两万字长文详细【C++11 新特性】
C++11 新特性
1、关键字explicit
- explicit 是 Cpp 中的一个关键字,用于指定构造函数或转换函数只能显式调用,不能进行隐式转换。
- 具体来说,如果一个构造函数或转换函数被声明为 explicit,则在使用该函数进行初始化或类型转换时,必须显式地调用该函数,不能进行隐式转换。
- 这可以防止一些不必要或不合理的类型转换,增强代码的可读性和安全性。
- 一般来说,explicit 只用在构造函数,而且是多个参数的构造函数,对于单个参数的构造函数比较少用
例如,下面的代码定义了一个类A,其中有一个带一个int参数的构造函数被声明为 explicit :
class A{
public:
explicit A(int n) {...}
};
那么在下面的代码中,使用 A 对象初始化 B 类型的对象时,必须显式地调用 A 的构造函数,不能进行隐式转换:
class B {
public:
B(const A& a) { ... }
};
A a(1);
B b = a; // 错误,不能进行隐式转换
B b(a); // 正确,显式调用构造函数
2、范围for循环
2.1 基本形式及实现过程
// 其中:
// decl 为定义的循环变量
// coll 为要遍历的容器或数组
// statement 为要执行的语句。
for( decl : coll ){
statement
}
/* 实现过程:就是从 coll 容器里把东西一个一个拿出来放到 decl 执行 statement,相当于遍历容器 */
例如:
for(int i : { 2,3,4,5,6,7,8,9,10 }) {
cout << i << "," << endl;
}
// 输出结果为:2,3,4,5,6,7,8,9,10,
2.2 传值和传引用
- 第一个循环中,使用了auto关键字来推导循环变量的类型,因此 elem 的类型是 double,且是按值传递的。在循环体内部,对 elem 的修改不会影响原来的vector容器。
- 第二个循环中,使用了auto&关键字来推导循环变量的类型,因此 elem 的类型是 double& ,即按引用传递的,可以修改 vector 容器中的元素。在循环体内部,对 elem 的修改会直接影响原来的 vector 容器中的元素。
例如,以下代码演示了上述两个for循环的区别:
#include
#include
using namespace std;
int main() {
vector vec = {1, 2, 3, 4, 5};
// 第一个 for 循环,按值传递
for(auto elem : vec){
cout << elem << " "; // 输出 1 2 3 4 5
}
cout << endl;
// 第二个 for 循环,按引用传递
for(auto& elem : vec){
elem *= 3; // 将 vector 中的元素乘以3
}
// 输出修改后的 vector
for(auto elem : vec){
cout << elem << " "; // 输出 3 6 9 12 15
}
cout << endl;
return 0;
}
注意:
如果 vector 容器中有大量元素,那么第二个for循环可能执行得更快一些。
- 这是因为第一个 for 循环中,每次迭代都会将 vector 中的元素复制一次,
- 而第二个 for 循环中,使用了引用传递,不需要进行复制,可以节省一定的时间和空间开销。
- 但是,这个差别通常都很小,而且取决于具体的编译器、机器和数据大小等因素。
- 因此,如果只是遍历 vector 中的元素,两种方法的性能差异可以忽略不计。重要的是代码的可读性和正确性。
- 在修改 vector 中的元素时,建议使用第二种方法,以免出现意料之外的问题。
因此,针对上面两个 for 循环,一个传值,一个引用,可得出两种 for 循环源码
for(auto _pos = coll.begin(), _end = coll.end(); _pos!=_end; ++_pos) {
decl =*_pos;
statement
}
for(auto _pos = coll.begin(); _pos!= coll.end(); ++_pos) {
auto& elem = *_pos;
cout << elem << endl;
}
3、=default 和 =delete
关键字作用
-
如果你自行定义了一个 ctor ,那么编译器就不会再给你定义一个default ctor
-
如果你强制加上 =default ,就可以重新获得并使用 default ctor
-
=default表示显式地声明类的特殊成员函数使用编译器默认生成的实现。当我们希望使用编译器的默认实现时,可以使用=default来声明。这通常用于复制构造函数、默认构造函数、移动构造函数、析构函数等。 -
=delete表示显式地禁用类的特殊成员函数的默认实现。当我们希望禁用某些特殊成员函数时,可以使用=delete来声明。这通常用于禁止复制构造函数、默认构造函数、移动构造函数、析构函数等。
具体用法
例如:以下代码展示 =default 和 =delete 的用法
class Zoo
{
public:
Zoo(int i1,int i2):d1(i1),d2(i2){}
Zoo(const Zoo&)=delete; //复制构造函数
Zoo(Zoo&&)=default; //移动构造函数
Zoo& operator=(const Zoo&)=default;//生成默认拷贝赋值运算符
Zoo& operator=(const Zoo&&)=delete;//禁用移动赋值运算符
virtual~Zoo(){} //虚析构函数
private:
int d1,d2;
}
