6.Python数据分析项目之音乐推荐系统
1.总结
预测类数据分析项目
| 流程 | 具体操作 |
|---|---|
| 基本查看 | 查看缺失值(可以用直接查看方式isnull、图像查看方式查看缺失值missingno)、查看数值类型特征与非数值类型特征、一次性绘制所有特征的分布图像 |
| 预处理 | 缺失值处理(填充)拆分数据(获取有需要的值) 、统一数据格式、特征工程(特征编码、0/1字符转换、自定义) 、特征衍生、降维(特征相关性、PCA降维) |
| 数据分析 | groupby分组求最值数据、seaborn可视化 |
| 预测 | 拆分数据集、建立模型(机器学习:RandomForestRegressor、LogisticRegression、GradientBoostingRegressor、RandomForest)、训练模型、预测、评估模型(ROC曲线、MSE、MAE、RMSE、R2)、调参(GridSearchCV) |
数量查看:条形图
占比查看:饼图
数据分区分布查看:概率密度函数图
查看相关关系:条形图、热力图
分布分析:分类直方图(countplot)、分布图-带有趋势线的直方图(distplot)
自然语言处理项目:
| 流程 | 具体操作 |
|---|---|
| 基本查看 | 导入数据(surprise.Dataset 、pickle) |
| 预处理 | 获取数据转换为对应的数据格式、Dataset构建训练集、 |
| 数据可视化(绘制词云图) | 分组统计数量、训练模型(学习词频信息)、使用自定义背景图、绘制词云图 |
| 建模(文本分类) | 文本分类(LDA模型)、机器学习(朴素贝叶斯)、深度学习(cnn、LSTM、GRU) |
推荐系统
| 流程 | 具体操作 |
|---|---|
| 基本查看 | 导入数据 、获取数据转换为列表、 |
| 预处理 | 删除空值、关键词抽取(基于 TF-IDF、基于TextRank )、分词(jieba) 、关键词匹配(词袋模型)、处理分词结果(删除特殊字符、去除停用词) |
| 建模(推荐系统surprise)与预测 | KNNBaseline算法 |
2.推荐系统概述
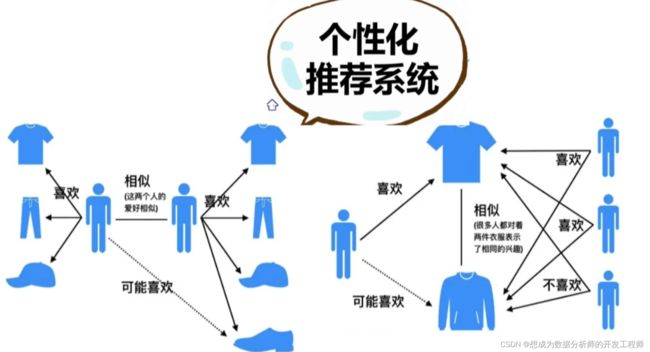
什么是推荐系统
推荐系统是利用网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
推荐系统建模大致过程
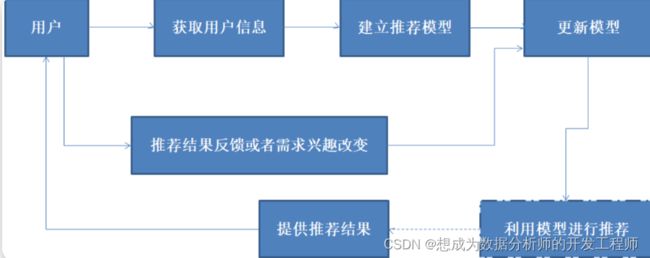
3.推荐系统解决方案

4.协同过滤算法
4.1 协同过滤算法简介
什么是协同过滤算法
简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
- 可以忽略Item本身的特性,也不用计算用户的特性
- 关注用户的行为,构建User与Item间的协同关系
- 是一种间接的推荐,通过行为找间接关系
协同过滤推荐的一般步骤
- 收集用户行为 这种行为一般能体现用户的偏好,但不分析他具体的兴趣标签。
- 找到相似物品用户 通过协同行为计算相似的用户或者相似物品,需要注意的是,我们不通过属性计算相似而是行为。
- 计算并推荐 计算出相似结果,基于场景进行用户或者物品的协推荐。
4.2 协同过滤算法的分类
基于用户的协同过滤
基于用户的协同过滤,即希望通过用户之间的关系来达到推荐物品的目的,于是,给某用户推荐物品,即转换为寻找为这个用户寻找他的相似用户,然后相似用户喜欢的物品,那么也可能是这个用户喜欢的物品(当然会去重)。
实现步骤:
- 对每个用户的所有行为进行汇总
- 用户行为进行向量化,找到与目标用户兴趣相似的用户集合
- 找到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户

基于物品的协同过滤
基于物品的协同过滤,即希望通过物品之间的关系来达到推荐物品的目的,于是,给某用户推荐物品,即转换为该物品与其他物品的相似度计算,但计算过程不是依赖于物品本身的属性相似,而是通过用户行为来判断物品的相似关系。
实现步骤:
- 对每个用户的所有行为进行汇总,然后以物品为维度构建向量
- 通过用户行为(已有购物偏好,非物品属性)计算物品间的关联性(相似性)
- 在物品候选集中,进行物品推荐

