爬虫学习 爬虫概述&入门(二)
爬虫合法 如菜刀是一把双刃剑
反爬机制
反反爬机制
robots.txt协议 君子协议,规定那些数据不可爬取。搜索引擎
第一个爬虫的开发
模拟浏览器
from urllib.request import urlopen # url_lib url_openfrom urllib.request import urlopen url ="http://www.baidu.com" #https resp = urlopen(url) #print(resp.read().decode("utf-8")) #charset with open("mybaidu.html", mode="w",encoding ="utf-8") as f : f.write(resp.read().decode("utf-8"))
返回 页面源代码(HTML,CSS,JS)
 https与http不同,百度这是...
https与http不同,百度这是...
web请求全过程剖析
请求 拼装html 返回响应 浏览器执行
请求1 响应1(只有页面结构,隐含脚本) 再次请求2(新url) 返回响应2(只有数据)
分布式 分开服务器
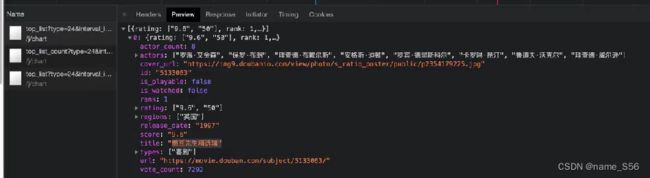
豆瓣为例
源代码只有壳

XHR preview
浏览器开发工具
elemets console network performance
elemets
与源代码近似,elemets,动态处理实时改变。
以源代码为基准
console
js调试,js逆向
sourse
源代码 js,css... 一切源
network
抓包工具

请求记录
XHR数据
preserve log
HTTP协议的简单了解
协议: TCP/IP HTTP SMTP
超文本传输协议
浏览器 与 服务器之间的数据交互规则
请求
请求行 -> 请求方式 (get/post) 请求url地址
请求头 -> 服务器附加信息
请求体 -> 一般放请求参数
响应
状态行 ->协议 状态码(200 302 404)
响应头 -> 客户端附加信息 (cookie,验证信息,解密的key)
响应体 -> 服务器返回 真正客户端要使用的内容(HTML,JS)
requests 模块入门
urllib urlopen 不太好用
第三方模块
终端
pip install requests
test_requests.py
import requests
#爬取百度的页面源代码
url = "http://www.baidu.com"
resp = requests.get(url)
resp.encoding = "utf-8"
print (resp.text) #拿到页面源代码
gets请求
搜狗为例
搜索https://www.sogou.com/web?query=2333
query后可更改
若被拦截:添加user-agent:请求头信息
headers = {
"user-agent": "...."
}
print(resp.request. headers) #查看请求头信息
resp =requsets.get(url,headers=headers)
post请求
以百度翻译为例
爬sug文件 新手
kw:dog

import requests
url; = "https://fanyi.baidu.com/sug"
data_name = { #可改名
"kw":input('输入一个单词')
}
resp = requests.post(url,data=data_name) #post在这赋值
#print(resp.text)
print(resp.json()) #json数据get请求太多时
豆瓣为例
HTML框架 和数据分开传输

注重链接中的"?"
GET---query string parameters
POST


params