《十堂课学习 Flink SQL》第四章:Flink 应用 java 开始典型案例
小伙伴们我们从本章开始将基于JAVA 进行Flink 应用开发,本章节主要介绍Maven开发环境搭建,日志配置,流计算案例以及批计算案例。一方面希望能借此规范化一下开发流程,另一方面也是简单案例入门,为接下来越来越复杂的案例分析打好基础。
4.1 基于 Maven 的 Flink 应用开发环境搭建
4.1.1 新建基于Maven的项目

4.1.2 添加 Maven 依赖
双击 pom.xml 文件,添加 dependencies 如下:
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<scala.binary.version>2.11scala.binary.version>
<lombok.version>1.18.30lombok.version>
<flink.version>1.14.6flink.version>
<slf4j.version>2.0.9slf4j.version>
<logback.version>1.3.11logback.version>
<junit.version>4.13.2junit.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>${commons-lang3.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>${lombok.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>${slf4j.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>ch.qos.logbackgroupId>
<artifactId>logback-coreartifactId>
<version>${logback.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>ch.qos.logbackgroupId>
<artifactId>logback-classicartifactId>
<version>${logback.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>${junit.version}version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-test-utils-junitartifactId>
<version>${flink.version}version>
<scope>testscope>
dependency>
dependencies>
这里特别需要说明:
- 不需要添加
flink-java/flink-stream-java_***/flink-core等等。因为均包含在 flink-client 之中; flink-client仅仅用于本地调试,如果上生产环境不需要打包上去,因为生产环境提供相应的包(注意版本一致)。- 日志相关工具依赖也仅仅用于本地调试,生产环境也有提供 Slf4j-api 以及对应log4j实现类。所以打包上 flink 客户端运行时不需要考虑日志的依赖问题。
- 测试类依赖的scope统一为
test,因为打包到flink客户端或生产环境flink集群均不需要这些。
4.1.3 添加 maven 插件
分别添加 maven-compiler-plugin 与 maven-shade-plugin 插件,注意其中的版本在前面已经提到。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<source>${maven.compiler.source}source>
<target>${maven.compiler.target}target>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>3.1.1version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shadingexclude>
<exclude>com.google.code.findbugs:jsr305exclude>
<exclude>org.slf4j:*exclude>
<exclude>org.apache.logging.log4j:*exclude>
<exclude>ch.qos.logback:*exclude>
excludes>
artifactSet>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
configuration>
execution>
executions>
plugin>
plugins>
build>
确保maven下载安装好了相关依赖,即 查看 pom.xml 文件是否还有报错。
4.2 运行官方案例 WordCount
接下来新建一个 StreamWordCount 类,代码如下,注意新建是添加的包名:
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.MultipleParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.flink.util.Preconditions;
/**
* 单词统计简单案例
* @author Smileyan
*/
@Slf4j
public class StreamWordCount {
/**
* 默认的用于统计单词个数的字符串
*/
public static final String DEFAULT_WORDS = "Flink’s Table & SQL API makes it possible to work with queries written " +
"in the SQL language, but these queries need to be embedded within a table program that is written in either Java or Scala. " +
"Moreover, these programs need to be packaged with a build tool before being submitted to a cluster. " +
"This more or less limits the usage of Flink to Java/Scala programmers" +
"The SQL Client aims to provide an easy way of writing, debugging, and submitting table programs " +
"to a Flink cluster without a single line of Java or Scala code. " +
"The SQL Client CLI allows for retrieving and visualizing real-time results from the running distributed " +
"application on the command line.";
public static void main(String[] args) throws Exception {
final MultipleParameterTool params = MultipleParameterTool.fromArgs(args);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.getConfig().setParallelism(3);
// 将全局参数传递给执行环境
env.getConfig().setGlobalJobParameters(params);
DataStream<String> text = null;
// 根据输入参数判断是否指定了输入文件路径
if (params.has("input")) {
// 遍历所有输入文件路径,将它们的数据合并为一个数据流
for (String input : params.getMultiParameterRequired("input")) {
if (text == null) {
text = env.readTextFile(input);
} else {
text = text.union(env.readTextFile(input));
}
}
// 检查数据集是否为空
Preconditions.checkNotNull(text, "Input DataStream should not be null.");
} else {
// 否则,使用默认的文本数据
text = env.fromElements(DEFAULT_WORDS);
}
// 对文本数据进行分词并计数
assert text != null;
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer())
.keyBy(value -> value.f0)
.sum(1);
// 打印结果到标准输出
log.info("Printing result to stdout. Use --output to specify output path.");
counts.print();
// 执行作业
env.execute("Streaming WordCount");
}
/**
* 分词函数,实现了 FlatMapFunction 接口。
* 将输入的文本行分割为单词,并为每个单词生成一个键值对(单词,1)。
*/
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 8061659867139246041L;
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 将文本行转换为小写并按非单词字符分割
String[] tokens = value.toLowerCase().split("\\W+");
// 遍历分割后的单词数组,将每个单词生成键值对并输出到结果收集器
for (String token : tokens) {
if (!token.isEmpty()) {
