A Lifelong Learning Approach to Brain MR Segmentation Across Scanners and Protocols(附翻译)
A Lifelong Learning Approach to Brain MR Segmentation Across Scanners and Protocols
冲冲冲冲冲冲冲!
文章目录
- A Lifelong Learning Approach to Brain MR Segmentation Across Scanners and Protocols
- 一、总结
- 二、翻译
-
- 0. 摘要
- 1. 引言
- 2. 方法
- 3. 实验
-
- 3.1 数据集:
- 3.2 训练细节
- 3.3 实验
- 3.4 结果
- 4. 结论
- 三、纸质版材料
一、总结



二、翻译
0. 摘要
abstract:
卷积神经网络(CNN)在磁共振(MR)图像的多个分割任务中已显示出令人鼓舞的结果。但是,与训练数据相比,在分割使用不同扫描仪和/或协议(different scanners and/or protocols)获取的图像时,CNN的准确性可能会严重下降,从而限制了其实用性 (limiting their practical utility)。我们通过终身多域学习(lifelong multi-domain learning)设置来解决这一缺点,不同的扫描器或协议获取的图像作为来自不同但相关域的样本。我们的解决方案是一个具有共享卷积过滤器和特定于域的批处理归一化层的单个CNN(shared convolutional filters and domain-specific batch normalization layers),可以将其调整为仅带有几张(≈4)标记图像的新域。重要的是,这是在保留较旧域的性能的同时实现的,这些域的训练数据可能不再可用。我们评估MR图像中的脑结构分割方法。结果表明,所提出的方法大大缩小了与基准的差距,后者正在为每个扫描仪训练专用的CNN。
1. 引言
introduction:
脑部MR图像的分割是许多诊断和手术应用中的关键步骤。因此,已经提出了几种解决该问题的方法,例如基于地图集的分割,基于机器学习技术的方法(例如CNN),以及最近的调查[3]中详述的许多其他方法。在许多MRI分析任务(包括分割)中,重要的挑战之一是对图像强度统计特性差异的鲁棒性 (robustness to differences in statistical characteristics of image intensities’图像彩色/灰度值’)。这些差异可能是由于使用不同的扫描仪而引起的,其中诸如扫描仪SNR随时间的漂移(drift in scanner SNR),梯度非线性(gradient nonlinearities)等因素起着重要的作用。当在同一台扫描仪上略微更改扫描协议参数(翻转角度,回波或重复时间等)时,甚至可能出现强度变化。图1(a,b)显示了来自不同扫描仪的两个T1加权MRI数据集的2D切片,以及显示上述变化的强度直方图。分割算法通常对此类更改非常敏感。此外,以不同的MR模态采集的图像(例如T1和T2加权图像)在图像内容中可能具有相当高的相似度(见图1)。在分析这些图像时,人类可以轻松利用这些共性,如果基于学习的算法可以模仿此特征,将是非常可取的。
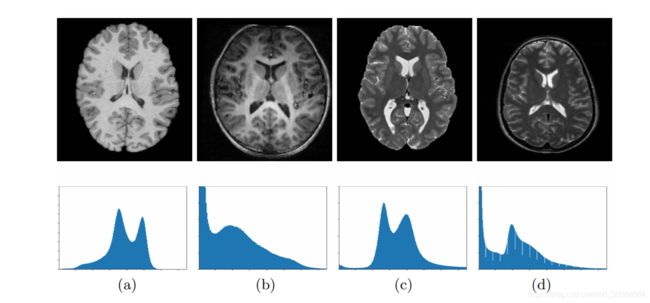
图1,来自不同扫描仪的标准化T1w(a,b)和T2w(c,d)MRI的图像切片和相应的直方图。 尽管在信息上具有高度的相似性,但是仍然存在相当大的强度和对比度差异,因此分割算法通常对此敏感。
用迁移学习的话来说,从不同的扫描仪,协议或类似的MR模式获取的图像可以看作是从不同域采样的数据点,域移动的程度可能由其强度统计的差异来表示。这种观点促使我们从域适应,多域学习和终身学习的文献中运用思想,跨扫描器/协议进行脑分割问题。域适应/转移学习是指这样一种情况,其中在源域上训练的学习者能够在目标域可用,且目标域中只有几个标记的示例。但是,在这种情况下,适应后不一定可以保持源域的性能。多域学习旨在训练可以同时在多个域表现出色的学习者。最后,在终身学习中,多域学习能够仅用少数几个带标签的示例合并新域,同时保持以前域的性能。
