第十二章 卷积神经网络实战--猫狗识别
1.介绍
我们已经学习了如何用传统的神经网络进行机器学习,在本章我们学习一下如何使用简单的神经网络进行图像分类。数据集用的是Kaggle的猫狗数据集。这里只有前100张,如果需要更多的可以去Kaggle官网获得,这是一个神奇的网站,你几乎可以在上面找到任何类型的数据集,你还可以找到许多经典卷积神经网络的代码和模型,比如Mobile_Net和LeNet等。用法:
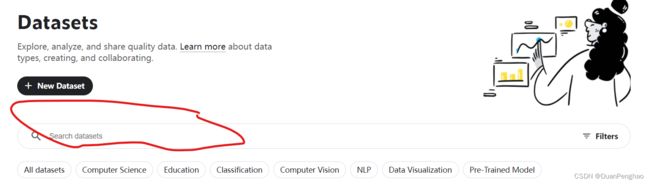
在这里搜想要什么图片(中英文都行)
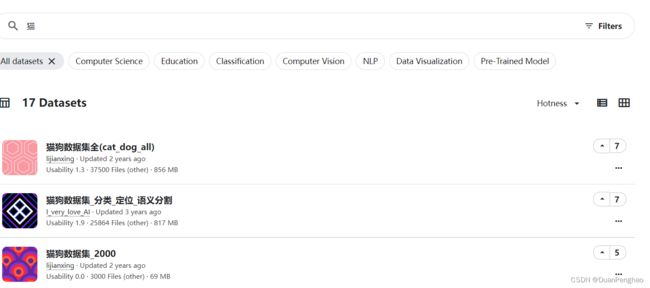
选个想要的
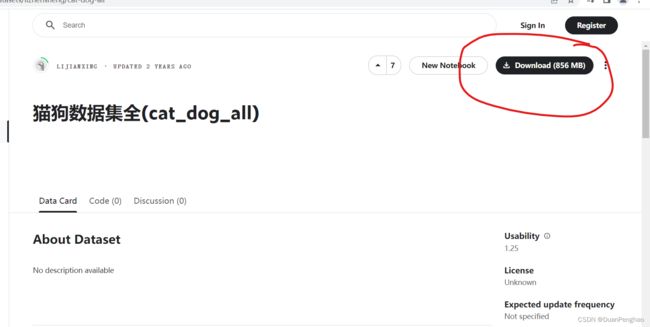
下载即可
找代码和模型就去Modle主页
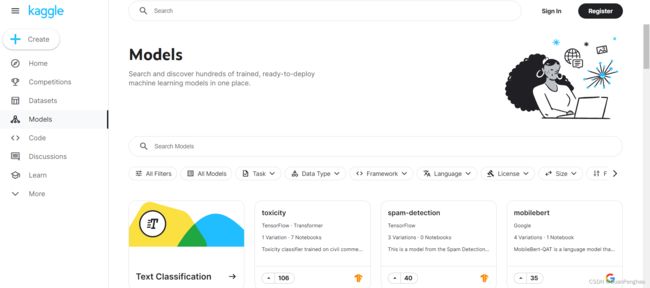
Code主页可以编程,Learn主页可以学习各种神经网络的知识,可以说这个网站是机器学习的必备。
2.猫狗识别神经网络
1.划分训练集和测试集
训练集和测试集的分法我们在第九章已经讲过,这里回忆一下。首先我们需要按照一个比例,把数据分开,常用的是7:3,之后我们要修改图片的尺寸。根据上一章的内容,我们还需要把输入合成一个,怎么把图片合成一个,在第九章其实也说了。先创建一个全零矩阵,矩阵规模是:图片数x图片通道数x图片长x图片宽。之后按照对应的规模np.reshape即可,这个在进行训练的时候才用,现在我们可以先按照比例划分数据集,这里的想法是把猫和狗的图片等分以后移动到四个文件夹中,分别是train_cat,train_dog,test_cat,test_dog。我的数据集中一共两百张图片,前100张是猫,后一百张是狗,那么我就把前70张放入train_cat,后30张放入test_cat,对狗也是一样。
"""
@FileName:cat_dog.py
@Description:猫狗识别神经网络
@Author:段鹏浩
@Time:2023/3/26 15:59
"""
import os
import cv2 as cv
import numpy as np
# 先读取出全部的图
data_path = "E:/pictures/sample" # 我的样本所在路径
datas = os.listdir(data_path)
# 因为这是对半分的,所以把猫的训练集和测试集数量,狗的训练集和测试集数量算好,因为两者都是一样的所以算一遍即可
num_of_train = int(0.7 * 0.5 * len(datas)) # 训练集数目
num_of_test = int(0.3 * 0.5 * len(datas)) # 测试集数目
# 图片尺寸
ix = 256
iy = 256
# 各个保存的路径
cat_train_path = "E:/pictures/cat_train"
cat_test_path = "E:/pictures/cat_test"
dog_train_path = "E:/pictures/dog_train"
dog_test_path = "E:/pictures/dog_test"
# 先看看路径是否存在,不存在就创建:
if not os.path.isdir(cat_train_path):
os.makedirs(cat_train_path)
if not os.path.isdir(cat_test_path):
os.makedirs(cat_test_path)
if not os.path.isdir(dog_train_path):
os.makedirs(dog_train_path)
if not os.path.isdir(dog_test_path):
os.makedirs(dog_test_path)
# 开始划分图片
# 先分猫的训练集和测试集
for i in range(num_of_train):
im_path = os.path.join(data_path, datas[i]) # 图片路径
if os.path.isfile(im_path):
img = cv.imread(im_path)
img = cv.resize(img, (ix, iy)) # 转为目标大小
name = "cat_tr" + str(i) + ".jpg"
path = os.path.join(cat_train_path, name)
cv.imwrite(path, img)
else:
print(f"路径:{im_path}不存在,读取失败")
