函数式接口
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
咱们今天讨论下函数式接口
以Predicate为例,之前在分析山寨Stream API时,我们已经不知不觉使用过函数式接口:
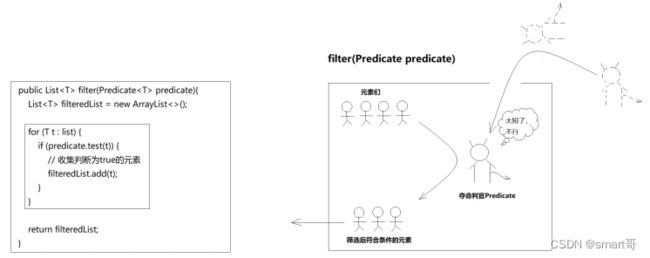
// 1.用Lambda表达式实现Predicate接口的抽象方法test(),并赋值给函数式接口
Predicate ifHigherThan180 = user -> user.getHeight()>180;
// 2.作为参数传入filter(Predicate ifHigherThan180),filter()会在内部调用test()用来判断
ifHigherThan180.test(user); 总的来说,就是把方法A(Lambda)传给方法B(filter),然后在方法B内部调用方法A完成一些操作:
public void methodB(method a) {
// 操作1
// 调用method a
// 操作3
}我们可以理解为Java8支持传递方法(之前只能传递基本数据类型和引用类型),也可以按原来面向对象的思维将Lambda理解为“特殊的匿名对象”。
为什么函数式接口很重要
有些同学应该会有疑问:
函数式接口有什么好讲的,我们不是在《Lambda表达式》中学过了吗?
不,当时只是向大家介绍了函数式接口的定义:
有且仅有一个抽象方法的接口(不包括默认方法、静态方法以及对Object方法的重写)
就我个人学习体会来看,函数式接口虽然不难,但作为参数类型出现时,经常会让初学者感到无所适从,甚至不知道该传递什么。比如Stream API中就大量使用了函数式接口接收形参:

CompletableFuture中也大量使用了函数式接口:
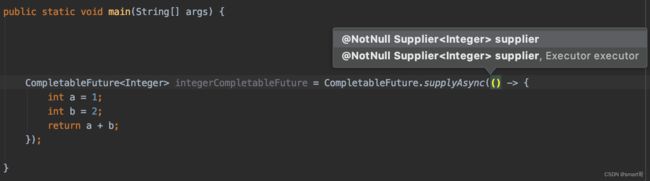
不知道大家是否曾经在调用filter()、supplyAsync()等方法时感到迷茫,起码我刚接触Java8时,每次调用这些方法都力不从心,不知道该传什么进去,也不知道Lambda表达式该怎么写。
如果你问我函数式接口难吗,我大概率会告诉你,它本身很简单。但如果你问我函数式接口重要吗,我会告诉你,它非常非常重要,能否熟练使用Java8的诸多新特性(Stream、CompletableFuture等)取决于你对函数式接口的熟悉程度。
函数式接口的类型
根据方法的出入参类型不同,各种排列组合后,其实有很多种类型,最常用的有以下4种函数式接口:
public class FunctionalInterfaceTest {
/**
* 给函数式接口赋值的格式:
* 函数式接口 = 入参 -> 出参/制造出参的语句
*
* @param args
*/
public static void main(String[] args) {
FunctionalInterface1 interface1 = str -> System.out.println(str);
FunctionalInterface2 interface2 = () -> {
return "abc";
};
FunctionalInterface3 interface3 = str -> Integer.parseInt(str);
FunctionalInterface4 interface4 = str -> str.length() > 3;
}
/**
* 消费型,吃葡萄不吐葡萄皮:有入参,无返回值
* (T t) -> {}
*/
interface FunctionalInterface1 {
void method(String str);
}
/**
* 供给型,无中生有:没有入参,却有返回值
* () -> T t
*/
interface FunctionalInterface2 {
String method();
}
/**
* 映射型,转换器:把T转成R返回
* T t -> R r
*/
interface FunctionalInterface3 {
int method(String str);
}
/**
* 特殊的映射型:把T转为boolean
* T t -> boolean
*/
interface FunctionalInterface4 {
boolean method(String str);
}
}
大家看,以上函数式接口是我自定义瞎写的,但牢牢把握了住了出入参的特点(接口名、方法名不重要),代表了4种不同的函数式接口。正因为各自出入参不同,导致Lambda表达式的写法也不同。
函数式接口的作用
实际开发中,出入参类型的排列组合是有限的,所以JDK干脆内置了一部分函数式接口。一般来说,我们只需熟练掌握以下4大核心函数式接口即可:
- 消费型接口 Consumer
void accept(T t) - 供给型接口 Supplier
T get() - 函数型接口 Function
- 断定型接口 Predicate
boolean test(T t)
为什么JDK要在Java8这个版本引入函数式接口,并且提供这么多内置接口呢?