图像强度标准化(image intensity standardization)和图谱强度重新归一化(atlas intensity renormalization)的变体已被提出作为预处理步骤,以确保传统的分割方法不受扫描仪间差异的影响。在基于手工特征的学习方法中,迁移学习方法已用于多站点(multi-site)分割和分类[12,13]。尽管12使用的自适应支持向量机可以终身学习的方式适应于新的扫描仪,但它们很可能会受到手工计算质量的限制。[14]提出使用CNN,通过学习域不变表示来处理协议间的差异。这种方法可能仅限于使用域之间的最小公分母来工作,而如[15]所示,为每个域提供一些单独的参数可以学习域特定的细微差别。此外,尚不清楚如何将[14]扩展为处理初始训练后可能遇到的新领域。在计算机视觉文献中,对于域自适应[17,18]和用于使用CNN的对象识别的多域学习[15,19],已经提出了几种批处理归一化(BN)的适应方法。 广泛地讲,这些工作采用BN进行特定于域的缩放以解决域偏移,同时共享大量CNN参数以利用域之间的相似性。
在这项工作中,我们扩展了基于自适应BN层的方法(adaptive BN layers),以在终身学习环境中跨扫描协议进行分割。 特别是,我们为每个协议/扫描器训练了具有通用卷积滤波器和特定BN参数的CNN。 最初使用来自一些扫描仪的图像来训练网络,以学习适当的卷积滤波器。 通过对带有一些标记图像的BN参数进行微调,可以使其适应新协议。至关重要的是,这在不降低旧扫描仪性能的前提下得以实现,而旧扫描仪的训练数据在初始培训后将不可用。
2. 方法
method:
批处理规范化(BN)在[16]中引入,可通过在每个非线性激活层之前通过对输入进行规范化来防止饱和梯度,从而实现对深度神经网络的更快训练。 在BN层中,每个batch x B x_B xB均被标准化,如等式1所示。 B N ( x B ) = γ × x B − μ B σ B 2 + ϵ + β BN(x_B)=\gamma\times\frac{x_B-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}+\beta BN(xB)=γ×σB2+ϵxB−μB+β训练期间, μ B \mu_B μB和 σ B 2 \sigma_B^2 σB2是 x B x_B xB的均值和方差,而在测试时,它们是估计的总体均值和方差,其是通过训练批次中的移动平均值近似得出的。 γ , β \gamma,\beta γ,β是可学习的参数,允许网络在需要时取消标准化。 受[15]的启发,我们建议对每个协议使用单独的批量标准化。
尽管由于扫描仪间的差异而导致图像统计信息的变化,但分割网络仍将面临以相同模态(MR)采集的相同器官的图像。 因此,合理地假设域之间有共同通用特征,并因此在适当的表示空间中共享支持。我们假设可以通过使用与领域无关的卷积滤波器来找到这样的表示空间,并且可以通过特定于域的BN模块通过适当的归一化来处理域间差异。 这种方法不仅符合先前的领域适应工作,而且还体现了用于处理扫描程序间变化的常规建议的规范化思想。 此外,一旦学习到合适的共享卷积滤波器,我们就将领域特定的BN层调整为新的相关领域。
我们框架中的训练程序如下。 我们使用上标 b n ^{bn} bn表示具有特定于域的BN层的网络。 我们最初在d个域上训练了一个网络 N 12... d b n N_{12...d}^{bn} N12...dbn,该网络具有共享的卷积滤波器和每个域 D k D_k Dk的单独的BN参数 b n k bn_k bnk。在训练期间,每批仅包含一个域,并且所有域都被依次覆盖。在训练迭代中,当批次由域 D k D_k Dk组成时,冻结 k ′ ≠ k k^{'}\neq k k′=k的 b n k ′ bn_{k^{'}} bnk′。现在,考虑一个新的域 D d + 1 D_{d+1} Dd+1,其中包含一些标记的图像 I D d + 1 I_{D_{d+1}} IDd+1。