for i in range(num_of_test):
im_path = os.path.join(data_path, datas[i+num_of_train]) # 图片路径
if os.path.isfile(im_path):
img = cv.imread(im_path)
img = cv.resize(img, (ix, iy)) # 转为目标大小
name = "cat_te" + str(i) + ".jpg"
path = os.path.join(cat_test_path, name)
cv.imwrite(path, img)
else:
print(f"路径:{im_path}不存在,读取失败")
# 再分狗的
for i in range(num_of_train):
im_path = os.path.join(data_path, datas[i+num_of_train+num_of_test]) # 图片路径
if os.path.isfile(im_path):
img = cv.imread(im_path)
img = cv.resize(img, (ix, iy)) # 转为目标大小
name = "dog_tr" + str(i) + ".jpg"
path = os.path.join(dog_train_path, name)
cv.imwrite(path, img)
else:
print(f"路径:{im_path}不存在,读取失败")
for i in range(num_of_test):
im_path = os.path.join(data_path, datas[i+num_of_train+num_of_test+num_of_train]) # 图片路径
if os.path.isfile(im_path):
img = cv.imread(im_path)
img = cv.resize(img, (ix, iy)) # 转为目标大小
name = "cat_te" + str(i) + ".jpg"
path = os.path.join(dog_test_path, name)
cv.imwrite(path, img)
else:
print(f"路径:{im_path}不存在,读取失败")
这样我们就已经成功地把数据集划分

2.搭建神经网络
第二步当然到了我们的搭建神经网络的环节。搭建卷积神经网络我们要分成两步,也就是写两个nn.Sequential(),第一个部分是卷积部分,第二个部分是全连接层,其实就是我们前面的那些网络。之所以要分开来写,是因为它们的输入是不一样。
(1)我们首先设计卷积和池化部分:
基本上需要两次卷积,卷积以后再来一次池化来压缩卷积以后的巨大体积,卷积核的尺寸可以由图片来定。公式 ( 1 s × ( n + 2 p − f ) + 1 ) × ( 1 s × ( n + 2 p − f ) + 1 ) (\frac{1}{s}\times(n+2p-f)+1)×(\frac{1}{s}\times (n+2p-f)+1) (s1×(n+2p−f)+1)×(s1×(n+2p−f)+1)很重要。我们的图片是256x256的,n就是256,那么我们假设步长s为1,我们希望的是卷积以后的尺寸不变,那么就要求: 256 + 2 p − f + 1 = 256 256+2p-f+1 = 256 256+2p−f+1=256,有多种选择,我选择让卷积核尺寸f为3,那么填充距离p就为1。
在卷积神经网络那里我们就讲过,卷积神经网络的输出数量和输入没有关系,只和卷积核的个数有关,所以我们设置每层有8个卷积核,这样输出就是8个256x256的矩阵(已经从三维变为8维)。我们设置两个一模一样的卷积层,这样输出还是8x256x256。最后用一层池化层来压缩4倍的数据,其实很简单,不填充就行,同时池化核尺寸为2x2,让其步长为2(数据的计算方法卷积核池化是一样的,用上面的公式看就行)。
所以网络前半部分是:卷积层+卷积层+池化层,卷积层每一层的步长为1,填充为1,卷积核尺寸是3;池化层步长为2,填充为0,池化核尺寸为2,层与层之间都用ReLU函数进行激活(起到一个过滤的作用)。
代码如下:
"""
@FileName:cdNet.py
@Description:猫狗识别的神经网络模型
@Author:段鹏浩
@Time:2023/4/2 12:51
"""
import torch.nn as nn
class Cat_dog_net(nn.Module):
"""
@ClassName:Cat_dog_net
