BiseNet实现遥感影像地物分类
遥感地物分类通过对遥感图像中的地物进行准确识别和分类,为资源管理、环境保护、城市规划、灾害监测等领域提供重要信息,有助于实现精细化管理和科学决策,提升社会治理和经济发展水平。深度学习遥感地物分类在提高分类精度、自动化程度、处理大规模数据、普适性以及推动遥感技术创新和发展等方面都具有重要的意义。本文将利用深度学习BiseNet实现遥感地物分类。
数据集
本文使用的数据集为WHDLD数据集[1](Wuhan dense labeling dataset)。WHDLD数据集包括4940张高分辨率遥感影像,包含6种土地覆盖类型,影像尺寸均被裁剪至256×256像素。下面是一些数据集示例。 
BiSeNet
BiseNet[2](Bilateral Segmentation Network)是一种用于图像分割的深度学习网络。它具有双边分割的特点,可以同时处理空间信息和上下文信息,从而实现高效、准确的图像分割。
具体来说,BiseNet由两个分支组成:空间路径(spatial path)和上下文路径(context path)。其中,空间路径具有较小的感受野,可以捕获丰富的空间信息并生成高分辨率的特征图;而上下文路径则具有较大的感受野,可以捕获更多的上下文信息并生成低分辨率的特征图。这两个路径通过一个特征融合模块进行融合,从而生成既包含丰富空间信息又包含上下文信息的分割结果。
在BiseNet中,还有一些关键的技术和设计,如轻量级模型设计、注意力机制、特征融合等,这些技术和设计可以进一步提升网络的性能和效率。 
网络复现
resnet18
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as modelzoo
resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
from torch.nn import BatchNorm2d
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
def __init__(self, in_chan, out_chan, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_chan, out_chan, stride)
self.bn1 = BatchNorm2d(out_chan)
self.conv2 = conv3x3(out_chan, out_chan)
self.bn2 = BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if in_chan != out_chan or stride != 1:
self.downsample = nn.Sequential(
nn.Conv2d(in_chan, out_chan,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(out_chan),
)
def forward(self, x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.relu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
shortcut = x
if self.downsample is not None:
shortcut = self.downsample(x)
out = shortcut + residual
out = self.relu(out)
return out
def create_layer_basic(in_chan, out_chan, bnum, stride=1):
layers = [BasicBlock(in_chan, out_chan, stride=stride)]
for i in range(bnum-1):
layers.append(BasicBlock(out_chan, out_chan, stride=1))
return nn.Sequential(*layers)
class Resnet18(nn.Module):
def __init__(self):
super(Resnet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
self.layer3 = create_layer_basic(128, 256, bnum=2, stride=2)
self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
self.init_weight()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
feat8 = self.layer2(x) # 1/8
feat16 = self.layer3(feat8) # 1/16
feat32 = self.layer4(feat16) # 1/32
return feat8, feat16, feat32
def init_weight(self):
state_dict = modelzoo.load_url(resnet18_url)
self_state_dict = self.state_dict()
for k, v in state_dict.items():
if 'fc' in k: continue
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
BiSeNet
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from .resnet import Resnet18
from torch.nn import BatchNorm2d
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class UpSample(nn.Module):
def __init__(self, n_chan, factor=2):
super(UpSample, self).__init__()
out_chan = n_chan * factor * factor
self.proj = nn.Conv2d(n_chan, out_chan, 1, 1, 0)
self.up = nn.PixelShuffle(factor)
self.init_weight()
def forward(self, x):
feat = self.proj(x)
feat = self.up(feat)
return feat
def init_weight(self):
nn.init.xavier_normal_(self.proj.weight, gain=1.)
class BiSeNetOutput(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, up_factor=32, *args, **kwargs):
super(BiSeNetOutput, self).__init__()
self.up_factor = up_factor
out_chan = n_classes
self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
self.conv_out = nn.Conv2d(mid_chan, out_chan, kernel_size=1, bias=True)
self.up = nn.Upsample(scale_factor=up_factor,
mode='bilinear', align_corners=False)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.conv_out(x)
x = self.up(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
self.bn_atten = BatchNorm2d(out_chan)
# self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = torch.mean(feat, dim=(2, 3), keepdim=True)
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
# atten = self.sigmoid_atten(atten)
atten = atten.sigmoid()
out = torch.mul(feat, atten)
return out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class ContextPath(nn.Module):
def __init__(self, *args, **kwargs):
super(ContextPath, self).__init__()
self.resnet = Resnet18()
self.arm16 = AttentionRefinementModule(256, 128)
self.arm32 = AttentionRefinementModule(512, 128)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
self.up32 = nn.Upsample(scale_factor=2.)
self.up16 = nn.Upsample(scale_factor=2.)