基于模型的协同过滤
基于用户或者物品协同的方法严重地依赖简单的相似性度量(比如余弦相似性、皮尔森相关系数等)来把相似的用户或物品匹配起来。 如果有一矩阵,其中每一行是一个用户,每一列代表一个物品,则基于记忆的方法对这一矩阵的行或列使用相似性度量来获得一个相似度值。
基于模型的方法尝试更进一步地填充上面说的矩阵,它们尝试量化一个用户会多么的喜欢他们之前没有遇到的物品。
为达此目的,基于模型的方法使用一些机器学习算法来对物品的向量(针对一个特定的用户)来训练,然后建立模型来预测用户对于新的物品的得分。

5.音乐推荐系统概述
本项目通过对网易云音乐的歌单与歌曲信息进行分析推荐,旨在掌握推荐系统的一般解决方案。
每个歌单都有对应的若干个歌曲

本项目的数据已经获取,分别是popular_playlist.pkl(歌单数据)、popular_music_suprise_format.txt(歌单与其对应的歌曲数据)、popular_song.pkl(流行歌曲数据)
在代码中可通过pickle模块加载popular_playlist.pkl歌单数据(二进制数据):
import pickle
data = pickle.load(open('popular_playlist.pkl', 'rb'))
popular_song.pkl歌曲数据加载使用同样的方法
注意:
可以把本项目的"歌单"看做用户
6.推荐系统库——Surprise介绍
在推荐系统的建模过程中,我们将用到Surprise(Simple Python RecommendatIon System Engine),是scikit系列中的一个推荐系统库。
安装方式:pip install surprise
如果安装过程报类似于“Microsoft Visual C++ 14.0 is required…”的错误,则说明需要安装C++环境,则先安装C++环境(C++环境安装文件已上传)。
Surprise官方网址:http://surpriselib.com/
7.最相似歌单与用户预测
7.1加载数据并处理
import pickle # 导入二进制数据
import os
from surprise import KNNBaseline, Reader
from surprise import Dataset
# 加载歌单数据:歌单id映射到歌单名的字典
id_name_dic = pickle.load(open("popular_playlist.pkl",'rb'))
# 重建歌单名到歌单id的映射字典
name_id_dic = {}
for playlist_id in id_name_dic:
name_id_dic[id_name_dic[playlist_id]] = playlist_id
# file_path 歌单-->歌曲文件路径
file_path = os.path.expanduser('./popular_music_suprise_format.txt')
# 指定文件格式: line_format是给定列名称
reader = Reader(line_format="user item rating timestamp", sep=',')
# 从文件读取数据(真正读取文件)
music_data = Dataset.load_from_file(file_path, reader=reader)
print('构建训练数据集...')
trainset = music_data.build_full_trainset()
使用surprise中的Dataset构建数据集查看数据

7.2建模——最相似的用户
'''
使用基于用户的方式进行推荐,这里选择索引为30的用户(歌单)作为被推荐对象,找到与其最相似的10个歌单
'''
index = 30
print('开始训练模型.....')
# 创建模型对象
algo = KNNBaseline()
# 拟合训练
algo.fit(trainset)
# 保存训练的模型结果
pickle.dump(algo, open("model.pkl",'wb'))
# 获取被推荐的用户名称
current_playlist = list(name_id_dic.keys())[index]
print('被推荐的用户名称: ',current_playlist)
# 通过用户名称去表中查看用户ID
playlist_id = name_id_dic[current_playlist]
print("被推荐的用户ID: ", playlist_id)
# 取出对应的训练集内部user_id
playlist_inner_id = algo.trainset.to_inner_uid(playlist_id)
print("内部id: ",playlist_inner_id)
# 找到与其最相似的10个用户(歌单) 是通过内部user_id去寻找
playlist_neighbors = algo.get_neighbors(playlist_inner_id, k=10)
# 把歌单内部id转成歌单原始id
playlist_neighbors = (algo.trainset.to_raw_uid(inner_id) for inner_id in playlist_neighbors)
# 通过字典去寻找最相似歌单的名称
playlist_neighbors = (id_name_dic[playlist_id] for playlist_id in playlist_neighbors)
print("和歌单 《,"+current_playlist+",》最接近的10个歌单为:\n")
for playlist in playlist_neighbors:
play_name = playlist.split('\t')
print(play_name[0],play_name[1],play_name[2])

7.3 用户预测
# 加载歌曲数据
song_id_name_dic = pickle.load(open("popular_song.pkl",'rb')) # 歌单的原始数据
# 内部编码为4的用户(歌单)进行推荐
user_inner_id = 4
# 从训练集(原始数据)获取编号为4的所有歌曲的评分
user_rating = trainset.ur[user_inner_id]
# 获取该歌单对应的歌曲内部id
items = map(lambda x:x[0], user_rating)
for song_id in items:
# 传递需要预测的用户id(内部),用户原始的歌单的id(内部),评分
print(algo.predict(user_inner_id,song_id,r_ui=1),'---',
# 获取歌单原始数据中的歌曲名称(通过训练集的歌曲id获取)
song_id_name_dic[algo.trainset.to_raw_iid(song_id)]
)