我们把这个小的数据集拆分两部分,一部分 I D d + 1 t r I_{D_{d+1}}^{tr} IDd+1tr用于训练,另一部分 I D d + 1 v l I_{D_{d+1}}^{vl} IDd+1vl用于验证。我们用 I D d + 1 t r I_{D_{d+1}}^{tr} IDd+1tr评估 N 12... d b n N_{12...d}^{bn} N12...dbn,使用每个学习到的 b n k , k = 1 , 2 , . . . , d bn_k,k=1,2,...,d bnk,k=1,2,...,d如果 b n k ∗ bn_{k^{*}} bnk∗导致最佳精度,我们推断在已经学习的域中, D k ∗ D_{k^{*}} Dk∗最接近 D d + 1 D_{d+1} Dd+1然后,在保持卷积滤波器权重不变的情况下,使用 b n k ∗ bn_{k^{*}} bnk∗初始化另一组BN参数 b n d + 1 bn_{d+1} bnd+1,并使用 I D d + 1 t r I_{D_{d+1}}^{tr} IDd+1tr进行微调,并采用标准随机梯度下降法。当 I D d + 1 v l I_{D_{d+1}}^{vl} IDd+1vl的性能停止改善时,停止优化。现在,网络可以分割所有域 D k D_k Dk,其中 k = 1 , 2 , . . . , d , d + 1 k=1,2,...,d,d+1 k=1,2,...,d,d+1使用它们各自的 b n k bn_k bnk。
本着终身学习的精神,这种方法允许仅使用几个带有标签的示例在新领域中进行学习。 这是通过利用从旧领域学习而获得的知识(以经过训练的域不可知参数的形式)来实现的。特定于域的参数数量少的事实具有两个优点。 第一,可以通过快速训练一些带有标签的图像并将它们过度拟合的风险降到最低,从而将它们调整到新的领域。 其次,可以为每个域保存它们,而不会占用大量内存。 最后,由于共享和私有参数的显式单独建模,在此方法中,先前域的性能下降而导致的灾难性忘记不会出现。
3. 实验
experiments and results:
3.1 数据集:
dataset:
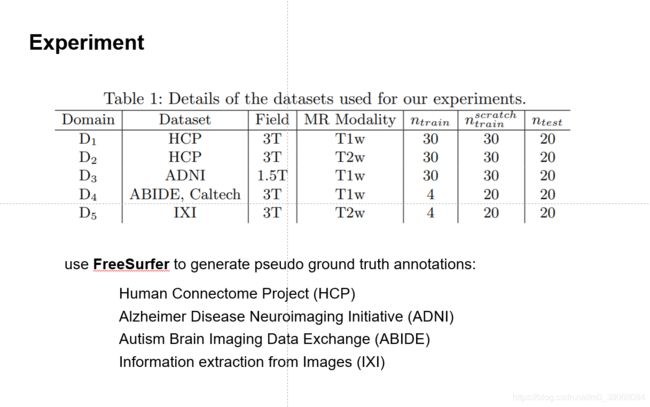
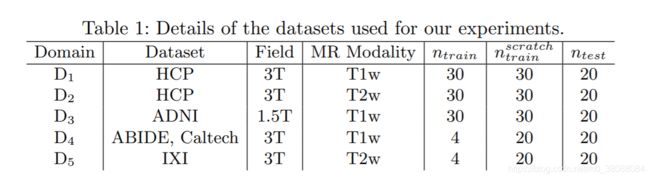
需要使用来自多个扫描仪,医院或采集协议的大脑MR数据集来测试所提出的方法对终身多域学习的适用性。 据我们所知,只有少数可公开获得的带有人类专家提供的带有ground truth分割标签的脑部MRI数据集。 因此,我们使用FreeSurfer生成伪ground truth注释。 尽管人类专家的注释是理想的选择,但我们认为FreeSurfer注释可以作为合理的代理,以测试我们进行终身多扫描器学习的方法。
我们使用来自4个公开可用数据集的图像:Human Connectome Project
(HCP),Alzheimers Disease Neuroimaging Initiative (ADNI), Autism Brain Imaging Data Exchange (ABIDE)和Information eXtraction from Images(IXI)。数据集分为不同的域,如表1所示,域D1,D2,D3被视为最初可用,而D4,D5被视为新域。 表中指出的每个域的训练图像和测试图像的数量将在稍后描述实验时进行说明。
3.2 训练细节
training details:
虽然特定于域的BN层可以合并到任何标准的CNN中,但我们使用的是经过小改动的U-Net体系结构。我们的网络减少了深度,有三个最大池化层,同时减少了滤波器的数量:收缩路径上的卷积块中的32,64,128,256和上采样路径上的128,64,32。而且,考虑到可能的棋盘伪像,双线性内插比反卷积层更适合进行反卷积放大。每个图像体积的强度通过除以98%的平铺度进行归一化。初始网络训练大约需要6个小时,而特定于域的BN模块可以在大约1个小时内针对新域进行更新。
3.3 实验