self.init_weight()
def forward(self, x):
feat8, feat16, feat32 = self.resnet(x)
avg = torch.mean(feat32, dim=(2, 3), keepdim=True)
avg = self.conv_avg(avg)
feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm + avg
feat32_up = self.up32(feat32_sum)
feat32_up = self.conv_head32(feat32_up)
feat16_arm = self.arm16(feat16)
feat16_sum = feat16_arm + feat32_up
feat16_up = self.up16(feat16_sum)
feat16_up = self.conv_head16(feat16_up)
return feat16_up, feat32_up # x8, x16
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class SpatialPath(nn.Module):
def __init__(self, *args, **kwargs):
super(SpatialPath, self).__init__()
self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
feat = self.conv1(x)
feat = self.conv2(feat)
feat = self.conv3(feat)
feat = self.conv_out(feat)
return feat
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
## use conv-bn instead of 2 layer mlp, so that tensorrt 7.2.3.4 can work for fp16
self.conv = nn.Conv2d(out_chan,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.bn = nn.BatchNorm2d(out_chan)
# self.conv1 = nn.Conv2d(out_chan,
# out_chan//4,
# kernel_size = 1,
# stride = 1,
# padding = 0,
# bias = False)
# self.conv2 = nn.Conv2d(out_chan//4,
# out_chan,
# kernel_size = 1,
# stride = 1,
# padding = 0,
# bias = False)
# self.relu = nn.ReLU(inplace=True)
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = torch.mean(feat, dim=(2, 3), keepdim=True)
atten = self.conv(atten)
atten = self.bn(atten)
# atten = self.conv1(atten)
# atten = self.relu(atten)
# atten = self.conv2(atten)
atten = atten.sigmoid()
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class BiSeNetV1(nn.Module):
def __init__(self, n_classes, aux_mode='train', *args, **kwargs):
super(BiSeNetV1, self).__init__()
self.cp = ContextPath()
self.sp = SpatialPath()
self.ffm = FeatureFusionModule(256, 256)
self.conv_out = BiSeNetOutput(256, 256, n_classes, up_factor=8)
self.aux_mode = aux_mode
if self.aux_mode == 'train':
self.conv_out16 = BiSeNetOutput(128, 64, n_classes, up_factor=8)
self.conv_out32 = BiSeNetOutput(128, 64, n_classes, up_factor=16)
self.init_weight()
def forward(self, x):
H, W = x.size()[2:]
feat_cp8, feat_cp16 = self.cp(x)
feat_sp = self.sp(x)
feat_fuse = self.ffm(feat_sp, feat_cp8)
feat_out = self.conv_out(feat_fuse)
if self.aux_mode == 'train':
feat_out16 = self.conv_out16(feat_cp8)
feat_out32 = self.conv_out32(feat_cp16)
return feat_out, feat_out16, feat_out32
elif self.aux_mode == 'eval':
return feat_out,
elif self.aux_mode == 'pred':
feat_out = feat_out.argmax(dim=1)
return feat_out
else:
raise NotImplementedError
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
for name, child in self.named_children():
child_wd_params, child_nowd_params = child.get_params()
if isinstance(child, (FeatureFusionModule, BiSeNetOutput)):
lr_mul_wd_params += child_wd_params
lr_mul_nowd_params += child_nowd_params
else:
wd_params += child_wd_params
nowd_params += child_nowd_params
return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
训练过程精度变化
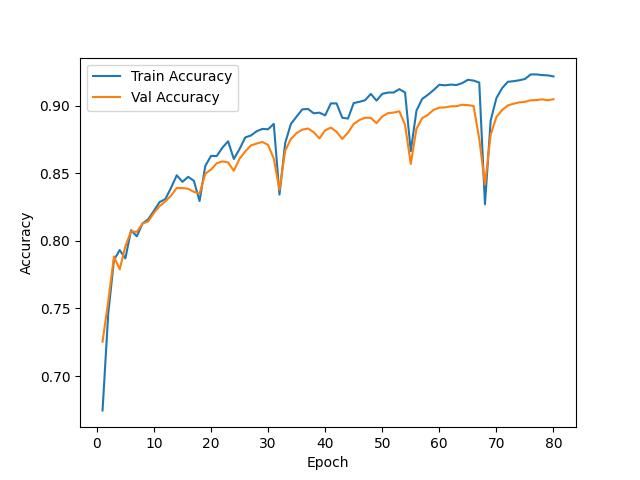
测试精度

结果展示

总结
今天的分享到此结束,感兴趣的点点关注,后续将分享更多案例。
参考资料
[1]WHDLD: https://sites.google.com/view/zhouwx/dataset#h.p_hQS2jYeaFpV0
[2]BiSeNet: https://arxiv.org/abs/1808.00897
本文由 mdnice 多平台发布