Zoo(const Zoo&) = delete;禁用了复制构造函数,即当试图复制 Zoo 对象时,编译器将报错。Zoo(Zoo&&) = default;默认生成移动构造函数,即当需要移动 Zoo 对象时,使用编译器默认生成的实现。Zoo& operator=(const Zoo&) = default;默认生成拷贝赋值运算符,即当需要将一个 Zoo 对象赋值给另一个 Zoo 对象时,使用编译器默认生成的实现。Zoo& operator=(const Zoo&&) = delete;禁用了移动赋值运算符,即当试图将一个右值对象赋值给 Zoo 对象时,编译器将报错。virtual ~Zoo() {}定义了虚析构函数,用于在删除 Zoo 对象时正确释放资源。 通过使用=delete和=default,我们可以显式地控制类的特殊成员函数的默认实现,从而提高代码的可读性和安全性。
什么时候用=default,什么时候用=delete
以下代码将详细介绍:
class Foo
{
public:
Foo(int i) :_i(i) {};
Foo() = default;
// 不会报错,构造函数可以有多个并存,因此构造函数可以和上一个自定义的构造函数并存
// 因此Foo f1(5)会调用Foo(int i) :_i(i) {};构造函数
// Foo f2;会调用Foo() = default;默认构造函数,如果没有这句Foo() = default;,则Foo f2;会报错
Foo(const Foo& x) :_i(x._i) {}// 拷贝构造函数
// !Foo(const Foo&) = default;// 想要保留默认拷贝构造函数,报错[error]拷贝构造函数不能被重载,因为拷贝构造函数不能有两个
// !Foo(const Foo&) = delete;//也会报错[error]拷贝构造函数不能被重载,既然自定义了拷贝构造函数又要禁用它,编译器也不承认
Foo& operator=(const Foo& x) { _i = x._i; return *this; }// 拷贝赋值构造函数(赋值运算符重载)
// !Foo& operator=(const Foo& x) = default;// 错误原因和拷贝构造函数一样(11行)
// !Foo& operator=(const Foo& x) = delete;// 错误原因和拷贝构造函数一样(12行)
// !void func1() = default;[error]函数不存在什么默认版本
void func2() = delete;// 不报错,但少用,不打算用这个函数就直接不写了,没必要 delete
// ~Foo() = delete;// 这会造成 Foo object 时出错,这意味着当我们试图销毁一个 Foo 对象时,编译器将会报错
~Foo() = default;
private:
int _i;
};
=default和=delete结论:
- =default 用于上述//!这五个,没有意义,编译器会报错
- =delete 可用于任何函数身上(而 =0 只能用于 virtual 函数,即纯虚函数)
4、别名模板
概念
它允许我们使用一个模板定义来定义一个模板别名,从而简化模板的使用方式。与类型别名类似,模板别名也是一种类型别名,它可以将一个模板类型映射为另一个模板类型,并且可以在代码中像普通类型一样使用。
语法
其中,别名就是我们定义的模板别名名称,模板参数列表和模板类型分别表示模板的参数列表和类型。
template<模板参数列表>
using 别名 = 模板类型;
template
using Vec = std::vector;
上述代码定义了一个 Vec 别名模板,它将一个类型T映射为一个std::vector类型。在使用时,我们可以像使用std::vector一样来使用 Vec ,例如:
Vec v { 1, 2, 3 };
5、类型别名
概念
它允许我们为一个类型定义一个别名。与之前的typedef关键字相比,类型别名语法更加直观和简单,可以使用using关键字来定义。
语法
其中,别名就是我们定义的类型别名名称,类型表示我们要起别名的类型。
using 别名 = 类型;
//这个语句将int类型定义为my_int的别名,因此我们可以使用my_int来代替int来定义变量或函数参数。
using my_int = int;
my_int i = 42; // 等同于 int i = 42;
在 Cpp 中,类型别名可以用来定义复杂类型的别名,例如函数指针、引用、指针等,例如:
using Func = int(*)(int, double);
using Ref = int&;
using Ptr = int*;
上面的代码分别将函数指针类型、引用类型、指针类型定义为了Func、Ref、Ptr的别名。在使用时,我们可以像使用原类型一样使用它们,例如:
Func f = my_func;
Ref r = i;
Ptr p = &i;
6、except 和 noexcept(异常处理)
概念
except用于指定函数可以抛出哪些类型的异常,而noexcept则用于指示函数不会抛出任何异常。
except 语法
void func() except (exception_type1, exception_type2, ...);
// 其中,func 表示要指定异常的函数名,exception_type1, exception_type2, ...是指定的异常类型列表。
noexcept 语法
void func() noexcept;//等价于void func() noexcept(true);
void swap(Type& x,Type& y)noexcept(noexcept(x.swap(y)))
{
x.swap(y);
}
// 只要noexcept(x.swap(y)不抛出异常,则noexcept(noexcept(x.swap(y))不抛出异常
注意:
- 异常一定要处理,不然异常会一直追溯到源头,最终执行编译器默认的异常处理
std::terminate(),而 terminate 会引起std::abort()处理。
其中:
std::terminate()函数就会终止程序的执行,可能会导致数据丢失或其他不可预料的后果。std::abort()函数会立即终止程序的执行,不会执行任何清理工作,而且产生的错误退出码是固定的。
7、Override
概念
用于显式地声明一个函数是覆盖了基类中的虚函数。当派生类中的函数与基类中的虚函数同名、参数列表相同,并且也是虚函数时,可以使用override关键字来显式地声明该函数是对基类虚函数的覆盖。
语法
class Base {
public:
virtual void func();
virtual void func2() const;
};
class Derived : public Base {
public:
void func() override; // 对基类中的虚函数func进行覆盖
void func2() const override; // 对基类中的虚函数func2进行覆盖
};
使用override关键字可以帮助我们发现派生类中的函数是否真正地覆盖了基类中的虚函数,从而避免因函数签名不一致等问题导致的错误。如果使用了override关键字,但实际上并没有覆盖基类中的虚函数,编译器就会报错。
class Base {
public:
virtual void func();
};
class Derived : public Base {
public:
void fnuc() override; // 错误:没有覆盖基类中的虚函数func
};
/* 在这个例子中,由于派生类中的函数名被错误地写成了 fnuc ,与基类中的虚函数 func 不同,因此编译器会报错。如果没有使用 override 关键字,这个错误可能会在运行时才被发现,导致程序出现不可预料的结果。因此,使用 override 关键字可以帮助我们在编译时就发现这种问题,提高程序的可靠性和稳定性。 */
8、Final
概念
用于禁止派生类对基类中的虚函数进行覆盖或对类进行继承。当我们希望某个虚函数在派生类中不能被覆盖,或者某个类不能被其他类继承时,可以使用final关键字来声明。
class Base {
public:
virtual void func() final; // 禁止派生类对该函数进行覆盖
};
class Derived : public Base {
public:
void func(); // 错误:不能覆盖基类中被声明为final的虚函数 func
};
class FinalClass final {
// 该类不能被其他类继承
};
class DerivedClass : public FinalClass {
// 错误:不能从被声明为final的类FinalClass中派生出新类 DerivedClass
};
9、decltype
概念
用于获取表达式的数据类型。它可以用于获取变量、函数、表达式等的类型,而且可以保留类型的const和引用信息。
语法
decltype(expression) varname; // 获取 expression 的数据类型,并定义一个变量 varname
mapcoll;
decltype(coll)::value_type elem;
// 当上面3、4这两句距离很远时,又想知道 coll 的数据类型,就可以使用 decltype
// 而在C++11之前,没有办法通过对象来得到它的数据类型,所以要直接明了的写出它的数据类型 map
map::value_type elem;
用法
①用来声名return type
// C++11 之前的写法
template
decltype(x+y) add(T1 x,T2 y);
//编译器会先执行 decltype(x+y) 推导出 (x+y) 这个表达式的数据类型,但不会执行 (x+y) 这表达式
// C++11 之后的写法--称为(后置返回类型)
template
auto add(T1 x,T2 y)->decltype(x+y);
//根据 decltype 获取函数的返回类型
int add(int a, int b) {
return a + b;
}
decltype(add(1, 2)) c; // 定义一个变量 c,其类型与函数 add 的返回值类型相同(即 int )
在这个例子中,由于变量 c 的类型使用了decltype(add(1, 2)),因此其类型与函数 add 的返回值类型相同,即为 int 类型。需要注意的是,decltype关键字并不会执行表达式,只会根据表达式的类型推导出数据类型。
拓展:lambdas
deletype的使用和lambdas声明 return type 是很相似的
lambdas的语法
[...](...)mutable throwSpec -> retType{...}
[capture list] (parameter list) -> return type { function body }
其中,capture list用于捕获外部变量,可以是值传递或引用传递,也可以省略不写;parameter list用于定义函数参数,可以为空;return type用于定义返回值类型,可以省略不写;function body用于定义函数体,可以是一个代码块,也可以是一个表达式。
用法
例如,我们可以使用 Lambda 表达式来定义一个求和函数:
auto sum = [] (int a, int b) -> int { return a + b; };
int result = sum(1, 2); // 调用Lambda表达式,计算1+2,返回结果3
在这个例子中,我们使用 Lambda 表达式来定义一个求和函数,其参数列表为(int a, int b),返回类型为int,函数体为return a + b;。使用auto关键字可以让编译器自动推导出Lambda表达式的类型。 Lambda 表达式可以像普通函数一样调用,例如sum(1, 2)可以计算 1+2 ,返回结果3。
注意: Lambda 表达式可以捕获外部变量
int a = 10;
