【GNN论文精读】A Gentle Introduction to Graph Neural Networks
论文地址:A Gentle Introduction to Graph Neural Networks
作者:谷歌的三位大佬
时间:2021年
参考李沐老师的论文讲解课而做的笔记
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
目录
1. 前言
2. 什么是图
2.1 图的基本概念
2.2 数据如何表示成图
2.3 哪些类型的问题具有图形结构化数据?
2.4 在机器学习中使用图形的挑战
3. 图神经网络
3.1 GNN的基本概念
3.2 最简单的GNN
3.2.1 GNN层——更新属性
3.2.2 全连接层——预测
3.2.3 池化层——汇聚信息
3.2.4 总体模型
3.2.5 消息传递GNN层
4. 实验
4.1 GNN playground
4.2 超参数对精度影响的解释
5. 相关技术
5.1 其他类型的图
5.2 GNN 中的图采样和批处理
5.3 inductive biases
5.4 不同的pooling方式
1. 前言
本文是关于图神经网络(graph neural networks, GNNs)的两篇 Distill 出版物之一。看看理解图上的卷积,了解图像上的卷积如何自然地推广到图上的卷积。
图是非常有用的表示形式。在论文的开头,做着便用图来展示神经网络的设计原理。
如图所示,选中图上的某一层的某个节点,在下一层会关联与该节点相邻的节点,再下一层就会再多关联其邻居节点的邻居节点。这样,如果层很多的,某个节点就能get到整个图的节点信息。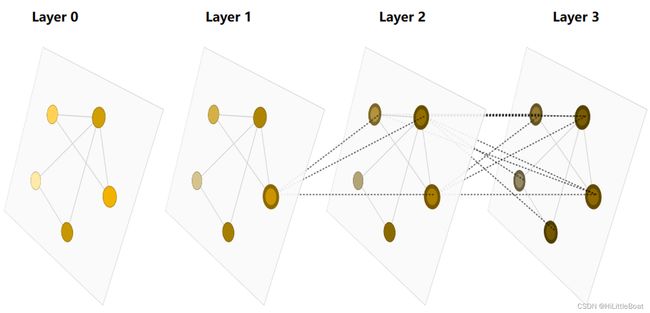
2. 什么是图
2.1 图的基本概念
1. 图的概念及其表示形式:
图表示实体(节点,nodes)集合之间的关系(边,edges)
- V: Vertex (or node) attributes 节点属性 (例如,节点身份、邻居数量)
- E: Edge (or link) attributes and directions 边属性和方向 (例如,边标识、边权重)
- U: Global (or master node) attributes 全局属性 (例如,节点数、最长路径)
2. 图信息的嵌入
接下来,我们讨论一下如何将这些属性(信息)存储在图的每个部分中,如下图所示,对于每个节点/边,以及全局属性,可以用向量来表示。

3. 有向图和无向图
通过将方向性与边(有向、无向)相关联来专门化图。
2.2 数据如何表示成图
寻常类型的图,如社交网络,本身就是图类型的数据,表示起来很容易理解。但是图形是一种非常强大且通用的数据表示形式。除了本身就是图类型的数据,还有图像和文本,这两种直觉上看,好像无法建模为图的数据,但人们可以通过将其视为图形来更多的了解图像和文本的对称性和结构,并建立一种直觉,这将有助于理解其他不太像网格的图形数据。
1. 图像—>图
如下图所示,左边的图是一张图片的一个个像素点。每个像素点代表一个节点,并用边连接到相邻像素点,就组成了右侧的图结构。
这个图结构的连通性可以用邻接矩阵来表示,如中间的矩阵所示,横坐标和纵坐标分别表示所有的节点,如果两个节点联通,则值为1,否则为0
2. 文本—>图
同理,文本也可以表示成图,如下图所示,将字符/单词/索引 视为一个节点,用边连接到其后边的节点。并用邻接矩阵表示连接关系。