其实这些接口本不是给我们用的,而是JDK自己要用。
还记得前几章我编写的山寨Stream API吗?为了顺利构造出山寨Stream API,我自定义了Predicate接口和Function接口:
/**
* 新建Predicate接口
*
* @param
*/
@FunctionalInterface
interface Predicate {
/**
* 定义了一个test()方法,传入任意对象,返回true or false,具体判断逻辑由子类实现
*
* @param t
* @return
*/
boolean test(T t);
}
// Function接口 略... 同样的,我和Java8一样,也把Predicate接口作为形参类型(详见myPrint方法):
public class MockStream {
public static void main(String[] args) {
Person bravo = new Person("bravo", 18);
// 1.匿名对象,调用它的test()方法
Predicate predicate1 = new Predicate() {
@Override
public boolean test(Person person) {
return person.getAge() < 18;
}
};
myPrint(bravo, predicate1); // false
// 2.Lambda表达式,调用它的test()方法。
// 按照Lambda表达式的标准,只要你是个函数式接口,那么就可以接收Lambda表达式
Predicate predicate2 = person -> person.getAge() == 18;
myPrint(bravo, predicate2); // true
}
public static void myPrint(Person person, Predicate filter) {
if (filter.test(person)) {
System.out.println("true");
} else {
System.out.println("false");
}
}
} JDK之所以要在Java8内置那么多函数式接口,本质原因和我的山寨Stream API一样,是为了配合Java8的各种API。单独发布Stream API和CompletableFuture是不现实的,它们的方法形参都依赖函数式接口呢。
Java8函数式接口的作用和我们自定义的Predicate接口一样:
- 接收Lambda表达式/方法引用
- 占坑
或者说,这两个作用是一体两面的。
所谓占坑,之前已经提过了,这里再说一下吧。
比如新冠病毒爆发时,我们需要对潜在感染者进行检测,但检测的手段有很多,比如CT和核酸测试。
虽然定义getHealthPerson()时并不确定实际会采用哪种方式进行新冠检测,可能是CT也可能是核酸测试,具体由子类实现。但不管怎么说,有一点是肯定的:一定要测试。
此时如果创建一个函数式接口,定义boolean test()方法,并将getHealthPerson()的形参定为getHealthPerson(List
/**
* 用Predicate占坑
* @param uncheckPersonList
* @param predicate
* @return
*/
public static List getHealthPerson(List uncheckPersonList, Predicate predicate) {
ArrayList healthyPersonList = new ArrayList<>();
for (Person person : uncheckPersonList) {
// 占坑,反正需要检测,但是具体拍CT还是核酸检测具体情况具体分析
if (predicate.test(person)) {
healthyPersonList.add(person);
}
}
return healthyPersonList;
} 此后如果有其他方法调用getHealthPerson(),必须传入具体的检测手段:
public static void main(String[] args) throws JsonProcessingException {
ArrayList uncheckPersonList = new ArrayList<>();
uncheckPersonList.add(new Person("张三", 18));
uncheckPersonList.add(new Person("李四", 20));
// 传入Lambda表达式
getHealthPerson(uncheckPersonList, person -> 核酸检测(person));
getHealthPerson(uncheckPersonList, person -> 胸部CT(person));
} 这就是函数式接口的作用。
如何克服面向对象的思维惯性
对于函数式接口,上面已经讲得很多了,本身很简单,没什么好介绍的。这里主要聊一聊初学者应该如何习惯函数式接口传参的方式,以及关注点应该放哪里。换句话说,帮助初学者克服面向对象的思维惯性,学会用函数式编程的思维去使用Java8的诸多特性。
还是以Predicate为例,它唯一的抽象方法是:
boolean test(T t);假设有个方法叫:getHealthPerson(List
很多Java程序员会对这种传参形式感到眩晕,因为我们的潜意识一直无法摆脱面向对象的影响。当你看到getHealthPerson(List
但之前介绍Python的函数时,我们很自然就接受了:
# encoding: utf-8
# abs是Python的内置函数
result = abs(-1)
print(result)
# 定义add()方法,f显然是一个函数
def add(x, y, f):
return f(x) + f(y)
print(add(-1, -2, abs))因为相比Python这些原本就支持函数式编程的语言来说,形参就是函数,不需要用接口做中间层过渡!而对于Stream这种面向对象世界中的异类,Java程序员还没准备好如何接纳它,看到接口形参第一时间想到的还是传匿名对象,突然要改成Lambda确实有点棘手,因为我们对接口内部的方法及出入参一概不知!