@Description:猫狗识别的具体网络
@Author:段鹏浩
"""
def __init__(self):
super().__init__()
# 卷积部分
self.covNet = nn.Sequential(
# 输入层和第一个卷积层,输入是3通道的256x256,输出是通道的256x256
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
# 第一个卷积层和第二个卷积层,输入和输出是一样的
nn.Conv2d(in_channels=8, out_channels=8, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
# 最后是池化层,池化层不需要设置输入输出,因为没有这些信息它也能计算,程序员自己清楚就行
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # 最后一层就不用激活了,因为只是压缩了一下数据
)
这里面的ReLu函数上有参数inplace=True,意思是每一次使用ReLU函数以后,都用新生成的数之比去覆盖原本的内存,可以大大地节省内存的开销(不然Python会把之前的数据一直保存在内存中,每次运行都开辟新的内存)。
(2)接下来我们设计全连接层的部分:
首先我们的输入是128x128x8的矩阵,之后因为图像分类是很复杂的事情,我们需要多设计一些神经元来完成分类,所以我们就设计1000个神经元,用ReLU函数分类,用两个隐含层即可,每层之间都用ReLU函数作为激活函数,最后使用softmax来输出分类。代码如下:
# 全连接层部分
self.LinNet = nn.Sequential(
# 全连接层的输入层和第一个隐含层,输入是128x128x8的一维向量,输出是1000个神经元
nn.Linear(128*128*8, 1000),
nn.ReLU(inplace=True),
# 第一个隐含层和第二个隐含层
nn.Linear(1000, 1000),
nn.ReLU(inplace=True),
# 第二个隐含层和输出层
nn.Linear(1000, 2),
nn.Softmax(dim=1)
)
(3)向前传播:
我们这里需要处理两部分的网络输入不一致的问题,需要用到view()函数,view函数用法是这样,它可以把多维的数据转为一维,和之前的np.reshap是一样的:
tensor变量.view(tensor变量.size(0),规模)
其中tensor变量.size(0),其实代表了有多少张图片,因为训练的时候其实不是一张张输入的,之后的规模就是要展多少,比如现在我们的是128x128x8。向前传播的完整代码如下,在两个部分网络之间加上变化就行:
def forward(self, data):
"""向前传播"""
# 先是卷积部分
data = self.covNet(data)
# 接下把对应的每一个数据都变为1维
data = data.view(data.size(0), 128 * 128 * 8)
# 经过全连接层就可以得到输出
out = self.LinNet(data)
return out
(4)完整代码:
这里我们把网络单独放在一个py文件中,既方便调整也方便封装:
"""
@FileName:cdNet.py
@Description:猫狗识别的神经网络模型
@Author:段鹏浩
@Time:2023/4/2 12:51
"""
import torch.nn as nn
class Cat_dog_net(nn.Module):
"""
@ClassName:Cat_dog_net
@Description:猫狗识别的具体网络
@Author:段鹏浩
"""
def __init__(self):
super().__init__()
# 卷积部分
self.covNet = nn.Sequential(
# 输入层和第一个卷积层,输入是3通道的256x256,输出是通道的256x256
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
# 第一个卷积层和第二个卷积层,输入和输出是一样的
nn.Conv2d(in_channels=8, out_channels=8, kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
# 最后是池化层,池化层不需要设置输入输出,因为没有这些信息它也能计算,程序员自己清楚就行
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # 最后一层就不用激活了,因为只是压缩了一下数据
