Scannet v2 数据集介绍以及子集下载展示
Scannet v2 数据集介绍以及子集下载展示
文章目录
- Scannet v2 数据集介绍以及子集下载展示
-
- 参考
- 数据集简介
- 子集
-
- scannet_frames_25k
- scannet_frames_test
- 下载脚本 download_scannetv2.py
参考
scannet数据集简介和下载-CSDN博客
scannet v2 数据集下载_scannetv2数据集_蓝羽飞鸟的博客-CSDN博客
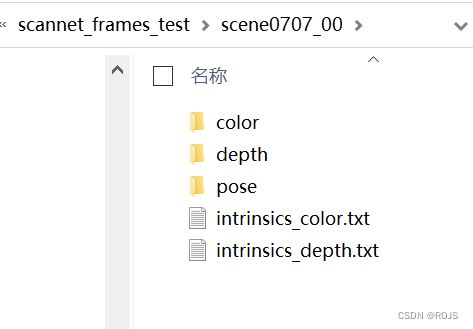
ScanNet数据集下载与导出颜色图、深度图、内参、位姿数据-CSDN博客
simplerecon/data_scripts/scannet_wrangling_scripts at main · nianticlabs/simplerecon (github.com)
数据集简介
数据集Github地址 ScanNet/ScanNet (github.com)
ScanNet 是一个 RGB-D 视频数据集,包含 1500 多次扫描中的 250 万个视图,并使用 3D 相机姿势、表面重建和实例级语义分割进行注释 。 ScanNet V2数据集一共1.2T 。(但其实不用全下载,按照对应的任务有选择的下载)
RGB-D 传感器是一种特定类型的深度感应设备,与RGB(红色、绿色和蓝色)传感器相机配合使用。 它通过在每个像素的基础上使用深度信息(与传感器的距离相关)来增强传统图像,即RGBD = RGB + Depth Map。
子集
由于整份数据较大,有1.2T,作者提供了下载较小子集的选项scannet_frames_25k(约25,000帧,从完整数据集中大约每100帧进行二次采样)通过ScanNet数据下载,有5.6G,还有基准评估scannet_frames_test。
- scannet_frames_25k.zip ~5.6G,1513 份 scans(即 RGB-D 序列,这里简单当成 videos),包含训练集和测试集,训练集1021,验证集312
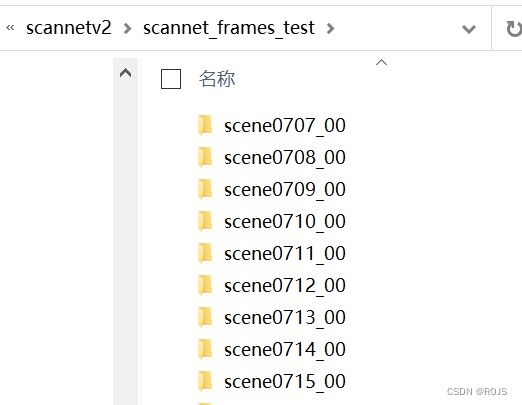
- scannet_frames_test.zip ~618mb ,100份,用作测试集
#下载scannet_frames_25k
python download_scannetv2.py -o data --preprocessed_frames
#下载scannet_frames_test
python download_scannetv2.py -o data --test_frames_2d
scannet_frames_25k



scannet_frames_test
下载脚本 download_scannetv2.py
#coding:utf-8
#!/usr/bin/env python
# Downloads ScanNet public data release
# Run with ./download-scannet.py (or python download-scannet.py on Windows)
# -*- coding: utf-8 -*-
import argparse
import os
import urllib.request #(for python3)
# import urllib
import tempfile
BASE_URL = 'http://kaldir.vc.in.tum.de/scannet/'
TOS_URL = BASE_URL + 'ScanNet_TOS.pdf'
FILETYPES = ['.sens', '.txt',
'_vh_clean.ply', '_vh_clean_2.ply',
'_vh_clean.segs.json', '_vh_clean_2.0.010000.segs.json',
'.aggregation.json', '_vh_clean.aggregation.json',
'_vh_clean_2.labels.ply',
'_2d-instance.zip', '_2d-instance-filt.zip',
'_2d-label.zip', '_2d-label-filt.zip']
FILETYPES_TEST = ['.sens', '.txt', '_vh_clean.ply', '_vh_clean_2.ply']
PREPROCESSED_FRAMES_FILE = ['scannet_frames_25k.zip', '5.6GB']
TEST_FRAMES_FILE = ['scannet_frames_test.zip', '610MB']
LABEL_MAP_FILES = ['scannetv2-labels.combined.tsv', 'scannet-labels.combined.tsv']
RELEASES = ['v2/scans', 'v1/scans']
RELEASES_TASKS = ['v2/tasks', 'v1/tasks']
RELEASES_NAMES = ['v2', 'v1']
RELEASE = RELEASES[0]
RELEASE_TASKS = RELEASES_TASKS[0]
RELEASE_NAME = RELEASES_NAMES[0]
LABEL_MAP_FILE = LABEL_MAP_FILES[0]
RELEASE_SIZE = '1.2TB'
V1_IDX = 1
def get_release_scans(release_file):
scan_lines = urllib.request.urlopen(release_file)
# scan_lines = urllib.urlopen(release_file)
scans = []
for scan_line in scan_lines:
scan_id = scan_line.decode('utf8').rstrip('\n')
scans.append(scan_id)
return scans
def download_release(release_scans, out_dir, file_types, use_v1_sens):
if len(release_scans) == 0:
return
print('Downloading ScanNet ' + RELEASE_NAME + ' release to ' + out_dir + '...')