auto f = [a] (int b) -> int { return a + b; };
int result = f(20); // 调用 Lambda 表达式,计算 10+20 ,返回结果 30
在这个例子中,我们使用 Lambda 表达式来定义一个函数f,其参数列表为(int b),返回类型为int,函数体为return a + b;。 Lambda 表达式中使用了[a]来捕获变量a,因此在函数体中可以访问变量a的值。使用f(20)可以计算 10+20 ,返回结果 30。
②in metaprogramming(元编程)( decltype 来历–拓展知识)
在 C++11 之前,我们通常使用模板元编程技术来推导变量和函数的类型。这种方法虽然可以实现类型推导,但代码比较繁琐,可读性较差。为了提高代码的可读性和简洁性,C++11 引入了
decltype关键字,它可以在编译时根据表达式的类型推导出相应的类型,从而避免了模板元编程的繁琐操作。
元编程(Metaprogramming)是指在编写程序时,编写能够产生程序代码的程序。C++中的元编程,通常是指使用模板(Template)和泛型编程(Generic Programming)技术来实现。元编程可以让程序在编译期间进行更多的计算和优化,从而提高程序的性能和可维护性。
在 C++ 中,元编程常常使用模板元编程(Template Metaprogramming)来实现。模板元编程是一种基于模板的技术,通过模板特化(Template Specialization)、模板递归(Template Recursion)、模板元函数(Template Metafunction)等手段,可以在编译期间进行程序计算和优化。
例如,我们可以使用模板元编程来实现一个阶乘计算函数:
template
struct Factorial {
enum { value = N * Factorial::value };
};
template <>
struct Factorial<0> {
enum { value = 1 };
};
在这个例子中,我们使用了模板特化来处理 N=0 的情况,防止递归无限展开。
使用Factorial可以在编译期间计算N的阶乘,例如:
int result = Factorial<5>::value; // 计算5的阶乘,返回结果120
在编译期间,编译器会根据模板实例化出多个版本的代码,每个版本的代码对应一个不同的模板参数。这些代码会在程序运行前进行计算和优化,从而提高程序的性能和效率。值得注意的是,元编程也会增加程序的复杂度和难度,需要在实现时谨慎考虑其使用场景和实际效果。
// 注意:传进来的 obj 是一个容器
template
void test18_decltype(T obj)
{
map::value_type elem1;
mapcoll;
decltype(coll)::value_type elem2;
// 使用了 decltype(coll) 来获取 coll 的类型,然后使用 value_type 来定义elem2的类型,这样可以在编译期间确定 elem2 的类型,并避免了手动定义类型的错误风险。
typedef typename decltype(obj)::iterator iType;
// 比 typedef typename T::iterator iType; 写法更好
// 使用了 decltype(obj) 来获取 obj 的类型,并使用 iterator 来定义 iType 的类型。
decltype(obj) anotherObj(obj);
// 定义了一个 anotherObj对象,使用 decltype(obj) 来推导出其类型,并将 obj 作为参数传入构造函数,这样可以将 obj 的值复制到 anotherObj 对象中。需要注意的是, decltype(obj) 推导出的类型和 obj 的类型一致,因此 anotherObj 的类型也和 obj 的类型一致,从而避免了手动指定类型的麻烦。
}
typedef typename decltype(obj)::iterator iType;和typedef typename T::iterator iType;的区别:
- 类型的推导方式不同
typedef typename decltype(obj)::iterator iType;是使用了decltype关键字来推导出obj的类型,并从中提取出iterator类型。因此,这个语句声明的iType类型,是obj的迭代器类型,而不是T的迭代器类型。这样可以在实例化模板函数时,根据实参的类型来推导出参数的迭代器类型,从而增强了代码的灵活性。- 而
typedef typename T::iterator iType;则是直接从模板参数T中提取出迭代器类型。这种方式需要在实例化模板函数时,将参数类型显式指定为一个具体的类型,从而使得代码的可读性和可维护性较差。 - 因此,虽然这两种方式都可以定义一个迭代器类型的别名
iType,但是它们的语法和语义是不同的,需要根据具体的使用场景来选择使用哪种方式。
③used to pass the type of a lambda
auto cmp = [](const Person& p1,const Person& p2){
return p1.lastname() coll(cmp);
面对 lambda ,我们手上往往只有 object ,没有 type ,要获得其 type 就得借助于 decltype。
10、lambda
基本语法
[...](...)mutable throwSpec -> retType{...}
[...]:Lambda表达式的捕获列表,用于指定Lambda表达式访问外部变量的方式。可以为空(即不捕获任何变量),也可以包含以下几种元素:
&:以引用的方式捕获外部变量;=:以值的方式捕获外部变量;- 变量名:以指定变量名的方式捕获外部变量;
this:以指针的方式捕获当前对象的地址。
