第十一章 神经网络实战1 回归和分类问题
1.介绍
在这章,我们来实战一下真正的神经网络。神经网络能解决的问题是多种多样的,总的来说可以分为两类,一类是回归问题,一类是分类问题。在本章,我们将实现两个简单的神经网络,一个解决回归问题,一个解决分类问题。
2.回归问题
1.什么是回归问题
我们之前做的异或分类的神经网络其实就是一个回归问题。回归问题就是把离散数据模拟成连续数据,探索其公式。这么说很抽象,说白了就是给你一个散点图,让你找一条曲线来尽可能地穿过它。和我们高中时期学过的预测降雨量,预测衣服销售和天气的关系是一样的,不过高中有用于解决回归的经验性公式,也叫回归函数来解决,回归神经网络往往是可以做得比回归函数更好的,下面我就用一个简单的回归网络解决几个简单的离散数据的预测问题。
2.准备数据集
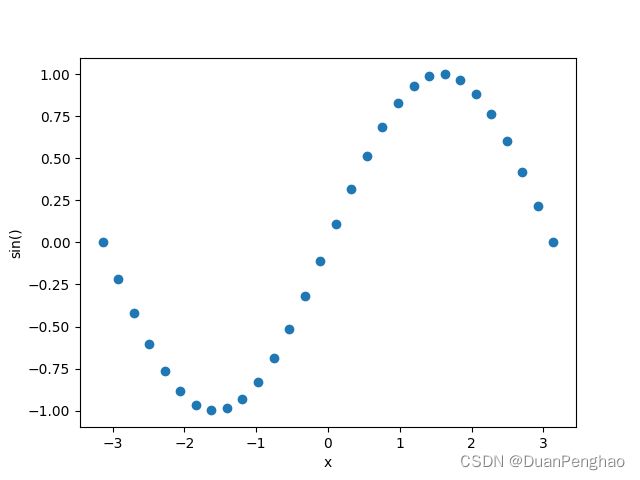
我们定一个简单的模拟目标,比如模拟正弦函数sin(),sin()的曲线我们前面画过,但是假设我们现在不知道sin()这个公式,我们只知道30个输入,和30个输出。我们先画它的散点图看看:
这里我们先介绍一个函数
torch.unsqueeze(x, dim=n)
这个函数可以转换数组成目标维度。x是一个任意维度的数组,dim是要转换的维度,但是1是二维,2是三维以此类推。为什么需要这个呢,因为torch的神经网络并不能接受二维以下的神经网络,我们如果有一维输入,那必须先转为二维。
"""
@FileName:Regression.py
@Description:简单回归问题:预测一个sin的曲线
@Author:段鹏浩
@Time:2023/3/23 21:48
"""
import numpy as np
import torch
import matplotlib.pyplot as plt
# 30个输入,从-pi到pi
x = torch.linspace(-np.pi, np.pi, 30)
x = torch.unsqueeze(x, dim=1) # 把一维的数组转为二维的
# 对应的输出:
y = np.sin(x)
plt.scatter(x, y)
plt.xlabel("x")
plt.ylabel("sin()")
plt.show()
图像如下:
3.搭建神经网络:
我们先对现在的输入输出进行分析,30个输入其实不多,所以就设置成一个输入一个输出(之前的异或模型两个输入是为了演示而已,100以下其实都不多,一个输入就行。)
输入和隐含层之间我们就设置1个输入单元,10个隐含层单元(因为问题简单,10是最少的了),用ReLU做激活函数:
nn.Linear(1, 10),
nn.ReLU()
在隐含层和输出层之间,就是10对1的关系,因为输出集中在-1到1之间,我们可以考虑使用Tanh函数来约束输出结果:
nn.Linear(10, 1)
nn.Tanh()
那么我们完整的网络可以定义如下:
class Rnet(nn.Module):
"""
@ClassName:Rnet
@Description:用于解决回归问题的一个神经网络
@Author:段鹏浩
"""
def __int__(self):
super().__init__()
self.regress = nn.Sequential(
nn.Linear(1, 10),
nn.ReLU(),
nn.Linear(10, 1),
nn.Tanh()
)
def forword(self, x):
"""向前传播"""
pre = self.regress(x) # 获得结果
return pre
我们这里还是用类的方法,因为后面这样的方法更常用,同时我们设置一个向前传播函数可以返回输入的结果,其实也可以直接向类传值。
4.训练神经网络
(1)首先要选择好损失函数和反向传播的函数,我们使用SGD进行优化,同时损失函数使用MSELoss,其实选什么都行,只要有结果就行,现在先不用纠结这个。
net = Rnet() # 创建一个类的对象
