具身智能17篇创新性论文及代码合集,2023最新
今天来聊聊人工智能领域近期的一个热门研究方向——具身智能。
具身智能(Embodied Intelligence)指的是机器人或智能体通过感知、理解和交互来适应环境,并执行任务的能力。与传统的基于规则或符号的人工智能不同,具身智能强调将感知和行动相结合,使智能体能够更好地理解其周围的环境和与环境的互动。
具身智能被认为是通往通用人工智能的重要途径,目前有关它的研究也已经有了很多突破性进展,比如李飞飞团队的VoxPoser系统。
我这回简单整理了17篇具身智能创新性工作相关的论文,都是今年最新,只做了简单介绍,建议大家查看原文仔细研读。
论文原文及代码需要的同学看文末
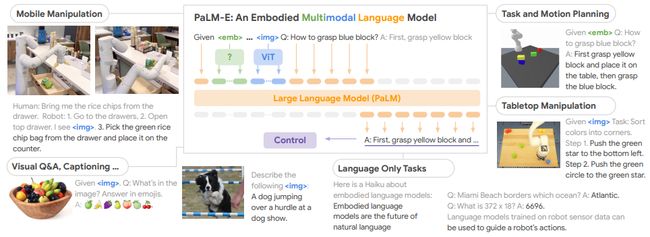
1.PaLM-E: An Embodied Multimodal Language Model
一个具身多模态语言模型
简述:论文提出了一个具身多模态语言模型,通过将真实世界的连续传感器模态直接融入语言模型中,实现了单词和感知之间的联系。实验结果表明,PaLM-E可以处理来自不同观察模态的各种具身推理任务,并在多个实现上表现出良好的效果。最大的PaLM-E-562B模型拥有562亿个参数,除了在机器人任务上进行训练外,还是一个视觉语言通才,并在OK-VQA任务上取得了最先进的性能。
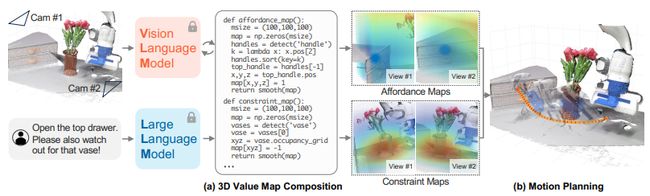
2.VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
采用语言模型实现机器人操作的可组合3D价值图
简述:论文提出了一种名为VoxPoser的方法,利用大型语言模型和视觉语言模型来合成机器人轨迹。作者发现,LLM可以通过自然语言指令推断出环境和物体的能力和限制,并通过与VLM交互来组合3D值图,将知识转化为代理的观察空间。这些组合的值图然后被用于基于模型的规划框架中,以零样本合成闭环机器人轨迹,并对动态扰动具有鲁棒性。
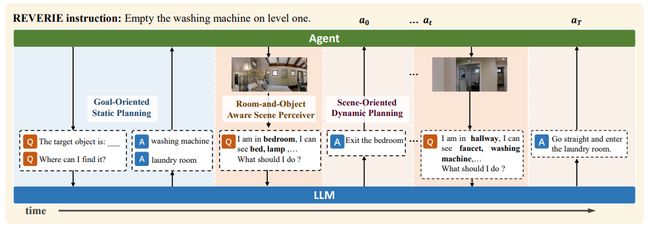
3.March in Chat: Interactive Prompting for Remote Embodied Referring Expression
远程具身指代表达的交互提示
简述:论文提出了一种名为March-in-Chat的模型,可以在REVERIE环境中与大型语言模型进行交互并动态规划。REVERIE任务只提供高级指令给代理,类似于人类的实际命令,因此比其他VLN任务更具挑战性。MiC模型通过ROASP实现了环境感知和动态规划,可以基于新的视觉观察调整导航计划,并且能够适应更大、更复杂的REVERIE环境。
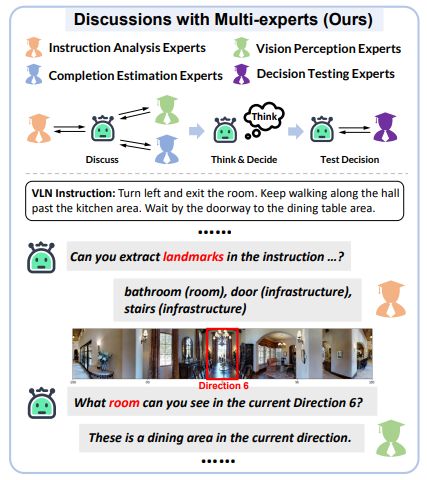
4.Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions
通过多专家讨论实现视觉语言导航