(...):Lambda表达式的参数列表,用于指定Lambda表达式所接受的参数。可以为空(即不接受任何参数),也可以包含一组形如type name的参数列表。
mutable:==可选项,用于指定Lambda表达式是否可以修改捕获的变量。==如果使用了mutable关键字,则可以在Lambda表达式中修改以值方式捕获的外部变量。
throwSpec:==可选项,用于指定Lambda表达式可能抛出的异常类型。==可以指定noexcept、throw()或者抛出异常类型的列表等。
-> retType:==可选项,用于指定Lambda表达式的返回类型。==可以根据Lambda表达式的实现自动推导,也可以显式指定返回类型。
{...}:Lambda表达式的函数体,包含了Lambda表达式的具体实现。可以是任意合法的C++语句和表达式,可以访问Lambda表达式所在函数的局部变量和参数,并且可以使用return语句返回值。
注意:mutable、throwspec、retType三个有其中一个前面就要加()
用法
lambda就像是一个匿名函数对象
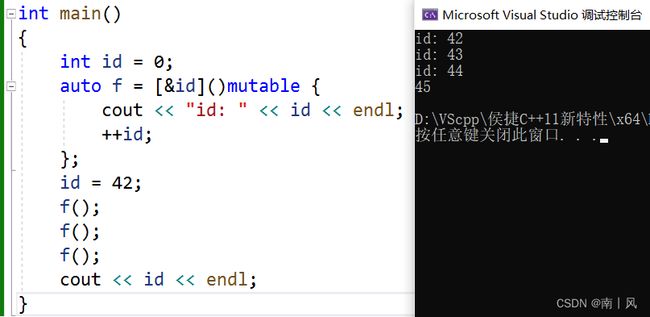
int id = 0;
auto f = [id]()mutable{
std::cout << "id: " << id << std::endl;
++id;
};
id = 42;
f();
f();
f();
std::cout << id << std::endl;
//输出结果如下:
//id:0
//id:1
//id:2
//42
//如果没有加上mutable则不等价下面的写法,因为不能对id进行修改,只能读取一个id值
//上面的例子等价于下面的函数对象写法:
class Functor {
private:
int id;
public:
void operator() {
std::cout << "id: " << id << std::endl;
++id;
}
};
Functor f;
为什么不先输出42,然后加1变成43、44的原因:
因为 lambda 表达式使用了mutable关键字,因此可以修改以值方式捕获的外部变量(即值拷贝的方式),也就是说在这段代码中,Lambda 表达式中的id变量是一个拷贝,初始值为 0,但是在 Lambda 表达式中可以被修改。
也就是说,Lambda 表达式中的id变量和外部变量id的值是不同的,初始值为 0。因此,调用 Lambda 表达式时会先输出 0,然后将 Lambda 表达式中的id值加 1,再次调用时输出 1,以此类推,输出 2。最后再输出外部变量id的值,即 42。
如果Lambda表达式中使用了引用方式捕获外部变量id,即将Lambda表达式定义改为auto f = [&id](){...},则输出结果会先为 42,然后是43、44、45,表示Lambda表达式中的id变量和外部变量id的是同一个变量的,共享一块内存地址。
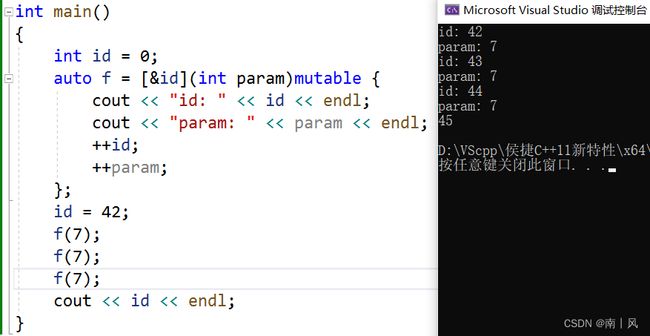
- 在这个例子中,Lambda 表达式中的形参
param是没有实际意义的,它只是作为一个参数传入 Lambda 表达式中,但并没有被使用到。 具体来说,Lambda 表达式中的形参param在输出时被使用,即输出传入 Lambda 表达式的参数值。但是在 Lambda 表达式中没有其他的操作使用这个参数,也没有对它进行修改。因此,这个形参param在这个Lambda 表达式中是没有实际意义的,并且可以被省略掉。 - 需要注意的是,在这个例子中,形参
param的名称并不重要,可以使用任何名称来表示这个形参,因为它并没有被使用到。而对捕获的外部变量id进行修改时,由于使用了引用方式进行捕获,Lambda 表达式中的id变量和外部变量id是同一个变量,它们共享同一块内存地址,因此对id变量的修改会直接影响到外部变量id的值。
拓展
lambda的类型是一个匿名函数对象(或函数),对于每个 lambda 表达式都是唯一的。==因此,要声明该类型的对象,您需要模板或auto。如果需要类型,可以使用decltype(),==例如,需要将 lambda 作为散列函数或排序或排序标准传递给关联或无序容器
auto cmp = [](const Person& p1,const Person& p2){
return p1.lastname() coll(cmp);
/* 因为您需要 lambda 的类型来声明集合,所以必须使用 decltype,它产生lambda对象的类型,比如 cmp。请注意,您还必须将 lambda对象传递给coll的构造函数:否则,coll 将调用传递的排序标准的默认构造函数,并且根据规则,lambda 没有默认构造函数,也没有赋值运算符。因此,对于排序标准,定义函数对象的类可能更直观。 */
- 这段代码定义了一个 Lambda 表达式
cmp,用于指定std::set容器中元素的排序方式。 - 具体来说,这个 Lambda 表达式接受两个
const Person&类型的参数p1和p2,并根据它们的lastname和firstname属性实现比较操作。 - 如果
p1.lastname()小于p2.lastname(),则p1排在p2之前; - 如果
p1.lastname()等于p2.lastname(),则根据firstname属性再进行比较。 - 比较结果为
true时,p1排在p2之前,否则p2排在p1之前。 - 之后,使用
decltype(cmp)作为std::set容器的第二个模板参数,指定元素的比较函数为cmp。 decltype(cmp)表示cmp表达式的类型,这里用作函数指针类型。- 需要注意的是,Lambda 表达式的类型是一个匿名类型,无法直接作为函数指针类型传递给
std::set容器。 - 因此,需要使用
decltype来获取 Lambda 表达式的类型,然后将其作为函数指针类型传递给std::set容器。
下面这段代码的作用是从vector类型的容器vi中,移除所有满足x < n && n < y条件的元素,即移除所有大于x且小于y的元素。