loss_func = nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.05) # 用随机梯度下降来优化网络
因为模型简单,我们也不用分批次训练了,直接训练就行,训练1000轮
for epoch in range(1000):
out = net(x) # 先计算输出
loss = loss_func(out, y) # 计算损失
loss.backward() # 将误差反向传播准备开始优化
if epoch%10 == 0:
optimizer.zero_grad() # 每十轮清一次梯度
optimizer.step() # 开始优化
5.完整代码和效果
这是按照上面说的写出来的代码:
"""
@FileName:Regression.py
@Description:简单回归问题:预测一个sin的曲线
@Author:段鹏浩
@Time:2023/3/23 21:48
"""
import numpy as np
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
class Rnet(nn.Module):
"""
@ClassName:Rnet
@Description:用于解决回归问题的一个神经网络
@Author:段鹏浩
"""
def __init__(self):
super().__init__()
self.regress = nn.Sequential(
nn.Linear(1, 10),
nn.ReLU(),
nn.Linear(10, 1),
nn.Tanh()
)
def forward(self, x):
"""向前传播"""
pre = self.regress(x) # 获得结果
return pre
# 30个输入,从-pi到pi
x = torch.linspace(-np.pi, np.pi, 30)
x = torch.unsqueeze(x, dim=1) # 把一维的数组转为二维的
# 对应的输出:
y = np.sin(x)
net = Rnet()
loss_func = nn.MSELoss() # 损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.05) # 优化器
for epoch in range(1000):
# 训练神经网络
out = net.forward(x) # 获得结果用来计算损失
loss = loss_func(out, y) # 计算损失
loss.backward() # 反向传播准备优化
if epoch % 10 == 0:
optimizer.zero_grad() # 每10次清一次梯度
optimizer.step() # 优化
y2 = net.forward(x)
y2 = y2.data.numpy() # 返回的信息很多,需要处理和转换一下
plt.scatter(x, y)
plt.plot(x, y2, c="r")
plt.xlabel("x")
plt.ylabel("sin()")
plt.show()
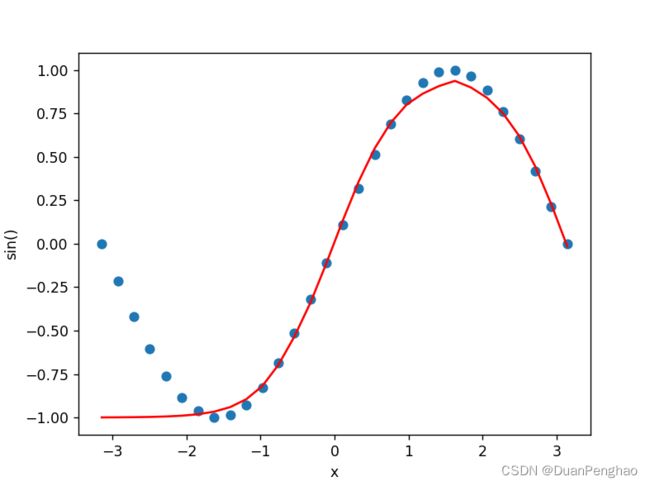
输出为:
或者是:
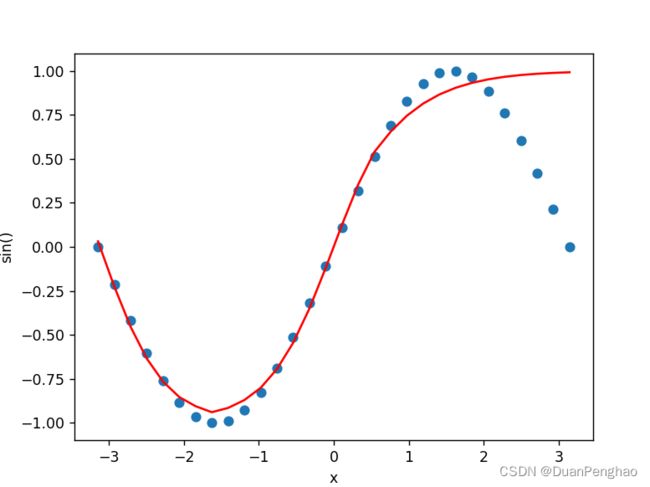
这是因为Tanh函数在数目较大时会发生梯度消失,所以会有一边欠拟合。
我们调整训练轮次为100,发现两边都欠拟合:

解决办法,既然欠拟合,那就多训练,训练10000轮:

效果很好。
另一种改进方法是,既然Tanh函数限制了输出,那我们干脆不要Tanh函数,网络成这样:
self.regress = nn.Sequential(
nn.Linear(1, 10),
nn.ReLU(),
nn.Linear(10, 1)
# nn.Tanh()
)