)
# 全连接层部分
self.LinNet = nn.Sequential(
# 全连接层的输入层和第一个隐含层,输入是128x128x8的一维向量,输出是1000个神经元
nn.Linear(128 * 128 * 8, 1000),
nn.ReLU(inplace=True),
# 第一个隐含层和第二个隐含层
nn.Linear(1000, 1000),
nn.ReLU(inplace=True),
# 第二个隐含层和输出层
nn.Linear(1000, 2),
nn.Softmax(dim=1)
)
def forward(self, data):
"""向前传播"""
# 先是卷积部分
data = self.covNet(data)
# 接下把对应的每一个数据都变为1维
data = data.view(data.size(0), 128 * 128 * 8)
# 经过全连接层就可以得到输出
out = self.LinNet(data)
return out
3.设计训练网络的代码
(1)设置好期望的输出值,我们要训练140张图片,70张猫,70张狗,我们和前面一样,70个0以及70个1作为期望输出,之后把两个合起来:
y1 = torch.zeros(70)
y2 = torch.ones(70)
y = torch.cat((y1, y2)).type(torch.FloatTensor)
(2)设置优化器和损失函数:
我们还是使用随机梯度下降法和交叉熵损失函数,这里导入网络需要两个py文件在同一个文件夹下:
import torch
from cdNet import Cat_dog_net
import torch.nn as nn
net = Cat_dog_net().cuda() # 导入网络,同时加入GPU
optimizer = torch.optim.SGD(net.parameters(), lr=0.03) # 用随机梯度下降法优化
loss_fun = nn.CrossEntropyLoss() # 交叉熵损失函数
(3)训练批次设置:
我们一共有140张图片,那么我们分四次,每次训练35张图片,同时要载入图片,我们同时使用之前的方法把35张图片集合在一起作为输入:
# 期望输出
y1 = torch.zeros(70)
y2 = torch.ones(70)
y = torch.cat((y1, y2)).type(torch.LongTensor)
all_pc = 140 # 总输入数
batch = 35 # 批次输入数
cc = 256 # 图片的尺寸
# 制作空白的容器,这里要装两个东西,一个是输入,一个是期望的输出:
# 输入的容器
x0 = np.zeros(batch * 3 * cc * cc)
x0 = np.reshape(x0, (batch, 3, cc, cc))
x0 = torch.tensor(x0).type(torch.FloatTensor).cuda() # 转为tensor类型不然不能输入网络,同时因为量大放入GPU
# 期望输出的容器
y0 = np.zeros(batch)
y0 = torch.tensor(y0).type(torch.LongTensor).cuda() # 同上
(4)开始训练:
一共训练1000次,每次称为一个epoch,每一个epoch里面其实分为4批进行训练,每一批都有35次循环来初始化输入:
cat_path = "E:/pictures/cat_train" # 猫的路径
dog_path = "E:/pictures/dog_train" # 狗的路径
cats = os.listdir(cat_path) # 有哪些猫
dogs = os.listdir(dog_path) # 有哪些狗
# 开始训练,一共跑300轮
for epoch in range(300):
# 计算一下每轮有几批,然后每一批单独计算
all_iter = int(all_pc / batch)
for iterations in range(all_iter):
# 先把输入搞进来
if iterations < all_iter / 2: # 一开始是猫
for i in range(batch):
a = iterations * batch # 计算图片的开始索引
img_path = os.path.join(cat_path, cats[a + i])