// lambda 写法一定是内联 inline 的
vectorvi {5,28,50,83,590,245,59,24};
int x = 30;
int y = 100;
vi.erase(remove_if(vi.begin(),vi.end(),[x,y](int n) { return x < n && n < y;}),vi.end());
for(autp i:vi)
cout << i <<' ';//输出结果:5 28 590 245 24
cout< 11、variadic templates
概念
Variadic templates 是 C++11 引入的一个新特性,它使得函数和类可以接受数量不定的参数,这些参数可以是不同的类型。在 C++ 中,variadic templates 通常用于实现泛型程序设计,以支持不定数量和不定类型的参数,从而提高代码的通用性和灵活性。
语法形式及用法
Variadic templates 的语法形式为:在模板参数中使用省略号...表示可变参数,例如:
template
void myFunction(Args... args) {
// 函数体
}
在上面的代码中,Args表示模板参数包,Args...表示可变参数模板。在函数体中,可以使用args...来访问可变参数包中的所有参数,例如:
template
void myFunction(Args... args) {
std::cout << sizeof...(Args) << std::endl; // 输出可变参数包中的参数数量
std::cout << sizeof...(args) << std::endl; // 输出函数调用时实际传入的参数数量
}
Variadic templates 还可以用于实现递归模板,例如:
//第一种
template
void print(T arg) {
std::cout << arg << std::endl;
}
//第二种
template
void print(T arg, Args... args) {
std::cout << arg << ", ";
print(args...);
}
//第三种
template
void print(Args... args) {
/*...*/
}
/*第二种和第三种可以并存,因为第二种更加特化,当有一个参数包时会优先调用更特化的函数,但是即使最后参数包只剩一个参数也一样会继续调用第二种,因此这会导致第三种方式会始终不被调用,所以一般都不一起存在*/
在上面的代码中,print函数使用了可变参数模板,实现了递归调用,将可变参数包中的所有参数依次输出到标准输出流中。
该函数包含两个重载形式,其中第一个形式接受一个参数arg,并将其输出到标准输出流中;第二个形式接受不定数量的参数,其中第一个参数为arg,后面的参数为可变参数包Args,并将它们依次输出到标准输出流中。具体来说,当调用print函数时,编译器会根据传入参数的数量和类型,选择合适的函数重载形式进行调用。
使用示例:
print(1, 2, 3); // 输出:1, 2, 3
print("hello", "world"); // 输出:hello, world
在第一个示例中,print(1, 2, 3)调用了第二个函数重载形式,其中T被推导为int类型,Args被推导为参数包(int, int),因此,函数将依次输出参数1、2和3。在第二个示例中,print("hello", "world")调用了第二个函数重载形式,其中T被推导为const char*类型,Args被推导为参数包(const char*, const char*),因此,函数将依次输出参数"hello"和"world"。
使用 Variadic templates 重写 printf( )
void printf(const char*s) {
while(*s) {
if(*s == '%' && *(++s) != '&')
throw std::runtime_error("invalid format string: missing argument");
std::cout << *s++;
}
}
// 如果调用重载后的printf函数时,可变参数包 args 为空,则会调用原始的 printf 函数,也就是 void printf(const char*s)这个函数。如果后续又检测到了%则会抛出异常,因为正常情况下参数已经被重写的 printf 函数实现完了
/* 原因是,当可变参数包为空时,递归调用时传入的参数列表为空,导致在下一次递归调用时会进入到 if (*s == '%' && *(++s) != '%')这个判断条件中,但是由于后面没有参数了,因此递归调用会终止,直接返回。当递归回到第一次调用时,由于参数列表为空,因此会调用原始的 printf 函数。 */
// 重写
template
void printf(const char* s, T value,Args... args) {
while(*s) {
if(*s == '%' && *(++s) != '%') {
std::cout << value << ' ';// 输出当前参数
printf(++s,args...); // 递归处理后面的参数
return;
}
std::cout << *s++;
}
thorw std::logic_error("extra arguments provided to printf");
}
使用示例:
int *pi = new int;
printf("%d %s %p %f\n",15,"This is Ace.",pi,3.141592653);
在函数体中,首先检查格式化字符串中是否存在%符号,并且下一个字符不是%,如果满足条件,则将当前参数输出,并递归调用printf函数处理后面的参数;否则,直接将当前字符输出。当格式化字符串处理完毕后,如果还有多余的参数,则抛出一个逻辑错误。