3. 其他的类型—>图
同理,很多的结构都可以表示成图,例如分子结构、社交网络图、文章的引用图(有向图)等等。
这篇文章中,也提到了一些例子,例如空手道比赛,对手的关系图,通过对图的处理来找到学生各属于哪个老师的阵营。这里不再详细展开。
2.3 哪些类型的问题具有图形结构化数据?
对图上的数据可以执行什么任务呢?
——三种类型的预测任务:图形级任务、节点级任务、边级的任务。
好像是可以很好地解决分类的问题。
2.4 在机器学习中使用图形的挑战
核心问题:
Q1: 怎么样表示一个图,使得与神经网络兼容?图上有四种信息:节点、边、全局信息、连接性,特别是 连接性,怎么表示呢?
——我们可以用邻接矩阵(如果有n个节点,矩阵规模就是n*n,如果两个点相连接,则为1,否则为0)。
但是这样也会产生其他问题:
Q2: 这个矩阵可能会非常大。但是边如果没有那么多,会比较稀疏。如何高效计算稀疏矩阵呢?
Q3: 对于一个邻接矩阵,如果更换节点的顺序,会得到不一样的矩阵,但是他们表示的仍是一张图,如何保证神经网络计算所得的结果是一致的?
解决方法:
基于上述问题,作者采用一种优雅且节省内容的方法——邻接列表。如下图所示,节点、边和全局信息,分别用一个标量或者向量表示。对于连接性,用一个邻接列表,列表中的第i个元素,对应第i个边由哪两个节点相连接,如[2,0],就表示下标为2 和0 的节点连接的边。

3. 图神经网络
3.1 GNN的基本概念
GNN是对图的所有属性(节点、边、全局上下文)的可以优化的转换(optimizable transformation),它保持了图对称性。(排列不变性)
就是说,这种变换,可以保持住图的对称信息,所谓的对称信息就是指,对顶点进行另外一种方式的排序之后,结果是不会变的。
这里使用了Gilmer等人提出的“信息传递神经网络”框架来构建GNN$^{[18]}$,采用“graph-in, graph-out”架构(输入是图,输出也是图)。
这意味着这些模型,接受图作为输入,将信息加载到其节点、边和全局上下文中,并逐步转换这些嵌入,但是不会改变图的连接性。
[18] Neural Message Passing for Quantum Chemistry J. Gilmer, S.S. Schoenholz, P.F. Riley, O. Vinyals, G.E. Dahl.Proceedings of the 34th International Conference on Machine Learning, Vol 70, pp. 1263--1272. PMLR. 2017.
3.2 最简单的GNN
3.2.1 GNN层——更新属性
对于顶点向量、边向量、全局向量会使用单独的多层感知机(MLP),这三个MLP就组成了一个GNN的层。
经过各自的MLP进行处理,只有各自的属性会被更新,而不会改变图的结构。
也可以将这些GNN层堆叠在一起,构造成更深一点的GNN。

3.2.2 全连接层——预测
以二分类为例,在简单的GNN层之后,加一个输出为2的全连接层,再加一个softmax,就可以了。
如下图所示,给最后一层的输入(左边那个图)将每个顶点进行全连接。

3.2.3 池化层——汇聚信息
但是在实际应用中,可能将图形中的信息存储在边中,但在节点中没有信息,但仍需要对节点进行预测。我们需要一种方法来从边收集信息并将其提供给节点进行预测。我们可以通过polling(池化) 来做到这一点。池化分两步进行:
- 对于要池化的每个项目,收集它们的每个嵌入并将它们连接成一个矩阵。
- 然后通常通过求和运算聚合收集的嵌入。
如下图所示,如果节点中没有信息,就收集与该节点相连的边的信息及图的全局信息,再进行求和,来表示这个节点,即$pE_n→V_n$(p表示池化操作)。 如果边、节点和全局信息的向量长度不一样,需要额外做一些投影。 同理,如果是边没有信息,需要处理边,就用相连接的节点来进行求和。 再同理,如果没有全局的向量,那就可以把顶点向量汇聚起来。

以从边向量汇聚成顶点向量为例,模型图如下所示,

3.2.4 总体模型
综合上述的层,我们就得到了一个最简单的GNN,整体的模型图如下所示,首先进入一系列的GNN层,其中包含了三个MLP分别处理节点、边、全局信息,输出仍为一个图结构,最后再根据需要用那个属性做预测,就添加合适的输出层,如果添加信息,就再加pooling层。