完整代码如下,这回还换了GPU运行,但是要注意的是输入gpu的函数,所接受的参数也必须在GPU里面,然后用完以后,用除了torch以外的库时(比如plt),参数必须挪回CPU。
"""
@FileName:Regression.py
@Description:简单回归问题:预测一个sin的曲线
@Author:段鹏浩
@Time:2023/3/23 21:48
"""
import numpy as np
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
class Rnet(nn.Module):
"""
@ClassName:Rnet
@Description:用于解决回归问题的一个神经网络
@Author:段鹏浩
"""
def __init__(self):
super().__init__()
self.regress = nn.Sequential(
nn.Linear(1, 10),
nn.ReLU(),
nn.Linear(10, 1)
# nn.Tanh()
)
def forward(self, x):
"""向前传播"""
pre = self.regress(x) # 获得结果
return pre
# 30个输入,从-pi到pi
x = torch.linspace(-np.pi, np.pi, 30)
x = torch.unsqueeze(x, dim=1) # 把一维的数组转为二维的
# 对应的输出:
y = np.sin(x)
net = Rnet().cuda()
loss_func = nn.MSELoss() # 损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.05) # 优化器
x = x.cuda() # 用到x的时候将其移入GPU
y = y.cuda()
for epoch in range(1000):
# 训练神经网络
out = net.forward(x) # 获得结果用来计算损失
loss = loss_func(out, y) # 计算损失
loss.backward() # 反向传播准备优化
if epoch % 10 == 0:
optimizer.zero_grad() # 每10次清一次梯度
optimizer.step() # 优化
y2 = net.forward(x)
y2 = y2.cpu()
y2 = y2.data.numpy() # 返回的信息很多,需要处理和转换一下
x = x.cpu() # 用torch以外的库时,必须把参数从gpu移出来
y = y.cpu()
plt.scatter(x, y)
plt.plot(x, y2, c="r")
plt.xlabel("x")
plt.ylabel("sin()")
plt.show()
输出如下:
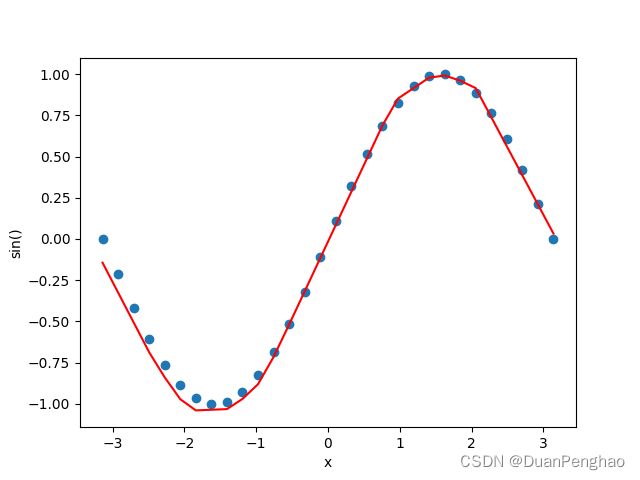
拟合的很接近,不过少了约束会偏离实际值。
加大循环到10000:

发现拟合的更好了但还是有偏离的现象,所以二者有利有弊,用Tanh约束可能会使结果在你想要的范围内,但缺点就是需要训练很多轮来防止欠拟合。如果放开的话数据会偏移,而且也容易过拟合。
而且什么时候清梯度也很重要,经过我反复测试,我发现10轮是最好的。
3.分类神经网络
1.什么是分类问题
分类是什么,大家肯定都是知道的,比如苹果和香蕉,猫和狗。其实我们之前的异或神经网络也可以称为分类问题,因为11和00是一类,01和10是一类。那为什么我之前也说异或神经网络是回归问题呢,其实分类问题的解决就是把分类变成回归。比如常见的二分类问题,我们有一堆大于200的数字和一堆小于200的数字,那我们的神经网络可以有两个输入和两个输出,如果输出为大于200的数字,则为1和0,输出为小于200的数字则为0和1。如果是三分类则是三个输入,输出分别是100,010,001(也就是对的那个输出才会在对应的通道输出1,否则就是0),这样的输出编码方式有一个特别的名字,叫做独热编码(one-hot),这是因为它是什么和1在哪里有很大的关系。当然,对于二分类问题,你也可以设置只有一个输出,0和1分别代表两种。但是记得输出可能是小数,需要规约一个范围,比如大于0.5是1,小于0.5是0。如果是三分类,那就先把二分类分好,然后先分好的两类为一类和第三类训练,但是这么做明显比先前的独热编码复杂。