# 如果图片存在则开始填充
if os.path.exists(img_path):
img = cv.imread(img_path)
x0[i, :, :, 0] = img[:, :, 0]
x0[i, :, :, 1] = img[:, :, 1]
x0[i, :, :, 2] = img[:, :, 2]
else:
print(f"路径{img_path},不存在")
y0[i] = y[i + a] # 同时也初始化期望输出
else:
for i in range(batch):
a = int(iterations % 2) * batch # 计算图片的开始索引
img_path = os.path.join(dog_path, dogs[a + i])
# 如果图片存在则开始填充
x0.cpu() # 放入cpu才能和图片关联
if os.path.exists(img_path):
img = cv.imread(img_path)
x0[i, :, :, 0] = img[:, :, 0]
x0[i, :, :, 1] = img[:, :, 1]
x0[i, :, :, 2] = img[:, :, 2]
else:
print(f"路径{img_path},不存在")
y0[i] = y[i + a + int(all_pc / 2)] # 同时也初始化期望输出
载入之后,就和之前一样的输入,计算损失,损失反向传播,消除梯度,优化:
x0.cuda()
out = net(x0) # 计算输出
loss = loss_fun(out, y0) # 计算误差
loss.backward() # 反向传播误差
optimizer.step() # 开始优化
if epoch % 10 == 0:
optimizer.zero_grad() # 每十轮清一次梯度
(5)保存模型:
torch.save(net, "cat_dog_net.pkl")
(6)完整代码:
"""
"""
@FileName:cat_dog.py
@Description:猫狗识别神经网络的训练
@Author:段鹏浩
@Time:2023/3/26 15:59
"""
import torch
from cdNet import Cat_dog_net
import torch.nn as nn
import numpy as np
import os
import cv2 as cv
net = Cat_dog_net().cuda() # 导入网络
optimizer = torch.optim.SGD(net.parameters(), lr=0.03) # 用随机梯度下降法优化
loss_fun = nn.CrossEntropyLoss() # 交叉熵损失函数
# 期望输出
y1 = torch.zeros(70)
y2 = torch.ones(70)
y = torch.cat((y1, y2)).type(torch.LongTensor)
all_pc = 140 # 总输入数
batch = 35 # 批次输入数
cc = 256 # 图片的尺寸
# 制作空白的容器,这里要装两个东西,一个是输入,一个是期望的输出:
# 期望输出的容器
y0 = np.zeros(batch)
y0 = torch.tensor(y0).type(torch.LongTensor).cuda() # 同上,但是可以先放入GPU
cat_path = "E:/pictures/cat_train" # 猫的路径
dog_path = "E:/pictures/dog_train" # 狗的路径
cats = os.listdir(cat_path) # 有哪些猫
dogs = os.listdir(dog_path) # 有哪些狗
# 开始训练,一共跑1000轮
for epoch in range(300):
# 计算一下每轮有几批,然后每一批单独计算
all_iter = int(all_pc / batch)
for iterations in range(all_iter):
# 先把输入搞进来
if iterations < all_iter / 2: # 一开始是猫
x0 = np.zeros(batch * 3 * cc * cc)
x0 = np.reshape(x0, (batch, 3, cc, cc))
for i in range(batch):
# 输入的容器
a = iterations * batch # 计算图片的开始索引
img_path = os.path.join(cat_path, cats[a + i])