到这里,并没有再GNN层内使用图的连接信息,(因为再各自的MLP中,并没有考虑节点相连的信息,而是单独处理各自的属性)接下来会使用之前提到的“信息传递”来进行处理。
3.2.5 消息传递GNN层
1. 节点→节点; 边→边
结合pooling来做更复杂的预测,分三个步骤进行:
- 对于图中的每个节点,收集所有相邻节点的信息
- 通过聚合函数(如sum)聚合所有信息
- 所有汇集的信息都通过update function传递,通常是学习的神经网络。
如下图所示,先将一个顶点自己本身的信息,与其相邻顶点的信息进行汇聚,得到进入MLP之前的向量。这就是最简单形式的消息传递。

这很像图像卷积的操作,假设这个图表示的是一张图片,连接的边就是与该像素点相邻的点,这个操作就等价于在图片上做卷积,但是这个卷积核窗口的权重是一样的。
通过构建多层的传递GNN层,消息堆叠在一起,节点最终可以合并来自整个图的信息。

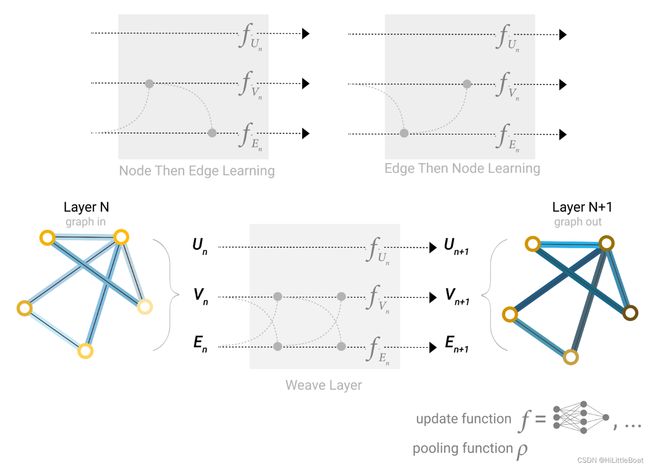
2. 顶点和边之间的交换
有时候,数据集并不是包含所有类型的信息(节点、边、全局),在3.2.3中提到,如果图缺失某些属性,可以从别的属性汇聚过来,得到该属性。但是当时是在最后的预测部分才做的。这里,我们可以使用消息传递在GNN层内的节点和边缘之间共享信息。
如下图所示,可以通过边所连接的节点信息,得到边的信息,再将边的信息聚合,更新节点的信息,之后再将各自的信息分别放入三个MLP中进行更新。

同理,也可以有很多的消息传递形式,如下图,可以通过边得到节点,再汇聚成边。
也可以先 节点→边,边→节点,如何再来一轮 边→节点,节点→边(开启炼丹模式)
3. 添加全局信息表达
也可以通过图的全局信息,更新节点和边,然后再根据节点和边,汇聚成全局信息。然后再放到各自的MLP进行更新。


4. 实验
4.1 GNN playground
原文提供了一个playground,展示了带有小分子图的图级预测任务,将训练程序嵌入到了JavaScript里,使得我们可以很直观地调整参数。
可视化页面如下图所示,上边有可以设置的超参数,改变超参数,会自动进行训练,AUC值越高越好
这里使用 Leffingwell 气味数据集,它由具有相关气味感知(标签)的分子组成。这里的例子就是用于预测分子结构(图)与其气味的关系,为了简化问题,只考虑每个分子的二元标签,即通过该分子是否”刺鼻“进行分类预测。
左边可以自己设计分子,来进行预测
右边是对数据集的预测结果,每个原点代表一个图(分子结构),如果远点的边框和填充颜色一致,则预测正确。