简述:论文提出了一种零样本视觉语言导航框架DiscussNav,通过多专家讨论来帮助代理进行导航。作者认为现有的VLN方法完全依赖单一模型自身的思考来进行预测,而即使是最先进的大型语言模型GPT4,在单轮自我思考中仍然难以处理多个任务。因此,作者借鉴了专家咨询会议的思想,将具有不同能力的大模型作为领域专家,让代理在每一步移动之前与这些专家积极讨论,收集关键信息。实验结果表明,该方法可以有效地促进导航,感知与指令相关的信息,纠正意外错误并筛选出不一致的运动决策。
5.Skill Transformer: A Monolithic Policy for Mobile Manipulation
用于移动操作的单体策略
简述:论文提出了Skill Transformer,一种结合条件序列建模和技能模块性来解决长视野机器人任务的方法。该方法在机器人的自适应和感知观察上基于条件序列模型,并通过训练使用Transformer架构和演示轨迹来预测机器人的高级技能(如导航、选择、放置)和整体低级动作(如基座和手臂运动)。它保留了整个任务的可组合性和模块性,通过一个技能预测模块来推理低级动作并避免常见于模块化方法的传递误差。
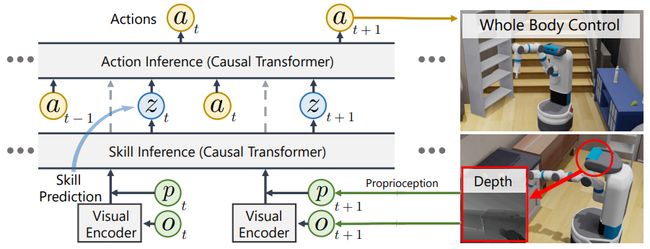
6.See to Touch: Learning Tactile Dexterity through Visual Incentives
通过视觉激励学习触觉灵活性
简述:论文提出了一种名为Tactile Adaptation from Visual Incentives (TAVI)的新框架,通过使用视觉奖励来优化基于触觉的灵巧性策略,从而提高多指机器人的精确度、丰富性和灵活性。在六个具有挑战性的任务中,TAVI使用四指Allegro机器人手实现了73%的成功率,比使用基于触觉和视觉奖励的策略提高了108%,比不使用基于触觉观察输入的策略提高了135%。
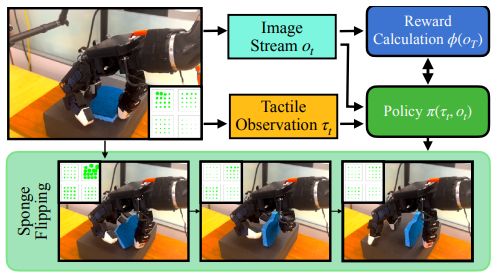
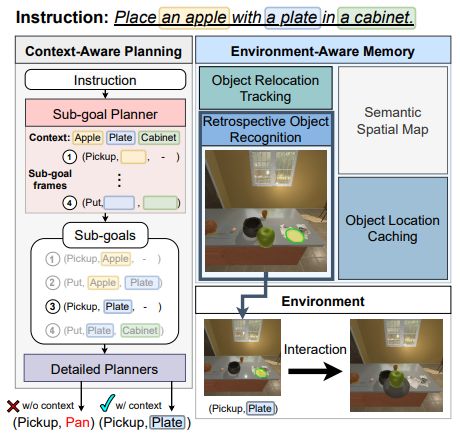
7.Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
用于执行指令的具身代理的上下文感知规划和环境感知记忆
简述:论文提出了一种CAPEAM方法,用于改善具身代理在视觉导航和对象交互方面的表现。该方法考虑了执行动作的后果,并将语义上下文和已交互物体的状态变化纳入一系列动作中,以推断后续动作。实验证明,该方法在各种指标上实现了最先进的性能,并在未见过的环境中获得了大幅提高。
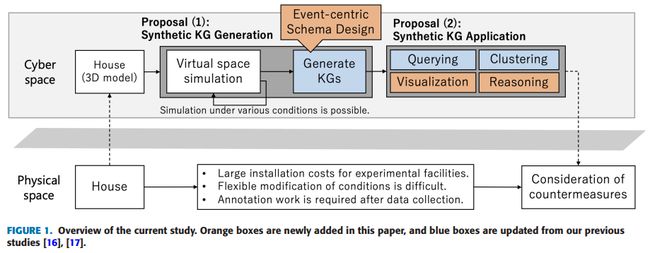
8.Synthesizing Event-Centric Knowledge Graphs of Daily Activities Using Virtual Space
使用虚拟空间合成以事件为中心的日常活动知识图谱
简述:论文提出了一种新框架VirtualHome2KG,用于在虚拟空间中生成日常生活活动的合成知识图谱。该框架基于提出的事件为中心的模式和虚拟空间模拟结果,扩展了日常生活活动的合成视频数据和与视频内容相对应的上下文语义数据。因此,可以分析上下文感知的数据,并开发各种传统上由于相关数据的不足和语义信息不足而难以开发的应用。