out.collect(Tuple2.of(token, 1));
}
}
}
}
}
接下来运行时请注意,我们需要运行时添加 provided 的依赖类型。即
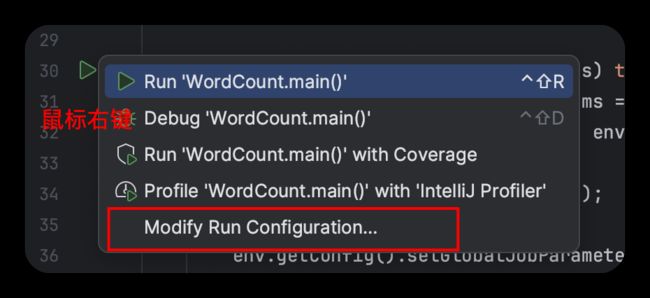
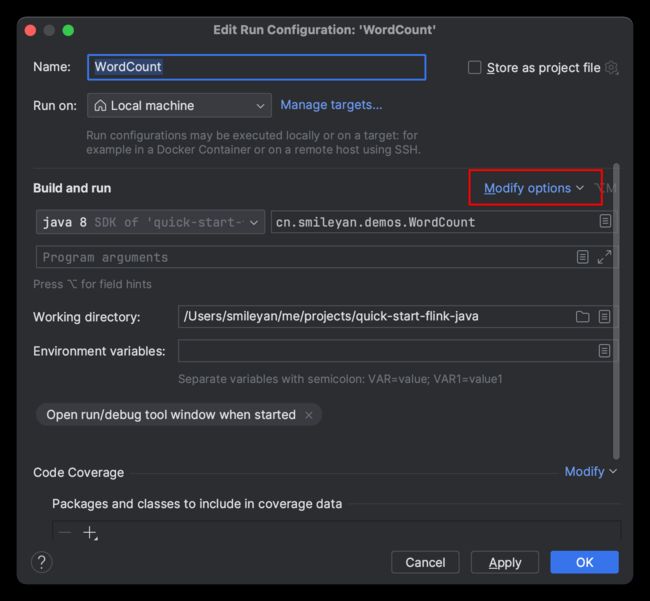
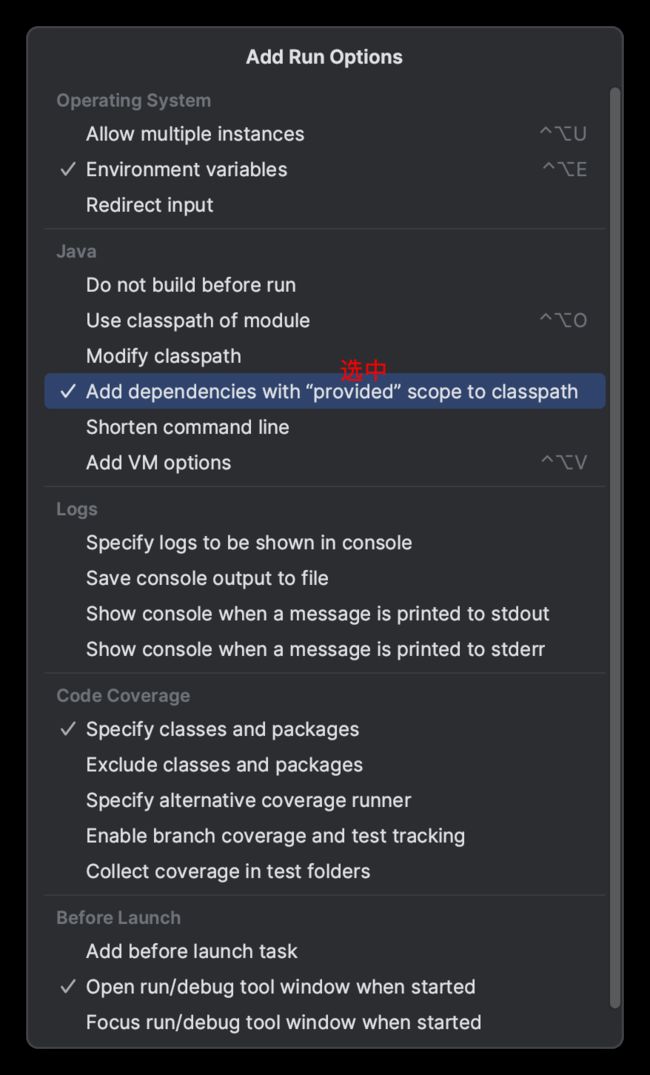
选择OK后,即可点击右上角的执行按钮。如下录制视频所示:
4.3 添加日志输出配置文件
经过前面的这些步骤,已经完成了本地运行 flink job ,先不急着分析其中的结果,先优化一下输出日志的问题,即 DEBUG 级别日志太多;全部都是白色的字体看起来不够清晰。如图所示:
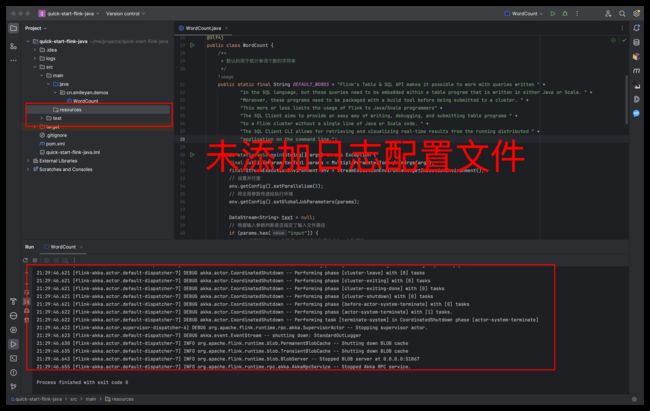
在项目的 resources 目录下新建一个文件,取名叫 logback.xml, 文件内容为:
<configuration>
<property name="CONSOLE_LOG_PATTERN"
value="%cyan(%d{yyyy-MM-dd HH:mm:ss.SSS}) %blue([%thread]) %magenta(%-5level) %green(%logger{60}) %yellow(%file:%line) %X{sourceThread} - (%msg%n)"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}pattern>
<charset>UTF-8charset>
encoder>
appender>
<appender name="file" class="ch.qos.logback.core.FileAppender">
<file>logs/${file.log}.logfile>
<append>falseappend>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{60} %X{sourceThread} - %msg%npattern>
encoder>
appender>
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
root>
<logger name="org.apache.flink" level="INFO">
<appender-ref ref="file"/>
logger>
<logger name="akka" level="INFO">
<appender-ref ref="file"/>
logger>
<logger name="org.apache.kafka" level="INFO">
<appender-ref ref="file"/>
logger>
<logger name="org.apache.hadoop" level="INFO">
<appender-ref ref="file"/>
logger>
<logger name="org.apache.zookeeper" level="INFO">
<appender-ref ref="file"/>
logger>
<logger name="org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline" level="ERROR">
<appender-ref ref="file"/>
logger>
<statusListener class="ch.qos.logback.core.status.NopStatusListener" />
configuration>
执行后的效果可以参考如下视频:
4.4 批处理案例
类似地,我们添加批处理案例代码,新建 BatchWordCount类。
package cn.smileyan.demos;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.MultipleParameterTool;
import org.apache.flink.util.Collector;
import org.apache.flink.util.Preconditions;
/**
* 说明:
* 1. 代码中的 DEFAULT_WORDS 数组包含了一些默认的文本数据,用于 WordCount 示例。
* 2. main 方法是程序的入口点,解析命令行参数,设置 Flink 执行环境,并执行 WordCount 示例。
* 3. Tokenizer 类是一个 FlatMapFunction,用于将输入的文本进行切分和计数。
* @author Smileyan
*/
@Slf4j
public class BatchWordCount {
/**
* 默认的用于统计单词个数的字符串
*/
protected static final String[] DEFAULT_WORDS = {"Flink’s Table & SQL API makes it possible to work with queries written ",