2.准备数据集
准备数据集无论何时都是正式开始搞神经网络前的准备工作。我们现在需要分类的是一些有一定特点的数据,可以将他们分为一类。我们可以从大于50的数里面选30个,小于50的里面选30个,但是这里我们也可以借机学习一下什么是正态分布,用正态分布来表示。正态分布也叫做高斯分布,具有如下的特点:若随机变量X服从一个数学期望为μ、方差为σ2的正态分布,记为N(μ,σ2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。看不懂也没有关系,我们只需要知道它的数据是一个对称的分布就行,troch里面专门给我们提供了正态分布的生成函数:
torch.normal(mean, std)
其中的mean是平均值,std是标准差。这里要注意的是,输入的mean和std可以是一个数字,也可以是数组,如果mean和std同时是数组,则它们的大小必须相同。当mean和std同时只是一个数字时,返回值也是一个符合正态分布数字,当它们有一个是数组时,返回对应规模的数组。
因为神经网络的输入必须是二维以上,我们可以创建两个二维的数组,然后把它们的正太随机数表示出来作为我们的数据集(忘了什么是ones(x,y)的这里提醒一下,x代表行数,y代表每行有几个):
data1 = torch.ones(50, 2)*6 # 平均值全为6
data2 = torch.ones(50, 2) # 平均值全为1
d1 = torch.normal(data1, 1)
d2 = torch.normal(data2, 1)
既然是一个二维数组,那我们可以直接把一行作为x轴,一行作为y轴来画出散点图。完整代码如下
"""
@FileName:Classfi.py
@Description:用于分类的神经网络
@Author:段鹏浩
@Time:2023/3/24 22:08
"""
import torch
import matplotlib.pyplot as plt
data1 = torch.ones(50, 2) * 6 # 平均值全为3
data2 = torch.ones(50, 2) # 平均值全为1
d1 = torch.normal(data1, 1)
d2 = torch.normal(data2, 1)
# 用切片的方式把数据切出来
x1 = d1[:, 0]
y1 = d1[:, 1]
x2 = d2[:, 0]
y2 = d2[:, 1]
plt.scatter(x1, y1)
plt.scatter(x2, y2, c="r")
plt.show()
输出如下:

可以看到,这些数据是很明显的两类。
3.数据合并
虽然神经网络可以设置输入是多少,但是输入其实只有一个变量。很明显,我们这里的数据是两个,所以我们需要进行合并。幸运的是,合并并没有那么复杂,torch已经提供了很好的接口。
torch.cat((张量1, 张量2), 合并方式)
张量1和张量2就是我们要合并的tensor类型,合并方式一共有两种,一种是0:按列合并,另一种是1:按行合并。现在来解释一下什么是按列合并,什么是按行合并。假如我们现在有两个tensor变量一个是[0, 0, 0],一个是[1, 1, 1],如果我们要把它们合并,则:
(1)按列合并:[ [0, 0, 0],
[1, 1, 1] ]
(2)按行合并:[0, 0, 0, 1, 1, 1]
如果不填则默认按列合并,这里也建议按列合并,这样数据不会变化。
最后,我们把前面的两组数据进行合并,为了防止数据类型不一致导致的错误,这里建议加上一个.type()强制转换,转换为torch.FloatTensor类型。