for scan_id in release_scans:
scan_out_dir = os.path.join(out_dir, scan_id)
download_scan(scan_id, scan_out_dir, file_types, use_v1_sens)
print('Downloaded ScanNet ' + RELEASE_NAME + ' release.')
def download_file(url, out_file):
out_dir = os.path.dirname(out_file)
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
if not os.path.isfile(out_file):
print('\t' + url + ' > ' + out_file)
fh, out_file_tmp = tempfile.mkstemp(dir=out_dir)
f = os.fdopen(fh, 'w')
f.close()
urllib.request.urlretrieve(url, out_file_tmp)
# urllib.urlretrieve(url, out_file_tmp)
os.rename(out_file_tmp, out_file)
else:
print('WARNING: skipping download of existing file ' + out_file)
def download_scan(scan_id, out_dir, file_types, use_v1_sens):
print('Downloading ScanNet ' + RELEASE_NAME + ' scan ' + scan_id + ' ...')
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
for ft in file_types:
v1_sens = use_v1_sens and ft == '.sens'
url = BASE_URL + RELEASE + '/' + scan_id + '/' + scan_id + ft if not v1_sens else BASE_URL + RELEASES[
V1_IDX] + '/' + scan_id + '/' + scan_id + ft
out_file = out_dir + '/' + scan_id + ft
download_file(url, out_file)
print('Downloaded scan ' + scan_id)
def download_task_data(out_dir):
print('Downloading ScanNet v1 task data...')
files = [
LABEL_MAP_FILES[V1_IDX], 'obj_classification/data.zip',
'obj_classification/trained_models.zip', 'voxel_labeling/data.zip',
'voxel_labeling/trained_models.zip'
]
for file in files:
url = BASE_URL + RELEASES_TASKS[V1_IDX] + '/' + file
localpath = os.path.join(out_dir, file)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded task data.')
def download_label_map(out_dir):
print('Downloading ScanNet ' + RELEASE_NAME + ' label mapping file...')
files = [LABEL_MAP_FILE]
for file in files:
url = BASE_URL + RELEASE_TASKS + '/' + file
localpath = os.path.join(out_dir, file)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded ScanNet ' + RELEASE_NAME + ' label mapping file.')
def main():
parser = argparse.ArgumentParser(description='Downloads ScanNet public data release.')