参数个数不限,但类型 type 都相同,则不需要用 variadic templates,使用 initializer_list 足以。

cout<initializer_list容器,它的背后其实就是一个array,之后就会调用*max_element函数,接下来在调用_max_element函数,但是里面还要调用一个_iter_less_iter()的函数,得到一个返回值_Iter_less_iter(),它就是一个 type ,而这个类就通过 operator 函数比较大小,因此也叫对象函数,最后就回到_max_element的函数调用
cout<initializer_list这个容器必须要用 {} 把里面的数据括起来,否则就要改变 max() 函数的具体实现。
不使用 {} 的具体实现如下:

int maximum(int n) {
return n;
}
template
int maximum(int n, Args... args) {
return std::max(n, maximum(args...));
}
这段代码实现了一个可变参数模板函数maximum,用于求取多个参数中的最大值。其实现方式是将第一个参数和剩余参数递归地进行比较,直到所有参数都比较完毕,返回最大值。
具体来说,代码首先定义了一个非模板函数maximum,用于处理只有一个参数的情况。当调用maximum函数时,如果只提供了一个参数,则直接返回该参数的值。用于处理递归终止的情况。接下来,定义了一个可变参数模板函数maximum,用于处理多个参数的情况。在函数体中,首先将第一个参数n与剩余参数args中的第一个参数进行比较,然后递归调用maximum函数,将前面比较出的最大值和剩余参数中的参数继续进行比较,直到所有参数都比较完毕,返回最终的最大值。
使用示例:
int max1 = maximum(5, 9, 3, 7, 1);
int max2 = maximum(1, 2, 3, 4, 5, 6, 7, 8, 9);
std::cout << max1 << std::endl; // 输出 9
std::cout << max2 << std::endl; // 输出 9
在上面的示例中,首先调用maximum函数,将5、9、3、7、1这5个整数作为参数传入,求取其中的最大值。在调用过程中,会递归调用maximum函数,比较出5和9的最大值,然后将它和3、7、1进行比较,最终得到9。然后再次调用maximum函数,将1、2、3、4、5、6、7、8、9这9个整数作为参数传入,求取最大值,得到9。因此,最终输出的结果为9。
Variadic templates用于递归继承,recursive inheritance

这段代码实现了一个可变参数模板类tuple,用于存储多个值。tuple类内部使用递归继承的方式,将多个值存储在不同的基类中。
- 首先,定义了一个空模板类
tuple<>,该类不包含任何成员变量和成员函数,用于处理没有参数的情况。 - 接下来,定义了一个有参模板类
tuple,该类继承于tuple,即它的基类是由Tail...类型参数构成的tuple类。 - 在这个类中,使用
Head类型参数定义了一个成员变量m_head,用于存储tuple中的第一个值。然后,定义了一个构造函数,将第一个值和剩余的值递归地存储在基类中。最后,定义了一个head()成员函数,用于返回tuple中的第一个值。 - 需要注意的是,这里使用了递归继承的方式,即
tuple类继承于tuple类。这样,当创建一个tuple对象时,它的基类就会递归地创建出所有需要的基类对象,从而将所有参数都存储在不同的基类中。
使用示例:
tuple t(1, 3.14, "hello");
std::cout << t.head() << std::endl; // 输出 1
在上面的示例中,首先创建了一个tuple类型的对象t,它包含了一个整数1、一个浮点数3.14和一个字符串"hello"。在调用构造函数时,首先将整数1存储在m_head成员变量中,然后递归地创建了一个tuple类型的基类对象,将浮点数3.14和字符串"hello"存储在基类对象中。
因此,最终得到的tuple对象的内部结构如下所示:
tuple
|
v
tuple
|
v
tuple
|
v
tuple<>
但是上面图片的代码有一点问题,编译器会报错无法识别Head::type
改进第二版:

改进第三版:

12、initializer_list
概念
std::initializer_list是 C++11 引入的一种特殊容器,它可以==用于在函数中轻松地传递和接收多个已知数量的同种类型的值==。- 其定义在头文件
std::initializer_list本质上是一个包含指向其元素的指针和元素数量的结构体,提供了迭代器和下标操作符等接口,因此可以像容器一样进行操作。- 使用
std::initializer_list的语法类似于数组,可以使用花括号{}来初始化
例如:
std::initializer_list il = {1, 2, 3, 4, 5};
也可以将std::initializer_list作为函数参数传递,例如:
void foo(std::initializer_list il) {
for (int i : il) {
std::cout << i << " ";
}
}
在调用foo函数时,可以直接使用花括号将参数放在一起,例如:
foo({1, 2, 3, 4, 5});
需要注意的是,std::initializer_list中的**元素是只读的,不能通过迭代器修改。此外,std::initializer_list不支持添加或删除元素,因为它是固定不变的**。 std::initializer_list的一个==常见用途是作为模板类的构造函数参数==
例如std::vector的构造函数:
template>
class vector {
public:
vector(std::initializer_list il, const Allocator& alloc = Allocator());
// ...