如何克服呢?两种方式:
- 以面向对象的思维直接new匿名对象,靠IDEA优化成Lambda(曲线救国,减少记忆负担)
- 每个函数式接口就一个方法,记住那个方法的出入参,看到接口就写对应方法的Lambda(需要记忆)
这里主要讲讲如何记忆函数式接口的方法。一定要注意,函数式接口的方法名字不重要,重要的是出入参:
- 消费型接口 Consumer
T t -> void 例:x -> System.out.println(x) - 供给型接口 Supplier
() -> T t 例:() -> {return 1+2;} - 映射型接口 Function
- 断定型接口 Predicate
T t -> boolean 例:user -> user.getAge()>18
Consumer,消费型接口,是黑洞,只管吃(C),不会往外吐,所以只有入参,没有返回值。
Supplier,供给型接口,是泉眼,不断往外涌出泉水(S),不需要入参,有返回值。
Function,映射型接口,就是高中数学的函数映射,x --> f(x) --> result,所以有入参,也有返回值。
Predicate,断定型接口,是特殊的映射函数,x --> f(x) --> boolean,只会评(P)论true/false。
如果你觉得口诀很生硬,就把上面的例子记住,把每个函数式接口都和一个例子绑定,实际开发时去套用例子即可。
记住了接口对应的出入参,Lambda就好办了,其实传递的都是:
接口声明 = 入参 -> 出参/制造出参的语句
不信你可以重新看看上面给出的例子,比如Function:user -> user.getAge(),就是把User user映射为Integer age,user是入参,user.getAge()是制造出参的语句。又比如Predicate:user -> user.getAge()>18,user是入参,user.getAge()>18就是制造出参的语句,因为boolean test(T t)需要返回boolean。
所以要习惯函数式接口传参,最重要的是记住该接口对应的方法的出入参,然后编写Lambda时套用模板:
接口声明 = 入参(有无入参?) -> 出参/制造出参的语句(有无出参?什么类型?)
虽然我们还没正式学习Stream API,但已经可以试着写写啦:
public class FunctionalInterfaceTest {
public static void main(String[] args) {
List list = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6));
/**
* Predicate:特殊映射,只断是非 Function:T t --> f(x) --> boolean
* Function:映射 Function:T t --> f(x) --> R r
*/
list.stream().filter().map().collect(Collectors.toList());
// Supplier,无源之水(S),却滔滔不绝,没有入参,却可以get()
CompletableFuture 私底下多写几次,形成肌肉记忆就好啦。我们走路时,虽然确实有一个规则:左右脚要交替向前,但我们实际行走时从来不会意识到这个规则,否则就走太慢了!
函数式接口与类型推断
之前在《Lambda表达式》中,我举过一个例子:

当接口内只有一个抽象方法时,可以使用Lambda表达时给接口赋值:
MyInterface interface = () -> System.out.println("吃东西");
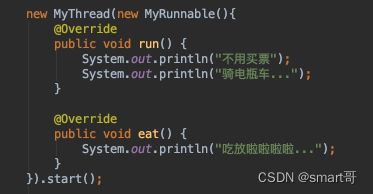
但如果函数式接口内有多个方法抽象方法,就无法传递Lambda表达式:


此时只能传入匿名对象分别实现两个抽象方法:
学完这一章,相信大家会有更深刻的理解:
public void run()和public void eat()如果只看出入参,其实是一样的,所以编译时无法自动推断。
由于本章节一直在强调函数式接口传参,所以这里再给出一个例子:
public class FunctionalInterfaceTest {
public static void main(String[] args) {
// Ambiguous method call
lambdaMethod(() -> System.out.println("test"));
}
/**
* 方法重载
*
* @param param1
*/
public static void lambdaMethod(Param1 param1) {
param1.print();
}
/**
* 方法重载
*
* @param param2
*/
public static void lambdaMethod(Param2 param2) {
param2.print();
}
/**
* 函数式接口1
*/
interface Param1 {
void print();
}
/**
* 函数式接口2
*/
interface Param2 {
void print();
}
}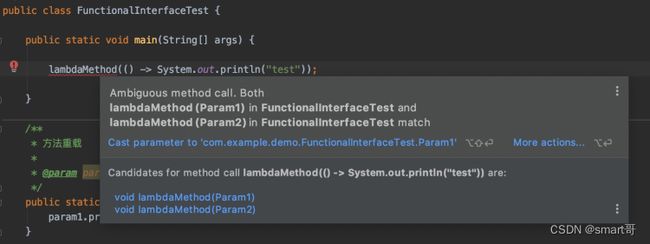
原因也是一样的,Lambda只关注方法的出入参,所以在进行类型推断时,interface Param1和interface Param2是一样的,编译器无法替我们决定实现哪一个接口,解决办法是使用匿名对象。
如果说《Lambda表达式》中举的例子是方法级别的推断冲突,那么上面的例子讲的就是接口级别的推断冲突,但归根结底就一句话:Lambda上下文推断只看出入参,无论是接口名还是方法名,都不重要!