Experiments:
如下所述,我们训练三种类型的网络。
Individual networks: 为每个域d训练 n t r a i n s c r a t c h n_{train}^{scratch} ntrainscratch的训练图像。 对于已知域(D1,D2,D3), N d N_d Nd的精度用作其他参数必须保留的网络的基线。 对于新领域(D4,D5), N d N_d Nd的性能是我们希望通过在更少的训练示例( n t r a i n n_{train} ntrain)上进行训练并利用先前学习的领域的知识来实现的基准。
A shared network N 123 N_{123} N123: 使用 n t r a i n n_{train} ntrain图像在D1,D2,D3上训练,共享所有参数,包括BN层 b n s bn_s bns。与第2节中介绍的 N 12... d b n N_{12...d}^{bn} N12...dbn的训练方式相反,在训练 N 123 N_{123} N123时,每批随机包含来自所有域的图像,以确保可以针对所有域调整共享的BN参数。直方图均衡在测试 N 123 N_{123} N123之前应用于新的域 D d D_d Dd。 为了使 N 123 N_{123} N123适应 D d D_d Dd,使用新域的 n t r a i n n_{train} ntrain图像对它的参数进行微调,并将修改后的网络称为 N 123 → d N_{123→d} N123→d。
A lifelong multi-domain learning network N 123 b n N_{123}^{bn} N123bn: 在D1,D2,D3上进行训练,具有共享的卷积层和特定于域的BN层。 根据本节中描述的过程将 N 123 b n N_{123}^{bn} N123bn扩展到新域 D d D_d Dd之后的更新网络,称为 N 123 , k ∗ → d N_{123,k^{*}→d} N123,k∗→d,其中 k ∗ k^{*} k∗是最接近 D d D_d Dd的域。
3.4 结果
results:
根据来自适当域的 n t e s t n_{test} ntest图像的平均Dice分数,对所有网络进行评估。我们的实验的定量结果显示在表2中。发现可总结如下:
N 123 N_{123} N123保留N1,N2,N3的性能。 因此,如果一次从所有域中获得足够的训练数据,则单个网络可以学习对多个域进行分割。 但是,对于没见过的域D4和D5,其性能会严重降低。 直方图均衡化(用Dd,HistEq表示)无法最显着地提高性能,而针对新域进行微调会导致灾难性的遗忘,即旧域的性能下降。
N 123 b n N_{123}^{bn} N123bn还保留了N1,N2,N3的性能。 对于新域D4,使用经过训练的 N 123 b n N_{123}^{bn} N123bn的 b n 3 bn_3 bn3参数可获得最佳性能。 因此,我们推断D3在D1,D2,D3中最接近D4。 在微调 b n 3 bn_3 bn3的参数以获得 b n 4 bn_4 bn4的参数之后,所有结构的骰子得分都显着提高,可以与N4的性能相提并论。至关重要的是,由于保存了k = 1,2,3的原始 b n k bn_k bnk,更新后的网络 N 123 , 3 → 4 b n N_{123,3→4{bn}} N123,3→4bn中D1,D2,D3的性能与 N 123 b n N_{123}^{bn} N123bn中的性能完全相同。对于另一个新域D5, 在微调BN参数后,也可以在图2中定性地观察到新域分割的改进。

4. 结论
conclusion:
在本文中,我们提出了一种终生的多域学习方法,用于学习MR相关模式以及跨扫描器/协议的分段CNN。 此外,它可以适用于仅带有少量标记图像的新扫描仪或协议,而不会降低以前的扫描仪的性能。 这是通过学习每个扫描仪的批处理归一化参数,同时在所有扫描仪之间共享卷积滤波器来实现的。 在以后的工作中,我们打算研究将这种方法扩展到初始训练中不存在的MR模式的可能性。
三、纸质版材料






