Langchain-Chatchat学习
参考:Langchain-Chatchat + 阿里通义千问Qwen 保姆级教程 | 次世代知识管理解决方案 - 知乎 (zhihu.com)
中文LLM生态观察
模型
就开源的部分而言,从一开始的MOSS[1] ChatGLM[2] ChatGLM2 [3] 到后来的 baichan [4] 基于LLama2 微调的 中文LLama2 [5] 再到最近开源的 通义千问 Qwen [6] 。 至于更多模型和相关评分榜单可以看一直在维护更新模型汇总的文章。
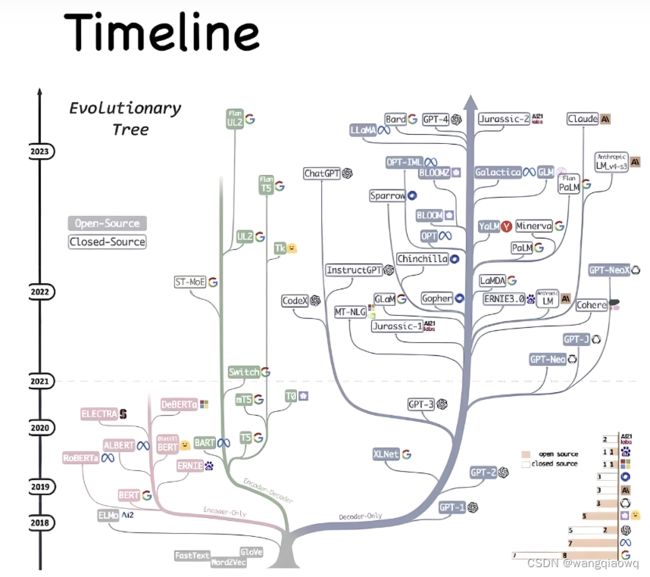
参考:大语言模型汇总索引帖(持续更新) - 知乎 (zhihu.com)
基于langchain的智能助手

其中比较突出的,之前我觉得是ChatGLM系列 ,不过现在我认为是最近开源的 Qwen 通义千问。
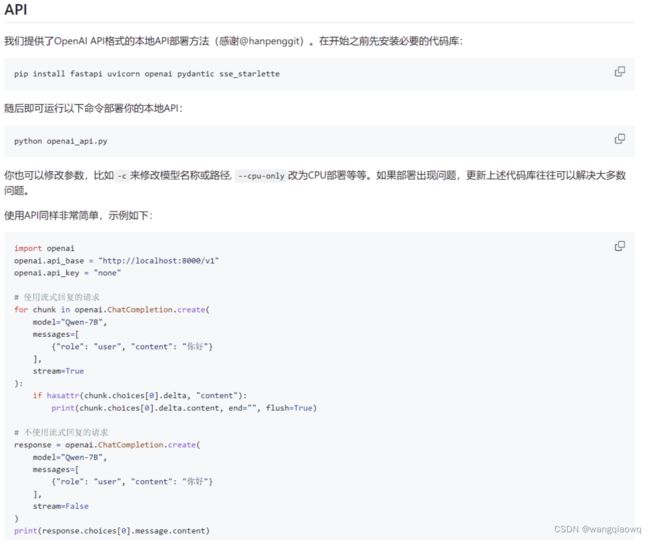
各家都有一个比较好的做法就是去适配一套和OpenAI gpt3.5一致的API 方便大家在测试和搭建不同模型时快速的切换,减少大量阅读接口文档的时间。