# 如果图片存在则开始填充
if os.path.exists(img_path):
img = cv.imread(img_path)
x0[i, 0, :, :] = img[:, :, 0]
x0[i, 1, :, :] = img[:, :, 1]
x0[i, 2, :, :] = img[:, :, 2]
else:
print(f"路径{img_path},不存在")
y0[i] = y[i + a] # 同时也初始化期望输出
# print(f"猫的预测:{y0}")
else:
x0 = np.zeros(batch * 3 * cc * cc)
x0 = np.reshape(x0, (batch, 3, cc, cc))
for i in range(batch):
a = int(iterations % 2) * batch # 计算图片的开始索引
img_path = os.path.join(dog_path, dogs[a + i])
# 如果图片存在则开始填充
if os.path.exists(img_path):
img = cv.imread(img_path)
x0[i, 0, :, :] = img[:, :, 0]
x0[i, 1, :, :] = img[:, :, 1]
x0[i, 2, :, :] = img[:, :, 2]
else:
print(f"路径{img_path},不存在")
y0[i] = y[i + a + int(all_pc / 2)] # 同时也初始化期望输出
# print(f"狗的预测:{y0}")
x0 = x0/255
x0 = torch.tensor(x0).type(torch.FloatTensor) # 转为tensor类型不然不能输入网络,这里先不放入GPU,因为要传值
x0 = x0.cuda()
out = net(x0) # 计算输出
loss = loss_fun(out, y0) # 计算误差
optimizer.zero_grad() # 每十轮清一次梯度
loss.backward() # 反向传播误差
optimizer.step() # 开始优化
print("\r" + f"正在训练第{epoch}轮的第{iterations}批数据", end="", flush=True)
# if epoch % 10 == 0:
if epoch % 50 == 0:
print("\n"+f"损失值为:{loss}")
torch.save(net, "cat_dog_net.pkl")
注意,图片只能存到ndarray数组里面,所以,这里生成输入数组容器变到了后面,这里就要及时清理梯度了,因为很容易陷入全局最优(只识别猫或者狗),并且训练300轮足够了。还需要注意,图片变成数组以后,需要进行归一化,只需要除以255就行,像素是255,这样简单的归一化也可以防止陷入太早局部最优。
4.测试
有了模型,我们就需要来测试一些下模型的准确率如何,用到的是前面划分好的测试集,因为不涉及训练,我们还是一样的导入之后就可以:
"""
@FileName:cat_dog_test.py
@Description:测试神经网络的准确率
@Author:段鹏浩
@Time:2023/4/2 19:45
"""
import torch
from cdNet import Cat_dog_net
import numpy as np
import cv2 as cv
import os
net = torch.load("cat_dog_net.pkl") # 导入模型
# 两组输入
cats = np.zeros(30 * 3 * 256 * 256)
cats = np.reshape(cats, (30, 3, 256, 256))
cat_path = "E:/pictures/cat_test"
cat = os.listdir(cat_path)
for i in range(30):
# 输入的容器
img_path = os.path.join(cat_path, cat[i])
# 如果图片存在则开始填充
if os.path.exists(img_path):
img = cv.imread(img_path)
cats[i, 0, :, :] = img[:, :, 0]
cats[i, 1, :, :] = img[:, :, 1]
cats[i, 2, :, :] = img[:, :, 2]
else:
print(f"路径{img_path},不存在")