torch.cat((d1, d2)).type(torch.FloatTensor)
4.计算期望输出
期望的输出很简单,我们一个设为0,一个设为1就行,那么我们可以设置两个等规模的0矩阵和1矩阵,再将其用上面的方法合并起来。因为上面我们的数据都是50行,每行的两个当x和y,所以只需要50个0和50个1的一维矩阵就行:
y1 = torch.zeros(50) # 平均值为6的输出
y2 = torch.ones(50) # 平均值为1的输出
ey = torch.cat((y1, y2)).type(torch.LongTensor)
注意,输入是Float但是输出的期望(也叫做标签)必须是Long,不然会报错
5.构建神经网络
构建神经网络我们首先需要确定输入和输出,明显,这是一个分类问题,有两种点,并且被分为2类,所以需要两种输入和两种输出。之后就是确定隐含层和输入层之间的激活函数还有隐含层和输出层之间的激活函数。
同时我们之前说过,分类问题ReLU函数很好用,所以输入和隐含层之间用它,同时我们可以注意到输出为0或者1,我们可以用Sigmoid函数把它们在输出进行约束,但是这里我们要介绍一个新的归一化函数,叫做softmax它常用于分类问题,soft是软,max是最大。故名思意,就是要找到软的最大值,什么意思呢,hardmax,硬的最大值是指一串数字里面的真正的最大值。比如123里面3最大。softmax如下,它的K代表输出节点的个数,xT代表第T个节点的输出,总的来说,它的值是一个分数,代表是一个大概的最大值。理解不了也没有关系,记住它可以把数据归一化,用来处理分类问题即可。softmax更直观的理解是,它输出的值和输出数量对应,比如我们这里有两个输出,那么这两个输出的和为100%,如果用sigmoid,则两个输出的值和可能会大于1,softmax代表了是哪个输出的概率,里面的最大值就是最可能的那个。

最后还要考虑一下隐含层的节点数,我们设置为20,和前面一样。
网络代码如下,我们还是用类的方式来表示,训练的不多也就不跑GPU了,数据移动到GPU还更费时间:
# 构建神经网络
class Cnet(nn.Module):
"""
@ClassName:Cnet
@Description:用于处理分类问题的神经网络
@Author:段鹏浩
"""
def __init__(self):
super().__init__()
self.cnet = nn.Sequential(
# 输入层和隐含层
nn.Linear(2, 20),
nn.ReLU(),
# 隐含层和输出层
nn.Linear(20, 2),
nn.Softmax(dim=1) # 这里的dim是维度,我们是2维输出,所以是1,一维就是0
)
def forward(self, x):
"""
@Description:向前传播
"""
a = self.cnet(x)
return a
6.之后就是一样的优化网络和训练
损失函数我们之前说过交叉熵损失函数在处理分类问题的时候挺好,接口是nn.CrossEntropyLoss()。
优化的方法我们还是选择使用随机梯度下降SGD。
设置好损失函数和优化器以后,就可以开始循环,循环里面还是一样的:
(1)计算误差;
(2)误差反向传播;
(3)清梯度;
(4)优化器优化。
具体代码如下,我们先设置循环100次。
# 优化网络
net = Cnet()
loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.03) # 还是随机梯度下降,学习率设置为0.03
for epoch in range(100):
out = net.forward(datas) # 计算输出
loss = loss_func(out, ey) # 计算误差
loss.backward() # 反向传播
if epoch % 10 == 0:
optimizer.zero_grad() # 还是一样的,10轮清一次梯度
optimizer.step()