"in the SQL language, but these queries need to be embedded within a table program that is written in either Java or Scala. ",
"Moreover, these programs need to be packaged with a build tool before being submitted to a cluster. ",
"This more or less limits the usage of Flink to Java/Scala programmers",
"The SQL Client aims to provide an easy way of writing, debugging, and submitting table programs ",
"to a Flink cluster without a single line of Java or Scala code. ",
"The SQL Client CLI allows for retrieving and visualizing real-time results from the running distributed ",
"application on the command line."};
public static void main(String[] args) throws Exception {
// 解析命令行参数
final MultipleParameterTool params = MultipleParameterTool.fromArgs(args);
// 获取 Flink 执行环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 设置全局作业参数
env.getConfig().setGlobalJobParameters(params);
// 定义文本数据集
DataSet<String> text = null;
if (params.has("input")) {
// 如果命令行参数包含输入路径,则从文件中读取文本数据
for (String input : params.getMultiParameterRequired("input")) {
if (text == null) {
text = env.readTextFile(input);
} else {
text = text.union(env.readTextFile(input));
}
}
Preconditions.checkNotNull(text, "Input DataSet should not be null.");
} else {
// 否则,使用默认的文本数据
text = env.fromElements(DEFAULT_WORDS);
}
// 执行 WordCount 示例
assert text != null;
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.groupBy(0)
.sum(1);
// 打印结果
counts.print();
}
/**
* Tokenizer 类实现了 FlatMapFunction 接口,用于将输入文本切分并计数。
*/
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
/**
* 切分并计数逻辑
*
* @param value 输入文本
* @param out 输出 Tuple2 的 Collector
*/
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 将文本转换为小写,并根据非单词字符切分
String[] tokens = value.toLowerCase().split("\\W+");
// 遍历切分后的单词数组,排除空单词,并将单词和计数为 1 的 Tuple 发送到 Collector
for (String token : tokens) {
if (!token.isEmpty()) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
4.5 相关资料
欢迎访问本文对应的源码地址:https://gitee.com/smile-yan/quick-start-flink-java
Flink 官网 1.14.6 的在线文档:https://nightlies.apache.org/flink/flink-docs-release-1.14/
4.6 本章小结
俗话说,“万事开头难” 。但是很多开源项目作者团队都有一个很好的习惯 —— 提供quick-start 的简单项目。本文的目的也是如此,Flink 很强大,如果我们细究原理的话应该至少得读一些论文,做一些实验,读一读源码。
但事实上,很幸运对大多数小伙伴们而言,我们不需要这样做。Flink 就像一把斧头,我们需要学会如何把斧头打磨锋利、如何更好地使用斧头,而不用考虑怎么去制作它。
愿我们都能掌握 Flink 基础知识,并在今后的学习与工作中更好地打磨它,在接下来的开发道路上帮助我们不断披荆斩棘 ~
如果认为本章节写得还行,一定记得点击下方免费的赞 ~ 感谢 !