cats = torch.tensor(cats).type(torch.FloatTensor).cuda() # 因为模型在GPU
dogs = np.zeros(30 * 3 * 256 * 256)
dogs = np.reshape(dogs, (30, 3, 256, 256))
dog_path = "E:/pictures/dog_test"
dog = os.listdir(dog_path)
for i in range(30):
# 输入的容器
img_path = os.path.join(dog_path, dog[i])
# 如果图片存在则开始填充
if os.path.exists(img_path):
img = cv.imread(img_path)
dogs[i, 0, :, :] = img[:, :, 0]
dogs[i, 1, :, :] = img[:, :, 1]
dogs[i, 2, :, :] = img[:, :, 2]
else:
print(f"路径{img_path},不存在")
dogs = torch.tensor(dogs).type(torch.FloatTensor).cuda()
# 两组标准结果
y1 = torch.zeros(30)
y2 = torch.ones(30)
# 计算输出
out1 = net(cats)
out2 = net(dogs)
# 转为01值
a1 = torch.max(out1, 1)[1].cpu().data.numpy()
a2 = torch.max(out2, 1)[1].cpu().data.numpy()
a3 = y1.data.numpy()
a4 = y2.data.numpy()
print(f"猫猫的识别准确率为:{sum(a1==a3)/30}")
print(f"狗狗的识别准确率为:{sum(a2 == a4)/30}")
可以看到精度很高
猫猫的识别准确率为:0.7
狗狗的识别准确率为:0.4666666666666667
不能是1的,因为我们这个网络太简单,很容易全局最优,如果你多运行几次训练的代码,你会发现每一次精度都不一样,这是我选出的最好的
5.可视化
我们要如何传入任何一张照片都可以判断呢?代码如下:
"""
@FileName:cat_or_dog.py
@Description:
@Author:段鹏浩
@Time:2023/4/2 20:18
"""
import torch
import numpy as np
import cv2 as cv
net = torch.load("cat_dog_net.pkl") # 导入模型
# 输入的容器变成1个了
data = np.zeros(1 * 3 * 256 * 256)
data = np.reshape(data, (1, 3, 256, 256))
# 读取图片,并对其进行标准化
path = "E:/pictures/dog_test/dog_te13.jpg"
# path = "E:/pictures/mycat.jpg"
img = cv.imread(path)
img = cv.resize(img, (256, 256))
# 放入容器
data[0, 0, :, :] = img[:, :, 0]
data[0, 1, :, :] = img[:, :, 1]
data[0, 2, :, :] = img[:, :, 2]
data = torch.tensor(data).type(torch.FloatTensor).cuda() # 因为模型在GPU
# 计算输出
out = net(data)
# 转为输出0和1的值
a = torch.max(out, 1)[1].cpu().data.numpy()
if a == 0:
print("这是猫")
cv.imshow("cat", img)
else:
print("这是狗")
cv.imshow("dog", img)
cv.waitKey(0)
这是效果:
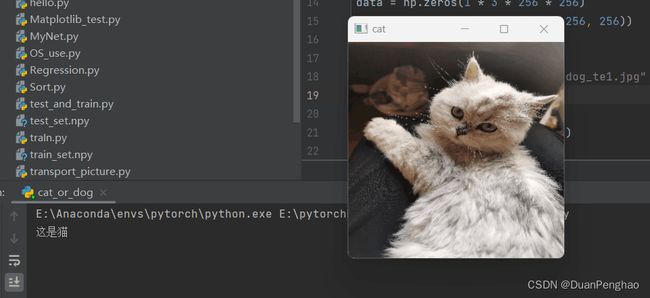
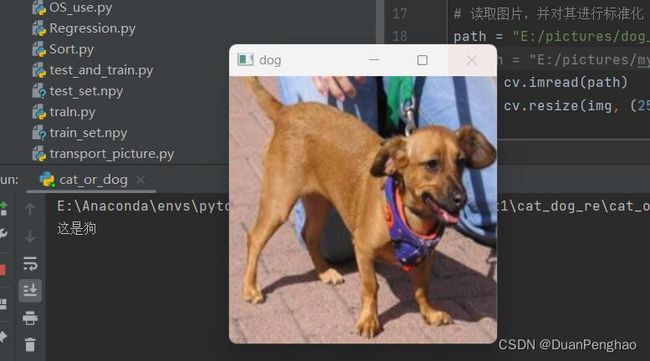
当然,刚刚说了,这个精度没有百分百,所以出现下面情况是正常的:
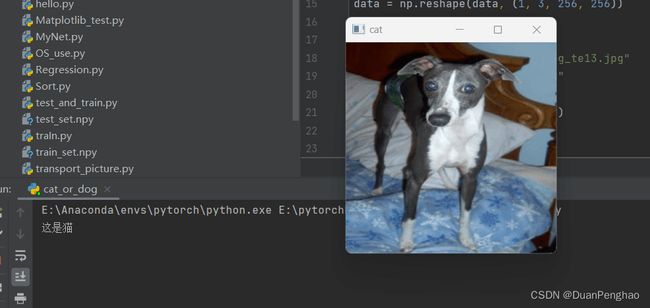
3.总结
本章使用卷积神经网络完成了一个简单的猫狗识别模型的构建,缺点是识别精度不高,若想提高精度,可以尝试复杂化神经网络,也可以尝试增加训练的数据集图片数量。后面我们会介绍一些常用的复杂神经网络。