7.torch.max()函数:
最后就是验证输出是否可靠了,但是我们的输出值是一些在0-1之间的小数,如何判断它是0还是1呢,以前的做法是大于0.5是1,小于0.5是0,但是softmax可能会出现两个输出都是大于0.5的,所以我们需要比较其大小,这也是softmax的精髓,就是没有绝对的1和绝对的0,而是通过比较得出结论。我们输入是一个100的二维矩阵,那输出也是与之对应的100的二维矩阵,这个输出也是与之对应的100的二维矩阵。这里我们介绍一种对torch.tensor快速检测其最大值的函数,max()。
比如我们有这么一个张量:
t1 = torch.tensor([[1, 4], [2, 3]])
输出为:
tensor([[1, 4],
[2, 3]])
max可以有如下几种用法:
(1)直接使用max(t1):
print(torch.max(t1))
将会直接返回t1里面的最大值:
tensor(4)
(2)添加参数0(和前面的cat函数一样,0代表列,1代表行):
print(torch.max(t1, 0))
他将返回每一列里面最大的那个数字是哪个,同时还会返回这个数字的位置(从0开始),并且把它们做成一个列表。
torch.return_types.max(
values=tensor([2, 4]),
indices=tensor([1, 0]))
可以看到第一列的最大值是2,第二列的最大值是4,分别在对应列的第二行和第一行
(3)那么参数1就是按行返回最大值,以及它在哪该行的哪一列:
print(torch.max(t1, 1))
torch.return_types.max(
values=tensor([4, 3]),
indices=tensor([1, 1]))
第一行最大值是4第二行最大值是3,且都在对应行的第二列。
(4)返回值可以看作是max类型的元组,那么0和1可以直接选择我们要的部分,0也就是第一部分是值,1也就是第二部分是位置。
1 ◯ \textcircled{1} 1◯返回每一列的最大值,不反回位置
print(torch.max(t1, 0)[0])
tensor([2, 4])
2 ◯ \textcircled{2} 2◯返回每一行的最大值,不反回位置
print(torch.max(t1, 1)[0])
tensor([4, 3])
3 ◯ \textcircled{3} 3◯返回每一列的最大值所在位置所组成的数组
print(torch.max(t1, 0)[1])
tensor([1, 0])
4 ◯ \textcircled{4} 4◯返回每一行的最大值所在位置所组成的数组
print(torch.max(t1, 1)[1])
tensor([1, 1])
8.验证网络
我们现在可以明白,我们的网络输出结果其实就是每一行的最大值的位置,如果在左边就是0,右边是1。那也正好和我们的期望值相同。那要怎么表示呢,其实也很简单,只需要把输出点的颜色和数字0,1挂钩就行,因为0和1其实也是代表颜色的,到时候根据位置选颜色。具体代码如下:
(1)首先我们要把输出的行的最大值数组取出来:
out = net.forward(datas)
cy = torch.max(out, 1)[1]
(2)我们让画图的时候,c=cy即可,这样颜色会根据0和1的不同而改变:
完整代码如下:
"""
@FileName:Classfi.py
@Description:用于分类的神经网络
@Author:段鹏浩
@Time:2023/3/24 22:08
"""
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
data1 = torch.ones(50, 2) * 6 # 平均值全为3
data2 = torch.ones(50, 2) # 平均值全为1
d1 = torch.normal(data1, 1)
d2 = torch.normal(data2, 1)