9.Conditionally Combining Robot Skills using Large Language Models
使用大型语言模型有条件地组合机器人技能
简述:论文提出了两个贡献。首先,介绍了一个名为“Language-World”的Meta-World基准扩展,允许大型语言模型在模拟机器人环境中使用自然语言查询和脚本化技能进行操作。其次,引入了一种称为计划条件行为克隆(PCBC)的方法,可以使用端到端演示微调高级计划的行为。使用Language-World,表明PCBC能够在各种少数情况中实现强大的性能,通常只需要单个演示即可实现任务泛化。
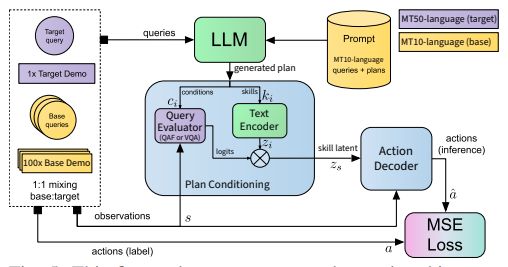
10.HoloBots: Augmenting Holographic Telepresence with Mobile Robots for Tangible Remote Collaboration in Mixed Reality
使用移动机器人增强全息远程呈现,实现混合现实下的可感知远程协作
简述:论文介绍了一种名为HoloBots的混合现实远程协作系统,使用同步移动机器人增强全息远程呈现。通过该系统,远程用户可以与本地用户及其环境进行物理互动,实现可感知远程协作。该系统使用了Hololens 2和Azure Kinect等技术,并通过实验证明其可以显著增强共现感和共享体验的水平。
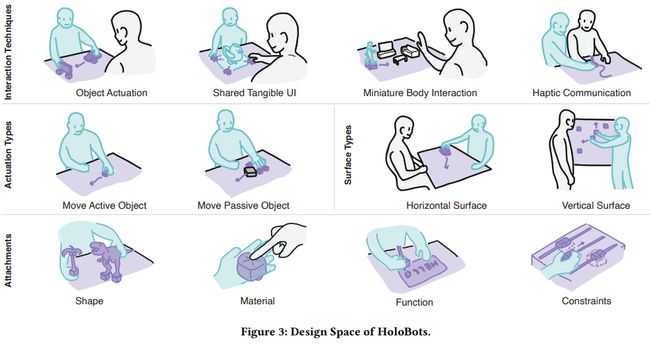
11.Building and Testing a General Intelligence Embodied in a Humanoid Robot
构建和测试具有人形机器人的通用智能系统
简述:论文提出了一种构建和测试具有人类水平智能的机器的方法。该方法包括一个物理人形机器人系统、一种基于软件的控制系统、一个名为g+的性能指标,用于衡量人形机器人的类人智能,以及一种用于逐步提高该性能指标分数的进化算法。作者介绍了每个部分的当前状况,并报告了该系统的当前和历史g+指标测量结果。
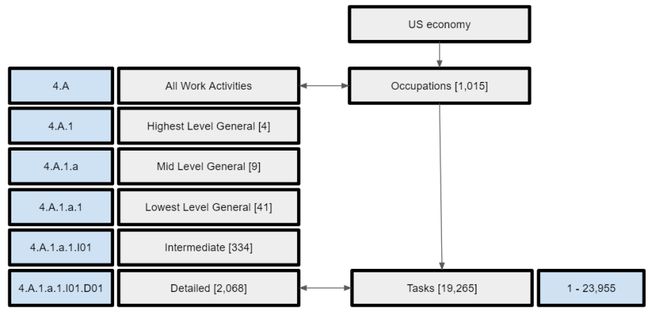
12.Systematic Adaptation of Communication-focused ML from Real to Virtual for HRC
面向HRC的从真实到虚拟的以通信为中心的机器学习的系统化适应
简述:论文提出了一个系统化框架,将经过训练的深度学习模型从真实环境适应到虚拟环境中,以实现协作机器人的体现遥操作。为了实现这一目标,需要创建大型标记数据集,以便保持易于学习和灵活的工作环境界面,并添加更多手势。虽然手部姿势被认为是通信方式,但这些指南和建议是通用的,适用于其他模式,例如在真实领域中具有大型数据集的身体姿势和面部表情,这些必须适应到虚拟环境中。
13.ChatGPT for Robotics: Design Principles and Model Abilities
机器人的ChatGPT:设计原则和模型能力