通义千问干脆直接默认API部署代码做成OpenAI API 格式
生态
除了大语言模型本身,相关的基建生态也是我们需要持续关注的。 其中最出名的当属基于相当于LLM应用中间件的 LLama Index 、 Langchain框架 和 AIGC时代数据持久化层的 各大向量数据库。
- 使用 FastChat 提供开源 LLM 模型的 API,以 OpenAI API 接口形式接入,提升 LLM 模型加载效果;
- 使用 langchain 中已有 Chain 的实现,便于后续接入不同类型 Chain,并将对 Agent 接入开展测试;
- 使用 FastAPI 提供 API 服务,全部接口可在 FastAPI 自动生成的 docs 中开展测试,且所有对话接口支持通过参数设置流式或非流式输出;
- 使用 Streamlit 提供 WebUI 服务,可选是否基于 API 服务启动 WebUI,增加会话管理,可以自定义会话主题并切换,且后续可支持不同形式输出内容的显示;
- 项目中默认 LLM 模型改为 THUDM/chatglm2-6b,默认 Embedding 模型改为 moka-ai/m3e-base,文件加载方式与文段划分方式也有调整,后续将重新实现上下文扩充,并增加可选设置;
- 项目中扩充了对不同类型向量库的支持,除支持 FAISS 向量库外,还提供 Milvus, PGVector 向量库的接入;
- 项目中搜索引擎对话,除 Bing 搜索外,增加 DuckDuckGo 搜索选项,DuckDuckGo 搜索无需配置 API Key,在可访问国外服务环境下可直接使用。
架构
其实LangChain-Chatchat 前身是 langchain-chatglm ,即为chatglm 制作的 langchain 组件
下面是早期项目的流程原理图
简单来说就是把本地的一些文档( doc txt md csv json ...) 先通过一系列处理( 读取 分词 )embedding模型编码成一定数量的高维向量 (下图中 1到6)
而用户原本直接和LLM对话的文本 也会通过embedding 模型编码成高维向量 (下图中 8 9)
然后通过计算余弦相似度的方式 (下图中10和7) 来检索本地文档库中可能提供帮助的相关资料
再和原用户的问题文本 结合 (下图中11)
经过预先我们准备好的提示词模板 Prompt Template 组装成最后的 Prompt 提示词 (下图中12 13)
去问LLM (下图中14 15)
简单来说,embedding模型是一种通过将输入数据转换为稠密的实值向量(也称为嵌入)来解决机器学习问题的技术。这种转换使得原始输入数据可以在一个新的、潜在的空间中表示,其中相似的输入被映射到彼此接近的位置,而不同的输入则被映射到远离的位置。
embedding模型最早在自然语言处理领域得到广泛应用,其中最著名的例子可能是word2vec模型。在这种模型中,每个单词都被映射到一个固定的向量,向量之间的距离可以反映两个单词在语义上的相似程度。
除了自然语言处理之外,embedding模型还广泛应用于计算机视觉、社交网络分析等领域。例如,在图像识别中,我们可以将每张图片映射到一个高维向量,向量之间的距离可以反映两张图片之间的相似度;在社交网络分析中,我们可以将每个用户映射到一个向量,向量之间的距离可以反映两个用户之间的相似度等等。
总之,embedding模型提供了一种有效的方式来捕获数据中的复杂结构和关联,因此它已经成为许多机器学习应用的重要组成部分。
模型下载方法汇总
通义千问 Qwen-7B-Chat-Int4 模型本地化部署-CSDN博客
git clone https://www.modelscope.cn/Jerry0/m3e-base.git
2.0版本在原有基础上
增加了支持的大语言模型 比如我们今天要讲的通义千问 。
增加了支持的向量数据库 比如本文中使用的Milvus。
增加了搜索引擎能力的集成 让LLM能利用外部实时信息 比如本文中使用的DuckDuckGO。

git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git


cat requirements.txt



pip install -r requirements.txt
配置文件修改
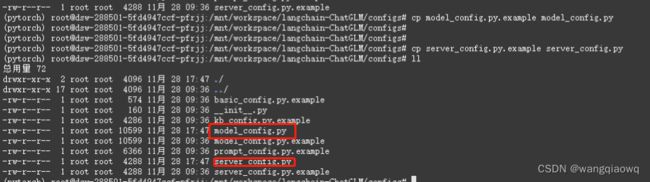
复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。
参考:win10 安装 Langchain-Chatchat 避坑指南(2023年9月18日v0.2.4版本,包含全部下载内容!)-CSDN博客


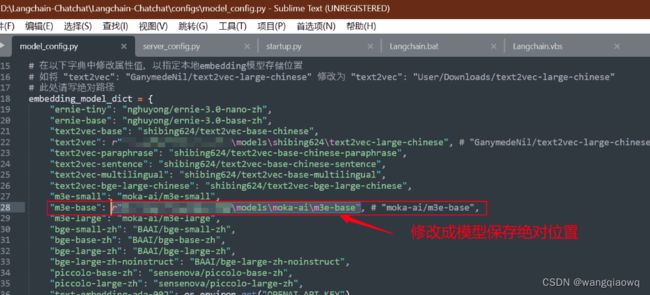

embedding模型 、llm模型、 向量数据库 、 prompt template (后面这俩我们先使用默认即可)
llm模型
将local_model_path 的值改为你机器上存放千问模型的路径

感觉配置的不对 待验证


参考:大模型部署手记(16)ChatGLM2+Ubuntu+LongChain-ChatChat-CSDN博客
cp basic_config.py.example basic_config.py
cp kb_config.py.example kb_config.py
cp prompt_config.py.example prompt_config.py
知识库初始化
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库
cd ..
python init_database.py --recreate-vs
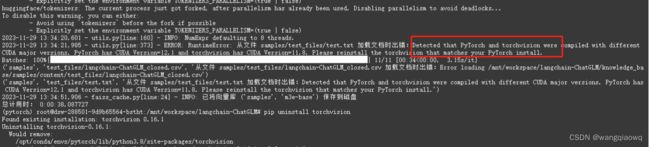
从给出的错误信息来看,PyTorch和torchvision是用不同的CUDA主要版本编译的PyTorch使用的是CUDA 12.1版本,而torchvision使用的是CUDA 11.8版本为了解决这个问题,你需要重新安装与PyTorch版本相匹配的torchvision
pip uninstall torchvision

pip install torchvision -f https://download.pytorch.org/whl/cu121/torch_stable.html

python init_database.py --recreate-vs
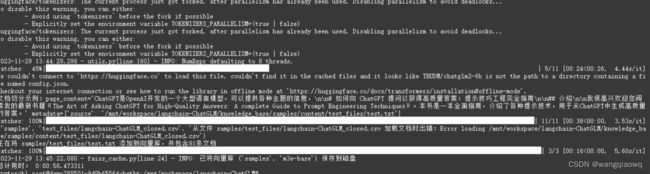
还是有些问题 GPU版本不对
启动:
python startup.py --all-webui