datas = torch.cat((d1, d2)).type(torch.FloatTensor) # 数据合并
# 期望输出
y1 = torch.ones(50)
y2 = torch.zeros(50)
ey = torch.cat((y1, y2)).type(torch.LongTensor) # pytorch中要求标签也就是期望输出类型是Long,否则会报错
# 构建神经网络
class Cnet(nn.Module):
"""
@ClassName:Cnet
@Description:用于处理分类问题的神经网络
@Author:段鹏浩
"""
def __init__(self):
super().__init__()
self.cnet = nn.Sequential(
# 输入层和隐含层
nn.Linear(2, 20),
nn.ReLU(),
# 隐含层和输出层
nn.Linear(20, 2),
nn.Softmax(dim=1)
)
def forward(self, x):
"""
@Description:向前传播
"""
a = self.cnet(x)
return a
# 优化网络
net = Cnet()
loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.03) # 还是随机梯度下降,学习率设置为0.03
# print(net.forward(datas).type(torch.FloatTensor)) # 计算输出)
for epoch in range(100):
out = net.forward(datas) # 计算输出
loss = loss_func(out, ey) # 计算误差
loss.backward() # 反向传播
if epoch % 10 == 0:
optimizer.zero_grad() # 还是一样的,10轮清一次梯度
optimizer.step()
out = net.forward(datas)
cy = torch.max(out, 1)[1]
# # 用切片的方式把数据切出来
# x1 = d1[:, 0]
# y1 = d1[:, 1]
#
# x2 = d2[:, 0]
# y2 = d2[:, 1]
x = datas[:, 0]
y = datas[:, 1]
plt.scatter(x, y, c=cy)
plt.show()
效果如下:
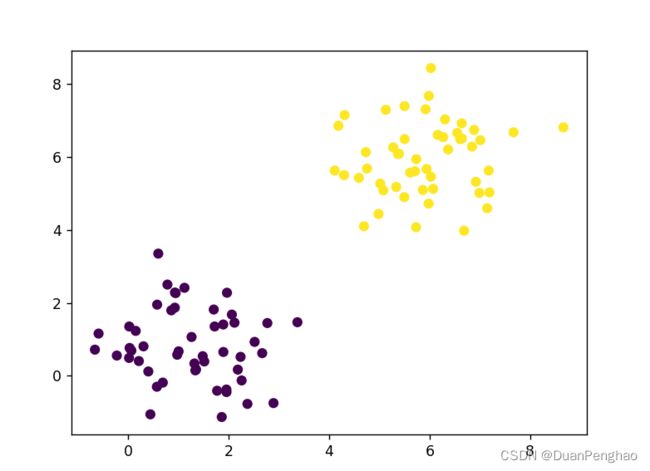
9.计算一下精确度
精确度计算其实很简单,只需要看看有多少符合预期即可,进行比较计算需要把ey和out转为numpy类型,然后看看有多少相同:
# 转换
ey = ey.data.numpy()
out = out.data.numpy()
# 计算准确率:
acc = sum(ey == out)/100 # 求出两者相同的数目然后除以总数,警告是正常的,因为python查不到类型,可以正常运行
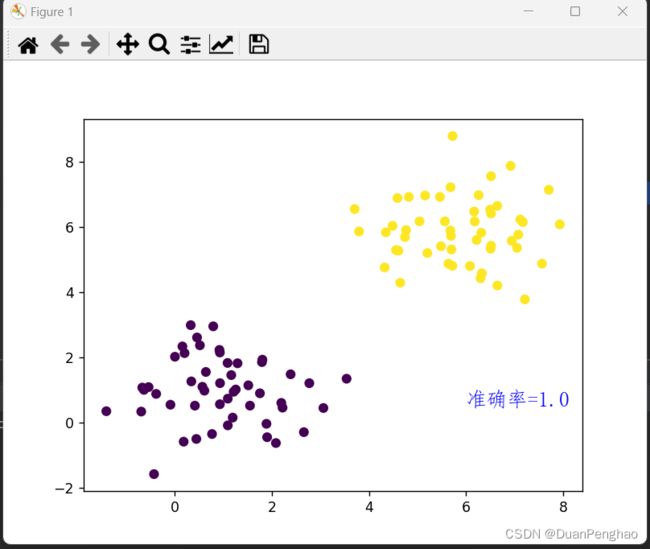
这里我们可以通过plt.text()将文本也打印在图上:
plt.text(6, 0.5, f"准确率={acc}", fontproperties='FangSong', fontdict={"size": 15, "color": "blue"})
前面两个参数是坐标,我们观察图发现右下角空着,所以选择在(8,1)位置,之后就是要显示的文本,fontdict是字体大小和颜色,显示中文必须先指定其字体哦。
输出效果如下:
如果不训练,直接跑是这样的:

因为这个全靠运气
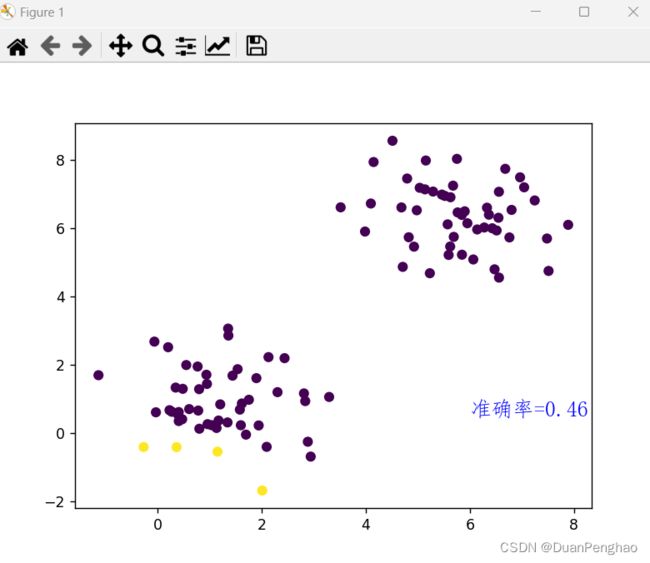
在40%-70%之间浮动,因为是猜硬币嘛,全猜测有50%的概率对,样本少的时候会在这区间上下浮动。
4.总结
本章实战了回归问题和分类问题的神经网络怎么写,提出了softmax的概念,以及如何在plt图像上展示文本。下一章我们实战一下猫狗识别。