4.2 超参数对精度影响的解释
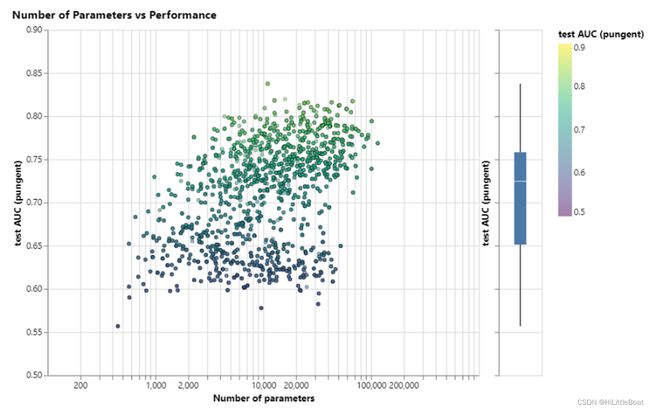
1. 模型大小
这张图表示模型可以学习的参数的大小和AUC之间的关系,这里每个点就是一个特定的超参数在模型上训练之后得到的结果。一个点就是一个模型,鼠标悬浮上去,可以看到具体的超参数。
x轴是参数的个数,y轴是AUC的值。整体来看,参数变多的时候,效果的上限是在往上增加的,但是如果参数调的不是很好,就算模型很大,效果也不会很好,跟小模型的差不多。
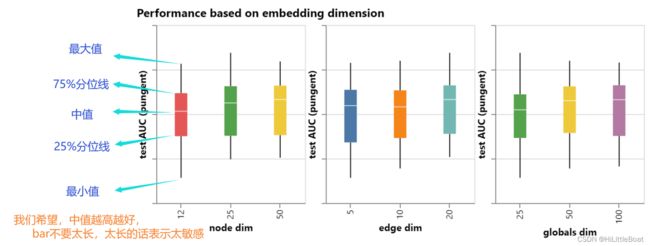
2. 向量长度
下面的箱线图(boxplot)展示了节点、边、全局信息的向量长度的影响,可以看出,他们都是稍微大一点会好一点,但是整体不是那么明显,因为这些点的方差太大了。
3. GNN层数对精度的影响
左边的部分同1 的图,x轴是参数的个数,y轴是AUC的值,在右侧加了一个boxplot,来表示不同的层数的影响。
基本上可以看出,当层数越低,可以学习的参数也会越少一点。从精度上看,好像是听耦合在一起的,但是通过boxplot,可以发现,当层数增加的时候,中值在增加,但是方差也还挺大的。

这意味着,我们可以把层次的参数调高一点,但是也要把剩下的参数调好。
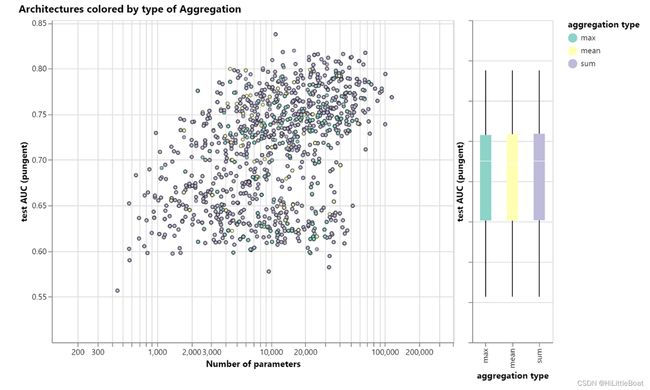
4. 聚合的方式mean/max/sum
如下图所示,不管是求和求最大求平均,效果差距不大,这个方式的选择,感觉更在于你想要怎么区分不同的图。
5. 在哪些属性之间传递信息
如下图,显示了不同的传递信息的属性的组合对精度的影响。

