 start()方法之后,不能再使 DStream 执行任何算子.
3.2 离散流 Discretized Streams(DStreams)
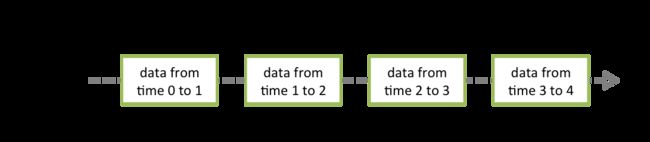
离散流或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过对输入流进行转换而生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不变的分布式数据集的抽象。DStream中的每个RDD都包含来自特定间隔(batch interval)的数据,如下图所示。
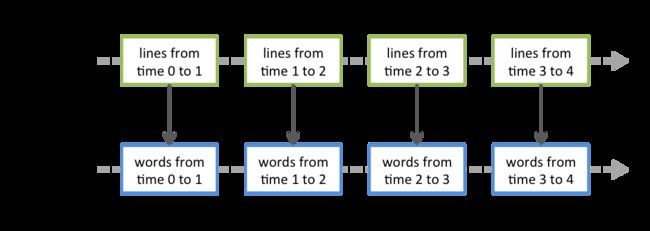
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,第二点举例中在将行流转换为单词中,该flatMap操作应用于linesDStream中的每个RDD,以生成DStream的 wordsRDD。如下图所示:
这些底层的 RDD 转换是由 Spark 引擎计算的。DStream 操作隐藏了这些细节中的大部分,并为开发人员提供了更高级的 API。详见后文 DStream API。
3.3 Input DStreams 与 Receivers(接收器)
输入DStream是表示从流源接收的输入数据流的DStream。在示例中,line输入DStream代表从netcat服务器接收的数据流。每个输入DStream都与一个Receiver对象 (Scala doc, Java doc)关联,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
Spark Streaming提供了两类内置的流媒体源:
- 基础源:StreamingContext API 中直接可用的资源。示例:文件系统和 Socket连接;
- 高级源:像 Kafka、Flume、Kinesis 等资源可以通过额外的工具类获得。这些需要额外依赖项;
可以在流处理程序中并行的接收多个数据流,即创建多个 Input DStreams。这将创建同时接收多个数据流的多个 receivers(接收器)。但需要注意,一个Spark 的 worker/executor 是一个长期运行的任务(task),因此它将占用分配给Spark Streaming 的应用程序的所有核中的一个核(core);
因此,一个Spark Streaming 应用需要分配足够的核(core)(或线程(threads),如果本地运行的话)来处理所接收的数据,以及来运行接收器(receiver(s))。
需要注意的点:
在本地运行 Spark Streaming 程序时,不要使用“local”或“local[1]”作为主URL。这两种方法都意味着只有一个线程将用于在本地运行任务。如果使用基于接收器的输入 DStream(例如 sockets、Kafka、Flume 等),那么将使用单个线程来运行接收器。因此,在本地运行时,始终使用"local[n]"作为主 URL,其中运行 n 个接收方;
在集群上运行时,分配给 Spark Streaming 应用程序的内核数量必须大于接收器的数量。否则,系统将接收数据,但无法处理它。
3.3.1 基础数据源
a.Socket(TCP Socket)
示例使用的即是是 Socket 数据源;
- textFileStream() 参 数 必 须 是 文 件 目 录 , 但 可 以 支 持 通 配 符 如"hdfs://namenode:8020/logs/2017/*";
- Spark 将监视该目录任务新建的文件,一旦有新文件才会处理;
- 所有文件要求有相同的数据格式;
- 监视文件的修改时间而不是创建时间,注意更新文件内容不会被监视,一旦开始处理,这些文件必须不能再更改,因此如果文件被连续地追加,新的数据也不会被读取;
- 处理后,在当前窗口中对文件的更改不会导致重新读取该文件。即: updates are ignored;
b.File Streams(文件流)
e.g.
import org.apache.spark.streaming._
val ssc =new StreamingContext(sc,Seconds(8))
ssc.textFileStream("/data/sparkstreaming/test/").print
ssc.start
c.RDDs 队列
通常用于测试中。为了使用测试数据测试 Spark Streaming 应用程序,可以使用 streamingContext.queueStream(queueOfRDDs) 创建一个基于 RDDs 队列的DStream,每个进入队列的 RDD 都将被视为 DStream 中的一个批次数据,并且就像一个流进行处理。
3.3.2 高级数据源
a.Flume 数据源
Spark Streaming 集成Flume
b.Kafka 数据源
Spark Streaming 集成 Kafka
3.3.3 Streams based on Custom Receivers
可以使用通过自定义接收器接收的数据流来创建DStream。
四、DStream API*
DStream API
五、Spark Streaming优化
Spark Streaming 优化
PS:如果有写错或者写的不好的地方,欢迎各位大佬在评论区留下宝贵的意见或者建议,敬上!如果这篇博客对您有帮助,希望您可以顺手帮我点个赞!不胜感谢!
| 原创作者:wsjslient |
| 作者主页:https://blog.csdn.net/wsjslient |