parser.add_argument('-o', '--out_dir', required=True, help='directory in which to download')
parser.add_argument('--task_data', action='store_true', help='download task data (v1)')
parser.add_argument('--label_map', action='store_true', help='download label map file')
parser.add_argument('--v1', action='store_true', help='download ScanNet v1 instead of v2')
parser.add_argument('--id', help='specific scan id to download')
parser.add_argument('--preprocessed_frames', action='store_true',
help='download preprocessed subset of ScanNet frames (' + PREPROCESSED_FRAMES_FILE[1] + ')')
parser.add_argument('--test_frames_2d', action='store_true', help='download 2D test frames (' + TEST_FRAMES_FILE[
1] + '; also included with whole dataset download)')
parser.add_argument('--type',
help='specific file type to download (.aggregation.json, .sens, .txt, _vh_clean.ply, _vh_clean_2.0.010000.segs.json, _vh_clean_2.ply, _vh_clean.segs.json, _vh_clean.aggregation.json, _vh_clean_2.labels.ply, _2d-instance.zip, _2d-instance-filt.zip, _2d-label.zip, _2d-label-filt.zip)')
args = parser.parse_args()
print(
'By pressing any key to continue you confirm that you have agreed to the ScanNet terms of use as described at:')
print(TOS_URL)
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = input('')
if args.v1:
global RELEASE
global RELEASE_TASKS
global RELEASE_NAME
global LABEL_MAP_FILE
RELEASE = RELEASES[V1_IDX]
RELEASE_TASKS = RELEASES_TASKS[V1_IDX]
RELEASE_NAME = RELEASES_NAMES[V1_IDX]
LABEL_MAP_FILE = LABEL_MAP_FILES[V1_IDX]
release_file = BASE_URL + RELEASE + '.txt' # 存放场景ID的文件
release_scans = get_release_scans(release_file) # 所有场景的ID
file_types = FILETYPES; # 所有文件的后缀名
release_test_file = BASE_URL + RELEASE + '_test.txt' # 存放测试场景ID的文件
release_test_scans = get_release_scans(release_test_file) # 测试场景的ID
file_types_test = FILETYPES_TEST; # 测试相关文件的后缀名
out_dir_scans = os.path.join(args.out_dir, 'scans') # 下载文件的子文件夹
out_dir_test_scans = os.path.join(args.out_dir, 'scans_test') # 下载文件的子文件夹
out_dir_tasks = os.path.join(args.out_dir, 'tasks') # 下载文件的子文件夹
# 指定下载的文件类型
if args.type: # download file type
file_type = args.type
if file_type not in FILETYPES:
print('ERROR: Invalid file type: ' + file_type)
return
file_types = [file_type]
if file_type in FILETYPES_TEST:
file_types_test = [file_type]
else:
file_types_test = []
if args.task_data: # download task data
download_task_data(out_dir_tasks)
elif args.label_map: # download label map file
download_label_map(args.out_dir)
elif args.preprocessed_frames: # download preprocessed scannet_frames_25k.zip file
if args.v1:
print('ERROR: Preprocessed frames only available for ScanNet v2')
print('You are downloading the preprocessed subset of frames ' + PREPROCESSED_FRAMES_FILE[
0] + ' which requires ' + PREPROCESSED_FRAMES_FILE[1] + ' of space.')
download_file(os.path.join(BASE_URL, RELEASE_TASKS, PREPROCESSED_FRAMES_FILE[0]),
os.path.join(out_dir_tasks, PREPROCESSED_FRAMES_FILE[0]))
elif args.test_frames_2d: # download test scannet_frames_test.zip file
if args.v1:
print('ERROR: 2D test frames only available for ScanNet v2')
print('You are downloading the 2D test set ' + TEST_FRAMES_FILE[0] + ' which requires ' + TEST_FRAMES_FILE[
1] + ' of space.')
download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]),
os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))
elif args.id: # download single scan
scan_id = args.id
is_test_scan = scan_id in release_test_scans
if scan_id not in release_scans and (not is_test_scan or args.v1):
print('ERROR: Invalid scan id: ' + scan_id)
else:
out_dir = os.path.join(out_dir_scans, scan_id) if not is_test_scan else os.path.join(out_dir_test_scans,
scan_id)
scan_file_types = file_types if not is_test_scan else file_types_test
use_v1_sens = not is_test_scan
if not is_test_scan and not args.v1 and '.sens' in scan_file_types:
print(
'Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')
key = input('')
if key.strip().lower() == 'n':
scan_file_types.remove('.sens')
download_scan(scan_id, out_dir, scan_file_types, use_v1_sens)
else: # download entire release
if len(file_types) == len(FILETYPES):
print(
'WARNING: You are downloading the entire ScanNet ' + RELEASE_NAME + ' release which requires ' + RELEASE_SIZE + ' of space.')
else:
print('WARNING: You are downloading all ScanNet ' + RELEASE_NAME + ' scans of type ' + file_types[0])
print(
'Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.')
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = input('')
if not args.v1 and '.sens' in file_types:
print(
'Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')
key = input('')
if key.strip().lower() == 'n':
file_types.remove('.sens')
download_release(release_scans, out_dir_scans, file_types, use_v1_sens=True)
if not args.v1:
download_label_map(args.out_dir)
download_release(release_test_scans, out_dir_test_scans, file_types_test, use_v1_sens=False)
download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]),
os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))
if __name__ == "__main__": main()