这里主要列三个:
- 绿色:不传递任何信息→ 效果最差
- 灰色:节点、边、全局都传递信息→中值最高
- 棕色:在节点、全局之间传递信息→也还不错
对比棕色和灰色,可以发现:边在传递信息上对精度的帮助不是很大
从整体的情况来看,传递的东西越多,效果也越好
如果参数没调好,也会有几个out layer
- 总结
总体来看,能调的超参数还挺多的:GNN设多少层,每个属性的embedding有多大,汇聚用什么操作、怎么样做信息的传递
博客论文的可交互型的图,做的非常好,可以调调看看
5. 相关技术
论文中,提到了很多相关的技术话题,接下来的部分可能是简单的列举,感兴趣的,可以针对某种技术再展开调研。
这里只列举了文中提到的4个部分,其他的还有GCN、点和边做对偶、将图卷积视为矩阵乘法,将矩阵乘法视为在图上行走、图注意力机制(Graph attention networks)、模型的可解释性。
5.1 其他类型的图
图的结构非常多,但是凭借灵活的消息传递框架,可以使GNN适应更为复杂的图结构。可以通过定义新图的属性,决定如何进行信息的传递和更新。
- multigraph(多重图/多边图)
节点之间,可以有多种类型的边,想要根据节点的类型对节点之间的交互进行不同的建模时,可以考虑这种图。GNN 可以通过针对每种边的类型使用不同类型的消息传递步骤来进行调整。
- 分层图/超节点图/嵌套图
一个节点代表一个图。嵌套图对于表示层次结构信息很有用。例如,我们可以考虑一个分子网络,其中一个节点代表一个分子,如果我们有一种将一个分子转换为另一个分子的方法(反应),则两个分子之间共享一条边。在这种情况下,我们可以通过一个 GNN 来学习嵌套图,该 GNN 学习分子级别的表示,另一个学习反应网络级别的表示,并在训练期间在它们之间交替。
- 超图
其中一条边可以连接到多个节点,而不仅仅是两个。对于给定的图,我们可以通过识别节点社区并分配连接到社区中所有节点的超边来构建超图。

不同的图结构在消息传递/信息汇聚的时候,会产生不同的影响。如何训练和设计具有多种图属性的GNN是当前的研究热点。
5.2 GNN 中的图采样和批处理
前文中提到过,假设我们有很多个GNN层,就算每一层只看1近邻,最后一层的节点,也可以看到一个很大的图,假设一个图的连通性足够的话,可以看到整个图的信息。
在计算梯度的时候,我们要存储整个forward里边所有的中间变量,如果最后一个节点,要看整个图的话,就意味着我们对它算梯度的时候,需要存储整个图之间的中间结果。即GNN存在邻居爆炸的问题。
并且,由于彼此相邻的节点和边的数量存在变化,这种做法对图提出了挑战,这意味着我们无法拥有恒定的批量大小。
所以我们需要对图进行采样,就是说,把这个图,每次采一个小图出来,在小图上做信息的汇聚。这样在算梯度的时候,只要在这个小图上的中间结果记录下来就行了。
文中列举了对一张图的4种采样方式,如下图所示
- 随机节点取样:随机采样一些点,即节点集,然后添加与节点集相邻距离为k的相邻节点,包括他们的边。每个邻域都可以被视为一个单独的图,并且可以在这些子图的批次上训练 GNN。通过控制采样的点,避免子图过大。
- 随机游走取样:随机采样单个节点,将其邻域扩展至距离 k,然后选择扩展集中的另一个节点。一旦构造了一定数量的节点、边或子图,这些操作就可以终止。
- 结合1 和2:随机走几步(图中为3步),然后找到他们的邻居节点
- 扩散抽样:随机取一个点,将其做一个宽度遍历,进行扩散

采用什么方法进行采样,取决于图的样子。
从性能上考虑,我们不想对每个顶点逐步更新,这样每一步的计算量太小,不利于并行。我们参考神经网络的做法,可以对小样本进行小批量的处理,然后对大的矩阵或者tensor做运算,这里的问题就是,每个顶点的邻居个数是不一样的,怎么样把这些顶点及其邻居通过合并成一个规则的张量,是一个有挑战性的问题。
5.3 inductive biases
任何一个神经网络,都有一定的假设,
- 卷积神经网络假设空间变换的不变性;(即 图像的平移、旋转、缩放,都可以成功识别出来)
- 循环神经网络假设的是时序的延续性;
- 图神经网络的假设就是保持图的对称性(也就是排列无关性,不管怎么样交换顶点的顺序,GNN对其作用保持不变)
5.4 不同的pooling方式
常见的pooling方式有max、mean、sum,如下图所示,左边的两个图,如果用max,结果都是4,不能区分开这两张图;对于右边的两个图,则只有sum可以区分。
因此没有一个Pooling方式是明显优于其它Pooling方式的。

总体来看,GNN就是对属性做变换而不改变图的结构,并利用图的连通性来更新属性。GNN可以有效地发掘图的结构,但是图上做优化是很难的,对超参数敏感。
第⑤部分提到的其他技术,写的不够详细。后续还需要更深入地了解想要应用的具体技术。