简述:论文介绍了一种使用ChatGPT进行机器人应用的实验研究。作者提出了一种结合设计原则和高级别函数库的策略,使ChatGPT能够适应不同的机器人任务、模拟器和外形因素,重点评估了不同的提示工程技巧和对话策略对于执行各种类型的机器人任务的有效性,探索了ChatGPT使用自由形式对话、解析XML标签和合成代码的能力,以及使用特定于任务的提示函数和通过对话进行闭环推理的能力。

14.Learning Hierarchical Interactive Multi-Object Search for Mobile Manipulation
学习分层交互式多目标搜索用于移动操作
简述:论文提出了一种新的交互式多目标搜索任务,要求机器人在导航房间的同时打开门并在橱柜和抽屉中搜索目标物体。为此,作者开发了一种分层强化学习方法,可以学习组合探索、导航和操纵技能。实验证明,这种方法可以在准确的感知下有效地转移到新环境中,并表现出对未见过的策略、执行失败和不同机器人运动学的鲁棒性。这些能力为一系列涉及嵌入式AI和现实世界用例的下游任务打开了大门。
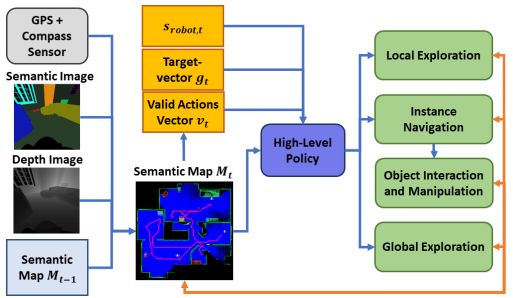
15.Robotic Manipulation Network (ROMAN) – Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
机器人操作网络(ROMAN)-解决复杂顺序任务的混合分层学习
简述:论文提出了一种混合分层学习框架——机器人操作网络(ROMAN),用于解决机器人操纵中的多个复杂任务在长时间范围内的难题。通过整合行为克隆、模仿学习和强化学习,ROMAN实现了任务的多功能性和鲁棒性失败恢复。它由一个中央操纵网络组成,协调各种神经网络的集合,每个网络专门从事不同的可重新组合的子任务,以生成正确的连续动作来解决复杂的长期操纵任务。
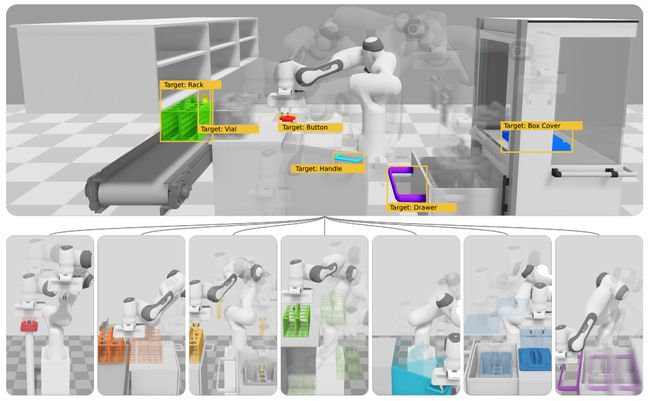
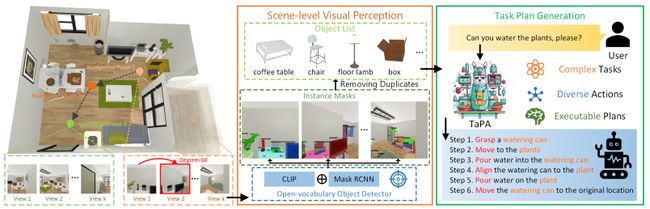
16.Embodied Task Planning with Large Language Models
基于大型语言模型的具身任务规划
简述:本研究提出了一种名为TAsk Planing Agent(TaPA)的基于场景约束的具身任务规划方法,用于在真实世界中生成可执行的计划。该方法通过将大型语言模型与视觉感知模型对齐,根据场景中已存在的对象生成可执行计划。另外,作者还构建了一个多模态数据集,并使用GPT-3.5生成了大量的指令和相应的计划动作。
17.Statler: State-Maintaining Language Models for Embodied Reasoning
用于具身推理的状态维护语言模型
简述:论文提出了一种名为Statler的框架,用于赋予大型语言模型(LLM)对世界状态的显式表示,可以随着时间的推移进行维护。通过使用两个通用LLM实例——世界模型阅读器和世界模型写入器——与世界状态进行交互和维护,Statler提高了现有LLM在较长时间范围内推理的能力,而不受上下文长度的限制。

关注下方《学姐带你玩AI》
回复“具身智能”领取论文原文及源码
码字不易,欢迎大家点赞评论收藏!