Hugging “Hugging Face“
2016年,两位怀揣梦想的法国人Clem Delangue和Julien Chaumond在巴黎创立了HuggingFace公司。最初致力于研发聊天机器人,为青少年找点乐子,打发下时间。后来他们为Google的BERT模型做了一个pytorch版的开源实现,得到了社区的广泛认可,并由此逐步开发出了Transformers库。Transformers库降低了预训练模型的学习门槛,使得模型的二次开发及应用变的简单。AI从业者快速运用BERT、GPT、Llama、Resnet、Stable Diffusion等模型,实现文本分类、信息抽取、文本生成、图像识别以及图像生成等不同的任务。
HuggingFace从此一发不可收拾,已然成为机器学习领域的GitHub。全球数以万计的AI开发者通过HuggingFace向大家展示自己的研究成果,分享自己的模型及相关的数据集。其中分享的各类AI模型每天以千为基数增长。以下两张图分别是HuggingFace网站9月5日与9月18日的模型数量截图。9月5日模型数量为319408个,9月18日模型数量为334732个。两周时间新增15324个模型,相当于每天平均新增约1095个模型。社区异常活跃,其中不乏优秀的,可以直接使用的模型。
(图: 9月5日)
(图: 9月18日)
HuggingFace除了提供Transformers库方便开发人员使用各类模型外,还提供了一组名为Inference API的Restful接口。使用者可以通过直接调用该Web接口来访问模型,了解模型,而不必将模型下载到本地。如今的模型,动辄几个G大小,如果每次都下载到本地使用Transformers库来运行看效果,这的确是一个费时、费力、费资源的事情。当然,Inference API也有一定的限制,并不是所有的模型都能通过Inference API访问。如:HuggingFace缺省条件下不提供大于10G模型的Inference API、部分模型设置了不支持通过Inference API访问的限制。另外,缺省条件下,HuggingFace对于Inference API做了速率限制,访问性能不高,无法用做生产环境。为此,HuggingFace提供了Inference Endpoints方案。允许使用者为Inference API申请专属的计算资源,以确保获得合适的响应性能。
即使有了如此方便的访问接口,在HuggingFace中找到能够匹配业务需求或研究效果的模型依然困难。毕竟在如此大规模的模型库中一点点搜索、运行和比较模型怎么看都是一个巨大的工作量。为此,笔者团队基于自研的Sengee(神机)平台,给出了一个通过低代码方式来研究和使用HuggingFace模型及数据集的社区版工具。为了表达对HuggingFace公司在人工智能领域为所有从业者做出的贡献,我们将其命名为”HuggingFists”,并为其设计了如下的图标,以一种中国人的礼仪文化对其表达了诚挚谢意。
好,闲话少叙,我们来介绍下如何使用HuggingFists访问HuggingFace中的模型与数据集。
HuggingFists简介
HuggingFists是在Sengee(神机)低代码平台基础上开发出的一款偏向模型部署、应用的工具。主旨为了让从业者能够在人工智能飞速发展的今天,更快,更方便的享受到包括大语言模型在内的各类模型为人类带来的便捷。其界面如下:
- 首页:用于宏观展示系统中各类资源及运行结果
- 数据源:用于管理系统中读写可能涉及到的各类数据源。类型包括:数据库、文件系统以及应用等。
- 流程管理:用于设计、调试及管理面向业务的各种数据处理流程。
- 作业管理:用于创建及调度流程作业,设置作业的执行周期,满足业务系统的生产需要。
- 环境管理:用于管理系统运行所需要的资源环境,如:工作节点管理、服务设置管理等。
- 资源管理:用于管理系统中的各类数据制品资源,如:连接器管理、算子管理等。允许用户根据需求扩展连接器和算子。不同的连接器用于连接不同的数据源;不同的算子则具备不同的功能,将其连接在一起构成一个数据处理流程。
系统内置了很多算子,类型包括:输入、输出、读取、写出、控制、处理、分析等。输入、输出用于控制可以对哪些数据源进行读写;读取、写出约定了如何读写特定格式的数据,支持的格式包括:图片、文本、CSV、Json、Xml、PDF、Word、Visio、Ppt等;控制算子用于控制及优化流程的逻辑及效率;处理算子用于调整和处理数据,将其处理为可被后续算子使用的结构及内容;分析算子则提供了对数据的各类分析,如:文本分类、图像分类等。
HuggingFists几乎支持了HuggingFace暴露出的所有Inference API,为每个Inference API都封装了一个算子,通过系统界面查询算子可以看到数十个以HuggingFace命名的算子,如下图:

从图中我们可以看到两种特征命名的算子,其中名字中带"Pte"的算子表示可以调用本地部署的私有化模型的算子。而不带该特征的算子则是封装了Inference API的算子。HuggingFists支持使用者本地化部署模型的应用场景,在算子的应用体验上,与使用Inference API类型的算子没有太大的差别。下面,我们就介绍下,如何使用HuggingFists便捷的访问HuggingFace中的模型与数据集。
如何访问Hugging Face中的模型
如何通过Inference API访问Hugging Face中的模型
要想通过Inference API访问Hugging Face模型,首先需要在Hugging Face网站中注册一个账号。可通过以下的链接https://huggingface.co/join注册账号。注册成功后,通过界面右上角的个人信息->Settings->Access Tokens申请一个专属的访问令牌。
其次,在HuggingFists右上角的个人信息->个人设置->资源账号中添加一个Hugging Face访问账号。进入资源账号界面后,选择添加资源账号,弹出如下的界面:

选中Hugging Face类型,并将申请到的访问令牌填充进“访问token”输入框,填充完成后提交,创建成功。
有时候,我们可能处于一个内网环境,无法直接访问到Hugging Face网站,那么我们可以配置一个Http代理,以方便我们跨过局域网的限制。在HuggingFists系统中,进入“环境管理”->"服务配置"模块。点击“新建服务配置”,弹出如下界面:

选中“网络Http代理服务”类型,填充代理相关信息,提交保存代理配置。
好,准备工作已经就绪,我们可以尝试使用Hugging Face算子来访问模型实现业务需求了。下面我们来看两个相关示例,一个是使用自然语言相关模型的例子;一个是使用图像相关模型的例子。先看使用自然语言相关模型的例子。
上图为一个读取互联网新闻,抽取新闻中的文本内容,然后对其进行文本摘要、文本情感分类以及命名实体识别三种作业任务的流程示例。秉持着无视频无真相的逻辑,各位看官如果想了解详细的操作流程和解读,可以点击“玩转数据之低代码玩转HuggingFace”观看视频。图中红色框选部分为流程定义过程中可以使用的算子树;蓝色部分为流程的定义模板;绿色部分为算子的属性配置及帮助区。如图所示,选中一个Hugging Face的摘要提取算子后,右侧绿色框中显示了它的可配置属性和文档说明。属性部分的前两个框输入之前已经提前准备好的Http代理和Hugging Face账号。后面的参数框可根据算子帮助辅助完成设置。以此方式拖拽和定义完所有流程,就可以点击蓝色区域上侧的按钮调试或执行流程了。下面我们再看一个图像相关模型的例子。
该示例同样可在上面提到的视频中看到详细的操作和讲解。其主要演示了对一张图片进行了物体识别、图像分割以及图像分类三种作业任务,涉及了三个不同的模型。
以上示例中,我们演示了几个模型。但实际使用时,哪个模型效果比较好呢?这个问题我们也回答不了,需要使用者自己去查找和比较了。这也是我们做这个系统的初衷之一,让大家更方便的了解和挑选模型。
如何访问本地化部署的Hugging Face模型
相较通过Inference API访问Hugging Face中的模型,本地化部署模型需要的准备时间稍长,但是成本和安全性上更可控。下面我们简单介绍下,如何使用HuggingFists访问本地部署的HuggingFace模型。
首先,我们选择一个希望本地部署的模型,然后选中模型的"Files and versions"页,如下图:
从图中我们可以看到模型相关的文件有很多,一般而言除了说明类文档,都是模型装载运行所需要的。所以,我们需要提前把所有相关的文件都下载本地,并将这些文件都存放在同一个文件夹下。由于Hugging Face没有提供文件的打包下载功能,所以目前只能手动,一个一个的下载(这是模型本地化部署最麻烦的地方)。
模型下载完成后,创建模型的应用流程。流程的创建过程及搭建方式与使用Inference API算子一致,唯一的差别是,当选择算子时,需要选择算子名中带有"Pte"部分的算子。这类算子支持模型的本地调用。"Pte"算子的种类超过Inference API算子,因为Hugging Face并不是为所有类型的任务都提供了Inference API。两种算子最大的差别如下:

图中可以看到在使用本地化部署的模型时,不再需要Http代理以及Hugging Face账号,取而代之的是选择一个本地的文件夹路径。文件夹内即为我们下载的模型。一般情况下,算子调用时不会再拉取其它文件,但笔者团队实验时发现,确实存在还要在运行时下载部分模型文件的情况。这种情况下,算子的启动速度就会被拖慢。另外还有两个属性Python脚本片段和计算设备值得注意。由于Hugging Face网站上的模型太多,有些模型在调用时会有细微差别,若存在无法正常启动模型的情况,可适当调整Python脚本片段确保模型可被正常加载执行。计算设备属性用于指定模型运行在本地计算机的哪个计算单元上,支持CPU和GPU两种计算单元。可以根据本地机器的情况设定该参数。算子的其它相关属性可参见算子说明进行配置。配置完成就可以驱动流程在本地使用模型了。
如何访问Hugging Face中的数据集
Hugging Face网站能够找到全球从业者分享的各类数据集,方便使用者训练或测试模型。HuggingFists提供了一个针对HuggingFace网站的连接器,可以方便使用者选中合适的数据集,并将这些数据集存储到指定的存储系统中。方便使用者应用这些数据。
首先,在数据源功能模块中,选中应用程序Tab页,选中HuggingFace连接器创建HuggingFace数据源,并设置好访问账号与访问代理等配置。如下图:

点击“提交”按钮后,会创建出一个HuggingFace数据源。可以通过点击“查看数据”按钮浏览数据源,挑选合适的数据集。
选中合适的数据集后,可以定义一个数据处理流程将数据集中的数据读出并存储到数据库或文件中。如下图流程,使用HuggingFaceReader读取数据集,并将其写入MySQL数据表,操作详情可参见视频“玩转数据之低代码读取HuggingFace数据集“。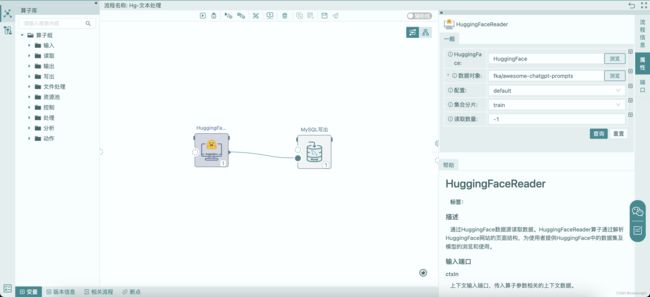
结语
Hugging Face网站汇集了全球AI从业者的智慧,他们在这里自由分享各类模型与数据集,是一个真正意义的AI宝库。值得有需要的各类小伙伴探索与发现。相信大家一定可以在此找到自己感兴趣的模型,并加以改进或应用。相信我们提供的HuggingFists工具可以一定程度的帮到一部分朋友来完成这个探索。我们为大家提供了HuggingFists的社区版,目前只支持Linux操作系统。系统是B/S架构的,支持多人同时使用。如果大家有兴趣可以下载使用。
安装部署要求:CentOS 7.6及以上版本;4核8G;
下载地址:HuggingFists社区版
系统采用容器化部署,安装包比较大,我们后续会持续优化。我们还提供了更多样的连接器及算子没有一并共享出来,因为那样会让安装包显的更大。如果您在使用时有更多需求,可以跟我们联系获取。如果您有什么建议、问题我们也欢迎您联系我们。可以通过扫描以下二维码加入我们,获得我们的支持。