};
使用std::initializer_list作为构造函数参数,可以方便地初始化一个std::vector对象
上面的代码定义了一个名为vector的模板类,它是一个动态数组容器。其中,模板参数T表示容器中元素的类型,模板参数Allocator表示容器使用的内存分配器类型,它的默认值为std::allocator。 vector类中定义了一个带有一个参数和一个可选参数的构造函数,它使用了C++11中的initializer_list特性,允许我们使用花括号分隔的列表来初始化容器中的元素。具体来说,这个构造函数接受一个std::initializer_list类型的参数il,并将它用于初始化容器。如果提供了第二个参数,则使用它来分配内存。
例如:
std::vector v = {1, 2, 3, 4, 5};
总之,std::initializer_list可以方便地传递和接收多个同种类型的值,是C++11中非常有用的特性之一。
13、make_tuple
概念
std::make_tuple是 C++11 引入的一个函数模板,用于创建一个std::tuple类型的对象。其定义在头文件std::tuple是 C++11 新引入的一个容器类型,可以将多个不同类型的值打包成一个对象,方便地进行传递和处理。
语法
template
std::tuple make_tuple(Types&&... args);
它接受任意数量的参数,并返回一个std::tuple类型的对象,该对象包含了所有传入的参数。需要注意的是,std::make_tuple会对所有参数进行完美转发,因此可以接受左值、右值和具有引用类型的参数。
使用示例:
auto t = std::make_tuple(1, "hello", 3.14);
- 在上面的示例中,
std::make_tuple接受了 3 个参数,分别为整数 1、字符串 “hello” 和浮点数 3.14。 - 它返回了一个
std::tuple类型的对象t,其中包含了所有传入的参数。 std::make_tuple常常与std::tie一起使用,std::tie可以将std::tuple类型的对象解包成多个变量,方便地进行处理。
例如:
int a;
const char* b;
double c;
std::tie(a, b, c) = std::make_tuple(1, "hello", 3.14);
- 在上面的示例中,
std::make_tuple返回了一个包含3个元素的std::tuple类型的对象,其中第一个元素为整数1,第二个元素为字符串 “hello” ,第三个元素为浮点数 3.14。 - 然后,使用
std::tie将这个std::tuple类型的对象解包成3个变量a、b和c,分别赋值为 1 、“hello” 和 3.14。
14、Rvalue refences右值引用
概念
C++ 右值引用是 C++11 引入的一项新特性,它是一种新的引用类型,用于表示一个对象的右值。右值引用的语法为&&,例如int&&表示一个右值引用类型的整数。
右值引用的主要作用有两个:
1.转移对象的所有权:
右值引用可以将一个对象的所有权从一个对象转移到另一个对象,从而实现移动语义,避免不必要的对象复制和销毁操作,提高代码性能。例如,可以使用右值引用来实现移动构造函数和移动赋值运算符。
2.完美转发:
右值引用可以实现完美转发,即在函数调用时,将参数以原本的类型和左右值属性转发给其他函数。这可以避免不必要的数据复制和类型转换,提高代码性能。例如,可以使用右值引用来实现可变参数模板函数。
template
void forward_func(T&& arg) { // 可以接受任意类型参数的函数
other_func(std::forward(arg)); // 完美转发参数
}
在上面的代码中,我们定义了一个可接受任意类型参数的函数forward_func,并使用右值引用类型的参数arg来实现完美转发。在函数内部,我们调用了另一个函数other_func,并使用std::forward函数来完美转发参数arg。
3.移动构造函数:
class MyClass {
public:
MyClass(MyClass&& other) { // 移动构造函数
// 将 other 的资源转移到当前对象
m_data = other.m_data;
other.m_data = nullptr;
}
private:
int* m_data;
};
在上面的代码中,我们定义了一个MyClass类,并实现了一个移动构造函数。这个移动构造函数接受一个右值引用类型的参数other,将other对象的资源移动到当前对象中,并将other对象的指针设为nullptr,避免重复释放资源。
侯捷讲解
Lvalue:可以出现在 operator= 左侧者
Rvalue:只能出现在 operator= 右侧者
1、以int类型试验
int a = 9;
int b = 4;
a = b; //ok
b = a; //ok
a = a + b; //ok
a + b = 42; //[error]lvalue required as left operand of assignment
2、以string类型试验
string s1("Hello ");
string s2("World ");
s1 + s2 = s2; //竟然可以通过编译
cout << "s1: " << s1 << endl; //s1:Hello
cout << "s2: " << s2 << endl; //s2:World
string() = "World"; //竟然可以对temp obj赋值
//可以这样想,string()是个临时对象,它是一个右值,而临时对象是没有名称的,那么没有名称要怎么赋值给它呢?
3、以complex类型试验
complexc1(3,8),c2(1,0);
c1 + c2 = complex(4,9); //c1 + c2可以当作Lvalue
cout << "c1: " << c1 << endl; //c1:(3,8)
cout << "c2: " << c2 << endl; //c2:(1,0)
complex()=complex(4,9)//竟然可以对temp obj赋值
//complex()也是一个临时对象,和string()一样
int foo() {return 5;}
...
int x = foo(); //ok
int* p = &foo(); //[error]
foo() = 7; //[error]
/*函数的名称就是函数地址起点,不用加&和(),foo就是这个函数的地址*/
/*而&foo()是对函数返回的对象取它的地址,但是函数返回的东西是个右值,对右值取地址的时候是不可以的*/
当 Rvalue 出现在 operator=(copy assignment) 的右侧,我们认为对其资源进行偷取/搬移(move)而非拷贝(copy)是可以的,是合理的。
那么:
1、必须有语法让我们在调用端告诉编译器,“这是个 Rvalue ”
2、必须有语法让我们在被调用端写出一个专门处理 Rvalue 的所谓move assignment函数。

但是使用右值引用之后,即使用 move 之后,其实就类似于浅拷贝,把临时变量指向要搬移的原变量,两个共享一个值,这是很危险的,一旦原变量销毁了内容,临时变量就会出问题,所以一般都要把原变量指向它本身的指针断掉,改为 nullptr ,只由临时变量指向原变量的内容,这时原变量之后就不能再用了,因此描述为“偷”,所以要使用 move 要确保以后不会再用原变量。