所以,学习函数式接口最重要的就是记住出入参的格式!!
回顾ConvertUtil
之前在《实用小算法》中我们封装过一个工具类,当时大家可能对于函数式接口并不熟悉,现在重新复习一下,看看自己能否完全理解这个工具类的设计细节:
public class ConvertUtil {
private ConvertUtil() {
}
/**
* 将List转为Map
*
* @param list 原数据
* @param keyExtractor Key的抽取规则
* @param Key
* @param Value
* @return
*/
public static Map listToMap(List list, Function keyExtractor) {
if (list == null || list.isEmpty()) {
return new HashMap<>();
}
Map map = new HashMap<>(list.size());
for (V element : list) {
K key = keyExtractor.apply(element);
if (key == null) {
continue;
}
map.put(key, element);
}
return map;
}
/**
* 将List转为Map,可以指定过滤规则
*
* @param list 原数据
* @param keyExtractor Key的抽取规则
* @param predicate 过滤规则
* @param Key
* @param Value
* @return
*/
public static Map listToMap(List list, Function keyExtractor, Predicate predicate) {
if (list == null || list.isEmpty()) {
return new HashMap<>();
}
Map map = new HashMap<>(list.size());
for (V element : list) {
K key = keyExtractor.apply(element);
if (key == null || !predicate.test(element)) {
continue;
}
map.put(key, element);
}
return map;
}
/**
* 将List映射为List,比如List personList转为List nameList
*
* @param originList 原数据
* @param mapper 映射规则
* @param 原数据的元素类型
* @param 新数据的元素类型
* @return
*/
public static List resultToList(List originList, Function mapper) {
if (originList == null || originList.isEmpty()) {
return new ArrayList<>();
}
List newList = new ArrayList<>(originList.size());
for (T originElement : originList) {
R newElement = mapper.apply(originElement);
if (newElement == null) {
continue;
}
newList.add(newElement);
}
return newList;
}
/**
* 将List映射为List,比如List personList转为List nameList
* 可以指定过滤规则
*
* @param originList 原数据
* @param mapper 映射规则
* @param predicate 过滤规则
* @param 原数据的元素类型
* @param 新数据的元素类型
* @return
*/
public static List resultToList(List originList, Function mapper, Predicate predicate) {
if (originList == null || originList.isEmpty()) {
return new ArrayList<>();
}
List newList = new ArrayList<>(originList.size());
for (T originElement : originList) {
R newElement = mapper.apply(originElement);
if (newElement == null || !predicate.test(originElement)) {
continue;
}
newList.add(newElement);
}
return newList;
}
// ---------- 以下是测试案例 ----------
private static List list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
Map nameToPersonMap = listToMap(list, Person::getName);
System.out.println(nameToPersonMap);
Map personGt18 = listToMap(list, Person::getName, person -> person.getAge() >= 18);
System.out.println(personGt18);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
} 小试牛刀
实际开发中,经常会看到这样的写法:
public void XxMethod(){
// ...
List iidList = new ArrayList<>();
List eventList = new ArrayList<>();
if(items != null && items.size > 0) {
for(Item item : items){
iidList.add(item.getId());
eventList.add(item.getEvent());
}
}
// ...
} 这里能用ConvertUtil的resultToList()吗?
答案是,不能。resultToList()一次只处理一个List,而上面一次循环可能处理N个List。所以我们能做的,只是抽取循环的操作,具体循环里做什么,每个List可能不同,不好抽取。
有了上面的经验,我们完全可以再给ConvertUtil封装个方法:
/**
* foreach,内部判空
*
* @param originList 需要遍历的List
* @param processor 需要执行的操作
* @param
*/
public static void foreachIfNonNull(List originList, Consumer processor) {
if (originList == null || originList.isEmpty()) {
return;
}
for (T originElement : originList) {
if (originElement != null) {
processor.accept(originElement);
}
}
} public void XxMethod(){
// ...
List iidList = new ArrayList<>();
List eventList = new ArrayList<>();
ConvertUtil.foreachIfNonNull(items, item -> {
iidList.add(item.getId());
eventList.add(item.getEvent());
})
// ...
} 上面相当于自己实现了foreach。你可能会想,为什么不直接用Stream API或者直接List.foreach()?原因在于它们都要额外判断非空,否则可能引发NPE。
最后留个思考题:自己实现groupBy()。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